Rethinking AI Agents: Why a Simple Router May Be All You Need
Using an LLM as a router vs. an agent to reduce latency.
Tanner McRae
Amazon Employee
Published Mar 19, 2024
Last Modified Mar 22, 2024
Photo by José Martín Ramírez Carrasco on Unsplash
AI Agents have been hot topic first started with the hype around AutoGPT and BabyAGI. From these projects, a wave of new tools emerged promising to simplify how we build applications with Large Language Models (LLMs). By far the most common one I hear about is LangChain and specifically LangChain agents.
While LangChain agents offer great out of the box features, in many use cases you don’t actually need an agent. You just need a router that decides which part of your code to call. In essence, this becomes a simple classification problem, not an agent problem.
In this post, I’ll provide a background on how agents work, some side effects of using agents, and define a simple software pattern that can used in lieu of agents for many common use cases.
In this section, we’ll go over the basics of how a LangChain agent works.
The idea behind agents is the use of an LLM as a reasoning engine to decide which actions to take so that a task can be completed. An agent uses tools to augment it’s capabilities in order to complete these tasks. As an example, if the agent needs to google something, you could provide a search engine (SERP) tool to call Google and return the results back to the agent.
There are multiple types of agents, but in this blog we’ll focus on ReACT (reason+act) based agents. With ReACT, an LLM is given a prompt describing tools it has access to and a scratch pad for dumping intermediate step results.
ReACT is inspired by human abilities to “reason” and “act” to complete tasks. LangChain ReACT agents are a wrapper around those concepts.
Let’s use the example image from the ReAct paper: Synergizing Reasoning and Acting in Language Models
Source: Yao et al., 2022
When a tool is used, the response is dumped into the {agent_scratchpad}. The LLM will be called continuously to create observations and thoughts. When the model determines it has enough information to respond to the user, it returns.
Agents using ReACT can sometimes make a large number of calls to answer a single question, accumulating tokens for each one. Not only is this costly, it introduces latency. Most (but not all) of the latency in LLM based applications come from generating output tokens. By calling an LLM repeatedly and asking it to provide thoughts / observations, it generates a lot of output tokens (cost) which results in high latency (degraded user experience).
LLMs are non-deterministic. While beneficial for creativity, this poses challenges in scenarios that require predictability. For example, if you’re writing an LLM backed chat application to make Postgres queries (Text2SQL), you want high predictability.
Takeaways
In order to make a solution performant (fast) and more consistent (deterministic), tweaks to the code architecture should be made.
In order to make a solution performant (fast) and more consistent (deterministic), tweaks to the code architecture should be made.
The solution presented is a software pattern that can reduce latency and force more deterministic outcomes while still getting value from LLMs in your application.
We will remove the dependency on LangChain agents and restructure the problem as a simple classification problem. We’ll use the LLM as a classifier where the input is our users request and the output is the name of the function to call. The path itself will return directly to the user in order to avoid extra calls to the LLM.
This would be analogous to giving an agent a bunch of tools to use and then having the tools short circuit and return directly to the user.
I’ll introduce 3 concepts which make this possible.
Using a router as the entry point into your application eliminates multiple steps in your agent. Referring back to the “how do agents work?” section, you can see that a typical ReACT agent does three things. (1) It selects a tool that’s useful for completing a task, (2) dumps the output of the tool into a scratchpad, and (3) reasons about whether it has the information needed to respond to the user. Steps 2 and 3 often repeat which we don’t want.
In some use cases, you don’t need to do steps 2 and 3. You just need the model to select which function to use.
Below is a diagram of what a routing layer might look like.
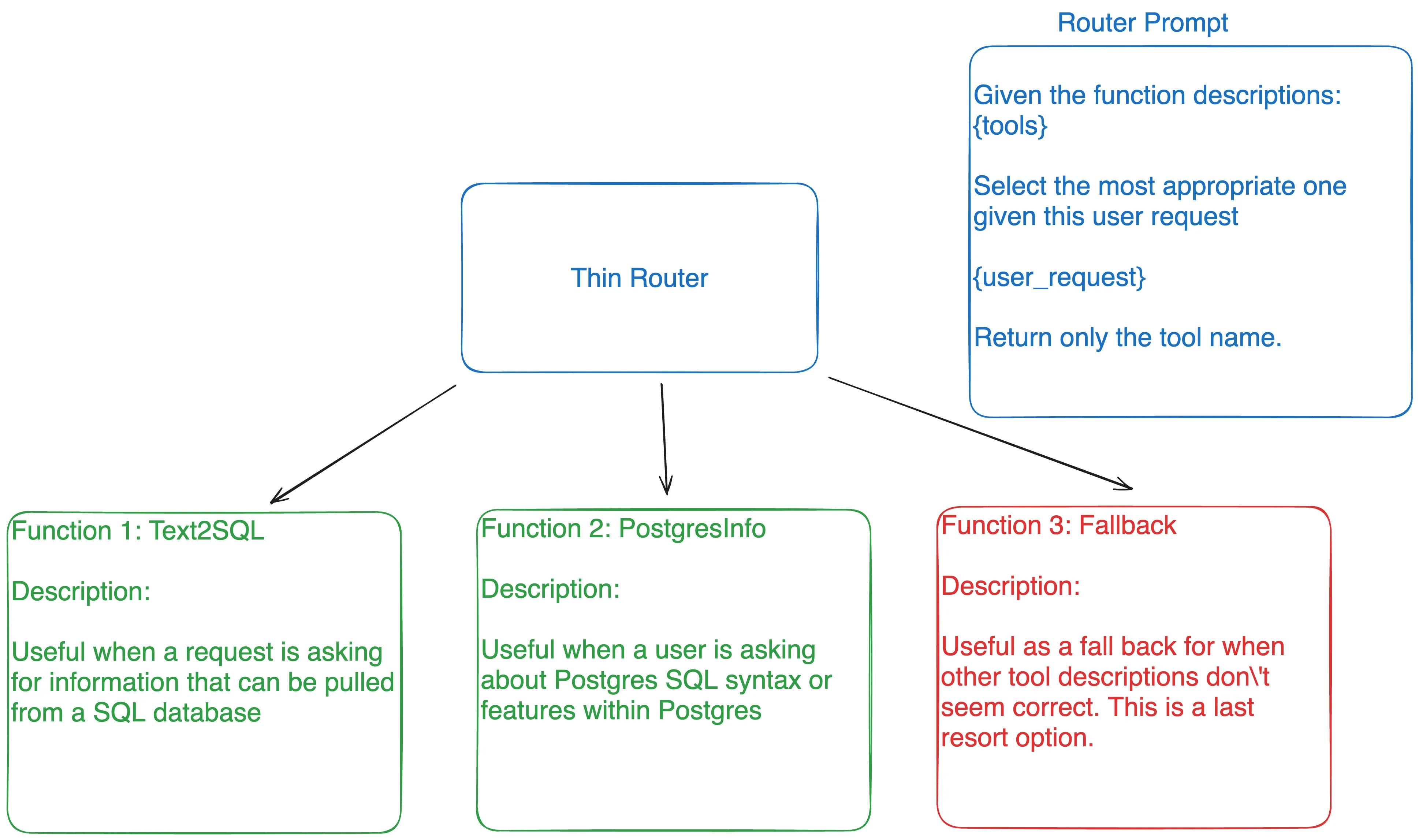
Latency is greatly affected by the number of output tokens the model generates. The router above is only returning a tool name which is ~3 tokens. Using the ReACT agent can produce up to 50+ tokens per call.
As a thought experiment, lets assume you can get 10 tokens per second from a model. Using a thin router and reducing the output tokens from 50 to 3 would take your response from 5 seconds down to ~300ms.
Note: There are a lot of great open source fine tuned LLMs that are purpose built for “function calling”. These make great routers, but you have to host them yourself. For a simple POC, it’s much cheaper to call an LLM from Bedrock. Models like Functionary and FireFunction are also great options as a router.
Most tool implementations are simple. A tool might make a single call to an API and format the response. In agents, decisions of what actions to take and in what order are driven by the LLM itself.
Often, we already know what actions to take and in what order to do them. For these types of use cases, we can define the actions in code and have our router select which function / tool to run. Executing code in memory is much faster than calling an LLM.
Let’s take the example of writing a sql query and returning the results to the user. To do this we take 4 actions. (1) Pull the relevant table definitions to provide context to our LLM, (2) generate a SQL query from the users input, (3) validate the query, and (4) execute the query to return.
Below is a sequence diagram for a theoretical Text2SQL tool/function:
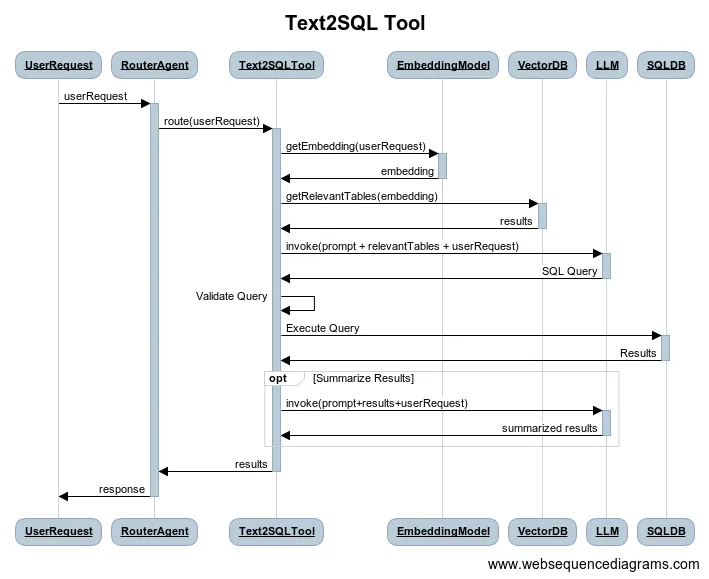
In the example above, we’re forcing determinism through code and only using the LLM to route to our function and to write a SQL query.
An additional benefit from this approach is that we can use a smaller model. Larger models are necessary when performing complex reasoning (i.e. functioning as an agent). By decomposing the tasks into singular asks, we can use smaller / faster models like Claude Haiku or even a fine tuned 7b parameter model.
Not only are smaller models still very capable, they’re faster and cheaper.
When designing a system using a thin router and predefined functions, encapsulation within code is important. The router and the functions need access to context of the request like the users access role and even chat history.
In the following section, I’ll demonstrate how all these ideas can fit together into a simple flask application to create a Text2SQL application.
Below you can find code for our software architecture pattern.
Note: I’ve left out the implementation of the tools invoke() functions. This code was written to show readers what the pattern looks like in Python code.
Define our functions (tools)
First we define an abstract class that our tool classes can implement.
First we define an abstract class that our tool classes can implement.
Define our Router
In this section we’ll instantiate our tools inside the constructor of the router. This will allow us to encapsulate the request context into the tools themselves. Having user_id and org_id as an example is necessary when querying against a multi-tenant DB.
In this section we’ll instantiate our tools inside the constructor of the router. This will allow us to encapsulate the request context into the tools themselves. Having user_id and org_id as an example is necessary when querying against a multi-tenant DB.
Define a simple flask app
Lastly, lets use our router agent in a simple flask application. Notice how we instantiate the SimpleRouterAgent during every call. This allows us to encapsulate the context and pass it down into the custom tools.
Lastly, lets use our router agent in a simple flask application. Notice how we instantiate the SimpleRouterAgent during every call. This allows us to encapsulate the context and pass it down into the custom tools.
And that's it!
By using a thin router as the entry point into your LLM application, you can easily extend the agent to do even more complex things. I’ve outlined a couple things below
Because our router is simply routing to the correct tool, we can define an agent as a tool. If you have a valid use case for a ReACT based agent, there’s nothing stopping you from defining that agent as a tool that the router can call.
In many cases, you can mask the latency of user facing LLM applications by outputting intermediate steps letting the user know what’s happening. Typically chat based applications use server sent events (SSE) to stream the responses back to users. You can pass the stream to each object so that if intermediate step information can be sent to the user interface so the user knows what’s happening.
Note: You can use LangChain’s CallbackManager for this or write it yourself. The important part is that the response stream is available to write to when performing these steps.
LangChain and other frameworks aim to abstract away most of the complexity involved in building LLM applications. However, you can get greater flexibility and performance by writing the core business logic with custom code while mix-and-matching parts of these agent frameworks to do the undifferentiated heavy lifting (like creating chains or handling memory).
As always thank you for reading and feel free to leave any feedback.
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.