How to build RAG Applications that Reduce Hallucinations
How RAG works, why it reduces hallucinations, and how to scale it to your enterprise.
Published Mar 13, 2024
Retrieval Augmented Generation (RAG) is a common approach for creating Generative AI applications that can answer questions or function as a chatbot, in a similar style to ChatGPT, but using your private or custom data.
RAG applications derive answers to user queries by incorporating the strength of pre-trained large language models (LLMs) with a powerful retrieval engine that picks the most relevant contextual text from your data to answer that specific question, as shown in Figure 1 below:
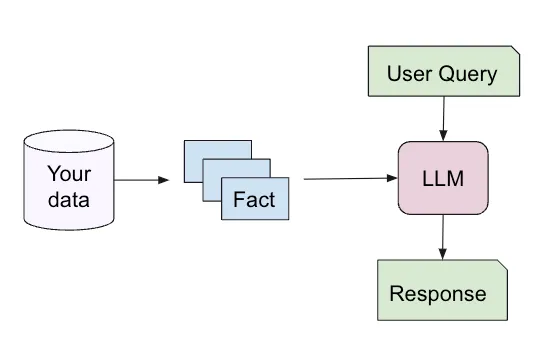
When you ask the LLM to respond to a user query, it usually relies on its original training data for the response. In contrast, with RAG the LLM has additional information available, via the facts retrieved from your data, and the LLM can ground its response in those facts.
When implementing a RAG-based application, two basic concepts must be understood: retrieval (the “R”) and generation (the “G”). Although a lot of attention is often given to the generation part due to the popularity of LLMs, getting the most out of RAG really depends on having the best retrieval engine possible — full stop.
Retrieval is not a new problem either. Google and many others have been working at it for decades and there’s a lot that is known about how to do it right, and where the challenges lie.
For the retrieval part of RAG to work well, one has to carefully consider various steps and design choices for both the ingest flow and the query flow, as shown in Figure 2 below:
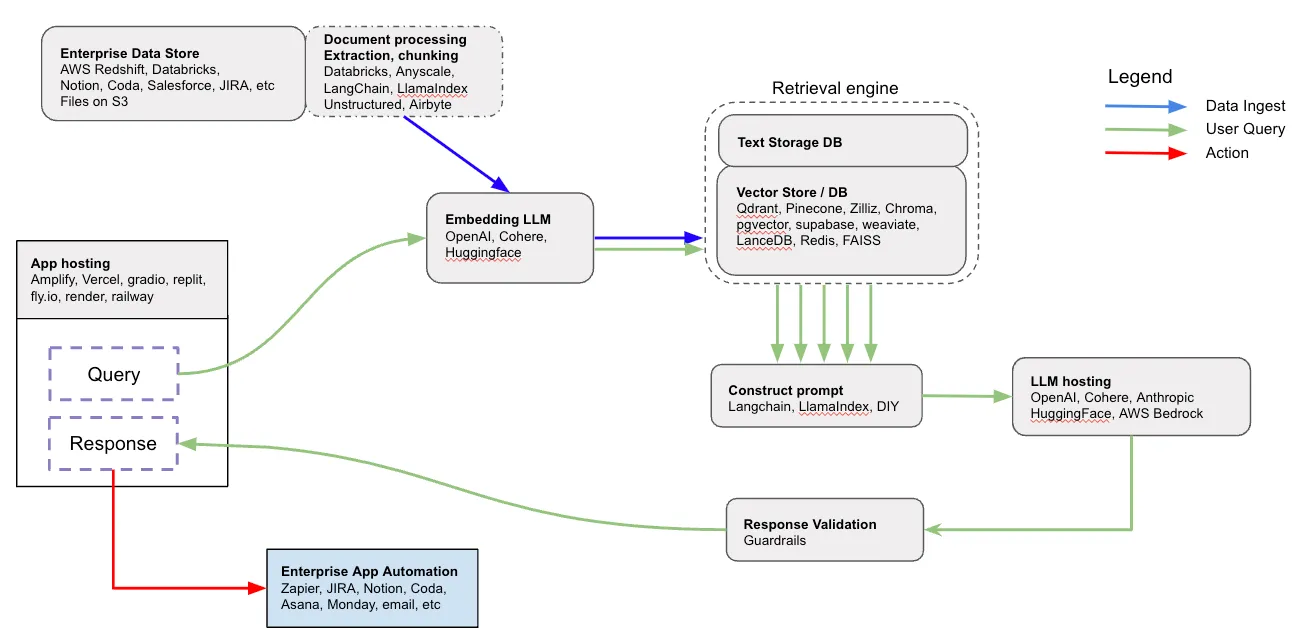
The blue arrows demonstrate the ingest flow, wherein the source data is processed and prepared for querying. This data may originate from any data store like AWS Redshift, Databricks or Snowflake, from an S3 bucket, or can be stored on any SaaS enterprise application.
The first step is to extract text from the input data. When the input includes files (such as PDF, PPT or DOCX files), we need to translate that binary file format into text. If the input comes from a database, the appropriate text is derived from one or more columns in the database.
Once text is extracted from the source data, the text is split into reasonably-sized “chunks” (or segments) that are appropriate for retrieval. These can be just chunks of a certain size (e.g. 1000 characters) or be constructed as individual sentences or paragraphs.
Using an embedding model, we then compute a “vector embedding” representation for each chunk of text and store both the vector and text in a vector database, which allows for efficient semantic retrieval later on.
This process of data ingestion is often performed on dedicated EC2 machines. When you deploy the application for the first time, all data is indexed; from there, regularly scheduled incremental updates provide an efficient mechanism to add new data items or refresh existing data.
The green arrows demonstrate the query flow, whereby a user issues a query, and the RAG application responds based on the most relevant information available in the ingested data.
The first step in the query flow is extracting the most relevant facts related to this query using the retrieval engine. In most cases, this retrieval step uses neural or vector search: the query is encoded using the embedding model, and an approximate nearest neighbor search algorithm is used to retrieve a ranked list of the most relevant chunks of text available in the vector store.
This is where a good retrieval shines: the ability to get relevant facts and only relevant facts depends on many of the choices made during the ingest step like chunking strategy, the embedding model used, and the availability of additional retrieval algorithms like hybrid search (combining vector search with traditional keyword search), and max marginal relevance (aka MMR, which reranks text chunks in a way that emphasizes diversity in results).
With the most relevant facts in hand, a prompt is constructed for the LLM, including the user query and all the pertinent information retrieved. That complete prompt is sent to a generative LLM like OpenAI’s GPT-4, Google’s Gemini, Cohere’s Command, Anthropic Claude or one of the open-source LLMs like Meta’s Llama2. Once a response is generated, it can optionally be sent to a “validation” service (like Nvidia’s Nemo Guardrails), and finally, it can be sent back to the user.
It’s important to highlight another optional step, depicted by the red arrow: the ability to take action based on the response. If the response generated is trusted to be correct (no hallucinations), we can use the response to take action on our behalf - for example, send an email, book a flight or add a task to JIRA. This often involves integration with enterprise/SaaS applications like JIRA, Notion, Asana, or even email or Google Drive.
Much has been said about the tendency of LLMs to hallucinate, the case where the LLM’s response to a user query may seem convincing yet is factually wrong.
Different LLMs have varying degrees of tendency to hallucinate, as is shown in Vectara’s HHEM leaderboard, and using RAG helps reduce hallucinations even further.
Why is that?
The answer lies in understanding that with RAG, we are asking the LLMs to summarize the facts provided in response to the user query. By following our instructions, the LLM’s response is less likely to be a hallucination. This response does not depend on whether the LLM's training set includes the information required to respond correctly to the question.
As an example, let’s ask GPT-3.5 the following: “Did Will Smith ever hit anyone?”
You get the following response: “There have been no public reports or allegations indicating that Will Smith, the actor and musician, has physically assaulted anyone. Smith has had a long and successful career in the entertainment industry, and while he has faced various controversies and challenges throughout his life, there is no evidence to suggest that he has been involved in any physical altercations resulting in harm to others. It's essential to rely on credible sources when discussing sensitive topics like this and to avoid spreading unsubstantiated rumors or false information.”
This is clearly a hallucination. As we all know, there was an incident in the 2022 Oscars where Will Smith struck Chris Rock.
In contrast, if Vectara’s Asknews demo application, implemented as a RAG over recent news articles, the response to the same question is: “Will Smith was involved in a publicized incident at the Academy Awards in 2022 where he slapped Chris Rock on stage. This incident occurred after a joke was made about Smith's wife, Jada Pinkett Smith. However, there is no information in the search results to suggest that Will Smith has physically hit anyone outside of this specific incident. Therefore, based on the provided search results, there is no evidence to suggest that Will Smith has ever hit anyone other than the incident involving Chris Rock at the Academy Awards.”
This response is much better: it notes the one known incident while mentioning that it’s the only known incident.
It’s important to realize that hallucinations often become worse as your dataset size grows. With more data available, it might be more likely for the facts retrieved to be the wrong ones, and having a really state-of-the-art retrieval engine to drive your RAG query flow becomes critical. Vectara’s state of the art embeddings model Boomerang that drives the semantic search engine, combined with advanced retrieval features like Hybrid search and MMR, all optimized to work in concert at large scale ensure hallucinations remain low at any scale with Vectara.
Since the launch of ChatGPT late in 2022, the Do-it-yourself (DIY) approach for building RAG applications has become quite popular, thanks in part to the amazing work in the open source community with projects like LangChain and LlamaIndex, the increasing popularity of vector database products like pinecone, Zilliz, Weaviate, Qdrant and many others, as well as continuous improvements in the core capabilities of LLMs (both open source and commercial).
The tooling around RAG created an environment where builders can put together a simple RAG pipeline on AWS relatively quickly. For example, if you wanted to build a “chat-with-my-PDF” application, you might follow these steps (we picked LangChain for this example, but LlamaIndex is equally capable):
- Ingest:
- Use Langchain’s PdfLoader to extract the text from one or more PDF files on S3
- Apply LangChain’s CharacterSplitter to break down the text into chunks
- Use OpenAI or Cohere to embed the text chunks into vectors
- Store the text and vector embeddings into a vector database. You can use a commercial offering like PineCone or setup your own (e.g. Weaviate) on AWS EC2
- Query:
- Host your Generative AI application front-end on Amplify
- Upon receiving a user request, use LangChain’s vector store retriever to retrieve the most relevant facts for this query
- Use Langchain’s RAG prompt to ask the LLM to respond to the user query given those facts
- Display the response to the user.
Yes, it’s not that hard. That’s why “chat-with-your-pdf” examples became so popular in social media in 2023 - everyone felt empowered to create RAG applications literally in minutes.
However, moving from a working prototype based on just a few PDF files, to a scalable production deployment of a RAG application that provides the best quality over millions of documents in an enterprise setting requires dealing with a lot more complexity.
You want to use the optimal approach for chunking, choose the best embedding model, implement advanced retrieval (like hybrid search or MMR), make sure you have the right prompt, and use the best LLM to summarize the final set of facts. And in many cases, you want this to also work properly in non-English languages. All of this while ensuring data privacy, security, low latency and high availability.
And then there’s ongoing maintenance of this RAG application; how do you update your flow when GPT-5 or Llama3 are launched? How do you integrate a new data source?
Maintaining a functional, robust, and accurate RAG pipeline requires a multi-disciplinary set of skills, including expertise in Machine learning, Information retrieval, MLOps, DevOps/SRE, and even what people now call PromptOps.
Just like Heroku helped developers deploy web applications quickly and efficiently without spending an enormous amount of time and resources on managing the underlying infrastructure, Vectara’s RAG-as-a-service helps developers create and develop RAG applications that are scalable, secure, and provide operational stability, without the need to hire a unique team of experts.
Let’s inspect some of the critical tasks that the Vectara platform handles for you:
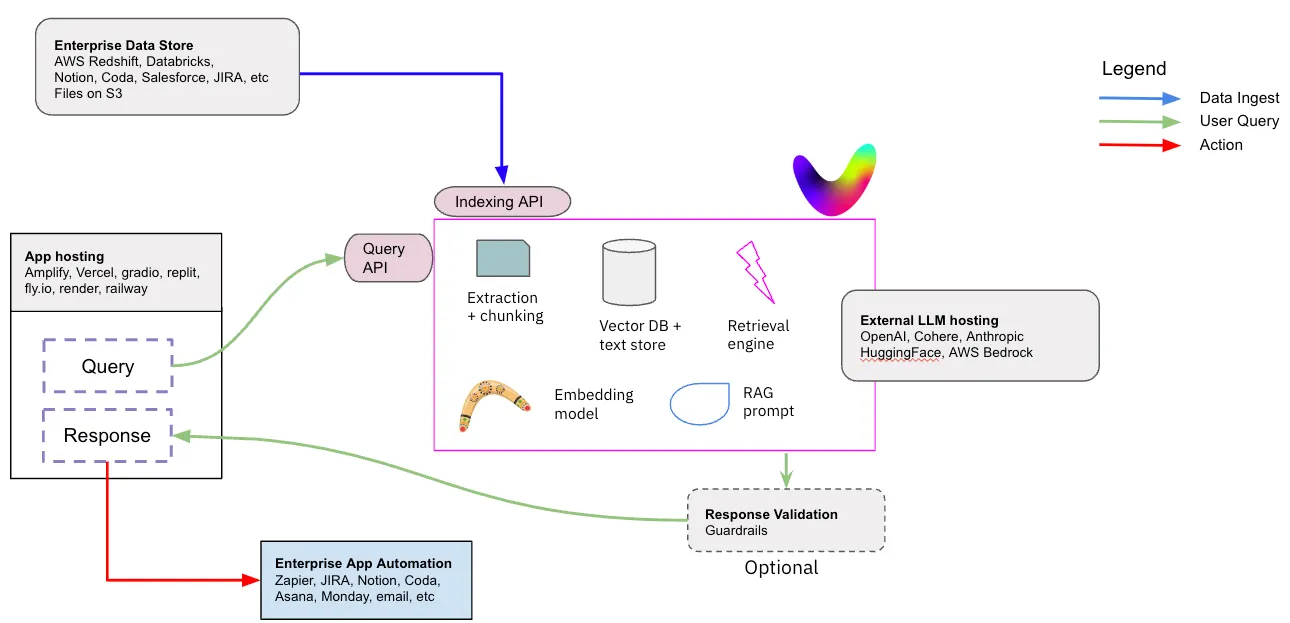
Figure 3: Retrieval Augmented Generation (RAG) as-a-service
Data processing. With Vectara you can upload a file (various file types for ingestion are supported including markdown, PDF, PPT, DOC, HTML and many others), in which case Vectara’s platform extracts the text from the file, or ingest the text directly. In both cases, the text is chunked into sentences, and a vector embedding is computed for each chunk, so you don’t need to call any additional service for that.
Vector and text storage: Vectara hosts and manages its own vector store, where both the embedding vectors and the associated texts are stored. Developers don’t need to go through a long and expensive process of evaluation and choice of vector databases. Nor do they have to worry about setting up that Vector database, managing it in their production environment, re-indexing, and many other DevOps considerations that become important when you scale your application beyond a simple prototype.
Query flow: When issuing a query, encoding the query into an embedding vector and retrieving the resulting text segments (based on similarity match) is fully managed by Vectara. The platform provides a robust implementation of hybrid search and re-ranking, which together with Vectara’s state of the art embedding model (Boomerang) ensures the most relevant text segments are returned in the retrieval step. Vectara then constructs the right prompt to use for the generation step, and calls the generative summarization LLM to return the response to the user’s query. Since all of these steps are performed within a single AWS environment and under full control of Vectara, it is optimized to achieve the fastest response latency for the RAG flow.
Security and Privacy: By relying on security services such as AWS KMS, and the seamless encryption of S3 and EBS, Vectara implemented its API to be fully encrypted in transit and at rest, and with full support for customer-managed-keys (CMK). Using some of the built-in capabilities of AWS, Vectara was able to achieve SOC-2 Type-2 certification and is GDPR compliant.
As the industry moves from “playing around” with RAG to full enterprise implementations, it is starting to become clear why using a platform like Vectara makes sense.
It’s the simplicity and the ease of use.
Total cost of ownership (TCO) for setting up your GenAI applications is also critical. It’s all about making the enterprise deployment economical.
With Vectara, not only do you not need to pay individual LLM providers on a per-token basis (for both embedding model and generative LLM), the infrastructure (AWS servers and services), you also don’t have to hire and keep a team of experts to develop and continuously improve and support your RAG application.
This can reduce your RAG TCO by 5x or more, just in the first year.
Vectara provides a serverless RAG-as-a-service platform for building trusted and scalable GenAI enterprise applications. Whether it’s in legal, financial services, insurance, cybersecurity, retail or any other industry - building RAG applications with Vectara is quick and easy.
As application developers rush to implement RAG applications, they often realize that the do-it-yourself approach is complex and requires a lot of expertise. Serverless RAG-as-a-service platforms like Vectara provide a powerful yet easy-to-use set of APIs that allow developers to focus on building their application, instead of having to specialize in the increasingly complex and constantly evolving set of skills required to build such applications on your own.
Want to experience the ease of use of RAG-as-a-service? It's super easy.
Get started with Vectara on the AWS Marketplace, or sign up for a free Vectara account directly, and get started today.