Coding Perspective: PartyRock App Development with Amazon Bedrock APIs
An alternative approach to building Gen AI applications using Amazon Bedrock -architectural considerations & model selection.
Published Apr 10, 2024
Last Modified Apr 15, 2024
PartyRock serves as an Amazon Bedrock Playground, providing a fast and enjoyable platform to learn about Prompt Engineering and Foundational Models (FMs) for developing functional apps with generative AI. It offers a code-free app builder, allowing users to experiment with prompt engineering techniques and review generated responses while creating and exploring various applications. The PartyRock generative AI Hackathon garnered significant participation, reflecting its global popularity.
During the hackathon, an intriguing bonus challenge was presented, inviting participants to explore an alternative development scenario for building applications using Amazon Bedrock in the absence of PartyRock, This prompted me to reflect on alternative development scenarios using Amazon Bedrock, given my background in information science and interest in coding.
Amazon Bedrock provides a fully managed service offering high-performing foundation models (FMs) from leading AI companies through a single API. Experimentation with top FMs for various use cases is simplified, allowing for customization with relevant data using techniques like Retrieval Augmented Generation (RAG).
Build With AWS simplifies the selection of AWS services for users' applications. By inputting project details, users receive a tailored list of AWS services, along with step-by-step guidance on integration. The app also offers access to AWS resources and features a built-in chatbot for real-time assistance.
- AWS cloud account with access to Amazon Bedrock.
- To use Amazon Bedrock, you must request access to BedRock's FMs (configure IAM policy to access Bedrock APIs). You may also have to submit your usecase to access a few models from Anthropic.
- For experimenting with this use case, I chose Amazon Titan Embeddings G1 - Text and Anthropic Claude foundational models.
- I had my code running in us-west-2 (Oregon) region and I used Amazon SageMaker studio for simplicity.
- To use BedRock APIs, python was installed.
- Install the boto3 and botocore AWS SDK for python (Boto3)
- Necessary Supporting Libraries: FAISS (Facebook AI Similarity Search) and LangChain (framework for developing applications powered by language models.).
In designing my GenAI application, several architectural considerations were crucial to ensure its effectiveness and usability, particularly given the need to handle domain-specific and proprietary data. Here, I'll delve into the architectural decisions made to address these requirements:
My application needed to access and utilize domain-specific and proprietary data effectively, such as the most relevant products and services offered by AWS. This involved querying information relevant to the application's requirements, including its machine learning and AI capabilities, the type of data used (relational or non-relational), and whether it was intended for a web or mobile application.
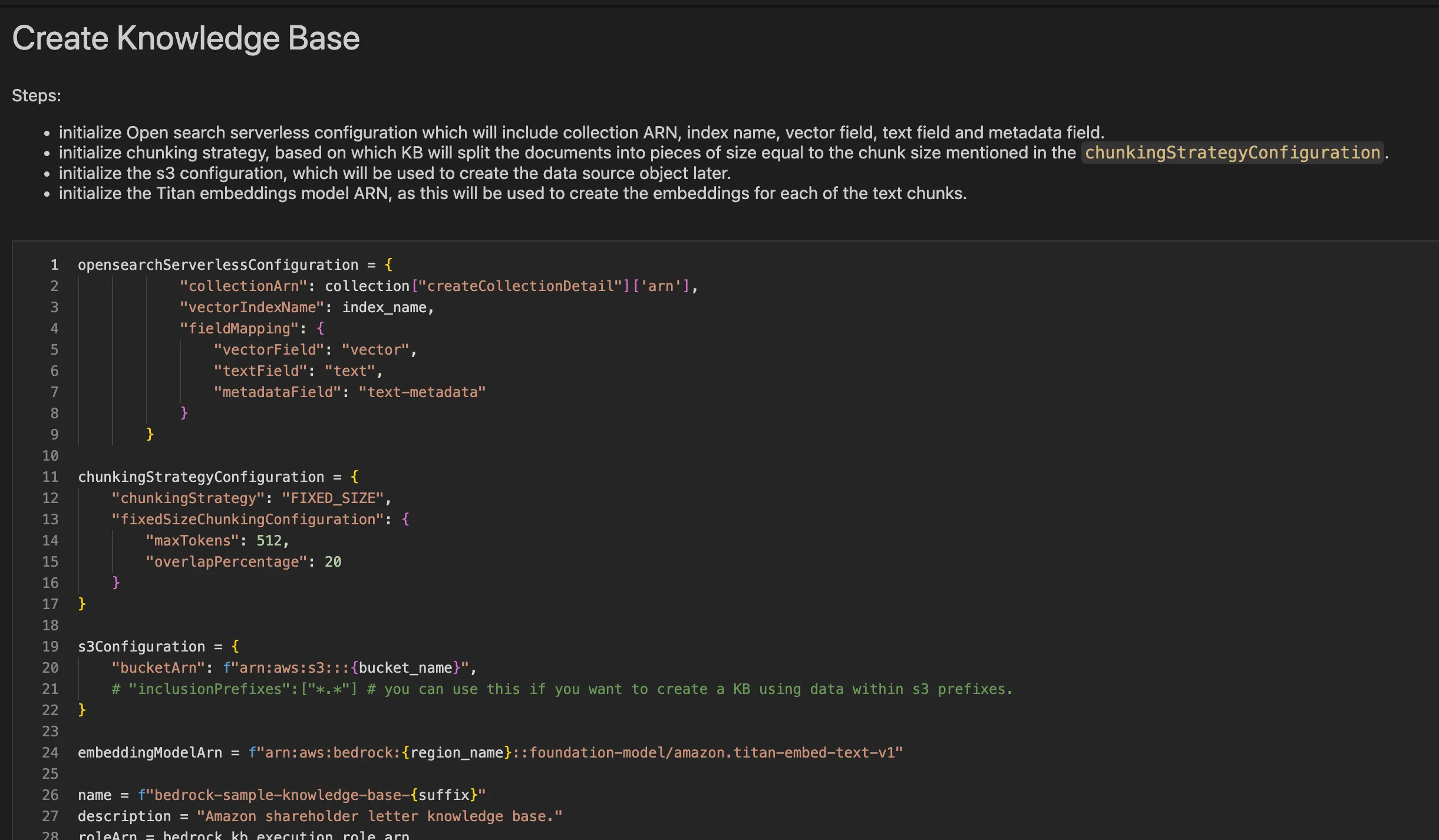
To overcome the limitations posed by the size constraints of prompt-based models, I adopted the Retrieval Augmented Generation (RAG) architectural pattern. RAG leverages Knowledge Bases within Amazon Bedrock to provide contextual information sourced from private data repositories. By augmenting prompts with relevant retrieved data, RAG enhances response accuracy and tailors responses to the user's needs.
Contextual Information: RAG furnishes foundation models (FMs) and agents with contextual information from private data sources, enabling more accurate and relevant responses.
- Improved Accuracy: By leveraging external data sources, RAG produces responses that are not only more relevant but also more accurate.
- Tailored Responses: RAG retrieves data from outside the language model and augments prompts, resulting in responses tailored to the user's specific requirements.
Knowledge Bases for Amazon Bedrock provides a fully managed capability to implement the RAG workflow, from ingestion to retrieval and prompt augmentation. I created a knowledge base by connecting an S3 bucket containing documentation for AWS services and products.
The ingestion process involved splitting data into smaller chunks, generating embeddings, and storing them in the associated vector store. I utilized open-source tools like Lang Chain to effectively implement the RAG pattern on the knowledge base.
Using the Retrieve API provided by Knowledge Bases for Amazon Bedrock, user queries were converted into embeddings and searched within the knowledge base. The relevant results, including retrieved text chunks and relevance scores, were obtained, offering more control over building custom workflows.
In my exploration of foundational models for my GenAI application, I experimented with three primary models Amazon Titan, Mistral AI, and Anthropic's Claude.
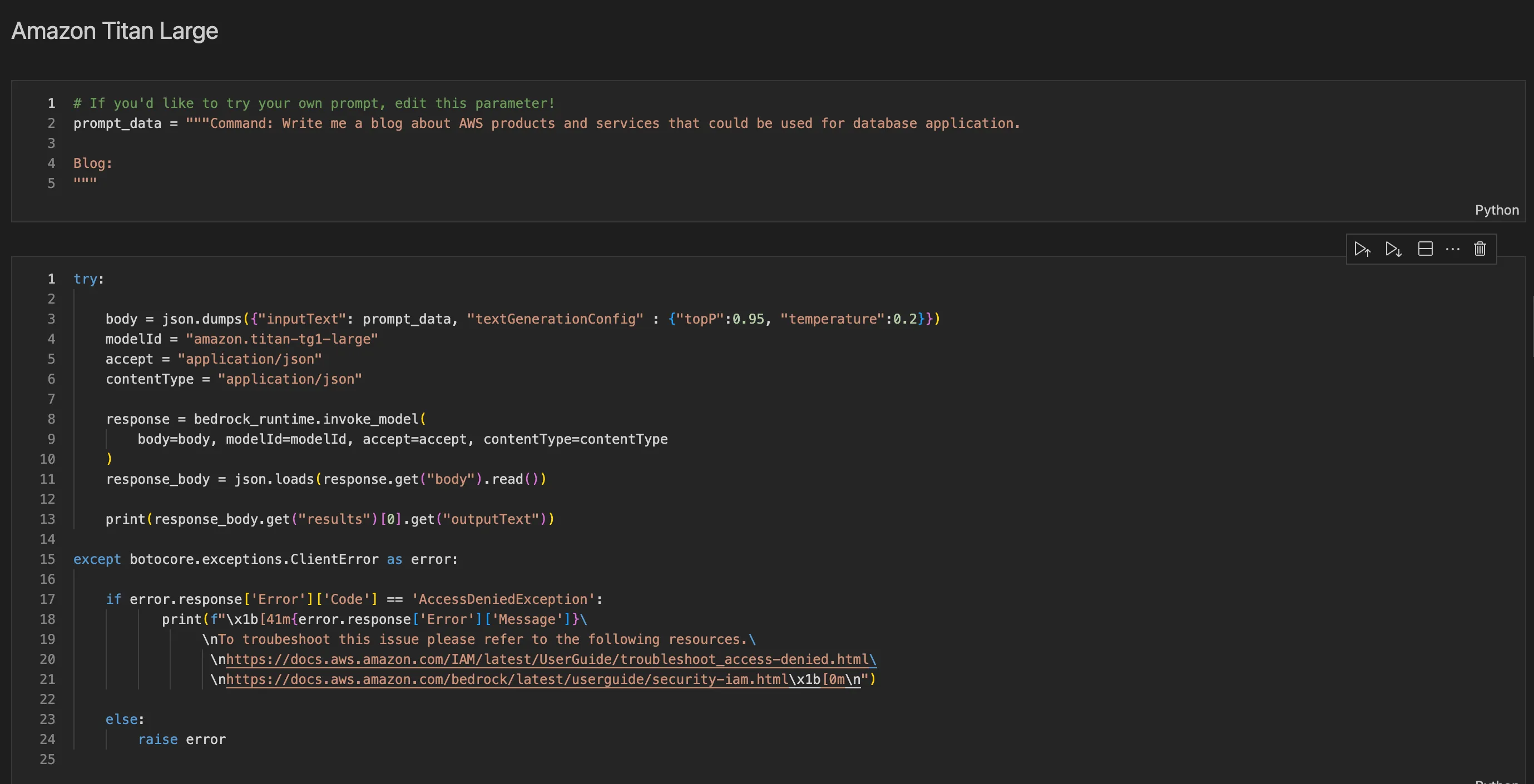
- Amazon Titan:
- Description: Amazon Titan foundation models offer a wide range of high-performing image, multimodal, and text model choices through a fully managed API.
- Features: Pretrained on large datasets, Amazon Titan models are powerful and versatile, supporting various use cases while ensuring responsible AI usage.
- Customization: These models can be used as-is or customized with proprietary data to tailor them to specific application requirements.
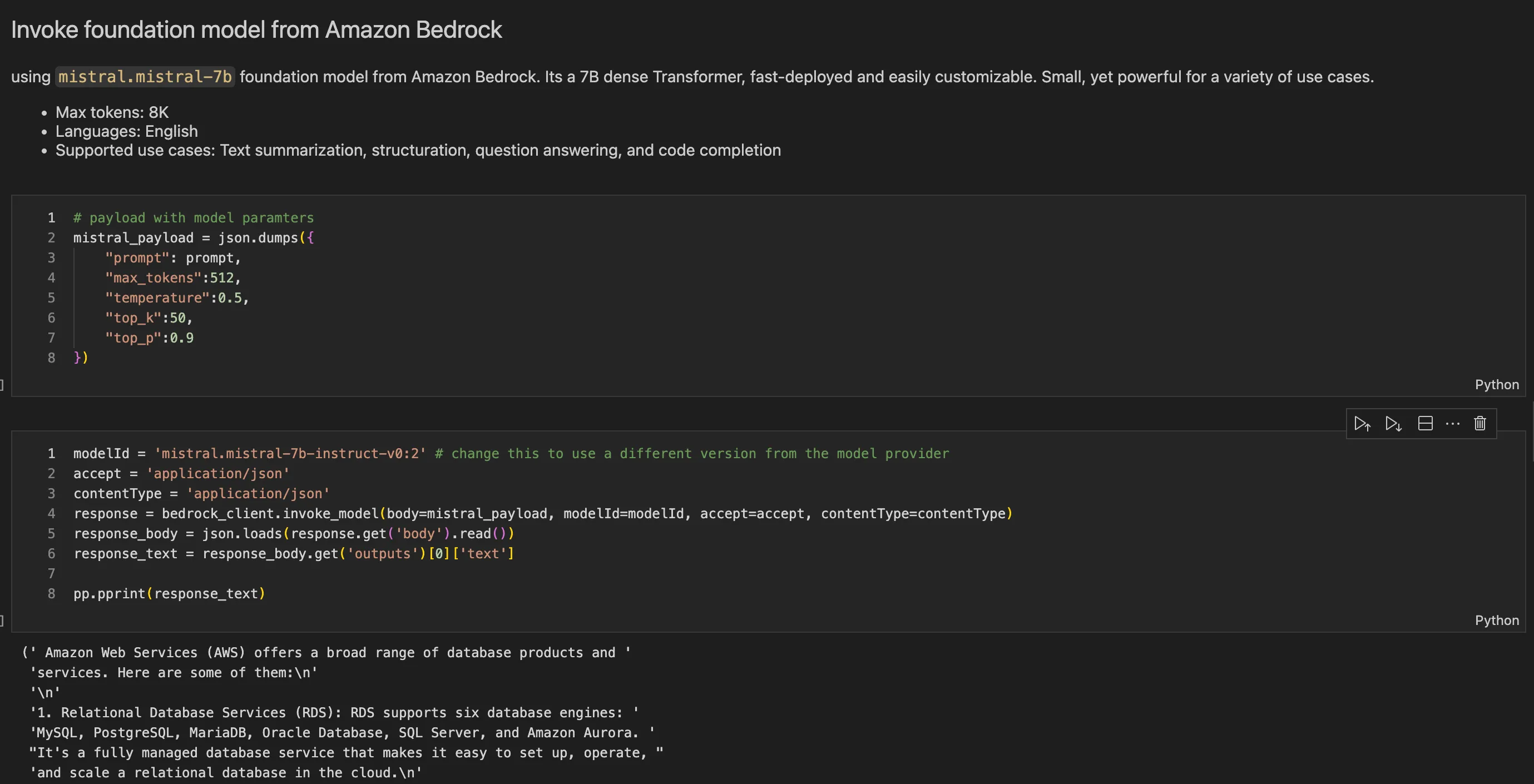
- Mistral AI :
- Description: Mistral AI is committed to advancing AI technologies and elevating publicly available models to state-of-the-art performance.
- Features: I utilized the Mistral 7B model, a compact yet potent dense Transformer suitable for various tasks, including text summarization, question answering, and code completion.
- Customization: Mistral AI models are easily customizable and offer support for multiple languages, making them adaptable to diverse use cases.
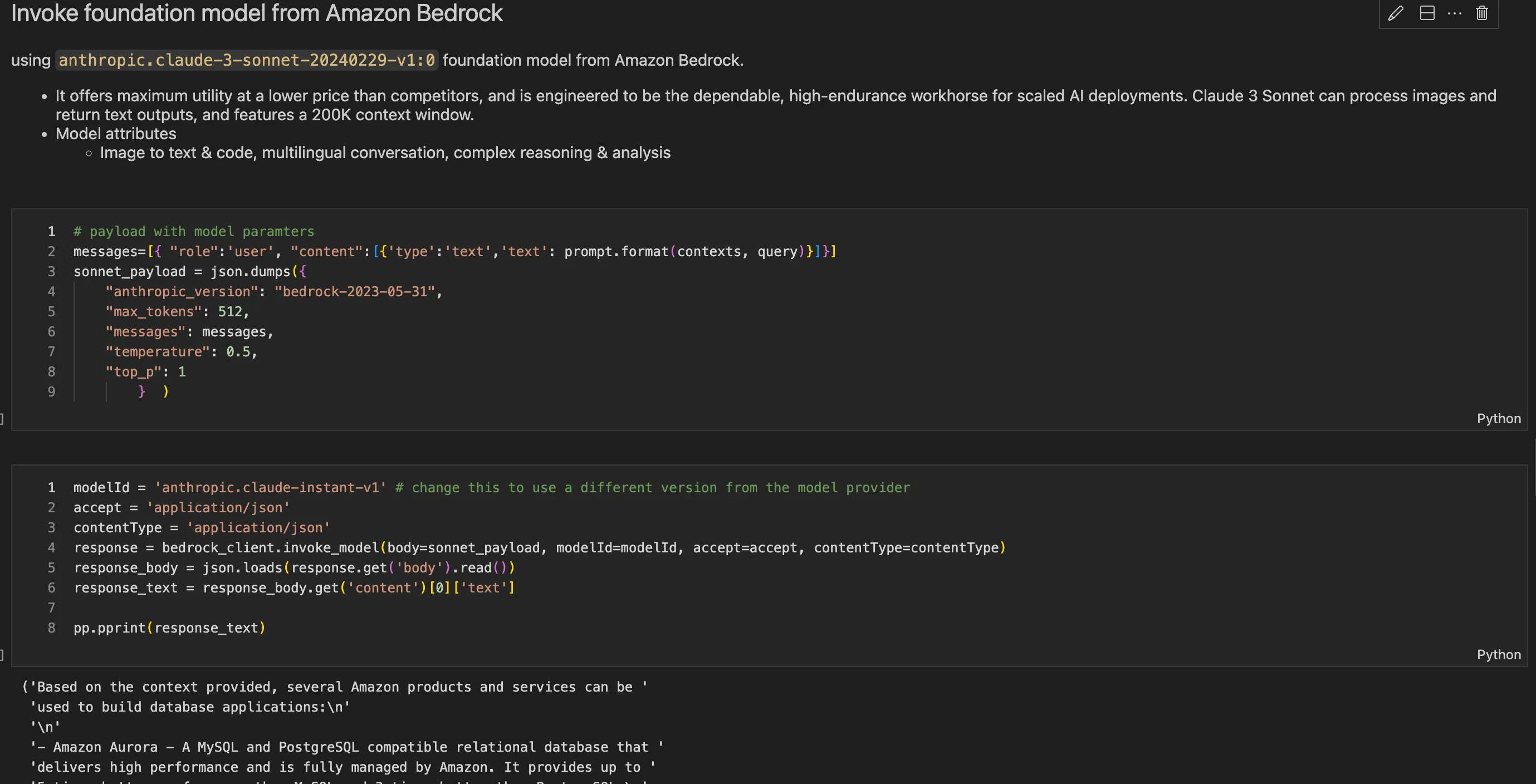
- Anthropic's Claude:
- Description: Anthropic's Claude represents the cutting-edge of large language models, designed to prioritize speed, cost-effectiveness, and context understanding.
- Features: Claude is built on Anthropic's research into creating reliable, interpretable, and controllable AI systems, excelling in tasks such as dialogue generation, content creation, and complex reasoning.
- Customization: I opted for Claude Instant version 1, a faster and cost-effective option with a generous max token limit of 100K. It supports multiple languages and is suitable for various tasks, including text analysis, summarization, and document comprehension.
Comments
Log in to comment