Auto-Scaling Amazon Kinesis Data Streams Applications on Kubernetes
Learn how to use to automatically scale data processing workloads deployed to Amazon EKS, based on the shard count of AWS Kinesis Stream.
Abhishek Gupta
Amazon Employee
Published Jun 14, 2023
Last Modified Mar 14, 2024
This blog offers a step-by-step guide on how to auto-scale your Kinesis Data Streams consumer applications on Kubernetes, so you can save on costs and improve resource efficiency.
Amazon Kinesis is a platform for real-time data processing, ingestion, and analysis. Kinesis Data Streams is a Serverless streaming data service (part of the Kinesis streaming data platform, along with Kinesis Data Firehose), Kinesis Video Streams, and Kinesis Data Analytics.
Kinesis Data Streams can scale elastically and continuously adapt to changes in data ingestion rates and stream consumption rates. It can be used to build real-time data analytics applications, real-time dashboards, and real-time data pipelines.
Let’s start off with an overview of some key concepts of Kinesis Data Streams.
- A Kinesis data stream is a set of shards. Each shard has a sequence of data records.
- The producers continually push data to Kinesis Data Streams, and the consumers process the data in real time.
- A partition key is used to group data by shard within a stream.
- Kinesis Data Streams segregates the data records belonging to a stream into multiple shards.
- It uses the partition key that is associated with each data record to determine which shard a given data record belongs to.
- Consumers get records from Amazon Kinesis Data Streams, process them and store their results in Amazon DynamoDB, Amazon Redshift, or Amazon S3 etc.
- These consumers are also known as Amazon Kinesis Data Streams Application.
- One of the methods of developing custom consumer applications that can process data from KDS data streams is to use the Kinesis Client Library (
KCL).
The Kinesis Client Library ensures there is a record processor running for every shard and processing data from that shard.
KCL helps you consume and process data from a Kinesis data stream by taking care of many of the complex tasks associated with distributed computing and scalability. It connects to the data stream, enumerates the shards within the data stream and uses leases to coordinates shard associations with its consumer applications.A record processor is instantiated for every shard it manages.
KCL pulls data records from the data stream, pushes the records to the corresponding record processor and checkpoints processed records. More importantly, it balances shard-worker associations (leases) when the worker instance count changes or when the data stream is re-sharded (shards are split or merged). This means that you are able to scale your Kinesis Data Streams application by simply adding more instances since KCL will automatically balance the shards across the instances.But, you still need a way to scale your applications when the load increases. Of course, you could do it manually or build a custom solution to get this done.
This is where Kubernetes Event-driven Autoscaling (KEDA) can help.
KEDA is a Kubernetes-based event-driven autoscaling component that can monitor event sources like Kinesis and scale the underlying Deployments (and Pods) based on the number of events needing to be processed.To witness auto-scaling in action, you will work with a Java application that uses the Kinesis Client Library (
KCL) 2.x to consume data from a Kinesis Data Stream. It will be deployed to a Kubernetes cluster on Amazon EKS and will be scaled automatically using KEDA. The application includes an implementation of the ShardRecordProcessor that processes data from the Kinesis stream and persists it to a DynamoDB table. We will use the AWS CLI to produce data to the Kinesis stream and observe the scaling of the application.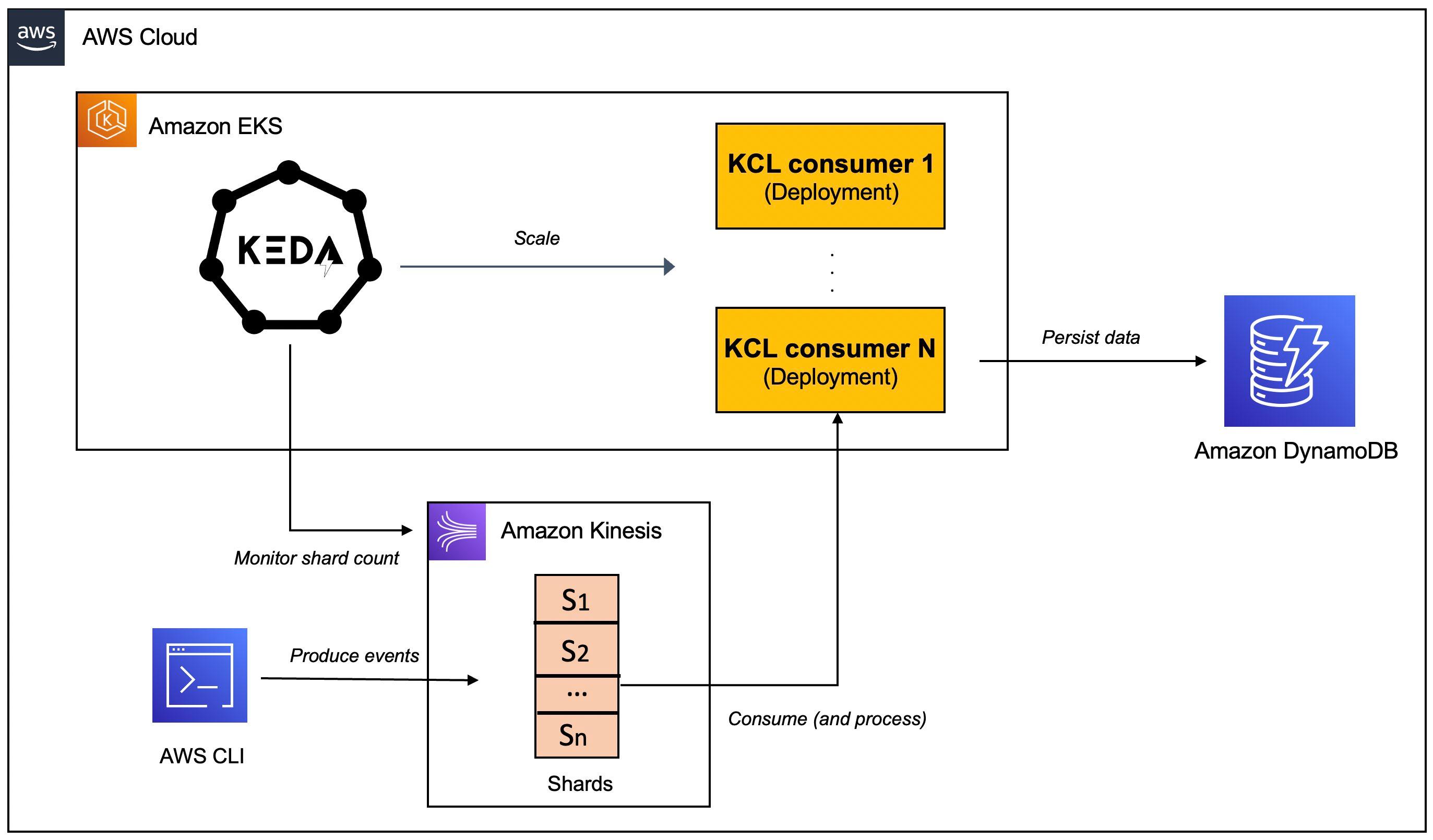
Before, we dive in, here is quick overview of
KEDA.KEDA is an open-source CNCF project that's built on top of native Kubernetes primitives such as the Horizontal Pod Autoscaler and can be added to any Kubernetes cluster. Here is a high level overview of it's key components (you can refer to the KEDA documentation for a deep-dive):- The
keda-operator-metrics-apiservercomponent inKEDAacts as a Kubernetes metrics server that exposes metrics for the Horizontal Pod Autoscaler - A KEDA Scaler integrates with an external system (such as Redis) to fetch these metrics (e.g. length of a List) to drives auto scaling of any container in Kubernetes based on the number of events needing to be processed.
- The role of the
keda-operatorcomponent is to activate and deactivateDeploymenti.e. scale to and from zero.
You will see the Kinesis Stream KEDA scaler in action that scales based on the shard count of AWS Kinesis Stream.
Now lets move on the practical part of this post.
In addition to an AWS account, you will need to have the AWS CLI, kubectl, Docker, Java 11 and Maven installed.
There are a variety of ways in which you can create an Amazon EKS cluster. I prefer using eksctl CLI because of the convenience it offers. Creating an an EKS cluster using
eksctl, can be as easy as this:For details, refer to the Getting started with Amazon EKS – eksctl.
Create a DynamoDB table to persist application data. You can use the AWS CLI to create a table with the following command:
Create Kinesis stream with two shards using the AWS CLI:
Clone this GitHub repository and change to the right directory:
Ok let's get started!
For the purposes of this tutorial, you will use YAML files to deploy
KEDA. But you could also use Helm charts.Install
KEDA:Verify the installation:
The KEDA operator as well as the Kinesis consumer application need to invoke AWS APIs. Since both will run as
Deployments in EKS, we will use IAM Roles for Service Accounts (IRSA) to provide the necessary permissions.In this particular scenario:
KEDAoperator needs to be able to get the shard count for a Kinesis stream - it does so with usingDescribeStreamSummaryAPI.- The application (KCL library to be specific) needs to interact with Kinesis and DynamoDB - it needs a bunch of IAM permissions to do so.
Set your AWS Account ID and OIDC Identity provider as environment variables:
Create a
JSON file with Trusted Entities for the role:Now, create the IAM role and attach the policy (take a look at
policy_kinesis_keda.json file for details):Associate the IAM role and Service Account:
You will need to restart
KEDA operator Deployment for this to take effect:Start by creating a Kubernetes Service Account:
Create a
JSON file with Trusted Entities for the role:Now, create the IAM role and attach the policy (take a look at
policy.json file for details):Associate the IAM role and Service Account:
The core infrastructure is now ready. Let's prepare and deploy the consumer application.
You first need to build the Docker image and push it to Amazon Elastic Container Registry (ECR) (refer to the
Dockerfile for details).Update the
consumer.yaml to include the Docker image you just pushed to ECR. The rest of the manifest remains the same:Create the
Deployment:Now that you've deployed the consumer application, the
KCL library should jump into action. The first thing it will do is create a "control table" in DynamoDB - this should be the same as name of the KCL application (which in this case is kinesis-keda-demo).It might take a few minutes for the initial co-ordination to happen and the table to get created. You can check the logs of the consumer application to track the progress.
Once the lease allocation is complete, check the table and note the
leaseOwner attribute: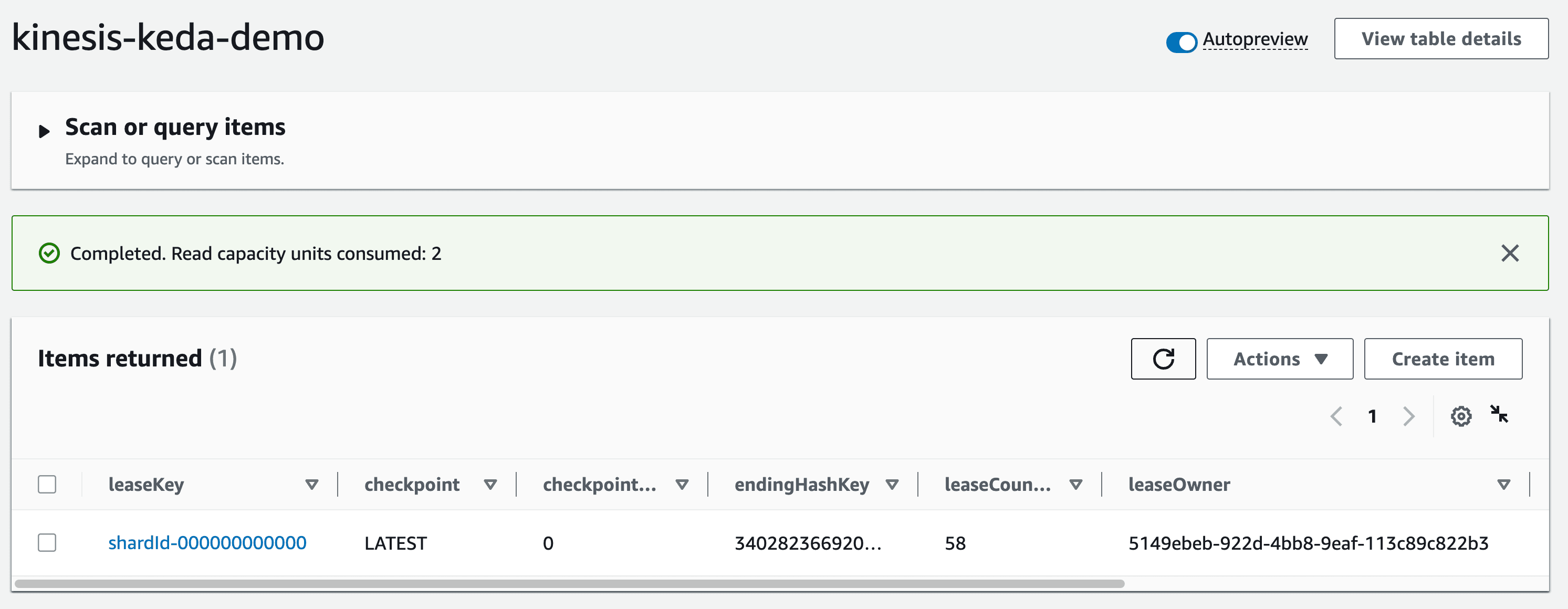
The KCL application persists each record to a target
DynamoDB table (which is named users in this case). You can check the table to verify the records.Notice that the value for the
processed_by attribute? It's the same as KCL consumer Pod. This will make it easier for us to verify the end to end autoscaling process.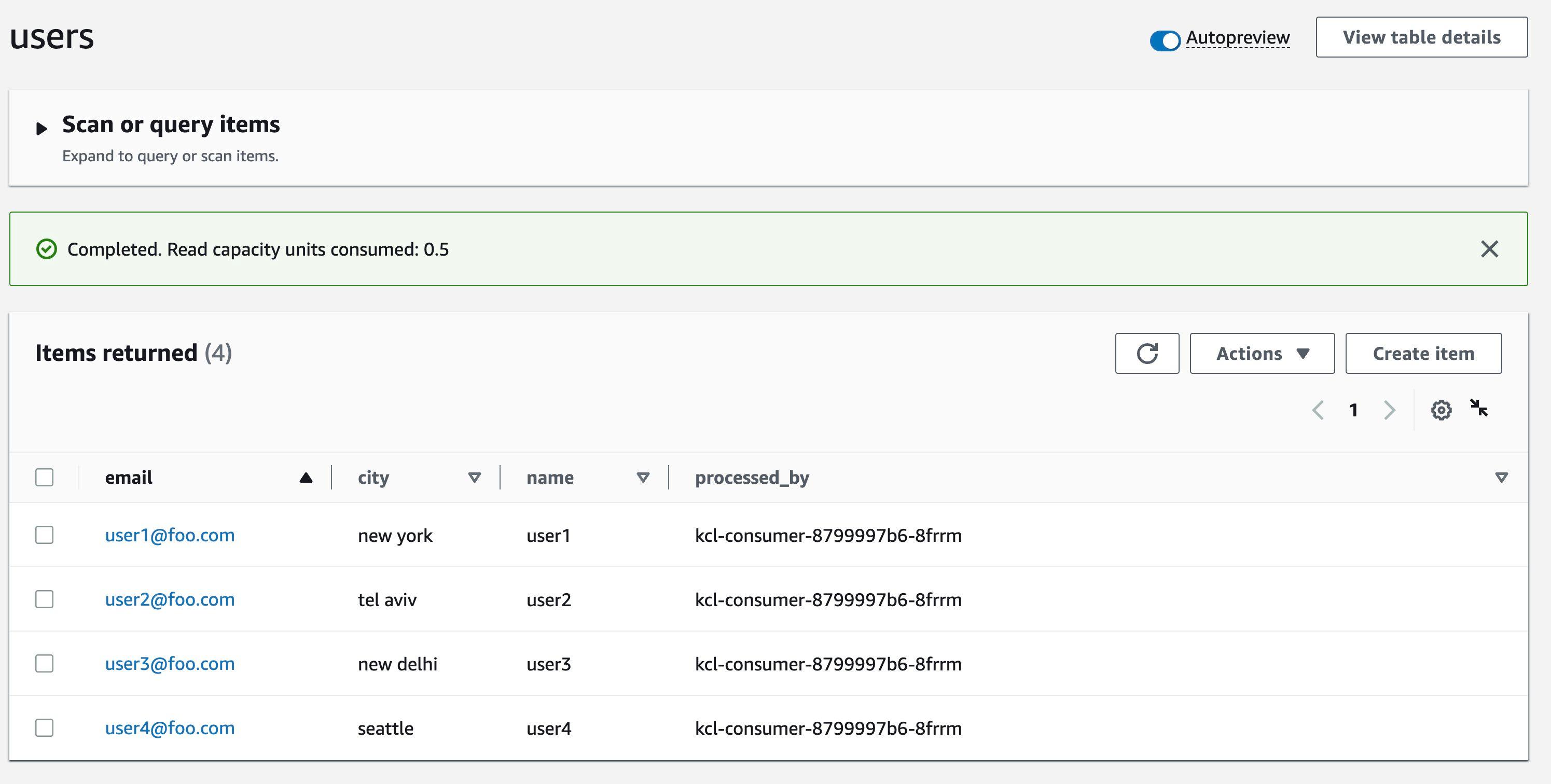
Here is the
ScaledObject definition. Notice that it's targeting the kcl-consumer Deployment (the one we just created) and the shardCount is set to 1:Create the
KEDA Kinesis scaler:We started off with one
Pod of our KCL application. But, thanks to KEDA, we should now see the second Pod coming up.Our application was able to auto-scale to two Pods because we had specified
shardCount: "1" in the ScaledObject definition. This means that there will be one Pod for per shard in the Kinesis stream.Check
kinesis-keda-demo control table in DynamoDB - You should see update for the leaseOwner.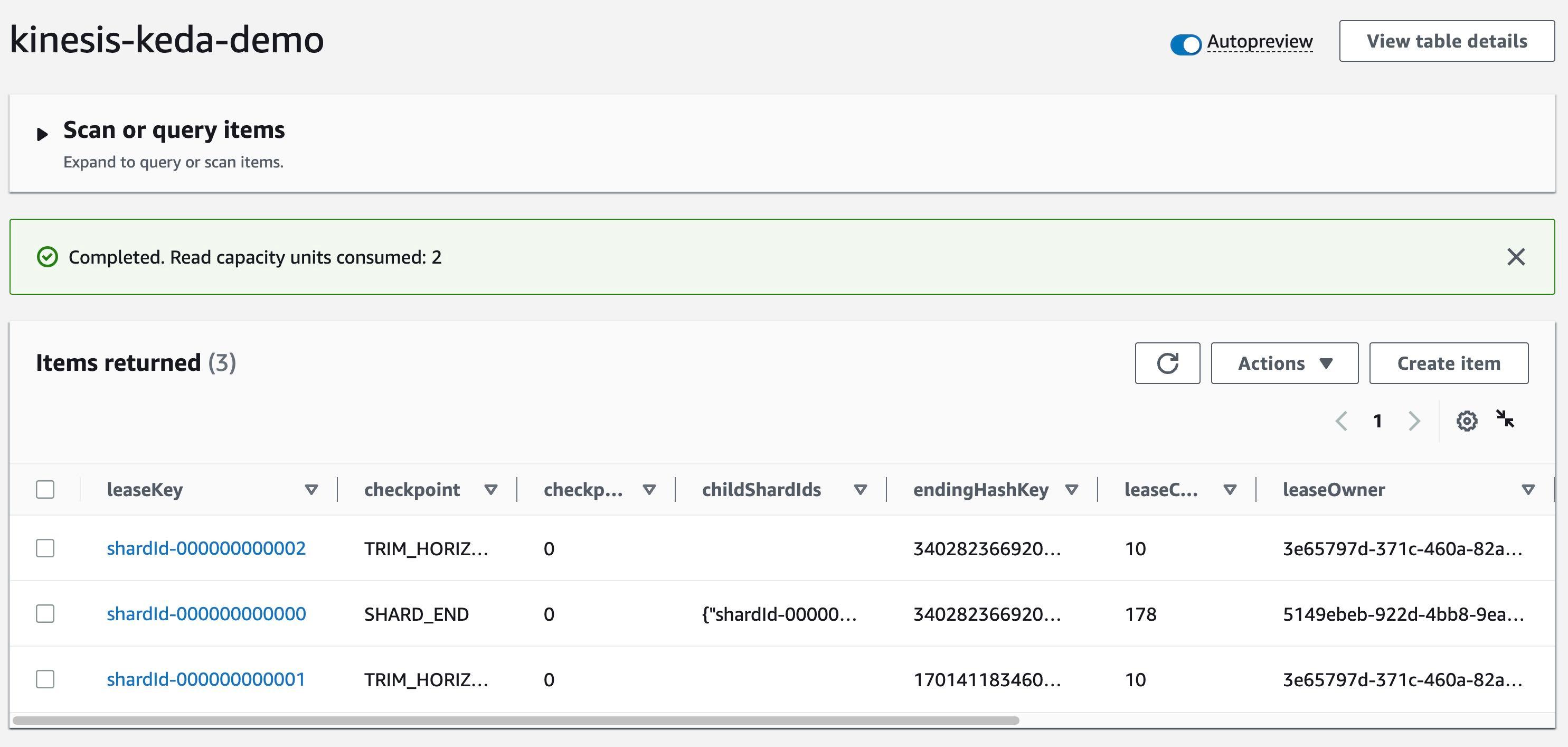
Let's send some more data to the Kinesis stream.
Verify the value for the
processed_by attribute. Since we have scaled out to two Pods, the value should be different for each record since each Pod will process a subset of the records from the Kinesis stream.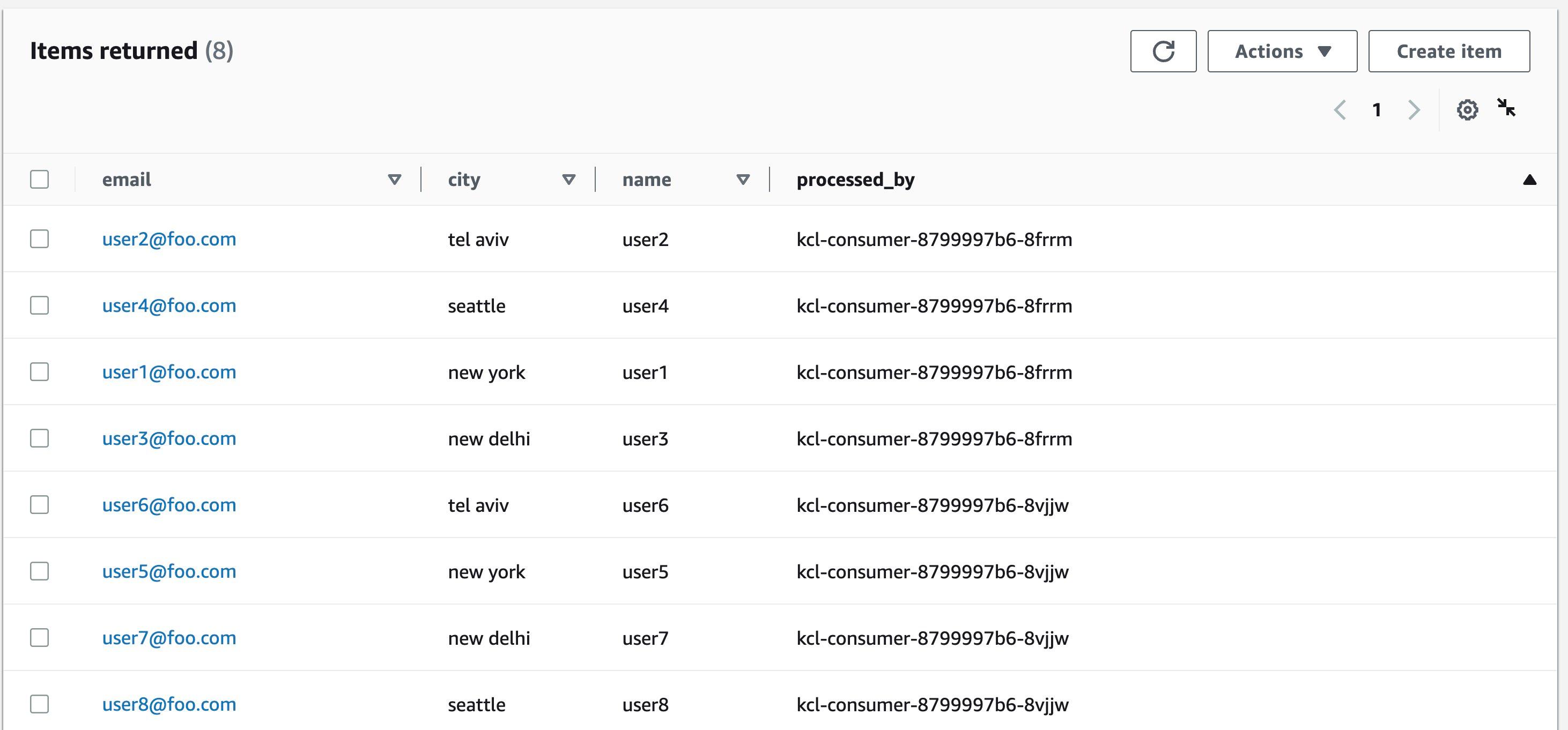
Let's scale out the number of shards from two to three and continue to monitor
KCL application auto-scaling.Once Kinesis re-sharding is complete, the
KEDA scaler will spring into action and scale out the KCL application to three Pods.Just like before, confirm that the Kinesis shard lease has been updated in the
kinesis-keda-demo control table in DynamoDB - check the leaseOwner attribute.Continue to send more data to the Kinesis stream. As expected, the
Pods will share the record processing and this will reflect in the processed_by attribute in the users table.Scale down - So far, we have only scaled in one direction. What happens when we reduce the shard capacity of the Kinesis stream? Try this out for yourself - reduce the shard count from three to two and see what happens to the KCL application.
Once you have verified the end to end solution, you should clean up the resources to avoid incurring any additional charges.
Delete the EKS cluster, Kinesis stream, and DynamoDB table.
In this post, you learned how to use
KEDA to auto-scale a KCL application that consumes data from a Kinesis stream.You can configure the KEDA scaler as per your application requirements. For example, you can set the
shardCount to 3 and have one Pod for every three shards in your Kinesis stream. However, if you want to maintain a one to one mapping, you can set the shardCount to 1 and KCL will take care of distributed co-ordination and lease assignment, thereby ensuring that each Pod has one instance of the record processor. This is an effective approach that allows you to scale out your Kinesis stream processing pipeline to meet the demands of your applications.Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.