
Power Chat Messages Search with DynamoDB & Amazon OpenSearch
Learn how to effectively implement full-text search using Amazon DynamoDB and Amazon OpenSearch in a real-world serverless group chat backend system.
Published Jan 25, 2024
Last Modified Jan 29, 2024
We have built a group chat application that stores chat messages in Amazon DynamoDB and it is running for a few months now. As the application grew, users wanted to be able to search through historical chat messages. To enable this, we will integrate DynamoDB with Amazon OpenSearch Service for full-text search capabilities. There are multiple ways of dealing with this, but I would like to experiment with something new. During the 2023 re:Invent AWS announced general availability of DynamoDB zero-ETL integration with Amazon OpenSearch service. In this article I will give it try on our group chat full-text search use case and share my insights and experience.
Our application already leverages DynamoDB for fast and scalable storage and retrieval of chat messages via an API. The API consists of an API Gateway and a few Lambda functions that interact with a DynamoDB table. That looks something like in the diagram below.
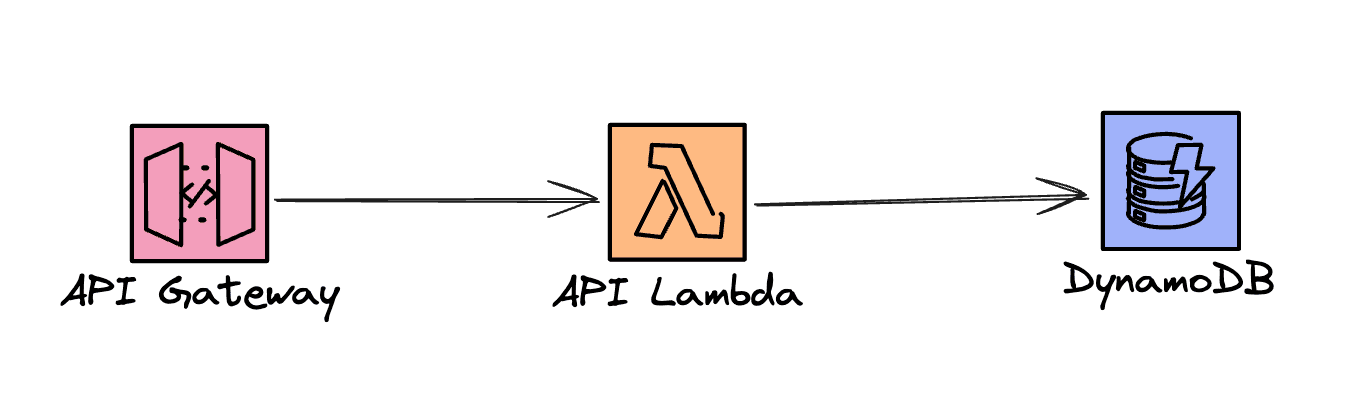
This is the already standard, boring setup for a Serverless API on AWS 🙃 DynamoDB is not well suited for the full-text search use case. Let's see what needs to be added to achieve this.
To facilitate the full-text search over chat messages we will add Amazon OpenSearch to our architecture. Now, how do we approach syncing the messages data from DynamoDB to OpenSearch? The first thing that comes to mind it of course enabling DynamoDB Streams and having a Lambda function handle them and send the data to OpenSearch. However, we won't do that. We will leverage the zero-ETL integration between the two services. So, our architecture changes to something like:
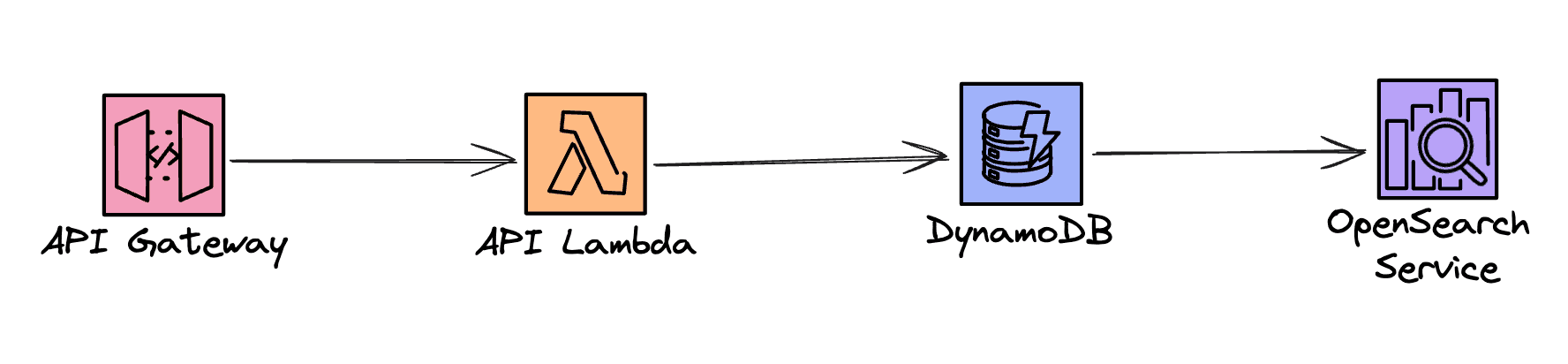
Amazon OpenSearch is a managed service and that means the underlying infrastructure is handled for us. We can set up an OpenSearch Domain, which means we specify the instance size and count, and it will be up and running after a short while. The second choice is to use the Serverless option, which is out of scope for this article. The important thing is that both options support zero-ETL sync from DynamoDB.
For this example, I provisioned a cluster with only 1 node of type t3.small.search. This is of course not production grade, but more than enough for this small PoC.
Having the OpenSearch cluster up and running is a great first step, but now we need to achieve two things:
- Import all existing messages from DynamoDB
- Set up constant sync of all future messages
Luckily, Amazon OpenSearch Ingestion pipeline can take care of both. How this works is the Pipeline initially exports all the table data to an existing S3 bucket of your choice, imports the data from there into OpenSearch, and then continues streaming all new changes in the table towards OpenSearch.
Before creating the Pipeline, some pre-conditions on the DynamoDB table need to be fulfilled:
- Point-in-time-recovery (PITR) is enabled
- DynamoDB Streams are enabled
Besides that, we need an S3 bucket that will be used for the data export and import. I created this bucket upfront.
And finally, we need an IAM Role that the Pipeline will assume to carry out all the work. Accordingly, the Role Policy must allow all actions that the Pipeline needs to perform on these resources.
For convenience, I am providing the Policy below:
The role needs to have a Trust relationship with
osis-pipelines.amazonaws.com. Once we make sure all of the above is set, we can proceed with creating the Pipeline.There are several options you need to pick and choose when creating a Pipeline. I'll focus only on a sub-set which proved useful to me for this example. After choosing the name, there is the Pipeline capacity configuration. It is measured in units called Ingestion-OCU and it is billed hourly while the Pipeline is Active, regardless of whether it is actually processing data. The Ingestion Pipeline billing resmbles the Serverless option of OpenSearch Service. I just left the minimum and maximum values to 1 and 4, as it was provided by default.
The Pipeline configuration is a YAML file with a lot of options, but luckily there are ready made blueprints for common use cases. I chose the
DynamoDbChangeDataCapturePipeline blueprint, which gives a nice template with some sensible defaults for this use case. The configuration ends up looking like the one below. I intentionally left the comments from the blueprint and added some of my own.Apart from the network configuration, ensuring that the Pipeline logs are sent to CloudWatch proved to be very useful for me, especially during the setup, as I wasn't able to get this working immediately. This was mostly due to misconfiguring the Role Policy. While there are many more options for high-availability and durability, those are out of scope for this discussion.
So, that should be it. Once the Pipeline is created, it should be started, and in a few minutes, if everything is configured properly, you should see the data appear in the designated S3 bucket for export, as well as in the OpenSearch Index, of course. As I already mentioned, CloudWatch logs were a big time-saver when something went wrong.
As I mentioned at the start, I already had a table full of chat messages with which I tested this setup. For the sake of testing, I am providing this gist which contains CSV representation of an AI generated group chat simulation about a trip to Hawaii 🌴 Feel free to use this for practicing and load it into a DynamoDB table.
After the pipeline runs the initial import, I am able to search all the data very quickly. Also, each new message ends up in OpenSearch within seconds. To test the search, let's say that I want to find out if the trip is confirmed and hopefully get more info on that. By issuing a very simple
GET _search/q=confirmed request in OpenSearch Dashboards DevTools, the result can be seen in the screenshot below.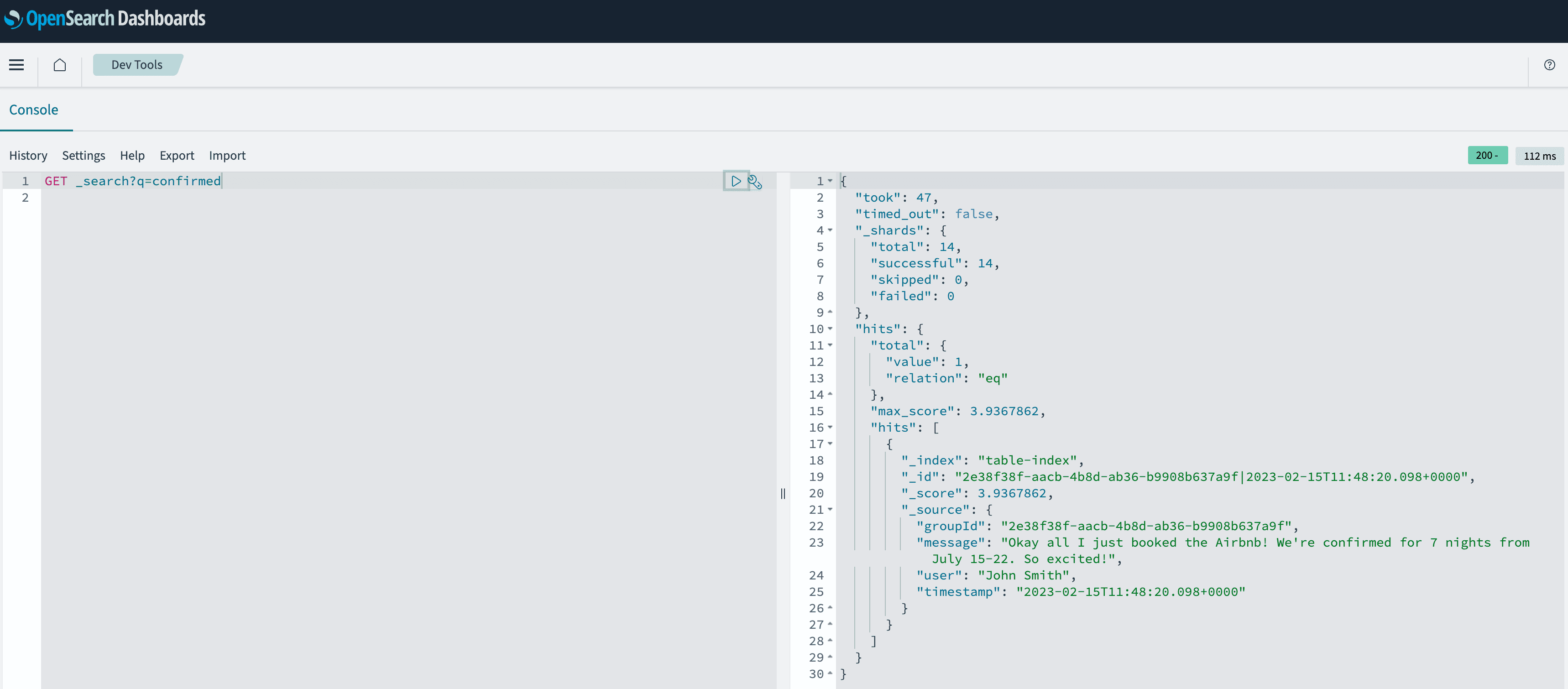
We see that there is one hit and the message contains just what we are looking for. Also, please notice that the
_id field contains the primary key of our DynamoDB table, which consists of a group chat id and a message timestamp. These mappings are performed automatically for us.This article shows that by leveraging the DynamoDB to OpenSearch zero-ETL integration, we can quickly and efficiently search for messages based on keywords without the need for complex infrastructure management. This goes for both the cluster and Serverless variants. The integration also allows us to scale our search solution as our application grows. Overall, Amazon DynamoDB and Amazon OpenSearch are a powerful combination that can help organizations build fast and efficient search solutions for their applications.
Nevertheless, I believe that the scale of data for both ingestion and search needs to be substantial to warrant the incorporation of OpenSearch into a solution of this nature. Considering that search is not the primary feature of our application, the associated costs do not justify its implementation. Given our architecture, operating the smallest OpenSearch instance along with ingestion for a weekend incurs expenses equivalent to running the entire application for an entire month. OpenSearch Serverless, despite being even more costly, is still unnecessary for us since our current workload is far from reaching the scale that would warrant such a solution. As mentioned earlier, the primary objective of this article is to delve into the new feature of zero-ETL integration. It is likely that we will opt for an alternative solution for search that aligns better with our smaller scale and budget.