Multi-modal Image text validation using Bedrock Claude 3
The post demos a scenario to validate restaurant hours of operation based on image submission time using multi-modal model, Claude 3 on Amazon Bedrock.
Swagat Kulkarni
Amazon Employee
Published Apr 3, 2024
In our previous article, we showcased the utilization of Amazon Rekognition and Amazon Bedrock to address a use case that involved validating the text present in an image. The objective was to determine whether a restaurant was closed or open at a specific time of the day.
In this article, we aim to utilize the recently released Claude 3 model family to perform similar tasks. The Claude 3 model family sets new industry benchmarks across a wide range of cognitive tasks. This family includes three state-of-the-art models with increasing levels of capability: Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus.
Amazon Bedrock offer support for Claude 3 Haiku and Sonnet with support for Opus coming soon at the time of writing this article.
Lets look at a concrete example. The screenshot below shows the chat playground experience within Amazon Bedrock inside AWS console. We have selected Claude 3 Sonnet to test this use case.

Next we open the prompt editor and upload an image which shows the restaurant hours of operation.

And the prompt used as shown here:
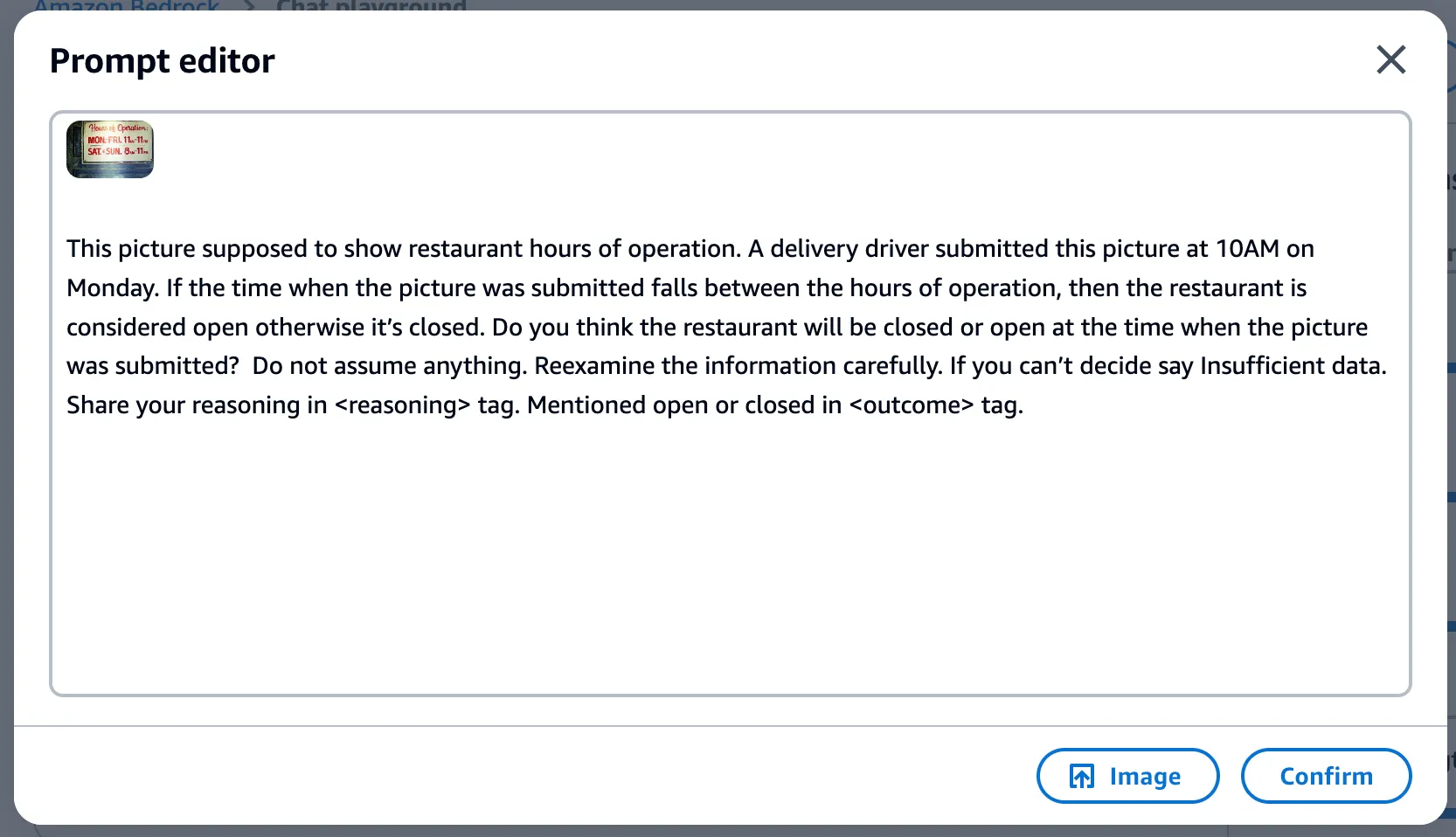
After hitting confirm and run, we get the following response enclosed in the xml tags:
Note that the model was able to detect the text within the image with accurate hours of operation. It was able able to reason based on the time and day of the image submitted and provided an accurate outcome. Furthermore, the prompt specifically asked the model to wrap the responses in xml tags which improves readability and makes it convenient to programmatically process the output response.
In another example, we passed the following image which had no hours of operation in it. The picture only shows the name of the restaurant.

Using the same prompt, the model responded with the following output:
The model accurately detected the absence of relevant data to determine whether the restaurant is open or closed, and came back with an outcome stating insufficient data as instructed in the prompt.
When testing with Claude 3 Haiku, the responses were not sufficiently accurate and exhibited hallucination (generating fictional or factually incorrect information) when using the same prompt. However, after switching to the more capable Claude 3 Sonnet model, no hallucinations were observed in the responses.
In this post, we demonstrated the power of multi-modal models to solve for complex use cases which require reasoning capabilities. It's important to note that the outcome will depend on the clarity of the prompt. It's important for the prompt to be precise, with clear and unambiguous instructions that will result in accurate responses from the models.
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.