
A new way to implement Product Search using Amazon Titan Multimodal Embeddings in Amazon Bedrock
The advantage of multi-modal embeddings lies in their ability to capture rich relationships and dependencies between different types of data. We can use these embeddings in various applications, such as image captioning, video analysis, sentiment analysis in multimedia content, recommendation systems, and more, where understanding and integrating information from multiple modalities is crucial.
Piyali Kamra
Amazon Employee
Published Jan 8, 2024
Last Modified Jan 16, 2024
Amazon Titan Multimodal Embeddings is a multimodal embedding model built by Amazon for use cases like searching images by text, image, or a combination of text and image. Designed for high accuracy and fast responses, this model is an ideal choice for search and recommendations use cases. Using Titan Multimodal Embeddings, we can generate embeddings for our content and store them in a vector database.
In the example below, I will show how to use the Titan Multimodal Embeddings model to perform domain-specific product searches on the Indo Fashion dataset on Kaggle. When we submit any combination of text and image as a search query, the model generates embeddings for the search query and subsequently we match the generated embeddings to the stored embeddings in a vector database to provide relevant search and recommendations results to end users.
AWS Command Line Interface (CLI) is an open-source tool that enables you to interact with AWS services using commands in your command-line shell. You can refer to AWS CLI to install it. Set up the IAM credentials for the AWS CLI via 'aws configure', ensuring the IAM entity has requisite permissions through appropriate policies attached, to allow actions for Amazon S3, Amazon Bedrock, and Amazon OpenSearch Serverless.
Download the Indo Fashion dataset from Kaggle and unzip the data. Here is how the folder structure and the entry in the JSON files look like:
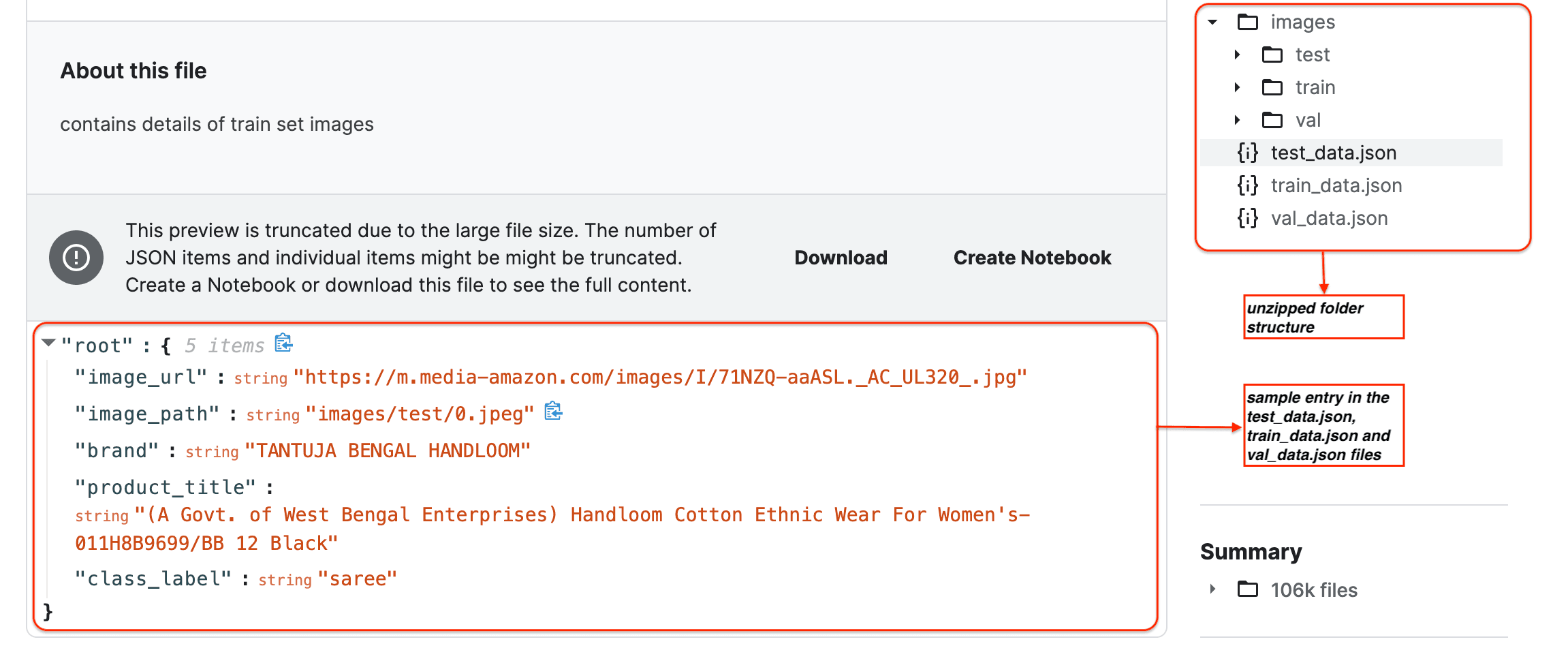
At a high level, I want to use the Titan Multimodal Embeddings model to encode the Indo fashion dataset images and their associated product titles into a shared embedding space. The model’s cross-modal understanding enables it to match image embeddings with relevant textual descriptions, such as product titles, effectively associating visual and textual information. Once I generate the embeddings, I store the vector embeddings in Amazon OpenSearch Serverless. Finally, I perform Text-based and Image-based searches against the generated embeddings.
After I configured the AWS CLI and the IAM credentials with the required permissions, I used Visual Studio Code (VS Code) with the Python and Jupyter plugins to run the code snippet shown below to configure my development environment. The cell below configures the libraries for Amazon Bedrock, Amazon OpenSearch Serverless, and visualization libraries.
Next, I initialize the boto3 client for Amazon Bedrock to use the Bedrock API's for invoking the Amazon Titan Multimodal Embeddings model. I generate embeddings for the images and their corresponding product titles in a shared embedding space by invoking the Amazon Titan Multimodal Embeddings Model on the indo fashion dataset represented in ./fashion_data/train_data.json and ./fashion_data/val_data.json files. Additionally, I decide to save the generated embeddings in flat JSON files, so that if I want to repeat my experiment, I don't need to re-generate the embeddings again, instead I can ingest the embeddings from the local JSON files and experiment with other vector databases.
After the above code snippet is executed, here is the structure of the embedding files generated in my local directory. These embeddings represent the vector representations of the Indo-fashion images and their product titles in a shared embedding space. Each vector representation generated by the Amazon Titan Multimodal Embeddings model has 1024 dimensions which is the default value, but other dimensions are available.
Amazon OpenSearch Serverless has a new feature called Collections that I use below for storing the vector embeddings generated above. I initialized an Amazon OpenSearch Serverless Collection named “product-search-multimodal” as shown below. Additionally, I create the encryption policies, network policies, and data access policies for accessing the Amazon OpenSearch Serverless Collection. At the end of the code block below, I instantiate an Amazon OpenSearch Serverless client to connect to Amazon OpenSearch Serverless.
Amazon OpenSearch is a versatile and fully managed suite for search and analytics, that offers robust scalability. It supports KNN (K-Nearest Neighbors) search, enabling retrieval of similar documents based on vectors. To use this capability, I create a new vector index within the vector search collection. Each document within this index will encompass six key properties: "image_path," "image_product_description," "image_brand," "image_class," "image_url," and a vector embeddings field named "multimodal_vector". The dense vector embeddings, generated from the Indo Fashion dataset by the Amazon Titan Multimodal Embeddings model, will contain 1024 dimensions. To query these vectors, the index "product-search-multimodal-index" is configured to use the Non-Metric Space Library (nmslib), with the Hierarchical Navigable Small Worlds algorithm (HNSW) and cosine similarity (cosinesimil). Please review OpenSearch’s index documentation for more information on the search methodology options available with OpenSearch.
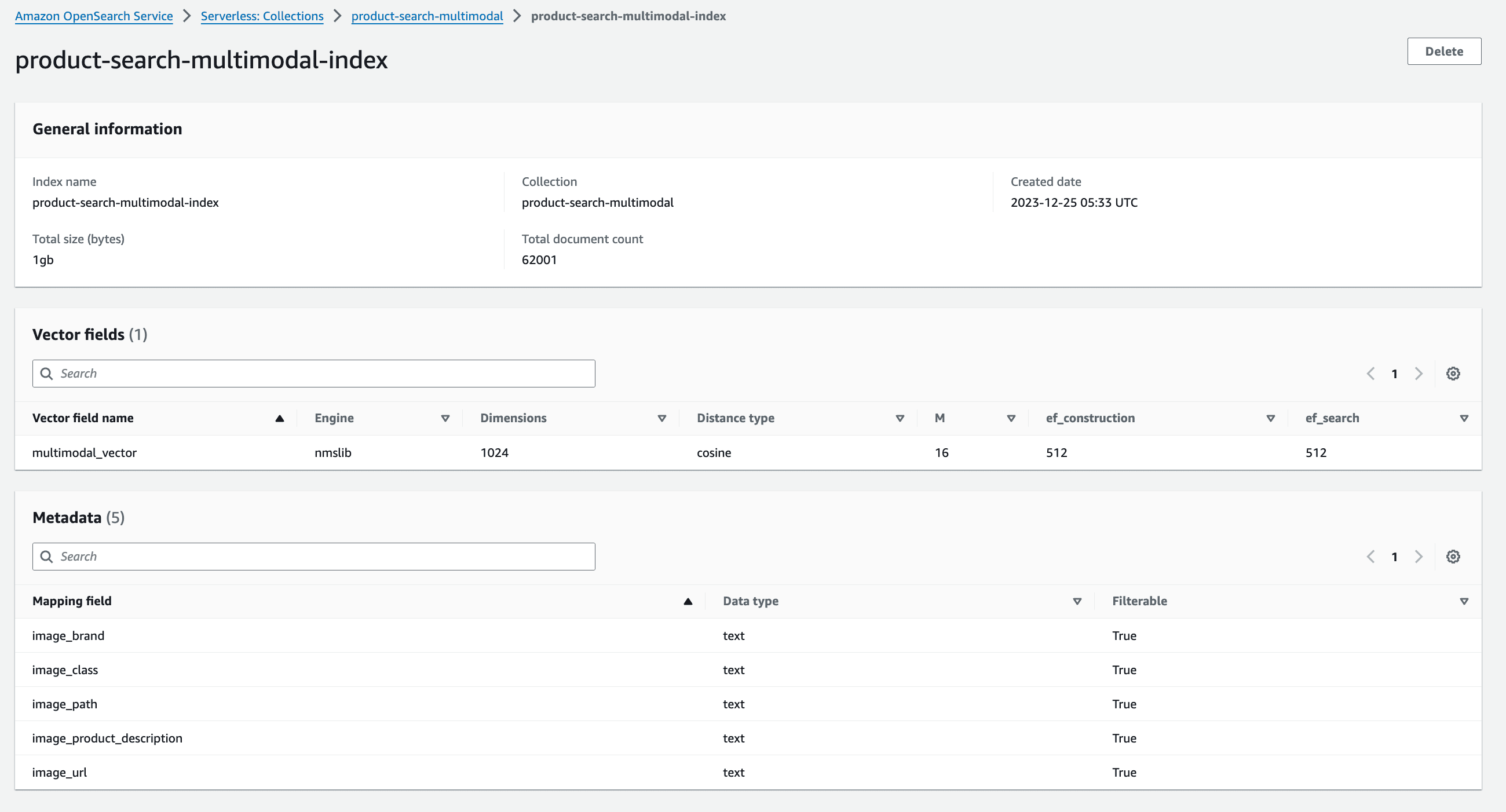
You can also review the new Vectorsearch collection, "product-search-multimodal", and the associated vector index, "product-search-multimodal-index", from the Amazon OpenSearch Service console.
In the next code snippet below, I ingest the JSON Documents generated in Step 2 into the Amazon OpenSearch index "product-search-multimodal-index".
Once the documents are ingested into the index, this is how my AWS console for the Amazon OpenSearch Collections index looks like:
I have indexed the documents and embeddings in OpenSearch and want to conduct a multi-modal search. To begin with, I want to try a text-based search, using the example of a "Georgette Pink Saree" description. My aim is to retrieve the most closely related images with this text description. To accomplish this, I will use the Amazon Titan Multimodal Embeddings model to generate vector embeddings for the text through the get_embedding_for_text() function. Then, I will query the OpenSearch Index "product-search-multimodal-index" using the text embedding generated by the get_embedding_for_text() function.
Next, I visualize the images retrieved, using the matplotlib library and iterating over the text_based_
search_response variable initialized in the above code block, which holds the documents retrieved from OpenSearch.
search_response variable initialized in the above code block, which holds the documents retrieved from OpenSearch.

Next, I upload an image as a request for semantic search instead of a text/product description and then retrieve images semantically similar to the requested image. This is what my input image in location './fashion_data/images/test/1358.jpeg' looks like:

The code below retrieves the vector embeddings for the input Image by invoking the Amazon Titan Multimodal Embeddings model and then I search the retrieved vector embeddings against the OpenSearch Index. The retrieved documents from OpenSearch are obtained in the variable image_based_search_response.
Finally, I visualize the images retrieved using the matplotlib library and iterating over the image_based_search_response variable initialized in the above code block.
As we see below, the images are semantically similar to the reference image I used for searching.

Conclusion
This blog provides insights into the Amazon Titan MultiModal embeddings model, showcasing its capability to process diverse data types concurrently, like text and images. This model facilitates the conversion of text and image data formats into a unified encoding space, enabling consistent processing across different data modalities. For more information on the Amazon Titan Multimodal Embeddings model, access this AWS News blog.
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.