How to Speed Up Model Training and Cut Down Billing Time with Amazon SageMaker
Optimizing the compilation and training of the open source GPT-2 model on the Stanford Sentiment Treebank v2 (SST2) dataset, using the features of the Amazon SageMaker Training Compiler.
Haowen Huang
Amazon Employee
Published Jul 31, 2023
Last Modified Mar 25, 2024
Large language models, or LLMs, are essentially composed of complex multi-layer neural networks with over billions of parameters, and may require thousands of GPU hours or more to train. Therefore, optimizing such models on the training infrastructure requires extensive knowledge of deep learning and systems engineering. While open-source implementations of some compilers can optimize the training process, they often lack the flexibility to integrate with certain hardware, such as GPU instances. The Amazon SageMaker Training Compiler can transform deep learning models from their high-level language expressions into hardware-optimized instructions, thereby speeding up training and helping reduce overall billing time.
In this hands-on demonstration, we'll experience together how to set up an environment in Amazon SageMaker, including permission settings, configuration settings, etc. Next, we'll experience how to train a GPT-2 model on an SST2 dataset using the Amazon SageMaker Training Compiler. The Amazon SageMaker Training Compiler is integrated into Amazon's deep learning containers (DLC), which use these containers to compile and optimize training jobs on GPU instances with minimal code changes.
The Amazon SageMaker Training Compiler is an optimization feature of SageMaker that can help reduce training time on GPU instances, and the compiler accelerates the training process by using GPU instances more efficiently. Amazon SageMaker Training Compiler is offered free of charge in SageMaker and helps reduce overall billing time by speeding up training.
The SageMaker training compiler is integrated into the AWS deep learning container (DLC). Using the AWS DLC that supports the SageMaker training compiler, you can compile and optimize training jobs on GPU instances with minimal code changes.
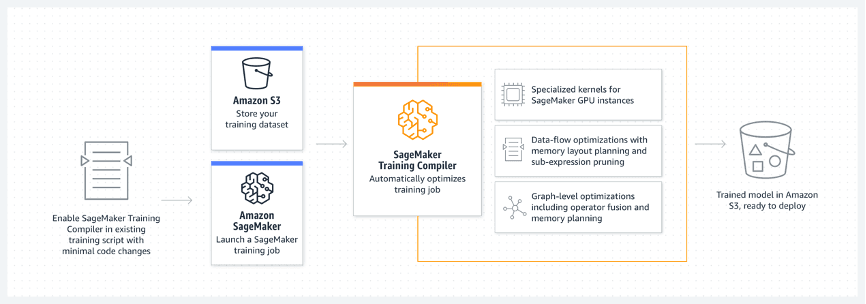
For more information, see the Amazon SageMaker Training Compiler section in the Developer Guide.
In this experiment, you'll train a GPT-2 model on the SST2 dataset with Amazon SageMaker Training Compiler using Hugging Face's transformers and dataset library. Note that this notebook will download the SST2 data set from the website, where you can view the dataset information and terms.
First of all, we need to set up the environment through some pre-requisites, such as permissions, configuration, etc.
Special Instructions:
- You can run this code on Amazon SageMaker Studio, Amazon SageMaker notebook instance (the way we're using it now), or on your local computer where the AWS CLI is set up. If you use Amazon SageMaker Studio or Amazon SageMaker notebook instance, make sure to select one of the PyTorch-based kernels, namely
PyTorch 3orconda_pytorch_p38respectively. - This notebook uses 2 x
ml.g4dn.12xlargeinstances with multiple GPUs. If you don't have enough quotas, please refer to the "Supported Regions and Quotas" to request an increase in service quotas for Amazon SageMaker resources.
First of all, you'll need to install the SageMaker Python SDK. This experiment requires installing the SageMaker Python SDK v2.108.0, as shown in the following code:
Secondly, you need to set up the operating environment for Amazon SageMaker:
If you are concerned about when the dataset is loaded, you can find the value sst2 of
dataset_config_name in the notebook code; if you compare it to the entry_point file of the Hugging Face estimator (run_clm.py is defined in this example), the code in it is written like this:
The explanation in the code comments is very clear. They are listed below for your reference:
“Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below) or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/ (the dataset will be downloaded automatically from the datasets Hub) …”
To create an Amazon SageMaker training job, we use an estimator. We'll be using the Hugging Face estimator in the Amazon SageMaker Training Compiler. With an estimator, you can use entry_point to define the training script that Amazon SageMaker should execute, the instance type (instance_type) participating in the training, the hyperparameters to be delivered, etc.
When the Amazon SageMaker training job starts, it's responsible for launching and managing all required machine learning instances, selecting the corresponding Hugging Face DLC(Deep learning container), uploading the training script, downloading the data from the S3 bucket (sagemaker_session_bucket) where the specified data set is located to the /opt/ml/input/data container.
First, we'll define some basic parameters common to all estimators (for experimental use, it's recommended to turn off the Amazon SageMaker Debugger performance analysis and debugging tools to avoid additional overhead):
Next, define some parameters to pass to the training script.
The following
per_device_train_batch_size defines the maximum number of batches that can fit into the ml.g4dn.12xlarge instance memory. If you change the model version, instance type, sequence length, or other parameters that affect memory consumption, you'll need to find the corresponding maximum batch size.Also, notice that this example code sets the way PyTorch data parallelization is set:
Setting up the PyTorch data parallel mechanism on Amazon SageMaker is easy. You can learn more on the “Running PyTorch Lightning and Native PyTorch DDP on Amazon SageMaker Training” blog.
Also, this example uses the Hugging Face training script
run_clm.py, which you can find in the scripts folder.The Amazon SageMaker Training Compiler can perform some optimization to reduce training time on GPU instances. The compiler optimizes DL models to accelerate training by using SageMaker machine learning (ML) GPU instances more efficiently. Amazon SageMaker Training Compiler allows you to use SageMaker at no additional cost, which helps reduce overall billing time by speeding up training.
The following code shows how to use the distribution mechanism pytorchxla, a distributed training method that recognizes compilers.
XLA (Accelerated Linear Algebra) is a compiler-based linear algebra execution engine. The input language to XLA is called "HLO IR", or just HLO (High Level Operations). XLA takes graphs ("computations") defined in HLO and compiles them into machine instructions for various architectures. The following diagram shows the compilation process in XLA:
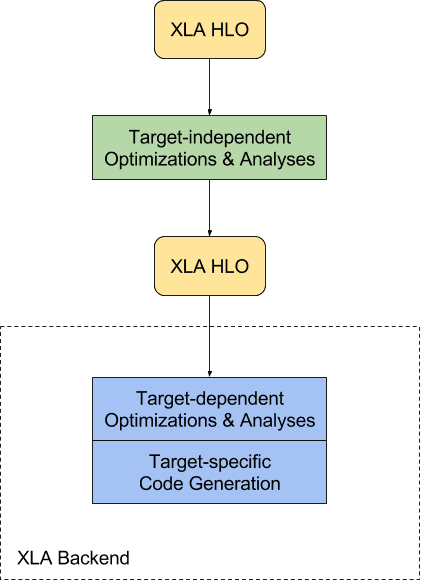
source: XLA Architecture
PyTorch/XLA is a Python package built on top of the XLA deep learning compiler, a domain-specific compiler for linear algebra that can accelerate TensorFlow and PyTorch models. The PyTorch/XLA package is used for connecting the PyTorch framework with CPUs, GPUs, TPUs and AWS Trainium.
Compiling with the Amazon SageMaker Training Compiler changes the model's memory usage. Most commonly, this is expressed as a decrease in memory utilization, followed by an increase in the maximum batch size that can accommodate the GPU. Note that to change the batch size, the learning rate must be adjusted appropriately. The following code shows how to linearly adjust the learning rate as the batch size increases.
Let's compare the various training metrics with and without the Amazon SageMaker Training Compiler. These include: training data throughput comparison, training loss convergence comparison, training time comparison, training cost comparison, etc.
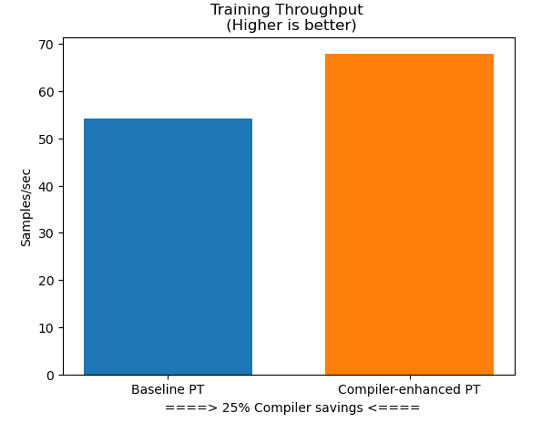
Training data throughput: without Training Compiler vs. with Training Compiler
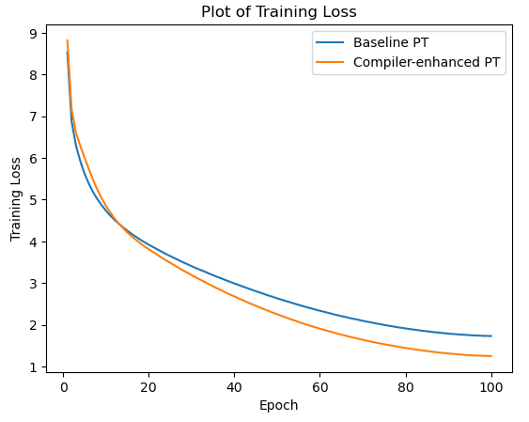
Training loss convergence: without Training Compiler vs. with Training Compiler

Training time: without Training Compiler vs. with Training Compiler
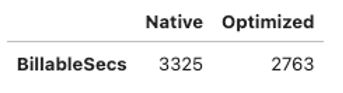
Training cost (billable seconds): without Training Compiler vs. with Training Compiler
As can be seen from the comparison of experimental data from multiple dimensions, we've been able to increase training throughput, which means the total training time will be reduced. Also, the reduction in total training time reduces the number of seconds Amazon SageMaker charges, thereby helping developers and customers save on the costs required for machine learning training.
If you want to learn more about training open source LLMs, check out SageMaker Training Compiler Best Practices and Considerations. Or, for more information about Amazon SageMaker Training Compiler, read this Amazon SageMaker Training Compiler reference document.
Also, recently we've seen that some advanced open source LLMs are still hot topics of discussion, such as the Falcon-40B model, the Llama-v2-70B model, etc. We'll continue to share how to deploy and fine-tune these open source LLMs with Amazon SageMaker in our upcoming blogs. Please stay tuned.
Haowen is a Senior Developer Advocate at AWS based in Hong Kong. He has over 20 years of experience in the cloud computing, internet, and telecom industries. He focuses on the promotion and application of AI, machine learning and data science.
Elizabeth is a Developer Advocate at AWS based in Santiago. She has extensive experience in data analytics and machine learning. She loves helping developers learn while building.
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.