Intelligent Document Processing With Augmented AI
Hands-on Guide: Extract Text with Textract, Classify Batch Documents Using Comprehend, and Implement Human Review with Amazon Augmented AI (A2I)
Published Mar 15, 2024
We will explore an Intelligent Document Processing (IDP) solution demonstrating core functionalities through code. Additionally, we will demonstrate the same operations using the Console, providing both programmatic and console-based approaches to building an IDP solution.
Intelligent Document Processing
Intelligent Document Processing (IDP) is the automation of manual document processing tasks. IDP usually involves using machine learning solutions to automate tasks such as extracting text from images or other legacy documents and performing business processing tasks on extracted text, such as document classification from the content of documents.
IDP is automating document processing, and usually involving extraction of text from legacy documents.
AWS Definition of IDP - Intelligent document processing (IDP) is automating the process of manual data entry from paper-based documents or document images to integrate with other digital business processes.
- IDP decreases the chances of human error.
- It decreases the workload of employees, allowing them to focus on certain edge cases requiring human verification.
- Decrease workload of employee, letting them focus on certain edge cases requiring human verification
- Increases scale of enterprise document processing
- Reduce cost of document processing
We would use A2I to review documents that are classified with confidence level below certain threshold for humans to review, while not reviewing document above certain threshold.
Textract - Is an AWS service to extract text from unstructured documents (PNG, JPEG, TIFF, and PDF).
Comprehend - Is a service to perform analysis on text, like extraction of key phrases, redaction of personal identifiable information and classification of text, it also support extension by training it on your data.
Amazon Augmented AI (A2I) - This is used to improve accuracy of machine learning tasks by including humans verify classification outputs based on rules it minimize misclassification in edge cases. Example if a certain task has confidence score below certain threshold, it is flagged for human verification.
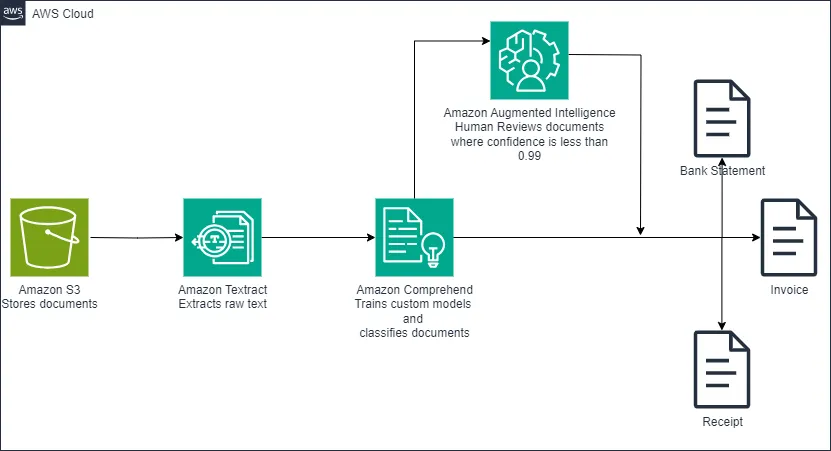
Our documents are mixed and we want to separate them into folders based on the type of document, and automate the process of document classification. Our solution.
- Extract text from legacy document using Textract
- Training Comprehend to classify document based on content of extract text
- Classify the document using comprehend custom classifier
- Based on the predicted document category save them to the right category
- If comprehend confidence of document category is below certain threshold send to for human review using A2I.
To get started, you'll need to create a SageMaker Domain. You can find detailed instructions in my other blog post or refer to the official AWS guide.
After that, create a JupyterLab space for code editing by following the steps outlined in this guide under the
To create a space and open JupyterLab section.we will modify Lab 1 of the AWS Intelligent Document Processing (IDP) workshop. You can download the complete solution from my GitHub repository and the original Jupyter notebook. The content will be similar to the original workshop, but we will enhance the solution by incorporating a human review component using Amazon Augmented AI (A2I)
We will and attach an inline policy to our SageMakerExecution Role that give SageMakerExecution role permission to pass IAM role credentials to other AWS services, such as Amazon Comprehend. This helps SageMaker integrate with other services to improve our IDP workflow.
In the AWS console navigate to IAM services
select
Roles on the left pane, Under
Roles select your SageMakerExecution role.Click
Add Permissions and select create inline policy Switch to the
Json tab and paste the following json policy.Click
Next, Under Review and save give the policy a name Click
create policyAttach the following managed policies to your SageMakerExecution role.
ComprehendFullAccess
AmazonTextractFullAccess
IAMPass
AmazonS3FullAccess
We will be using the default SageMaker bucket, you can use other bucket of your choice
We use the command above to the download document dataset for our classification task.
The code below is used to unzip the dataset and remove hidden files
We downloaded a third party library
call_textract containing code samples of different Textract use cases to interact with Textract instead of directly interacting with the Textract SDK (boto3).The code submits a document to Textract and extracts text. We use multi threading to submit and extract document text concurrently as shown below.
After extracting the text from documents using Amazon Textract, we compiled the extracted data into a CSV file. This file contains the extracted texts and their corresponding document types, which will serve as the training data for our Comprehend custom classifier. To make this data accessible for training, we uploaded the CSV file to an Amazon S3 bucket.
We will create a custom model using Comprehend to detect document types from the csv dataset we uploaded to s3. The below code creates the custom classifier.
You can now classify documents with the custom classification model created above using the console or the SDK specifying the input and output data locations. We demonstrate how to run a comprehend batch job below.
The below code starts a comprehend document classification job using our previously trained classifier. The comprehend API uses Textract to extract text from input documents, abstracting the process from users.
There are three core components of A2I
Template - Contains instructions for reviewers to follow.
Human Workforce - Are human reviewers performing the task.
Workflow or flow definition - Encompasses other component like specifying a UI template for instructions, the workforce team for review, the type of task and conditions for human review. We will create a custom A2I workflow definition.
We are use A2I to minimize misclassification, our workflow sends document for humans to review when classification confidence is below 1.0 .
We will create a private workforce to help review classifications with lower confidence.
You can use this guide to create work team with the console Create a Private Workforce (Amazon SageMaker Console) - Amazon SageMaker , we could also use the API to create private workteam programmatically but would need to create a Cognito User pool. To keep things simple we created our workforce using the SageMaker console.
On the SageMaker console select
Labeling workforces under Ground Truth and under private team copy the Workteam Arn to use for creating workflow with the API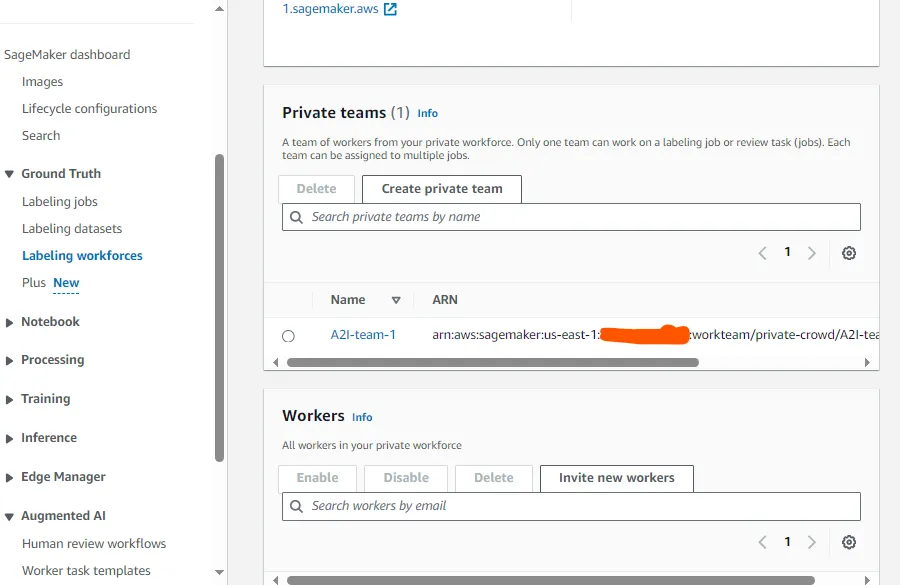
The below code specifies custom logic to send document for human classification when confidence score is less than 1.
Note, the initialValue of inputContent should be one of the possible categories
You could continue with the optional part of the original workshop and try adding a human loop to the deployed comprehend real-time endpoint or do it replacing comprehend classifier with an LLM. Bonus point write your own blog.
We have demonstrated how to implement an intelligent document processing solution using AWS tools within SageMaker and outside SageMaker to extract text from a legacy document format (image) and train a text classification model from our extracted document to classify our documents.
https://github.com/aws-samples/amazon-a2i-sample-jupyter-notebooks/blob/master/Amazon%20Augmented%20AI%20(A2I)%20and%20Comprehend%20DetectSentiment.ipynb