How to develop a tag-based web searcher using AI
This service enhances users' convenience in using web pages by supporting smart page management and search using tags.
Hyunjoong Shin
Amazon Employee
Published Apr 18, 2024
- Streamlit
- Langchain
- Bedrock (anthropic.claude-instant-v1)
- Opensearch
In recent years, as the number of websites and web pages has increased exponentially, it is becoming increasingly difficult to effectively manage the web pages stored by individuals. In particular, when a large number of web pages are stored, it is difficult to search and use them because it is difficult to check the main information and contents of each page one by one. Accordingly, this service extracts and provides key information and appropriate tags on the corresponding page through an AI algorithm based on the web page URL entered by the user. Specifically, the overall contents of the web page are summarized, and representative keywords related to the contents are extracted as tags. Since the information extracted in this way is stored as a brief description and tag of each page, users can use it much more efficiently in the process of searching and managing pages. In particular, it has the advantage of being able to search related pages immediately when a specific tag is selected. This service is an AI-based tagging solution for managing users' web pages, and is expected to be useful to individual users or companies that store large amounts of web pages.
- Users register by entering the URL of the webpage they want to bookmark.
- When a page is registered and refreshed, the AI analyzes the contents of the page and automatically generates appropriate tags.
- Users can click on the generated tag to search for other pages with the same tag.
- These tag-based searches allow you to quickly browse pages with similar content.
- In addition, page-specific tags allow you to grasp the content and characteristics of the saved page at a glance.
- Create a new IAM user.
- The IAM User you created connects its policy (Amazon BedrockFullAccess, Amazon OpenSearchServiceFullAccess).
- Perform credentials through aws configure using the users created above through the CMD window.
- At this time, the region must select the region in which the Opensearch is generated.

- Connect Opensearch dashboard, Management > Security > Roles > search all_access
- Click manage mapping in all_access > Mapped users
- Map the ARNs of IAM users created in the previous step,

- Connect Opensearch dashboard > Management > Click Devtools
- Opensearch should set the index as follows.
- In Opensearch, insert the following example documents.
- Run IDE similar to Pycharm.
- Install the required libraries as follows.
- Enter the code below.
- Change the region and host according to your environment in the code below.
- If the code above has been entered, use the command below to execute it.
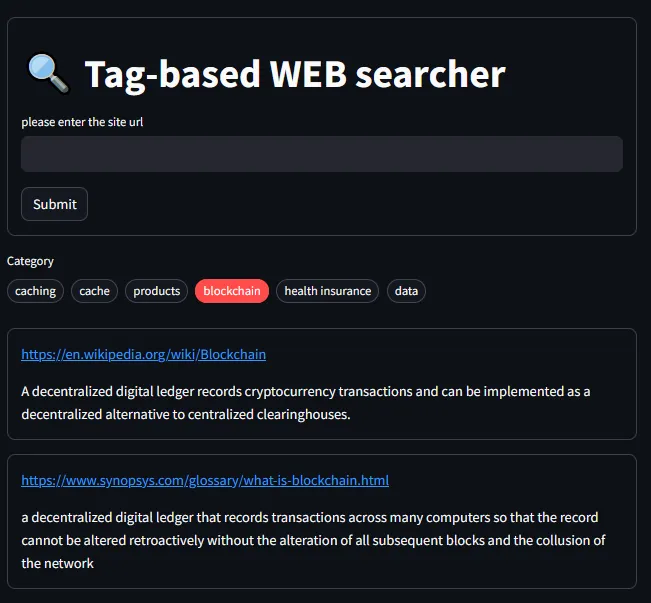
streamlit run <your python file>.py- You can successfully check the page below.
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.