Scaling to Infinity: Mastering Hyperscale AWS Serverless Architecture with Lambdas
AWS Lambda performance series.
Published Feb 8, 2024
Introduction:
In the ever-evolving world of cloud computing, the concept of hyperscale has become increasingly important. Organizations are constantly seeking ways to scale their applications quickly and efficiently to meet growing demands. Amazon Web Services (AWS) has been a pioneer in this field, and one of their flagship serverless services, AWS Lambda, plays a pivotal role in enabling hyperscale solutions.
In this blog post, we’ll explore how AWS Lambda can be a game-changer for building hyperscale serverless architectures. We’ll dive into the core concepts, benefits, best practices, and real-world use cases for Lambdas in hyperscale scenarios. This is a daily discussion at Dealer Automation Technologies and I would like to share with my team this post.
Quotas and behaviors:
When using Cloud services we need to understand how these services behave, the default quotas, and behaviors before the big burst of traffic comes to ensure your event scales seamlessly, this is a good point to start this journey.
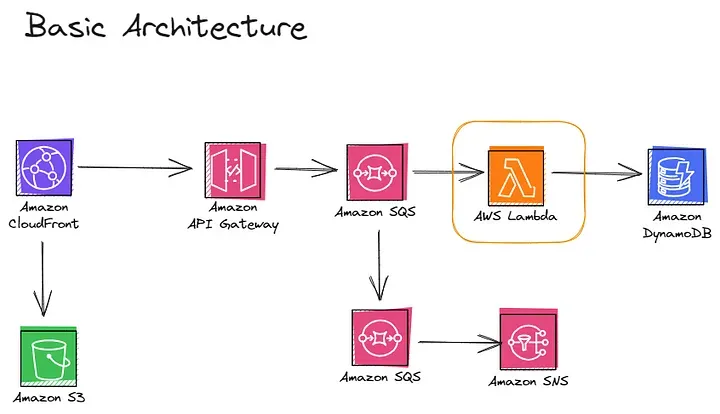
Let's take a look at this simple diagram, first, we have Amazon CloudFront within distribution pointing to S3, but I am going to talk about it in another post, and then we have API gateway, if you’re not familiar with this service, wait for future post, but I would like to mention the capabilities in terms of scalability; API Gateway is an always-on, always scaled out multi-tenant services.
- Burst from 0 to 100s of thousands of requests per second (RPS) with no advanced notice and no burst quota.
- Default throughput: 10000 RPS (Can be raised to handle the most demanding workloads).
- Max integration timeout: 29 (REST API) or 30 (HTTP API) seconds.
- Payload size: 10 MB.
- If you want to see more: https://go.aws/3qi1F7Y
API Gateway is a great service for Hyperscale workloads, but let's concentrate on the main services of this post. No matter what kind of API we are using GraphQL or API Gateway we need to get the response back from the integration, we have a timeout that's roughly 30 seconds depending on the type of API and we have a max payload size of 10 MB. So with AWS Lambda, we have this concept called concurrency.
Lambda concurrency
A single Lambda execution environment( Micro virtual machines or micro VMs) can only process a single event at a time
- Regardless of event source or invoke type.
- Batches pulled from SQS or DynamoDB Streams count as a single event.
Concurrent requests necessitate the creation of new execution environments. It’s essential to understand that every incoming concurrent request triggers the instantiation of a micro VM. If there isn’t a pre-initialized micro VM with your code ready to execute, a new one is spun up almost instantly and that's what we would call an “execution environment”. The total number of execution environments processing requests at a given time is this concept called concurrence.
Now let's take a look quickly this concept with pictures because it's important for planning our hyperscale workload.

As shown in the picture is an example request coming in, and in this case, we’ll just call it function X, but in the process of invoking function X, we don't have any existing micro VM to go, so what the lambda services do is it says: are there any hot on deck? If the answer is no, then we’re going to spin up a new execution environment, is this the concept called “Cold Starts” Anytime we spin up from scratch a whole new micro VM, we pull our code down to it, we initialize the runtime of the language, for example, NodeJs or Python (my favorites), and then we initialize our code, anything outside of the handler, etc. All of that time until the point where we enter the handler of our function is what we call a Cold Start, one important point here is once we actually enter the handler of the function, that where execution begins in this case, and the entire time until that execution is finished, this execution environment is dedicated to that request. If we have more requests come in let's say another comes in, as before we had no available capacity hot on deck (no micro VMs ready), so we spin up one more micro VMs, which means we have more Cold Starts, now the two or more environments are busy, and we get more requests coming in, but because all of the 2 were still busy processing those initial events when 3 and 4 come in, we get another two execution environments spun up and effectively, we’ve reached what we could call now 4 concurrencies, ‘couse we have 4 parallel things processing requests simultaneously. Now what changes here and an important behavior to understand is when the first request finishes, we don't just get rid of this execution environment, we reuse these environments by default until either a period of inactivity has occurred, so when we get a request 5 we actually reuse the first execution environment and we can jump directly into the handler (No cold start), this is what we call a warm start, see this explanation in the next picture.
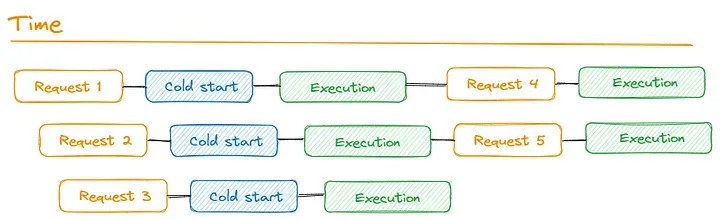
If we have a fairly steady state, we’re gonna have a lot more warm starts than cold starts. After this, I would like to show the Lambda scaling quotas.
Account concurrency
By default, Lambda provides your account with a total concurrency limit of 1,000 across all functions in a region. To support your specific account needs, you can request a quota increase and configure function-level concurrency controls so that your critical functions don’t experience throttling.
Burst concurrency
Maximum increase in concurrency for an initial bust of traffic
- 3000 in US East(N. Virginia), US West (Oregon), and Europe (Ireland).
- 1000 in US East (Ohio), Asia Pacific (Tokyo), and Europe ( Frankfurt).
- 500 in all other Regions.
After that, functions can scale by 500 concurrency per minute.
Maybe burst concurrency sounds new, but in a single minute, how much can we scale up our concurrent executions by region.

If we want to raise the account concurrency limit in advance of our event and if this bust limit is a concern, we need to use something called provision concurrency (a number of execution environments that we wanna have hot on deck at all times).
I will explain in the second part of this part the best practices if we want to optimize lambda function performance. Thanks and see you in the next lecture.