How Fazz Financial Group reduced MTTR for production failures with Generative AI
In this blog post, we will share about our innovation journey with GenAI through deliberate training, enablement, collaboration and rapid prototyping.
Glendon Thaiw
Amazon Employee
Published Mar 22, 2024
Last Modified Mar 24, 2024
Co-authored by Fazz Financial Group & Amazon Web Services (AWS)
With revolutionary advancements and mind-bending demos hitting the market every couple of weeks, the popularity of GenAI seems to be at its all time high. Despite the hype, the value of GenAI is quickly being recognised by the toughest skeptics - with Startups to Enterprises experimenting to build different GenAI prototypes & use-cases.
At Fazz Financial Group, we wanted to see how Generative AI can be used for us to strengthen our product portfolio, refine internal processes, and ultimately - help us better serve our customers.
In this blog post, we will share more about the journey we took to get our Engineering, Product Management and Data teams up-skilled with GenAI, and an interesting approach we used to come up with relevant GenAI use-cases that works best for us. Finally, we'd share how we brought some of these use-cases into production, with the help of our friends at Amazon Web Services (AWS).
As a bonus - we’d dive deep into a top GenAI project we managed to built, and discuss how it brings the potential to help our on-call Engineers reduce our Mean Time To Resolve (MTTR) for production failures.
Read on to find out more!
Fazz is a digital financial services group on a mission to make finance fair and inclusive for businesses in Southeast Asia. Started as a YC-backed company in 2016, we empower micro and small businesses in Indonesia by offering affordable payment services.
We've now expanded our mission to serve underserved businesses in Southeast Asia, providing easy access to essential financial services, including payments, savings, and loans. Our group owns the following brands: (1) Fazz Agen (Financial Agent Network) and (2) Fazz Business (Lending and Neobank) and (3) StraitsX (Payments infrastructure for digital assets).
As an Engineering-first company, we are constantly on the hunt for emerging tech that can help make our lives easier or build innovative features for customers. With the recent wave of GenAI, we knew we had to take a deeper look.
We approached some of our Engineers across different product teams to look into GenAI, and play around with different prototypes they can build.
Ideas were thrown around...
Scrapy proof-of-concepts were being duct-taped together...
But after months, we didn’t have anything concrete. We realised we needed a better approach
That’s where we decided to reach out to our good friends at AWS.
Ever since the early startup days in 2016, AWS has been our primary cloud service provider, and we have enjoyed great partnerships with our account teams. We decided to approach them with our endeavour.
Through discussions with relevant GenAI, product and industry experts at AWS, we identified that our progress to build GenAI capabilities was stalled as a result of 3 main gaps.
- (1): GenAI knowledge gaps
- While our Engineers, Product Managers and Data Analysts have some interest in GenAI, they are not familiar with the underlying technology or basic building blocks they can use to build GenAI use-cases.
- (2): Unclear ROI of GenAI use-cases
- While ideas were being thrown around and our builders have been researching popular GenAI reference projects, it remains unclear which use-case would actually carry tangible ROI for our unique business.
- (3) Lack of structured path to build & deploy GenAI apps
- Finally, while our builders are strong in shipping technical services - it’s not apparent if we can stick to the same processes with GenAI features. What do we do if LLMs start to hallucinate? How can we set up guardrails? The path to take GenAI projects to production remains unclear.
We decided to tackle these challenges head-on.
Custom GenAI Training & Enablement curriculum
Partnering with relevant teams at AWS, we sat down and co-developed a custom GenAI Training & Enablement curriculum tailored for our very own needs. We worked backwards from identified gaps, and designed 4 technical workshops focused on equipping our builders with core GenAI knowledge and hands-on expertise to build GenAI use-cases on AWS. This involves sessions around GenAI for Financial Services, GenAI security and GenAI Product Management - things we care deeply about.
Partnering with relevant teams at AWS, we sat down and co-developed a custom GenAI Training & Enablement curriculum tailored for our very own needs. We worked backwards from identified gaps, and designed 4 technical workshops focused on equipping our builders with core GenAI knowledge and hands-on expertise to build GenAI use-cases on AWS. This involves sessions around GenAI for Financial Services, GenAI security and GenAI Product Management - things we care deeply about.
We then mobilised over 140+ Engineers, Product Managers and Data Engineers across our product tribes to attend these workshops as our way to sharpen the saw, and remain adaptable during rapid changes in tech.
GenAI Hackathon!
Following which, here comes the fun part! We then gave our builders an opportunity to apply their new-found skills through an internal hackathon. Focusing on developing GenAI use-cases to influence our roadmap, we got our Engineers, Product Managers and Data Engineers in one room - and have them ideate and build prototypes to solve day-to-day challenges using GenAI.
During the 24-hour hackathon, our teams built 10 prototypes using AWS GenAI services from SageMaker Jumpstart, Bedrock and Amazon Q. The event also gave us an opportunity to connect our regionally-dispersed teams across Singapore, Jakarta and Taiwan through a fun and interactive technical collaboration.
Following which, here comes the fun part! We then gave our builders an opportunity to apply their new-found skills through an internal hackathon. Focusing on developing GenAI use-cases to influence our roadmap, we got our Engineers, Product Managers and Data Engineers in one room - and have them ideate and build prototypes to solve day-to-day challenges using GenAI.
During the 24-hour hackathon, our teams built 10 prototypes using AWS GenAI services from SageMaker Jumpstart, Bedrock and Amazon Q. The event also gave us an opportunity to connect our regionally-dispersed teams across Singapore, Jakarta and Taiwan through a fun and interactive technical collaboration.

We were really impressed with the creative prototypes surfaced through the way they addressed our real-world business challenges - whether it was to streamline internal processes or delight our customers. In the following section, we will showcase one of these projects - where we built an internal tool to drastically reduce our Mean Time To Resolve (MTTR) for production failures using Generative AI.
We will walk you through our inspiration for the use-case, and how our builders came together to take it from ideation to production.
Read on!
At Fazz, we manage our on-call duties through a rotation system, using an open-source tool called GoAlert for scheduling, automated escalations and notifications.
As with many other customer-facing products, the time it takes to recover from incidents (otherwise known as Mean Time To Resolve or MTTR) is crucial to minimise impact to users for a great customer experience.
Reviewing past incident reports, we noticed that a significant contributor to our MTTR is the time Engineers would take to gather information across multiple data sources to form the right context to come up with a proposed resolution.
This makes intuitive sense. With our on-call team dealing with numerous components across multiple systems, gathering the right relevant information needed to address issues is a huge challenge.
So, how can we make sure our Engineers get the right context they need, fast?
This was what we set out to tackle with the power of Generative AI.
We started with a 360 review of our incident management system. At the end of each incident, our on-call Engineers conducts After Action Reviews (AARs) and documents key findings in Notion. At the same time, we also set up dedicated channels on Slack to facilitate real-time discussions among Engineers during root cause analyses. Finally, issues are stored and tracked using our issue management software - JIRA.
From these practices emerged the idea for the AI Storm Surge Agent.
The agent first taps into our various data sources (Notion documents, JIRA issues, Slack messages) and consolidates all relevant information regarding an incident. Based on the issue faced, it distills vital context and presents suggestions to our on-call Engineers in real-time - making incident resolution faster and more efficient.
Picture this: you’re on call, and an incident unfolds.
You’re figuring out where to start, because there are so many things that could be the cause.
The AI Storm Surge agent instantly gathers relevant information across all your company’s records.
It's like having a personal assistant who quickly goes through all your notes, chats, and updates to tell you, "Hey, look here first." On top of presenting information, it guides you towards performing a root cause analysis.
You’d interact with the agent like you would with a teammate. It helps make sense of the complexity and provides you with actionable next steps.
Dealing with on-call escalations no longer have to be a nerve-wrecking experience.
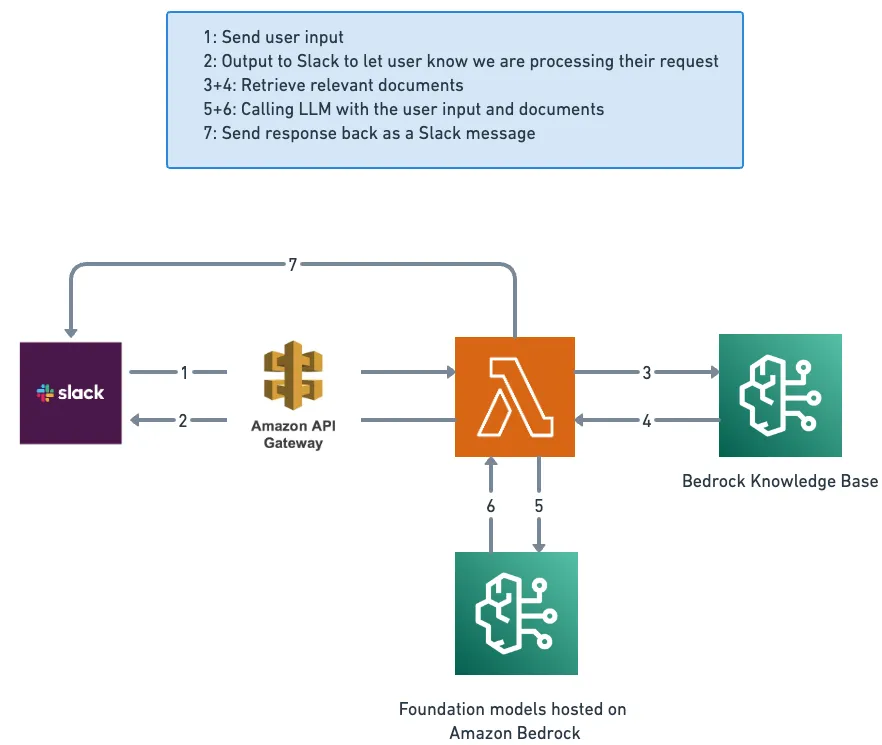
Our architecture has 4 main components:
- Slack acting as our user interface
- AWS Lambda for Serverless hosting of our code
- Amazon Bedrock Knowledge Base to store and retrieve our data sources
- Foundational models hosted on Amazon Bedrock for understanding and processing natural language
Our team understood the importance of demonstrating a working prototype at the end of the hackathon. Given that we had only one day, we chose technologies that facilitated rapid prototyping while still preserving the core essence of what we wanted to showcase.
You can have a powerful large language model operating behind the scenes, but if the user interface isn't intuitive, users will not fall in love with the product.
A Slack bot was the perfect interface because we were already using Slack extensively, especially during incidents.
Our team utilised Slack's API to download past messages from incident channels so we could analyse them and ingest the data into Bedrock. We also retrieved the most recent messages to grasp the context of the current incident, and relayed the context to the foundational model for further analysis.
Once we receive a response, the bot directly replies with suggested resolution steps in the incident channel.
Since Slack operates outside the AWS ecosystem, we required a deployment environment that could be accessed externally to run our operations. We chose AWS API Gateway and AWS Lambda for this task.
In the Lambda function, we use Python version 3.10, following the example provided by AWS's matching Jupyter notebook, which allowed us to easily replicate the Jupyter notebook environment. This lambda execution environment was then exposed through an API Gateway integration. This allows us to configure an authentication mechanism between API Gateway and Slack to ensure authorised communication with our Slack interface.
We encountered an issue during implementation - Slack expects a response within 300 milliseconds, and this parameter is not adjustable. To circumvent this, we leveraged the asynchronous invocation mode of AWS Lambda to be able to return a response immediately to Slack, while allowing our language model to complete processing asynchronously.
Language Models
Building on Amazon Bedrock allows us to tap on on different first-party (E.g. Amazon Titan) and third-party language models (E.g. Anthropic Claude) using the same data platform. This allows us to build a single GenAI platform, yet constantly adapt the best model for our use-case at different points in time. Given the rapid pace of development in GenAI and foundation models, this helps us build longevity into our GenAI stack going forward.
Building on Amazon Bedrock allows us to tap on on different first-party (E.g. Amazon Titan) and third-party language models (E.g. Anthropic Claude) using the same data platform. This allows us to build a single GenAI platform, yet constantly adapt the best model for our use-case at different points in time. Given the rapid pace of development in GenAI and foundation models, this helps us build longevity into our GenAI stack going forward.
Retrieval-Augmented Generation
Using Amazon Bedrock's Knowledge Base has been a key part of adopting Retrieval Augmented Generation (RAG). This ready-made tool makes it easy to save and find our data. After we upload our documents, it turns them into text, breaks them into pieces that overlap enough, changes them into vector forms, and keeps them in a database. When we need to get our data back, we can simply use a Python function to call the API and get the most relevant information related to our question.
Using Amazon Bedrock's Knowledge Base has been a key part of adopting Retrieval Augmented Generation (RAG). This ready-made tool makes it easy to save and find our data. After we upload our documents, it turns them into text, breaks them into pieces that overlap enough, changes them into vector forms, and keeps them in a database. When we need to get our data back, we can simply use a Python function to call the API and get the most relevant information related to our question.
We downloaded the entire list of past incident reports from our Notion database, which amounted to only ~3 MB of data, and uploaded the data onto the Knowledge Base.
Prompt Engineering
Prompt Engineering was necessary to incorporate the context obtained from RAG into the prompt and to enhance the response quality. For our use case, it was crucial that the response was coherent and easy to read. Therefore, we added the following instructions to the prompt: “think step-by-step,” “write in a conversational tone,” and “keep your replies concise.”
Prompt Engineering was necessary to incorporate the context obtained from RAG into the prompt and to enhance the response quality. For our use case, it was crucial that the response was coherent and easy to read. Therefore, we added the following instructions to the prompt: “think step-by-step,” “write in a conversational tone,” and “keep your replies concise.”
The end result was a slack bot that can be triggered from any incident channel. The bot then responds with suggestions of potential causes and solutions.
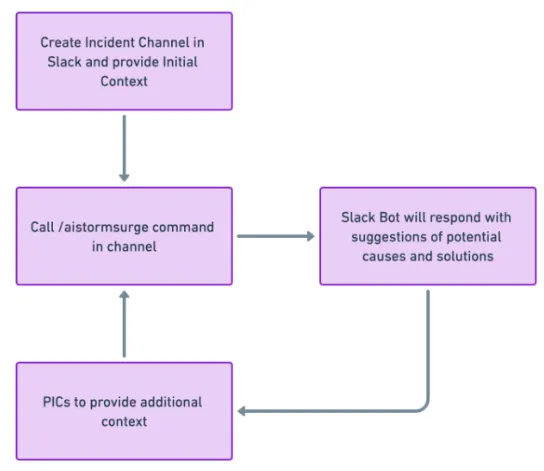
As the conversation progresses, the bot is able to take in the additional information, revise its context, and provide updated responses.
Here’s how it looks like when an incident occurs!
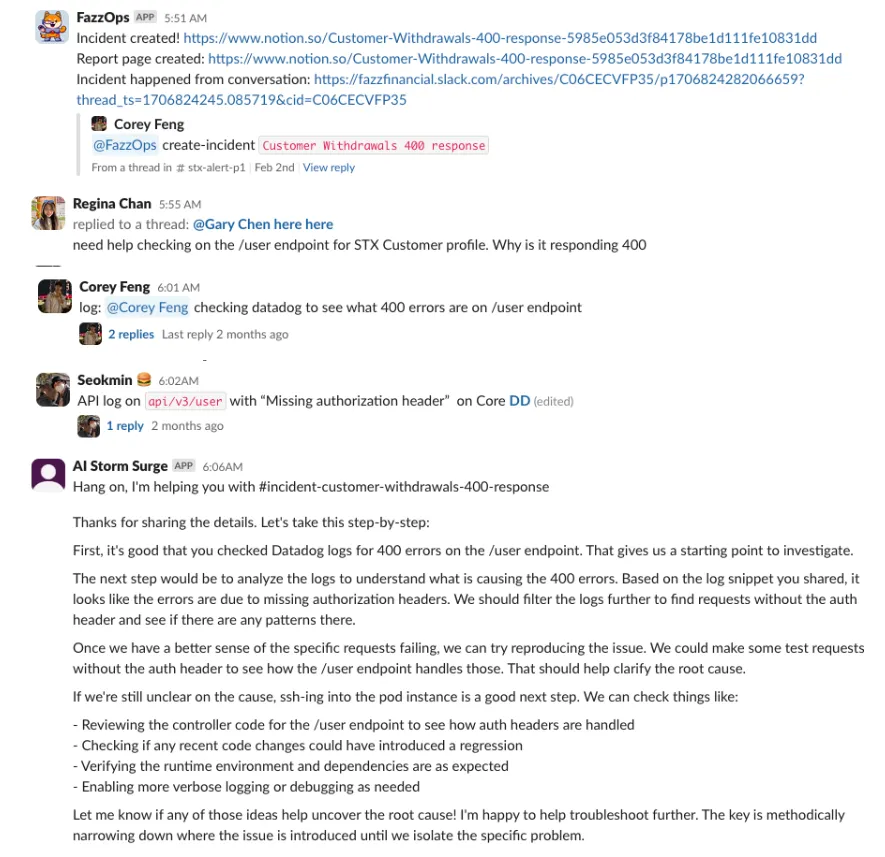
Thoughts about Generative AI
Truth be told, I used to think GenAI and machine learning was complex and out of reach, not really related to my daily responsibilities. But participating in the training, workshops, and hackathon showed me how advanced and user-friendly Gen AI technology is. Now I see that you don't need to be an expert to use it to create new and exciting services and products. It's truly impressive how much GenAI can do.
Truth be told, I used to think GenAI and machine learning was complex and out of reach, not really related to my daily responsibilities. But participating in the training, workshops, and hackathon showed me how advanced and user-friendly Gen AI technology is. Now I see that you don't need to be an expert to use it to create new and exciting services and products. It's truly impressive how much GenAI can do.
Looking back, I realize that GenAI is more than just a tool for creating new things; it's a powerful force that's pushing our company, Fazz, forward in the fintech world. It can do a lot for finance, like making fraud detection better, improving how we manage risks, making customer service better, and making our own work more efficient. By getting into GenAI, we're staying ahead in tech, opening up all sorts of possibilities to do even more in the fast-changing world of FinTech.
Next Steps
Going forward, we would be iterating on our agent such that it can be used in production environments to help us with real-time incidents. We can’t wait to implement and scale the innovative solutions developed during the hackathon, as they hold the potential to revolutionise our operations, delight our customers, and further cement Fazz's position as a leader in the FinTech space. Special thanks to our friends at AWS for their constant support, guidance, and mentorship in our Startup journey.
Going forward, we would be iterating on our agent such that it can be used in production environments to help us with real-time incidents. We can’t wait to implement and scale the innovative solutions developed during the hackathon, as they hold the potential to revolutionise our operations, delight our customers, and further cement Fazz's position as a leader in the FinTech space. Special thanks to our friends at AWS for their constant support, guidance, and mentorship in our Startup journey.
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.
2 Comments
Log in to comment