GenAI under the hood [Part 2] - Some form of “Attention” is still what you need, looks like
We looked at tokenization in part 1 of this series; here we will dive deeper into attention, and why it is still relevant.
Shreyas Subramanian
Amazon Employee
Published Apr 9, 2024
The Transformer architecture (here’s the severely cited original paper https://arxiv.org/pdf/1706.03762.pdf) and its core attention mechanism have been powering most of the recent breakthroughs in deep learning across domains like natural language processing, computer vision, and genomics. While extremely effective, Transformers have a major drawback - their computation scales quadratically with the input sequence length. This makes them computationally expensive and inefficient for very long sequences.
This computational inefficiency has driven researchers to explore alternative architectures that can achieve Transformer-level performance with better scaling properties. One promising direction is structured state space models (SSMs), a class of sequence models inspired by classical control systems. The newly proposed Mamba architecture falls into this category. There are of course other alternative architectures coming up in literature, but we’ll focus on Mamba for now (for those brave enough, here’s the paper - https://arxiv.org/ftp/arxiv/papers/2312/2312.00752.pdf):
High level, this is what the Mamba architecture looks like (of course, as a UML diagram because I <3 UML):

Like Transformers, Mamba operates on sequences in an autoregressive manner. However, under the hood, it uses selective state space modules instead of the self-attention layers in Transformers. These modules have linear computational scaling with respect to sequence length, enabling much higher throughput, especially for very long sequences. The key innovation in Mamba is the "selection mechanism" that allows the state space modules to dynamically focus on or ignore inputs based on their content. This selectivity gives Mamba the same modeling power as Transformers while avoiding their quadratic overhead. The diagram above may look simple, but it all comes down to zooming into the SSM block; here’s what happens under the hood:
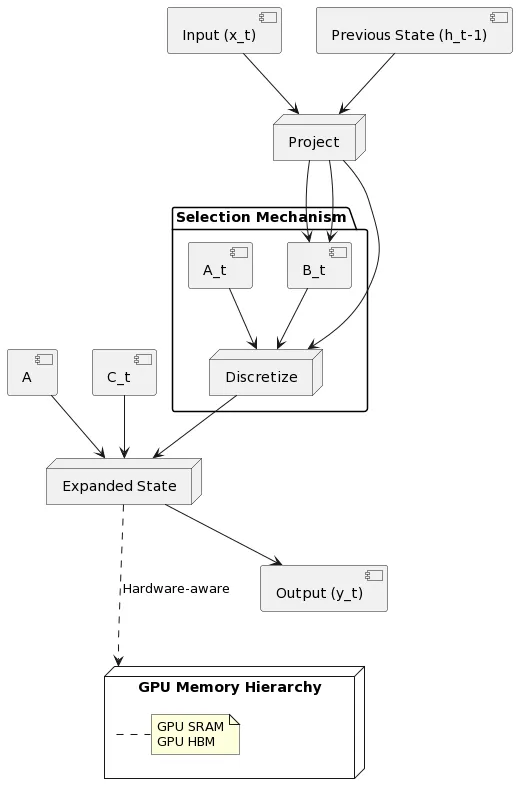
Existing SSM architectures, can be quite complex, involving multiple interleaved components such as linear attention and multi-layer perceptrons (MLPs). Mamba combines the strengths of SSMs and MLPs into a homogeneous, streamlined design. The key idea behind Mamba is to merge the linear attention and MLP blocks of the standard SSM architectures (“H3”) into a single block, which is then repeated throughout the model - similar to how decoder blocks are repeated throughout the model.
But Mamba isn't just about simplifying the architecture; it also introduces a connection between selection mechanisms and gating mechanisms commonly used in recurrent neural networks - RNNs - yes, still relevant today. This connection highlights the principled foundation of heuristic gating mechanisms, rooted in the discretization of SSMs. In addition to this, Mamba incorporates a few other design choices (it uses the SiLU (Swish) activation function and an optional normalization layer (e.g., LayerNorm) is included, drawing inspiration from the RetNet architecture)
Overall, Mamba presents a streamlined approach to sequence modeling, combining the power of SSMs with the simplicity of MLPs. Its connection to gating mechanisms and its design choices make it an intriguing addition to the field of sequence modeling architectures. The results (in the paper) show that it works for practical problems as promised.
Despite these advantages, self-attention still provides powerful modeling capabilities that are difficult to match with sequence models like Mamba. The key strength of Transformers lies in their ability to directly capture long-range dependencies between tokens across the entire input sequence via the self-attention mechanism. This allows relevant information to be easily related and integrated, regardless of how far apart the tokens are in the sequence.
In contrast, recurrent architectures like Mamba have to incrementally process the sequence token-by-token, selectively compressing the past context into a finite internal state representation. While theoretically capable of maintaining longer-term dependencies, this requires making decisions about what information to keep or discard based solely on the current time step. Important details could potentially be lost if their relevance is not apparent until much later in the sequence.
For instance, in question-answering scenarios where the query comes after the context, a recurrent model would have to proactively retain all potentially relevant information while processing the context blindly. A Transformer, on the other hand, can simply attend to the entire context after seeing the query. This flexibility of the self-attention mechanism is a key advantage.
However, recurrent state space models like Mamba have their own strengths. Their structured formulation provides a more interpretable and mechanistically-grounded approach to sequence modeling compared to the relatively opaque self-attention. The computational scaling of O(n) allows for much more efficient processing of extremely long sequences compared to Transformers' O(n^2) scaling.
Researchers are actively exploring hybrid architectures that combine the respective strengths of multi-head attention and structured state space models. Attention-based modules could provide the context modeling power, while the recurrent state transition allows efficiently tracking very long-range dependencies. Such architectures could unlock transformative capabilities across domains like genomics, books, videos and time series data where extremely long sequence lengths are common.
Ultimately, as models grow larger and more compute-intensive, the choice between self-attention and efficient recurrent architectures may come down to the specific application domain, dataset characteristics like sequence lengths, and the available computational resources. The deep learning field continues to make rapid advances in developing powerful, scalable and efficient sequence modeling techniques.
Today, most models you see (and use) are decoder-only models, as highlighted in red in the adapted diagram below (yes, again, UML - you should try it! Or ask Claude to generate one for you as a starting point):
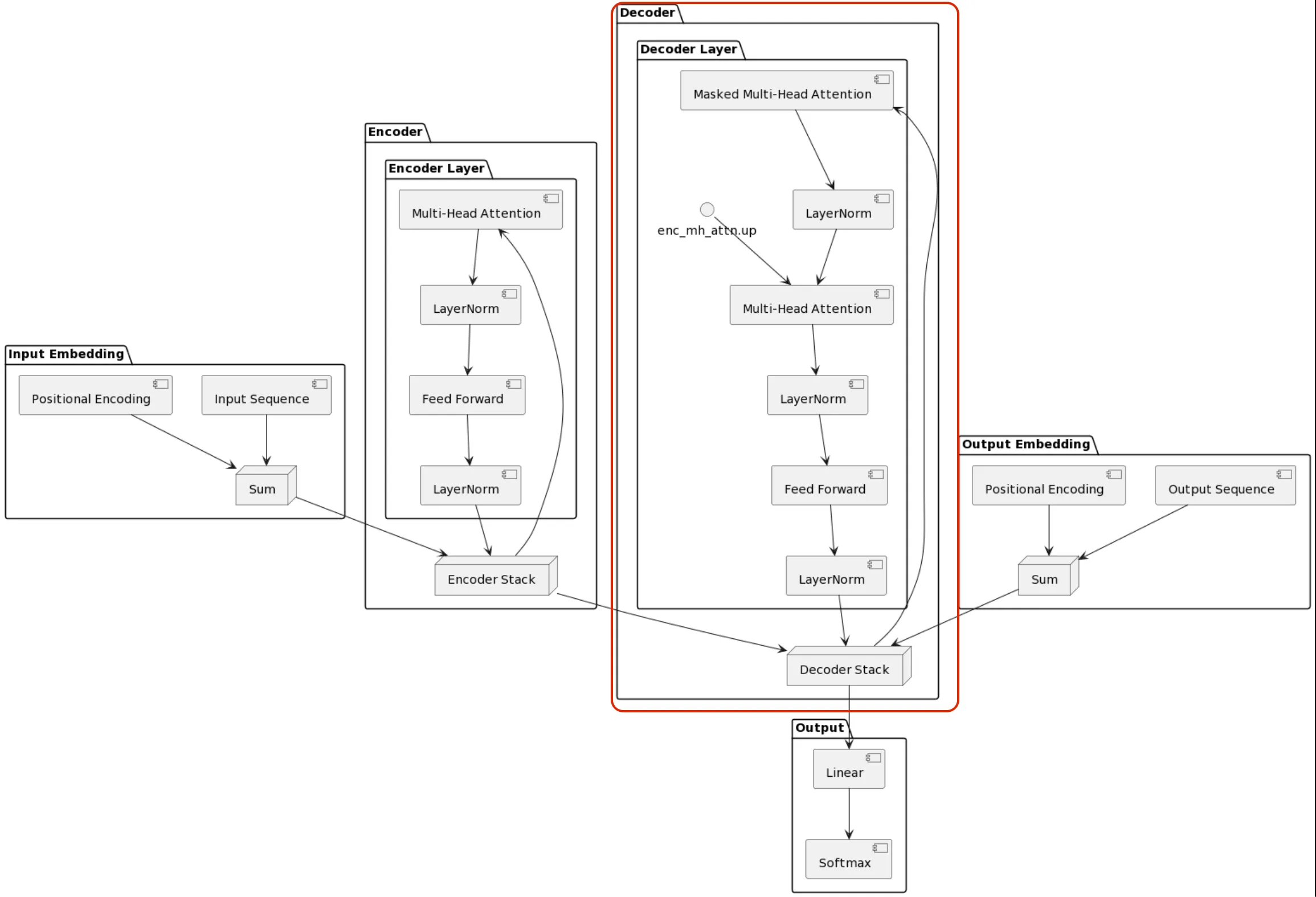
Here’s a great high level diagram looking at a particular sequence from the GPT2 block https://jalammar.github.io/illustrated-gpt2/
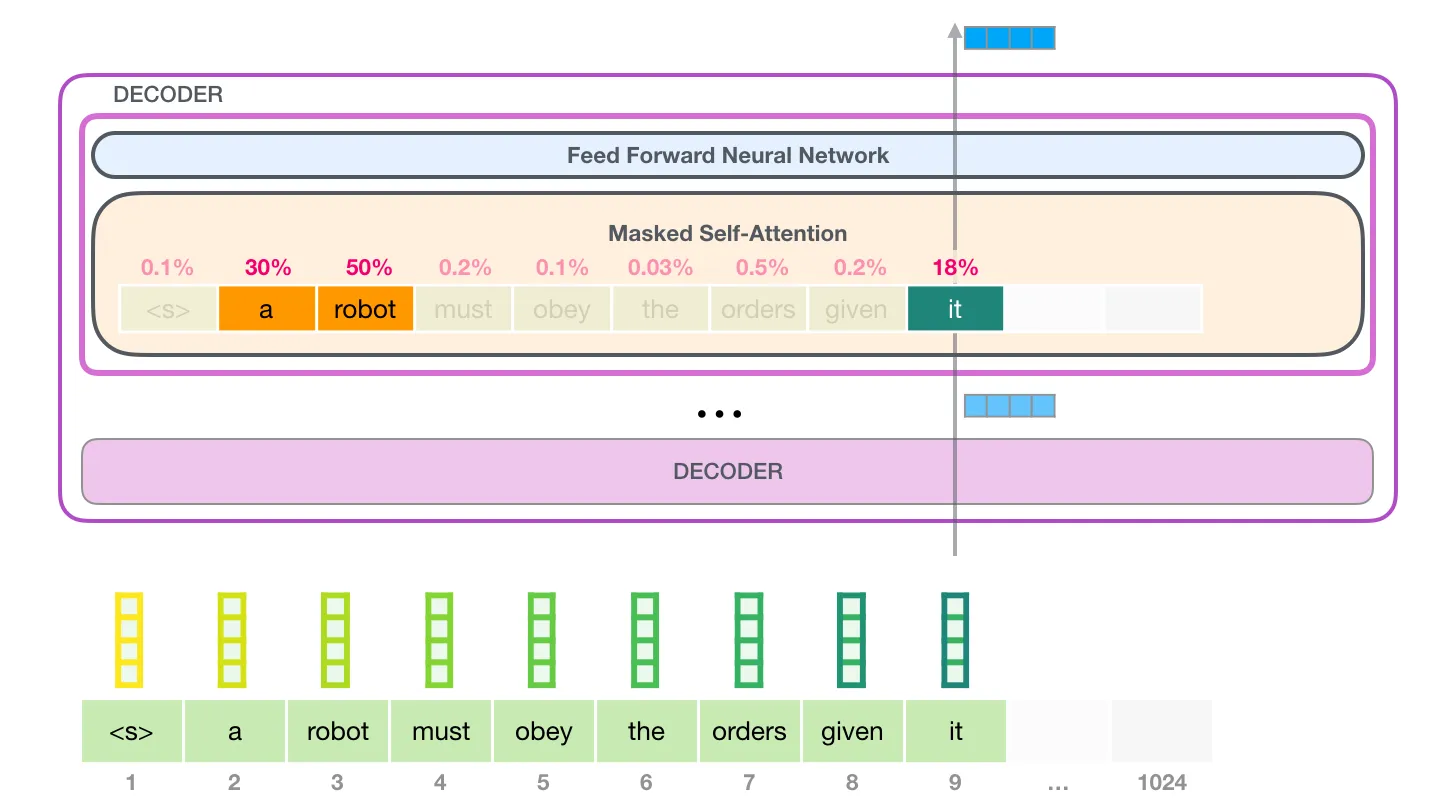
We read about tokens in Part 1. With that in mind:
In the Transformer architecture, the attention mechanism employed is called self-attention, where each sequence element (token) provides a key, value, and query vector. For every token, we have one key and one value vector. The query vector, representing the current token, is compared to all keys (labels for words in the segment) using a score function (in this case, the dot product) to determine the weights. The value vectors (actual word representations) of all words are then averaged using these attention weights. The self-attention process is applied along the path of each token in the segment. The significant components are the query vector used to score against all other word keys, the key vectors acting as labels for matching, and the value vectors that are combined based on relevance scores.
Here’s what the first layer of GPT nano looks like (a tiny model with only 85K parameters, but similar in architecture to GPT2) - oh, also check out this great tool https://bbycroft.net/llm:
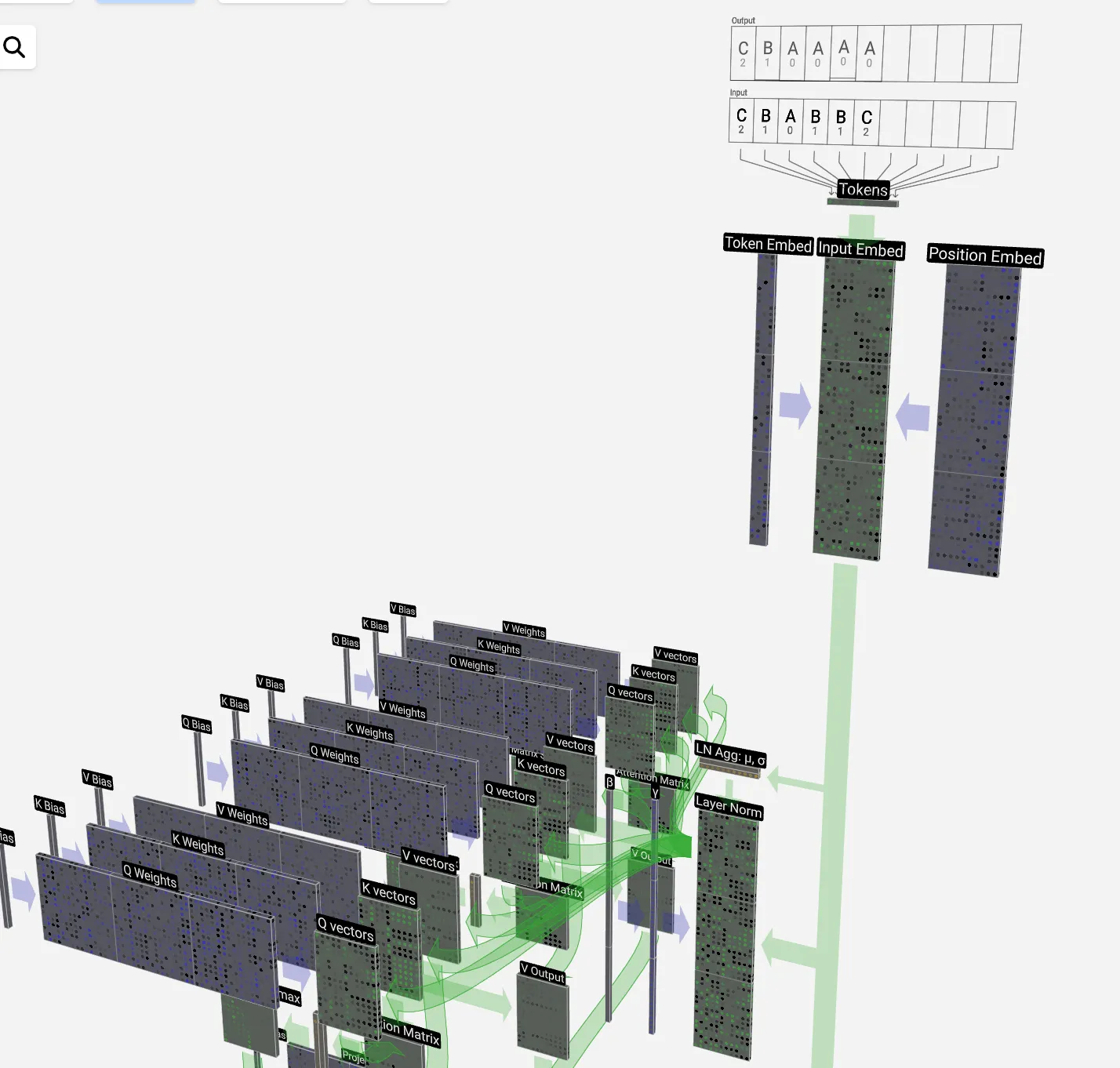
This shows a simple input (CBABBC) for illustration, and is not very useful except for understanding how the QKV weights are placed. The next step is to pass it through the layer norm and feedforward (MLP) layers as we showed on the diagram above (with the red box highlighting the decoder block - follow the arrows!):
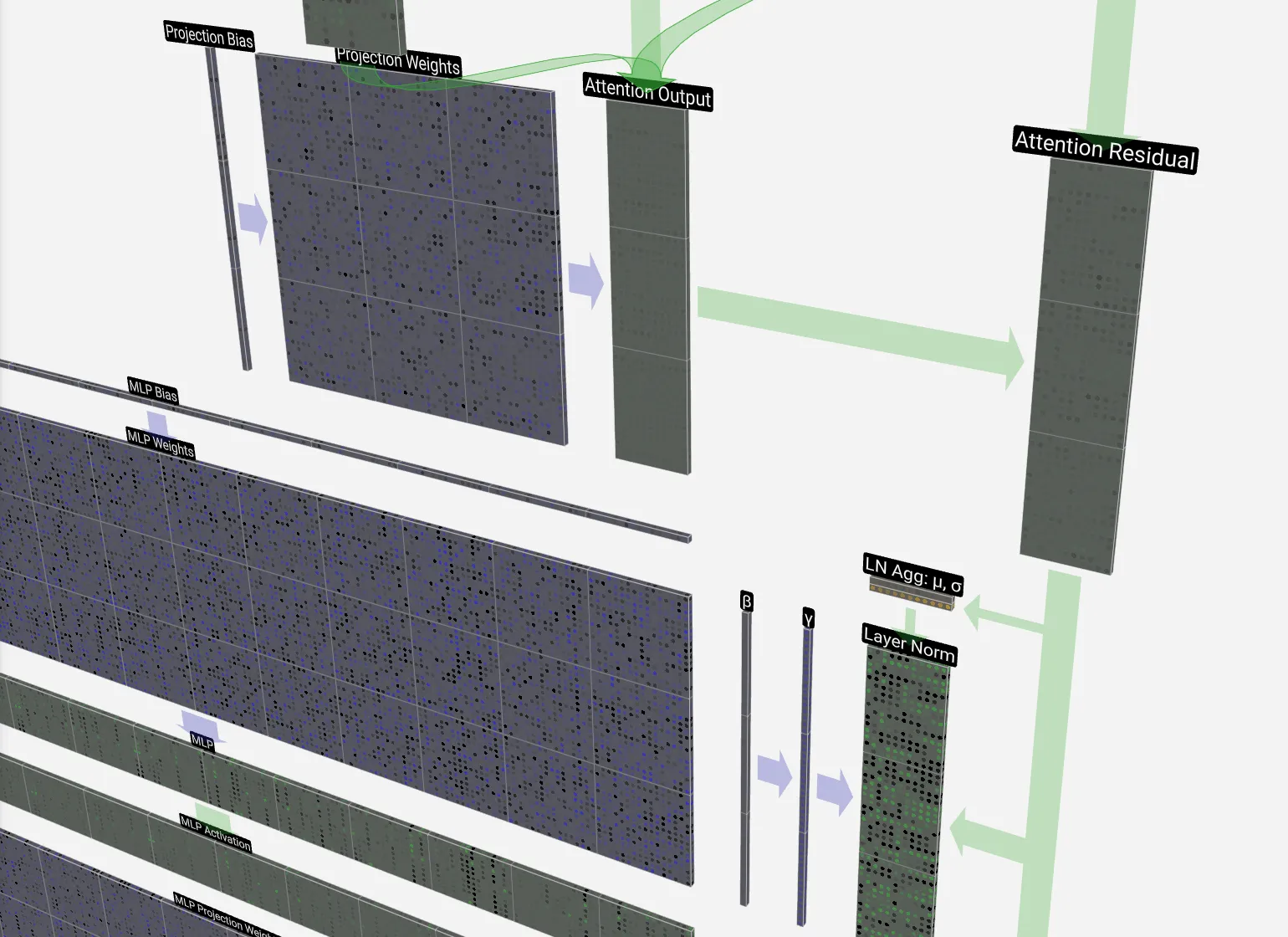
This is repeated twice through two transformer layers (here’s zoomed out nano GPT):
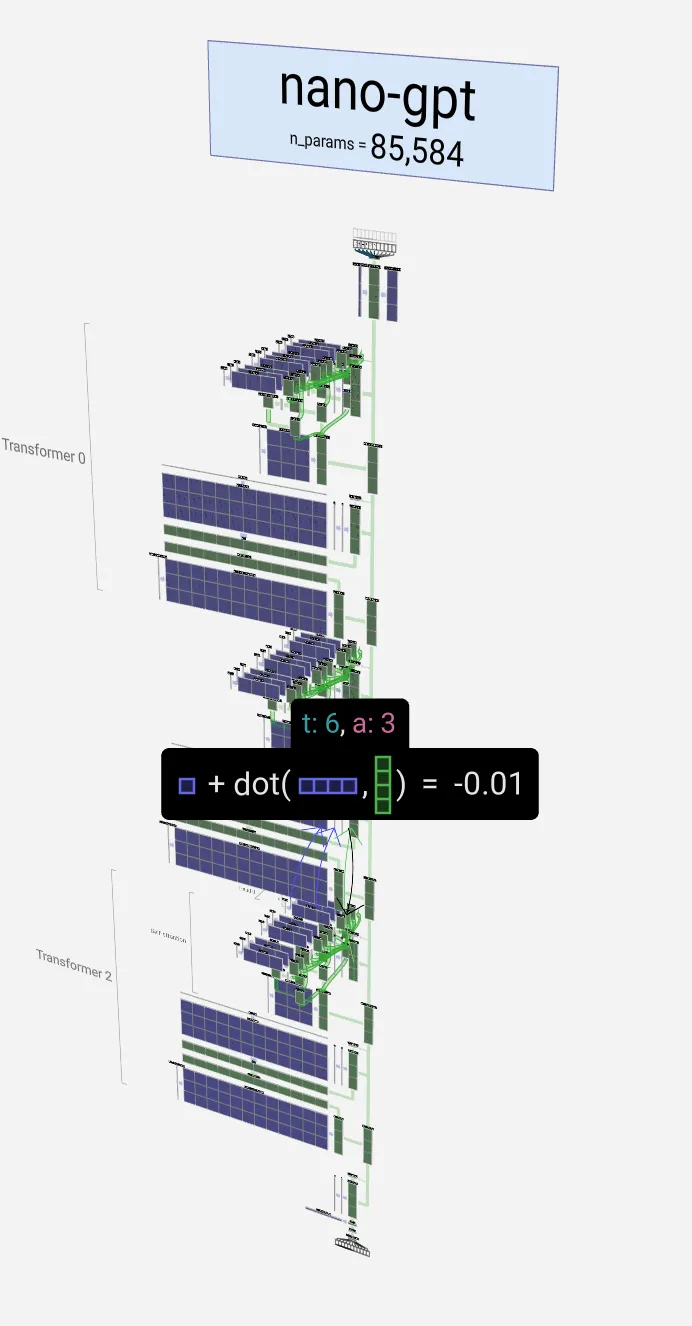
Ok, when you do that across many layers (rinse and repeat), you get larger and more capable models. Here’s what GPT XL (with 1.5Billion parameters) looks like in comparison. If you are wondering, the small green spot that you may or may not see under “nano-gpt” is the smaller model).
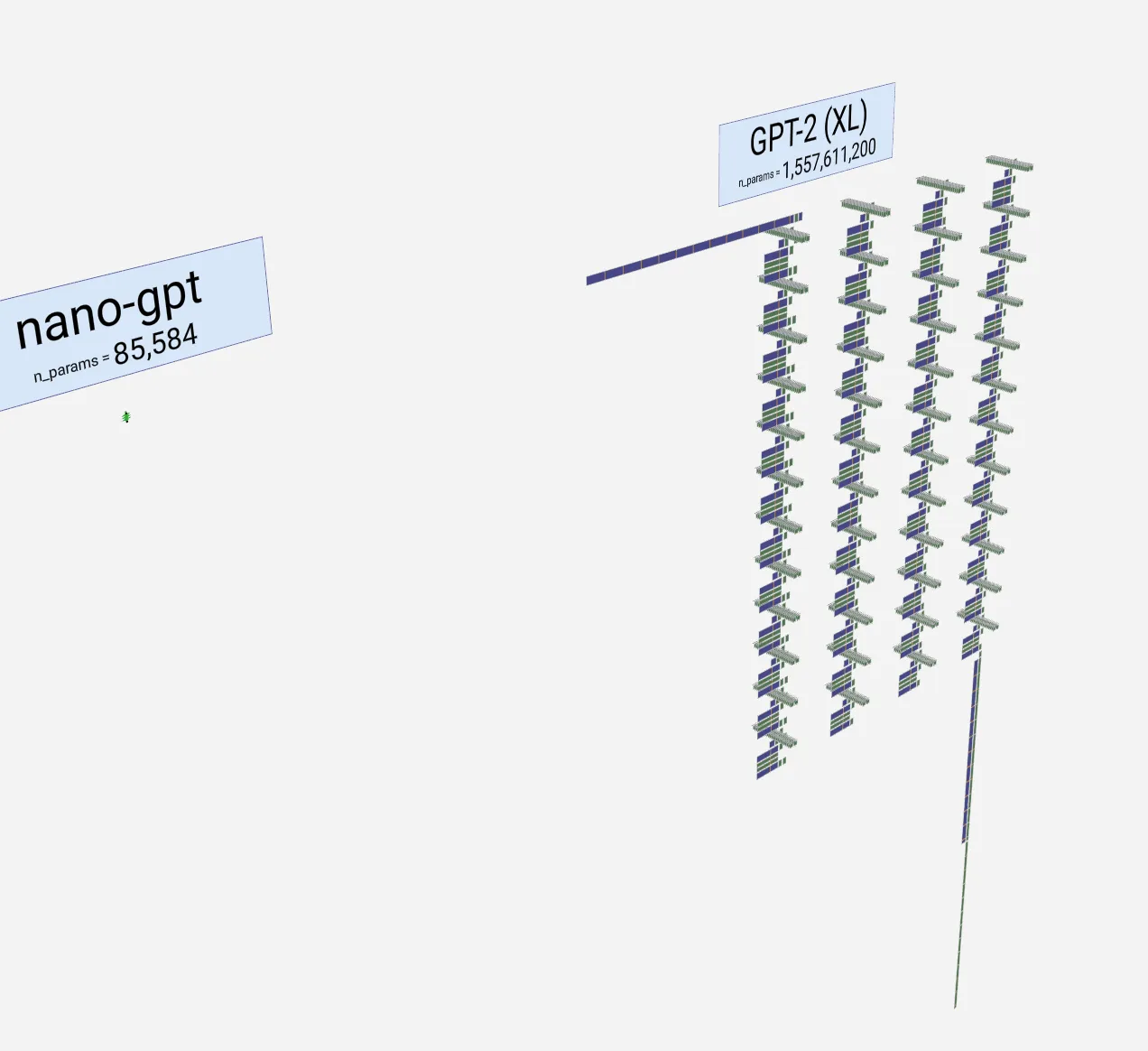
Now you can imagine what very large models look like, how compute intensive they would be for training and inference. For example, the PalM model is 540B parameters! The recent Cohere command model with 100B+ parameter model is a new model doing great at current open leaderboards even compared to proprietary models:
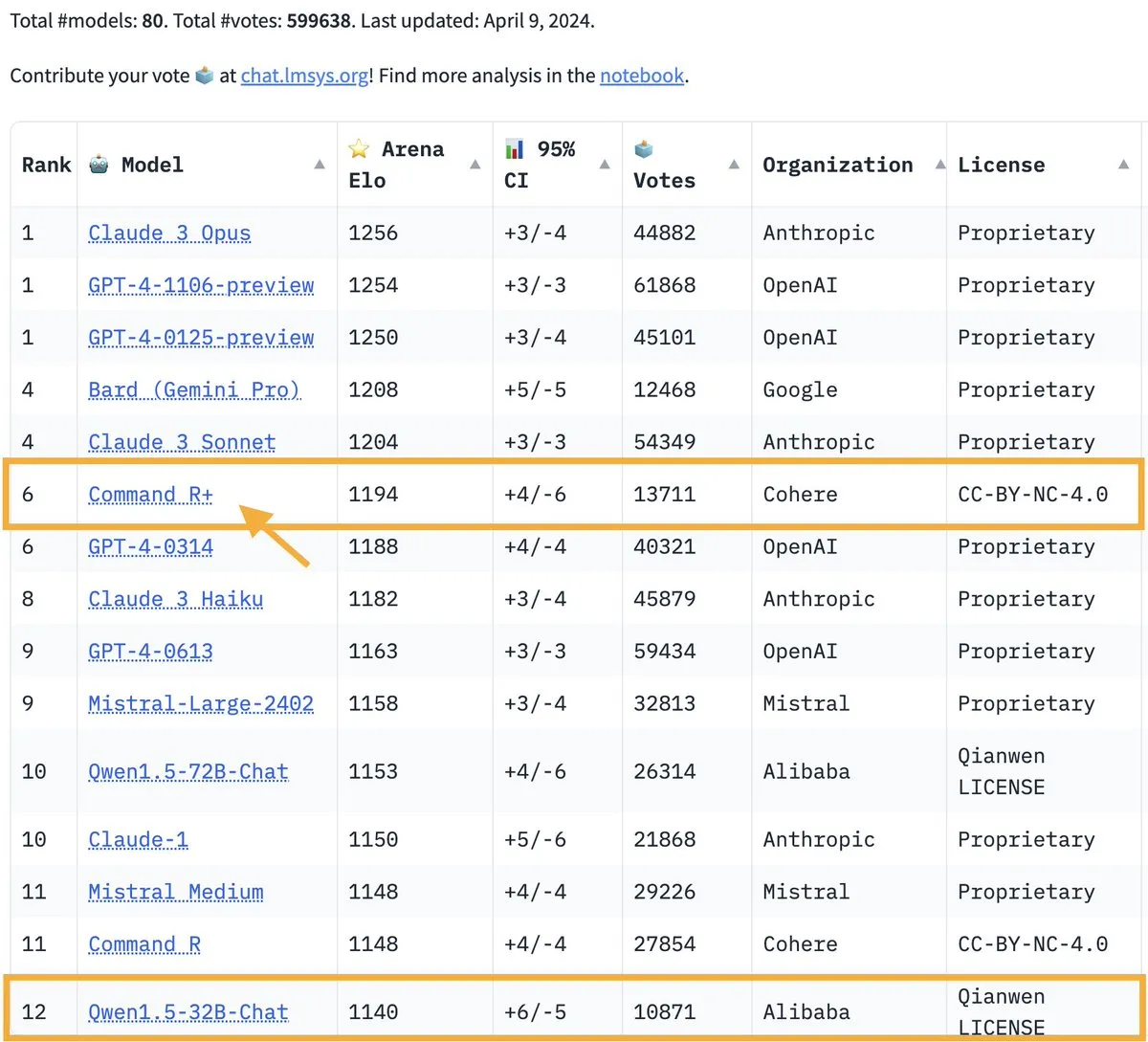
source: original tweet here - https://twitter.com/lmsysorg/status/1777630133798772766
And you guessed right, all those models you see up there are transformer based with some proprietary (or sometimes open, thanks Cohere) architectural choices. Here’s how you can explore the cohere model if you’re interested through the transformers library:
An easy way to look at what’s actually happening through the layers is visualization, although this may not be scalable to very large models. Here we’ll try out a library called bertviz:
First, we initialize the model (
from_pretrained, meaning load from Huggingface hub). Then, we’ll use the simple show function of the neuron view capabilityUsing the drop down lets you select the layer (here we have 12 layers), and the attention head you want to introspect:
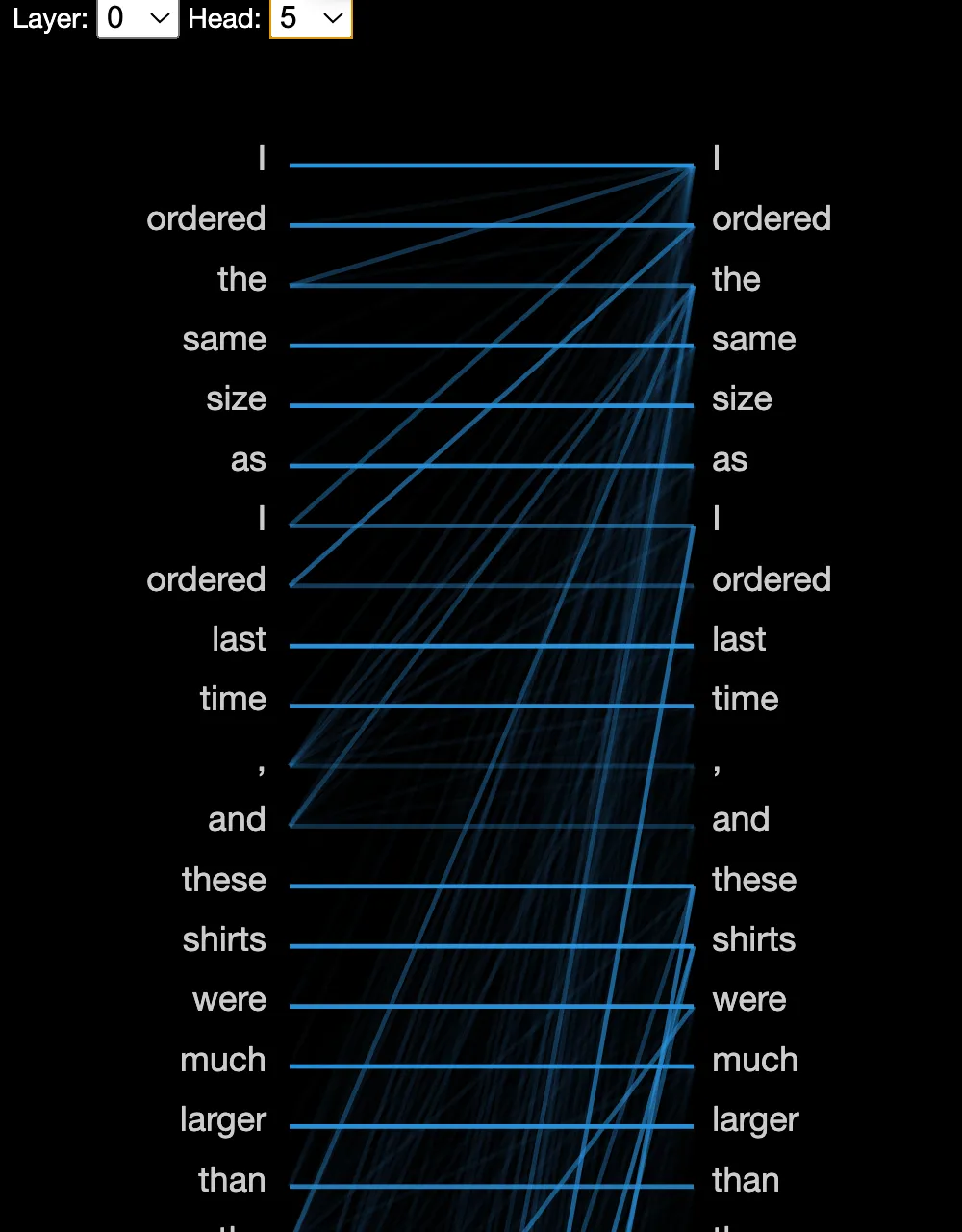
Hovering on a word gives you the high level attention map, and further clicking a token on the left side actually expands out the calculations to show you which tokens are being attended to via the softmax layer at the end.


Here we see that the word “previous” maps (see light lines) to “I”, “ordered”, “shirts”. In the expanded image above, the word “larger” maps to relevant tokens like “much”, “ordered”, “same”. The next token selected depends on the output probability over the entire vocabulary of the model, which is fixed. This is great, but we can’t do this at every layer, and head, especially for a large model, and this is why we still rely on large benchmarks for interpretability though high level scores. Also, “Attention is not explanation” - https://arxiv.org/pdf/1902.10186v3.pdf
While attention mechanisms have consistently boosted performance on natural language processing tasks, we perhaps shouldn't be too surprised that they seem to fall short in providing true explanations for model predictions. The researchers found that attention weights often did not align well with gradient-based measures of feature importance and that permuting the attention distributions still yielded similar model outputs. This implies the attended tokens may not actually be the ones "responsible" for the predictions as the attention visualizations might suggest.
Here’s a news item used in the paper above:

Here’s the adversarial example:

Here’s another example, but focusing on what the premise is related to:

And the adversarial output:

Although the output predicted is the same, the model attention is quite different! When you have a complex encoder that can entangle inputs in intricate ways, visualizing which specific words received high attention weights and trying to rationalize the model's behavior from that is likely to be misleading. At the end of the day, attention aims to improve performance, not provide a transparent window into the reasoning process. So while attention has been a powerful tool, we should be cautious about overinterpreting its visualizations as true explanations of what factors drove a model's decisions.
this post explored the Transformer architecture and self-attention mechanism that have driven recent (?) breakthroughs in deep learning across various domains. While extremely effective, Transformers face computational challenges with very long sequences, leading researchers to explore alternative architectures like the promising Mamba model based on structured state space models. Despite their advantages, Transformers' self-attention still provides powerful modeling capabilities for capturing long-range dependencies. Ultimately, the choice between architectures will depend on factors like the application domain, sequence lengths, and available computational resources in this rapidly advancing field, but it definitely looks like Attention is here to stay!
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.