Dolly, Miley, or Beyonce? I asked the new Chat With Your Document feature in Amazon Bedrock.
In this article, I detail how the new Chat With Your Document feature in Knowledge Bases for Amazon Bedrock helped me learn more about music from the 70s.
Veliswa Boya
Amazon Employee
Published May 2, 2024
Last Modified Nov 1, 2024
Editor's Note: This post has been updated as a contribution to the hackathon that AWS is running through the month of November. More details on how to participate at the end of this post.
The revival of Dolly Parton's original song from the 70s Jolene, first by Miley Cyrus, and most recently by Beyonce, had me curious to learn more about music from this era that still has so much influence on what we listen to today.
Recently, Amazon Web Services (AWS) announced a new feature that gives the ability to chat with your document with zero setup in Knowledge Bases for Amazon Bedrock. With the chat with your document feature you can securely ask questions on a single document, make an analysis, or create a summary without the overhead of setting up a vector database, ingesting data, or retraining a model, making it effortless to bring own data to generative AI. All you need to do is provide a relevant data file as input and choose your Foundation Model (FM) to get started.
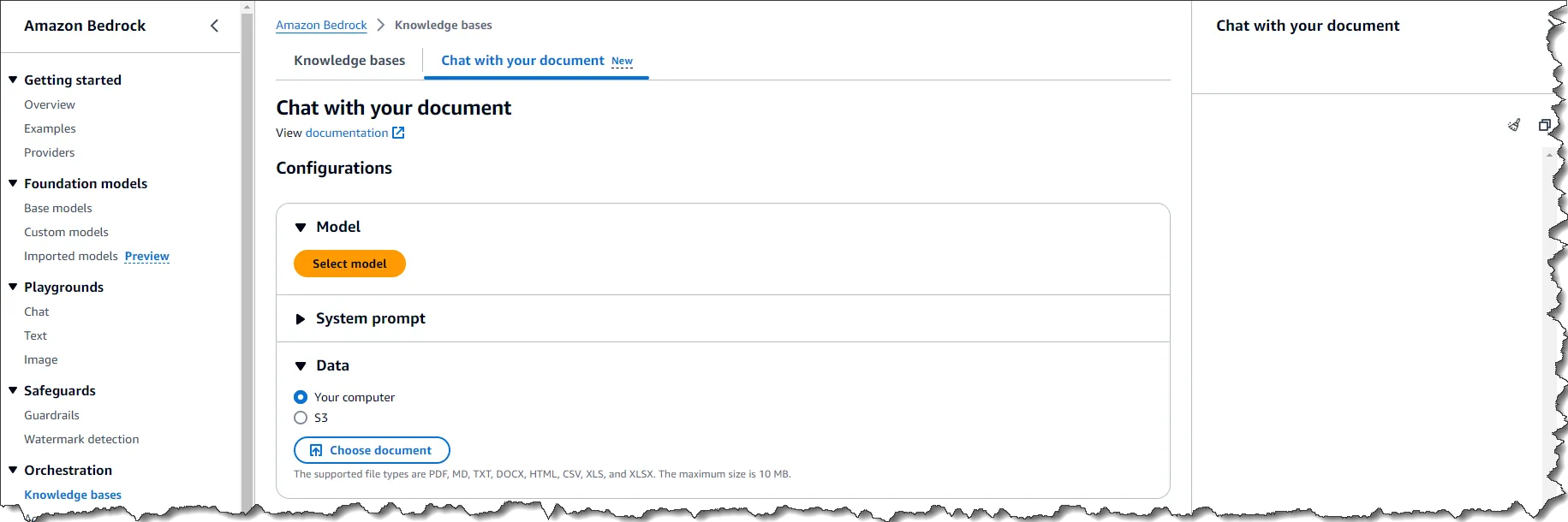
- You can ask questions on a single document with zero setup.
- Supported file formats are .pdf, .md, .txt, .docx, .html, .csv, .xls, and .xlsx.
- File size must not exceed 10 MB and contains no more than 20,000 tokens.
- Chat with your document either in the Amazon Bedrock console, or the Amazon Bedrock
RetrieveAndGenerateAPI (SDK). - Select the document for your chat either from an S3 bucket, or your local device.
- Anthropic's Claude 3 Sonnet is the only model currently available in this functionality.
- A text-heavy file, that is much smaller than 10MB, can potentially breach the token limit.
- Your document or its data won't be stored after use.
So, I asked Claude 3 Sonnet in Amazon Bedrock Chat Playground for a list of Top 100 songs from the 70s, then uploaded this list in .docx format to an S3 bucket and asked it a couple of questions using the AWS SDK.
I could have used any Text model besides Claude 3 Sonnet here. Jurassic-2 Ultra gave me similar results, and Command Light gave me a very different list as it seemed to consult a different chart than Claude 3 Sonnet and Jurassic-2 Ultra. In the end, it's based on personal preference that I went with the list from Claude 3 Sonnet. Also note that you need access to the models before you can use the models, whether in the Playground or chat with document.
Here are the steps I followed and the relevant code for each step:
Instead of local device, this setup is for a document that's located in an S3 bucket so I provide the document S3 URI.
Here's the list of top 100 songs I retrieved earlier.
Here are some of the questions I asked, and the corresponding answers, starting with the most obvious question :)

As mentioned at the beginning of this post, chat with your document uses your uploaded document to answer questions. This response is expected as interestingly enough, Dolly Parton's Jolene is not in the list of 100 top songs that Claude 3 Sonnet in Chat Playground gave me earlier.
Anyway, I want to learn more, so I go on and ask more questions.

I asked for some analysis.
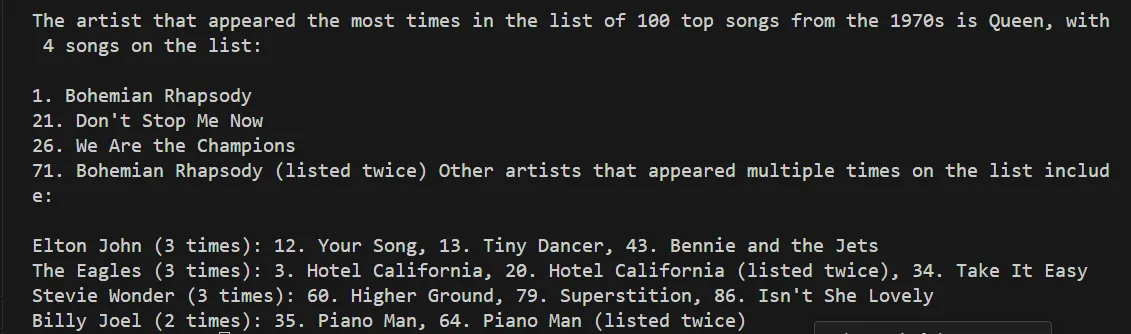
I asked for more analysis, and the result impressed me because I did not expect chat with your document to return any results on questions where the answer is not obvious.

Ok, I could have gone on for a while, because this was a lot of fun!

In this post, we looked at how chat with your document lets you consult your own data (in the form of a single document) to answer questions, make an analysis, create a summary, without the overhead of setting up a vector database or ingesting data, making it effortless to bring own data to generative AI.
Based on my experiences when I started to play with this feature, chat with your document is not suitable for documents with a lot of text on them (for example, a Wikipedia page (for these, knowledge bases is more suitable)) as they can potentially breach the token limit.
- Learn more about chat with your document in Knowledgebases for Amazon Bedrock
- Find the code in our Github repository.
If you're ready to build your own game, AWS is running a hackathon through the month of November. From a simple tic tac toe game built with HTML/CSS/JS to a complex Unity game -- all skill levels and tech stacks are welcome. Join now on DevPost: https://awsdevchallenge.devpost.com!
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.