Prototype a RAG chatbot with Amazon Bedrock, Kendra, and Lex
An instructive guide and reference repository on creating your first Retrieval Augmented Generation chatbot on AWS
Colin Baird
Amazon Employee
Published Mar 26, 2024
The growth in interest and adoption of generative AI (GenAI) tooling across many organizations has taken center stage over the last year. At AWS, we believe in working backwards from our customers problems, and the problems that many seek to solve with generative AI are no different. This year, we’ve spent a lot of time working with and listening to customer feedback on the tools that are available, and where the gaps lie. With the recent launch of Amazon Bedrock, we’re empowering developers to not only quickly and effortlessly harness the power of generative AI, but also take advantage of a wide variety of AWS tools and services that are complementary to these use cases. Tools like Amazon Lex, Amazon Kendra, and Amazon Connect empower you to build scalable and intelligent generative AI services on AWS.
Before we dive into building a Generative AI bot of our own its important to understand some of the core elements these systems are comprised of:
Foundation Models are the AI models that underpin generative AI systems. They are pre-trained on vast datasets to understand and generate human-like text, images, or other media. These models serve as the backbone, providing the initial capabilities that are then fine-tuned or adapted to specific tasks or domains. Within most Generative AI systems these foundation models can be easily swapped with one another while requiring only minor changes to the application.
Prompt Engineering refers to the process of structuring text in a way that is optimally understood by the language model within your generative AI system. Effective prompt engineering is crucial for eliciting the desired output from the model, as the way a prompt is formulated can significantly influence the quality and relevance of the response. Refer to this guide for a more in-depth look at the various aspects of prompt engineering.
Orchestration Layers such as LangChain provide a framework for integrating different components of a Generative AI system, including foundation models, external databases, and APIs. These layers manage the flow of data and interactions between components, enabling more complex and dynamic AI applications.
Agents in Generative AI systems are computational components that simulate human behavior for the purpose of executing pre-defined tasks in an automated manner. Often an agent will operate on one or more underlying language models and fulfill process or task specific actions, such as for example helping to book concert tickets in a customer service capacity.
Retrieval Augmented Generation (RAG) introduces a method where the AI system retrieves relevant information from an external dataset or knowledge base to use as context before generating a response. This approach enhances the model's ability to provide accurate and contextually appropriate outputs by grounding its responses in real-world information.
This video offers a high level introduction to Generative AI concepts and terminology, and this one introduces Amazon Bedrock, the fastest and easiest way to get started with GenAI on AWS, and a core component of the solution we will be building in this post.
A generative AI design pattern that has been of particular interest from our customers recently has been Retrieval Augmented Generation (RAG). The RAG design pattern has a wide range of potential business applications. By utilizing a two-step process that includes retrieving relevant information from an external dataset and then suppling it to a large language model (LLM) to generate a response based on that information, RAG introduces a new layer of precision and adaptability to the use of LLMs in the workplace.
One of the primary advantages of RAG is its ability to reduce hallucinations by providing additional context to the model. Hallucinations in simple terms is when the model generates incorrect or misleading information. Moreover, RAG allows seamless integration of LLMs with external or corporate data, enabling businesses to tailor responses that align with their specific data ecosystem. This makes RAG particularly adept at handling evolving data, and extends the applicability of LLM systems beyond their parametric (internal) memory. Furthermore, the RAG design pattern can be applied in conjunction with any LLM, giving you the flexibility to leverage the most advanced or use case specific model for your needs.
Today, AWS offers a variety of ways to deploy a RAG system of your own, including a fully managed experience with Knowledge Bases for Amazon Bedrock. In this post, we guide you through the creation of a custom RAG chatbot using Amazon Lex, Amazon Kendra, Amazon Bedrock, Amazon Simple Storage Service (Amazon S3), AWS Lambda, and LangChain. We also showcase the ease with which you can interchange LLMs after the overall system has been deployed.
The following RAG chatbot, written in Python, is designed to answer user prompts against company-specific data by harnessing Amazon Kendra, Amazon Lex, AWS Lambda, LangChain, and LLMs hosted on Amazon Bedrock. Some unique features of this solution include leveraging multiple LLMs for price/performance, including historical messages in future answers, as well as leveraging Lex Session State for state retention. The bot UI is hosted through Amazon Lex, and uses a Lambda invocation via fallback intents to facilitate interactions between a user and multiple LLMs. As our retrieval source, we are using Amazon Kendra, which offers robust natural language processing (NLP) indexing of text data, allowing us to retrieve results based on semantic similarity without having to worry about vector embeddings, chunking strategies, and managing external vector datastores. Data indexed by Amazon Kendra can be in various text formats, such as PDF, .txt, .doc, and others, and can be indexed either manually or with the help of the built-in web crawler.
The following diagram illustrates the solution architecture and user request flow.
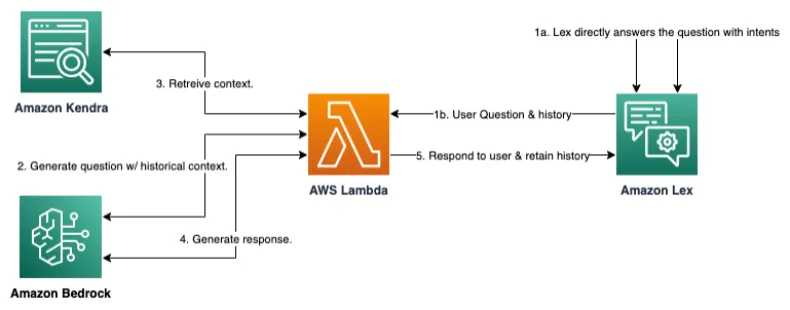
The workflow includes the following high-level steps:
1. The user asks the chatbot a question:
a. If Amazon Lex has an existing intent that fulfills the question, then it handles the response via the intent definition.
b. If Amazon Lex doesn’t have an intent, then it sends the question to a Lambda function via a fallback intent.
2. The Lambda function uses LangChain to call the Amazon Bedrock endpoint to formulate a prompt based on the question and conversation history (facilitated by the Lex Session State and LangChain Conversational Retrieval Chain).
Note: A cheaper LLM is leveraged for this step vs the next to save on cost while delivering similar performance.
3. The Lambda function sends that prompt to Amazon Kendra, which returns a set of context passages.
4. The Lambda function sends the prompt along with the context to the Amazon Bedrock endpoint to generate a response.
5. Finally, the Lambda function returns the response along with the message history to the user via Amazon Lex, and Amazon Lex stores the message history in a session.
For handling the chat history (step 2) we use sessionState's in Lex to pass the three most recent conversation lines to LangChain via our Lambda. Here is an example of what this payload looks like:
event = { ... 'sessionState': { 'sessionAttributes': {'chat_history': [ ("Human: What is Kendra?", "Assistant: Amazon Kendra is a highly accurate and easy to use enterprise search service powered by machine learning that enables companies to index and search content across multiple data silos and cloud applications."), ("Human: What does it integrate with?", "Assistant: Amazon Kendra integrates with popular data repositories like Amazon S3, file systems, databases, applications, and Salesforce."), ("Human: How can I get started?", "Assistant: Create an index, add data sources, configure data source permissions and field mappings, then query the index using the Kendra search APIs or query integration tools like a search bar.") ]}, ... } ... }In the following sections, we discuss the core AWS services in more detail and share options to extend the RAG bot.
In this section, we discuss how the solution uses the core AWS services.
Amazon Kendra
Amazon Kendra functions as the retrieval source in our RAG implementation. It’s designed to index and search across both structured and unstructured data residing in an organization's corporate repositories. The service’s robust suite of connectors facilitates straightforward integration with several popular data sources, such as SharePoint, Salesforce, and ServiceNow. Additionally, it offers seamless connectivity with Amazon S3, thereby accessing and using the extensive, scalable storage for query-centric workloads. The natural language understanding capabilities of Amazon Kendra facilitate the extraction of the correct response based on semantic similarity rather than keyword matching.
Amazon Lex
Amazon Lex is a service for building conversational interfaces into any application using voice and text, and is underpinned by the same deep learning technologies that power the conversational capabilities of Amazon Alexa. Amazon Lex stands out due to its ability to be seamlessly integrated, allowing it to be effortlessly embedded into existing applications. Additionally, Amazon Lex offers a plug-and-play chat UI, further enhanced by extended features like voice support through Amazon Polly and easy integration with Amazon Connect.
For this particular RAG bot, we use Amazon Lex as the principal user interface. Users communicate with the bot by entering text, which Amazon Lex interprets and passes to Lambda, which then triggers queries in Amazon Kendra and responses from the LLM in Amazon Bedrock. The system takes advantage of the fallback intent feature in Amazon Lex, which ensures that unfulfilled queries are carried over seamlessly, thereby ensuring accurate and effective interactions with the bot. Chat history is managed by Amazon Lex session state, and preserves the three most recent messages from the conversation, which are used as a reference via LangChain's conversational retrieval chain.
AWS Lambda
AWS Lambda is a serverless computation service that lets you run your code without the need to directly provision or manage any infrastructure. Lambda runs your code only when required and scales automatically, going from a few requests per day to thousands per second. You don’t have to worry about patching, updating servers, or runtime environments, and can focus on your core product.
In our RAG bot architecture, Lambda plays an important role in facilitating orchestration between Amazon Lex, Amazon Kendra, and our LLM in Amazon Bedrock. It is fully managed and serverless, offering a cost effective and scalable solution for receiving queries from Amazon Lex and facilitating interactions between Amazon Kendra and Amazon Bedrock to retrieve relevant data and generate responses. Lambda harnesses event-driven computing to provide real-time file processing and run the code in response, thereby ensuring uninterrupted, smooth communication with the bot and maintaining a swift response rate.
Amazon Bedrock
Amazon Bedrock is a fully managed service that provides access to high-performing foundation models (FMs) from leading AI organizations such as AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API. It offers an array of comprehensive capabilities necessary for building generative AI applications. Amazon Bedrock also simplifies development while ensuring confidentiality and security. Its serverless nature eliminates the need to manage any infrastructure, allowing secure integration and deployment of generative AI capabilities into your applications using readily familiar AWS services.
In our RAG bot architecture, Amazon Bedrock plays a pivotal role. It hosts the LLM from which our chatbot generates responses. The beauty of having Amazon Bedrock in our structure is the adaptability it provides. You can easily and swiftly experiment, modify, or interchange LLMs with minimal changes to existing code. To make the transformation, you simply update the API endpoint and adjust the prompt template according to your needs. This recalibration ability enhances the versatility of our RAG bot, making it a potent tool for a broad scope of applications.
To get this RAG bot up and running, download the code from this repository, and follow the steps laid out below (or within the ReadMe):
1. Preparation: Ensure you have the following prerequisites in place:
- The AWS Command Line Interface (CLI), installed and configured
- Docker CLI installed, for building the lambda container image
- Python 3.9 or later, for packaging Python code for Lambda
- An IAM role or user with permissions for creating a Kendra index, invoking Bedrock, and creating an IAM role, policy, and a Lambda function.
2. Deployment of the Sample Solution: Initialize the environment and create an ECR repository for your lambda function's image.
bash ./helper.sh init-env…{"repository": {…}}Then, generate a cloud formation stack and deploy the resources.
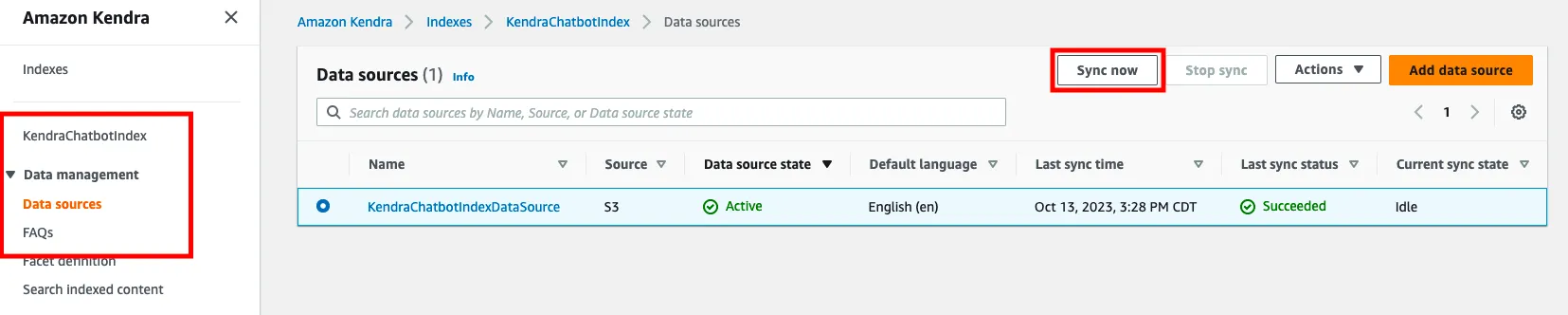
bash ./helper.sh cf-create-stack3. Set Up Amazon Kendra: Go to the Amazon S3 service in the AWS console and locate the bucket that was created via the CloudFormation template. Upload your text documents to this bucket. Navigate to the Amazon Kendra service console and sync the data you just uploaded to S3 by selecting 'Indexes', then your index, and clicking on 'Sync now'.
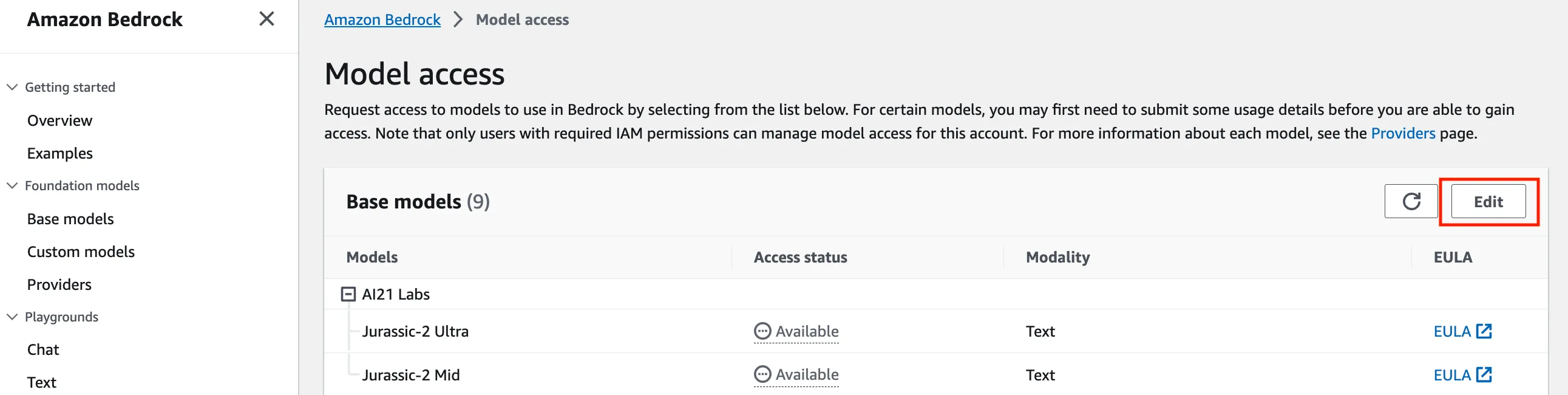
4. Model Access in Amazon Bedrock: If you're deploying in a new AWS account, request access to Bedrock hosted models. In the Bedrock console, request for model access and select the models you want access to.
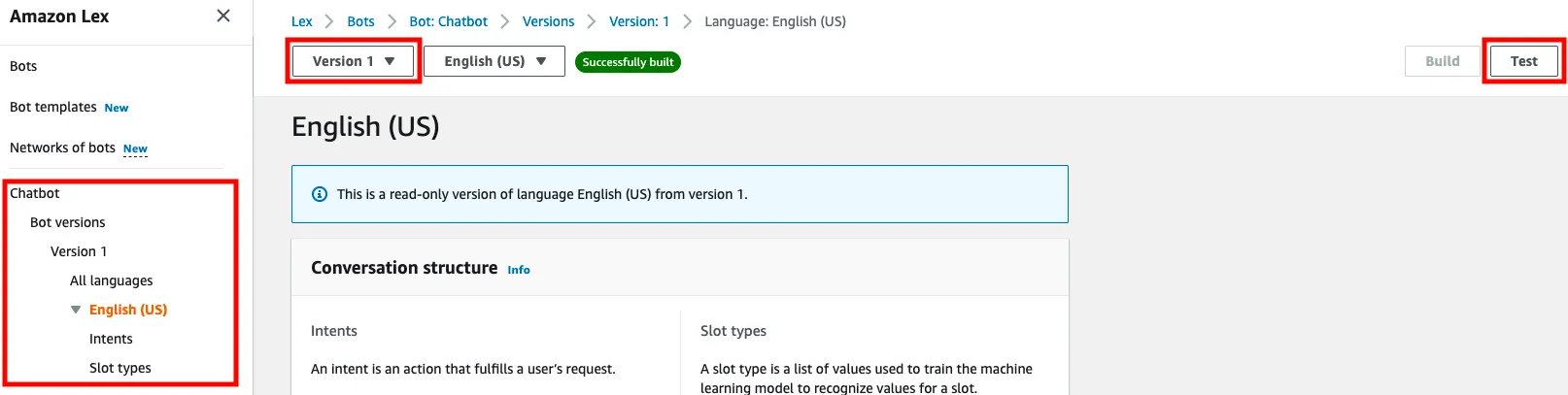
5. Testing: Test the functionality of the bot via the Amazon Lex service in the AWS console. Select the 'Chatbot' Bot in the Lex console. On the left side of the screen click English (US) under All languages. At the top of the screen click the 'Draft version' dropdown and select 'Version 1'. Finally, click Test in the top right corner and select 'ChatbotTestAlias' and confirm. Use the chat interface to test the bot.
- Cleanup: When you're done you can remove all associated resources by simply calling the CloudFormation delete stack function via the AWS CLI
bash ./helper.sh cf-delete-stackHarnessing the power of generative AI, particularly in the realm of RAG, has the potential to reshape businesses across industries. At AWS, it’s our mission to provide the tools and services to foster this transformation. Rapidly growing fields like RAG and generative AI hold the promise of producing more intelligent, efficient, and tailored solutions to complex problems. We encourage you to continue your education in these areas and increasingly take advantage of the diversified and robust AWS tooling to your advantage. Explore, experiment, and innovate with us on this exciting generative AI journey.
Finally, for any readers who may be looking for a fully managed RAG experience, our recently announced Knowledge Bases on Amazon Bedrock may be of interest. Knowledge Bases for Amazon Bedrock manages the end-to-end RAG workflow for you. You can simply specify the location of your data, select an embedding model to convert the data into vector embeddings, and have Amazon Bedrock create a vector store in your account.
Authors:
Colin Baird - Solutions Architect, AWS
Brett Seib - Sr. Solutions Architect, AWS
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.