A Cost-Effective Modern Data Architecture for Small and Medium Enterprises
Leveraging Open-Source Tools And AWS Services for Scalable Big Data Solutions
Published Feb 10, 2024
In the landscape of modern data platform architectures, a common design pattern involves the integration of Fivetran for data extraction with Snowflake/Redshift/BigQuery/Databricks for data landing and transformation, complemented by DBT (Data Build Tool). While powerful, this architecture can be prohibitively expensive, especially for startups or small to medium-sized enterprises with only basic business intelligence (BI) needs at the early stage of growth.
This article introduces a cost-effective architecture that I have designed, implemented (with support from DevOps), and maintained in a production environment. Operating at an approximately cost of AU$450 per month, this architecture efficiently processes 10 billion records, executes over150 DBT models, and serves more than 40 dashboards on a daily basis.
- Daily batch job to ingest internal data (full overwrite sync)into **Data Lake (AWS S3)**via Spark Batch
- Daily batch job to ingest incremental data from 3rd party social media into Data Lake(AWS S3) via Airbyte
- AWS Glue Crawler scans and creates data catalog
- Data transformation is run on AWS Athena and managed by DBT
- Apache Superset consumes DBT model results and builds BI reports
- Restful API Microservice to provide DBT model results to 3rd party application
Designing a solution, especially for small to medium-sized businesses, involves careful consideration of trade-offs, priorities and especially the factor of cost.Through the solution design process, I have focused on four key criteria to ensure the architecture’s alignment with the unique needs of this segment:
- Cost-Effectiveness: Emphasising both upfront investment and ongoing operational cost
- Time-to-Market: Selecting solutions that can be rapidly deployed to accelerate benefits realisation
- Scalability: Ensuring the system can accommodate growing data volumes and workloads efficiently without proportional increases in costs or complexity.
- Ease of Use and Maintenance: Selecting technologies that are straightforward to operate and maintain, minimising the need for extensive training or specialised skills.
It’s important to note that while above criteria guide the overall architectural design, their relative importance varies across different components. For example, scalability & customisation takes precedence in the ingestion of our internal data from AWS Aurora into the data lake, whereas the emphasis shifts towards time-to-market for other aspects.
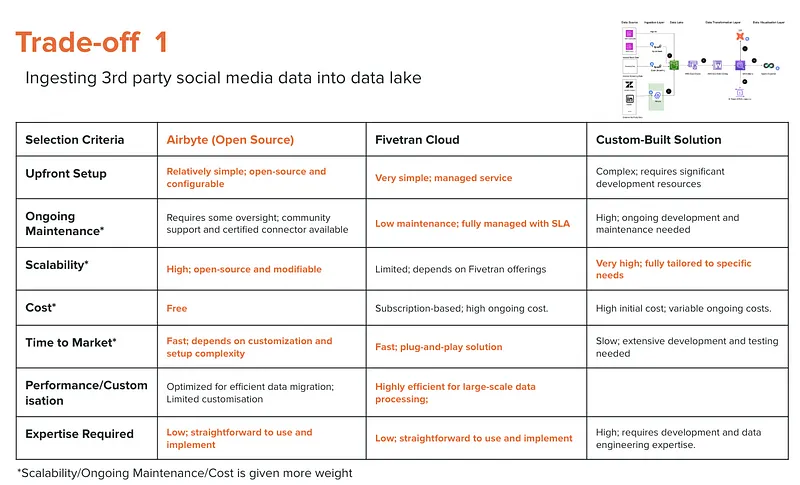
Choosing the right tool for integrating third-party data into our data lake was critical. I utilised an evaluation matrix to navigate this decision, highlighting our chosen factors/solutions in details. The selection process led us to Airbyte, deployed on AWS EKS EC2 with spot instances, which enables up to 70% in cost savings.
Why Airbyte?
- Cost: Airbyte is an open-source solution, eliminating licensing fees and reducing our operational costs significantly
- Scalability: Offers the ability to handle large volumes of data efficiently, a must-have for ingesting Zendesk Support data
- Simplicity: Provides a relatively straightforward setup process, minimising the time and effort required to get started
By leveraging Airbyte on EKS EC2 spot instances, we achieve substantial cost savings while ensuring our architecture remains scalable and easy to implement.
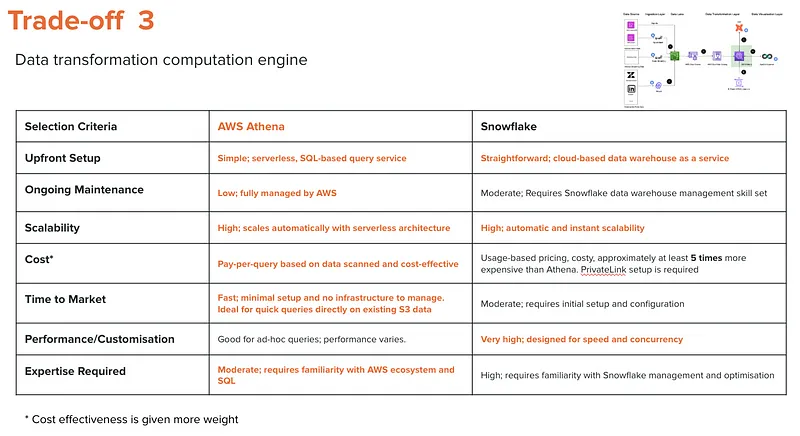
Faced with the challenge of managing an immense dataset — exceeding 10 billion records — stored in Aurora, our organisation prioritised simplicity and efficiency in our data ingestion strategy. To align with our objectives of scalability and customisation, I chose a full overwrite sync approach with Spark Batch to maintain straightforwardness in our processes.
Why Apache Spark?
- Scalability and Customisation: Apache Spark’s batch processing capabilities allow us to ingest massive volumes of data efficiently while providing the flexibility to tailor the ingestion process and logic to our specific needs.
- Performance: Hosting Apache Spark on EKS EC2, we can process and ingest the entirety of our 10 billion records within approximately 80 minutes, striking a balance between speed and cost-effectiveness.
This strategic decision underscores our commitment to maintaining control over our data ingestion pipeline, enabling us to optimise and adjust our processes as needed while handling large data volumes effectively.
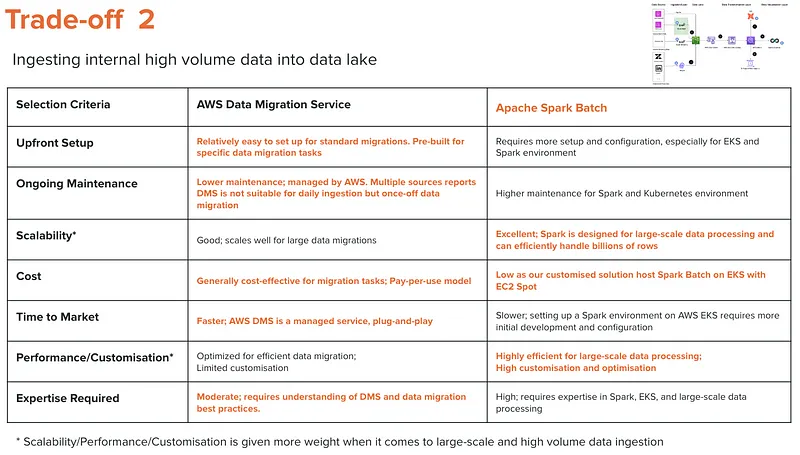
The heart of any modern data platform architecture is its data warehouse and computational capabilities. Despite AWS Athena is generally treated as an ad-hoc query engine, our experience demonstrates that combining DBT with Athena can forge an exceptionally cost-effective computational solution.
Why DBT + Athena?
- Cost-Efficiency: This combination significantly reduces operational costs, delivering the same outcomes for at least five times less expense than alternative solutions.
- Timing: Given that these are nightly batch jobs, the value of cost savings substantially outweighs the benefit of saving an estimated 30 minutes in processing time.
This decision underscores a strategic prioritisation of cost over speed, particularly for operations scheduled during off-peak hours.
For DBT and Athena integration, please feel free to refer to my previous post
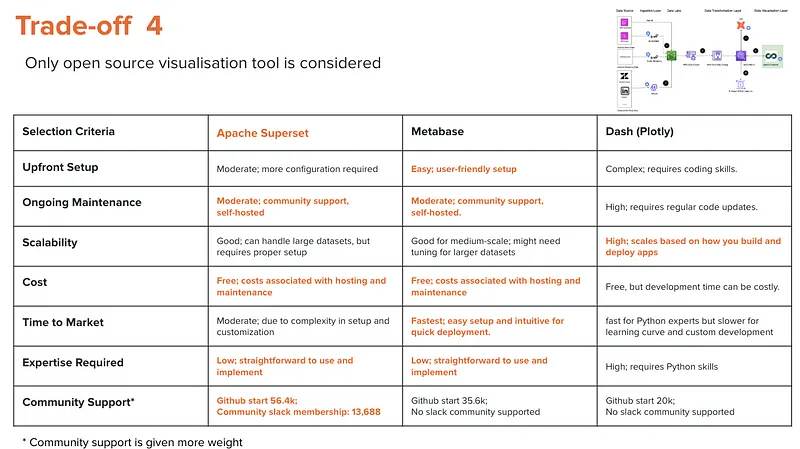
To align with our strategic goal of minimising costs while providing the business value of our BI initiatives, I deliberately focused on open-source options for our visualisation tools. This approach not only keeps expense low but also we embed as much business logic as possible within DBT. Such a strategy significantly simplifies future transitions between visualisation tools, whether open-source or commercial, by centralising the business logic and reducing dependency on any specific visualisation tool.
Why Apache Superset?
- Community Support: Apache Superset stands out due to the size and maturity of its community, offering a robust support network and a wealth of shared knowledge.
- Future Flexibility: By managing business logic in DBT, we maintain the ability to easily migrate to other visualisation tools as our needs evolve or as we demonstrate the tangible value of BI to our business units.
This choice reflects a strategic commitment to cost-efficiency and operational agility, ensuring that our BI infra can adapt to changing business requirements without incurring unnecessary expenses.
Despite the fact that this solution is computational highly efficient and cost effective, there are some known limitations (high-level)
Athena
- S3 Dependency: Tightly integrated with S3, requiring careful data management.
- No Indexing Support: Though mitigated by data partitioning, the absence of indexing can impact query performance.
- Query Timeouts: Default DDL query timeout is 30 minutes, extendable up to 360 minutes, which may limit complex operations.
- Concurrency Limits: The default DDL concurrency is set at 20, posing potential bottlenecks for parallel processing.
Superset
- Handling Large Datasets: Encounters performance issues with datasets in the billions of rows.
- Feature Set: Lacks advanced features such as version control and multi-user editing capabilities.
- Documentation: The documentation lacks structure and clarity, which can hinder troubleshooting and advanced customization.
Airbyte
- Connector Quality: Variability in the quality and reliability of connectors can affect data integration processes.
- Large Dataset Processing: Similar to Superset, Airbyte may face challenges in processing and syncing extremely large datasets effectively.
Despite these limitations, the selected components of our architecture have been chosen for their overall strengths and alignment with our cost and efficiency objectives. Continuous evaluation and adaptation of our tools and processes will help mitigate these challenges over time.
In our journey to enhance the system’s performance, I have implemented several optimisation techniques that are broadly applicable across big data projects:
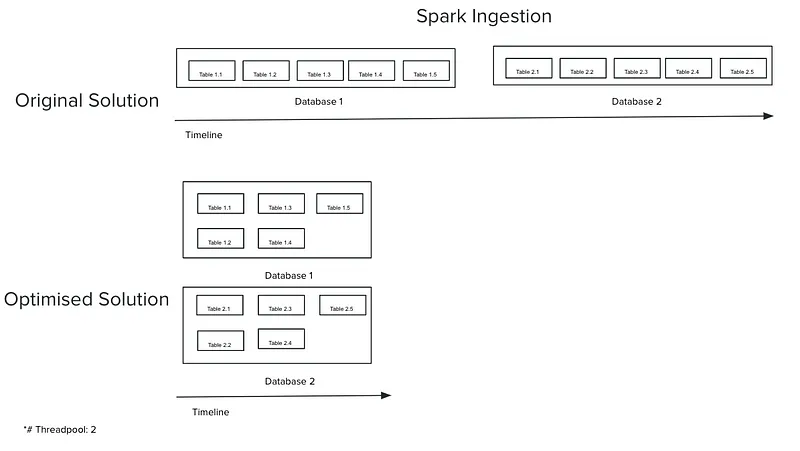
Consider the scenario where we need to ingest data from 2 databases, each containing 5 tables. Initially, it processes data sequentially — one table after another, moving from one database to the next. This approach, while straightforward, was time-intensive.
To address this, we made infrastructural enhancement to allow ofr the parallel running of 2 instances (a configurable parameter), enabling the simultaneous ingestion of data from both databases. Furthermore, at the application layer (using Spark in Scala), I leveraged Scala’s asynchronous non-blocking operations — specifically, the
Future construct—coupled with an execution context. This execution context acts as an abstract layer, representing a thread pool where asynchronous tasks are executed.This optimisation dramatically reduced ingestions times by enabling the simultaneous processing of data.
Sample code to demo the parallel ingestion of tables by using Scala future and execution context.
A critical lever for enhancing our data processing efficiency is optimizing parallel execution within DBT (Data Build Tool). The degree of parallelism DBT employs is governed by the
threads setting within the profiles.yml file. By adjusting this setting to 8, we've significantly increased our capacity for concurrent model execution.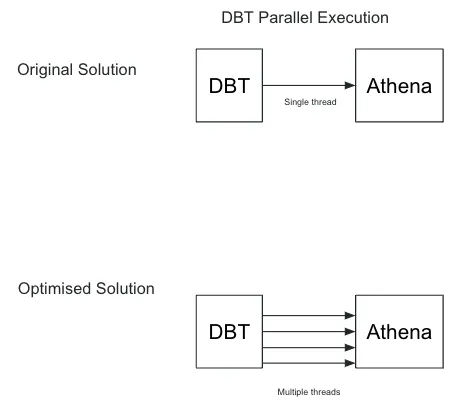
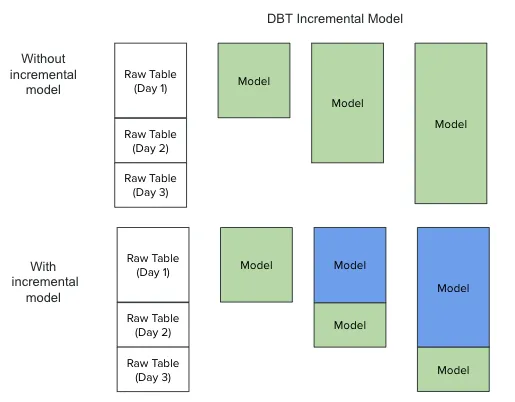
DBT incremental models are a way to efficiently update your data tables by adding or updating only new or changed data, instead of reprocessing the entire dataset from scratch every time you run your models. This method significantly reduces the run time and resource usage for models applied to large datasets or when only a small subset of the data changes frequently.
Initially, our process rebuilds the entire model daily, incorporating both existing data and any incremental changes. With the implementation of incremental models, it now preserves the previous day’s model result (represented as blue boxes) and apply transformation solely to the delta data(the green boxes).
Thanks for your engagement and time spent exploring the insights shared in this article. I hope you found the discussion around cost-effective data architecture solutions both informative and applicable to your work.