Goodbye Elasticsearch, Hello OpenSearch: A Golang Developer's Journey with Amazon Q (Lessons Learned)
In this blog post, I share my experience using Amazon Q to migrate an application written in Go to replace the backend from Elasticsearch to OpenSearch. Modernizing legacy code and migrating applications are one of the most interesting use cases for AI Coding Companion tools like Amazon Q, and here I share how this worked for me.
Published Apr 17, 2024
Last Modified Apr 21, 2024
After spending my entire career writing code in Java, about 5 years ago, I ventured myself with another programming language, and Go was my choice at the time. I can't say enough how happy I was learning Go. It was a language I could quickly learn the basics, and within a few weeks I was venturing myself writing complete apps. Personally, I think the best way to learn a programming language is building complete apps after you learn the basics. There is only so much you can learn from simple hello worlds. If you want to really learn how to use the tools from the language to solve real problems, get your hands dirty by building an app. One of the apps that I built with Go is one that performs search and analytics in a movie dataset available in the JSON format.
The app loads the dataset in-memory, store into a data store optimized for searches, and then performs different kinds of search on it. For the data store, at the time using Elasticsearch was a good idea. It was a data store I was familiar with, and getting started with it was a breeze, as both Docker images and a fully managed service called Elastic Cloud were available. However, recently I took upon the task to revive that project with a fresh version of the code, replacing the data store from Elasticsearch to OpenSearch. Before getting started with this migration, I thought about speeding up the process by counting with the help with a AI Coding Companion tool like Amazon Q. After all, my point was no longer no learn the language—but to get things done as fast as possible.
I'm happy to share that this was one of the best decisions I ever made, because I spent little time with this migration that got completed in about two days. In this blog post, I want to share my experience using Amazon Q to migrate this app from Elasticsearch to OpenSearch, the positive and negative surprises I got along the way, and what I learned that may be useful for you as well. You can find the complete migrated code here.
I started the migration of my project with the review of which parts of the code needed to be updated. The idea was to look after parts of the code that would contain references to the Elasticsearch client for Go. Using the search tools from the IDE helped me with this task, as I needed to find the code files containing references to the package
github.com/elastic/go-elasticsearch/v8.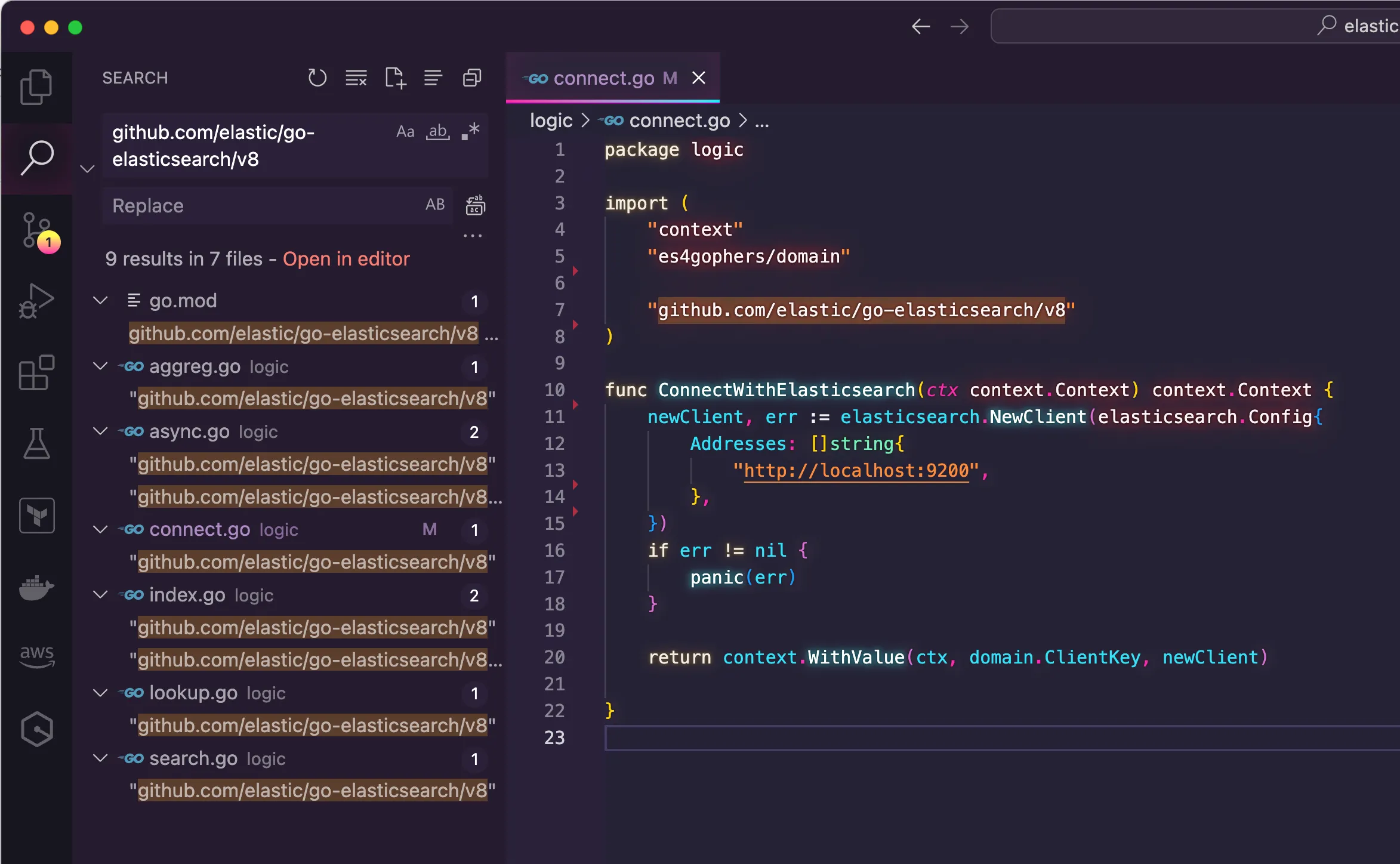
I started with the file
connect.go as it contains the logic about how to establish the connection with the data store. As my first experiment with Amazon Q, I wanted to see how much effort the tool would save me if I asked for help to migrate an entire function instead of bits and pieces of code. Therefore, I selected the entire function called ConnectWithElasticsearch() and sent to Amazon Q as a prompt. Then, I typed:"Modify the selected code below to remove the usage of the Elasticsearch client for Go with the OpenSearch client for Go, keeping the underlying logic."
To my surprise, not only Amazon Q could execute the prompt successfully, but also give some notes about how to further improve the code. Remarkably, Amazon Q was also clever enough to suggest the name of the function be changed from
ConnectWithElasticsearch() to ConnectWithOpenSearch(), meaning that it can recognize the nature of the work being done by the developer.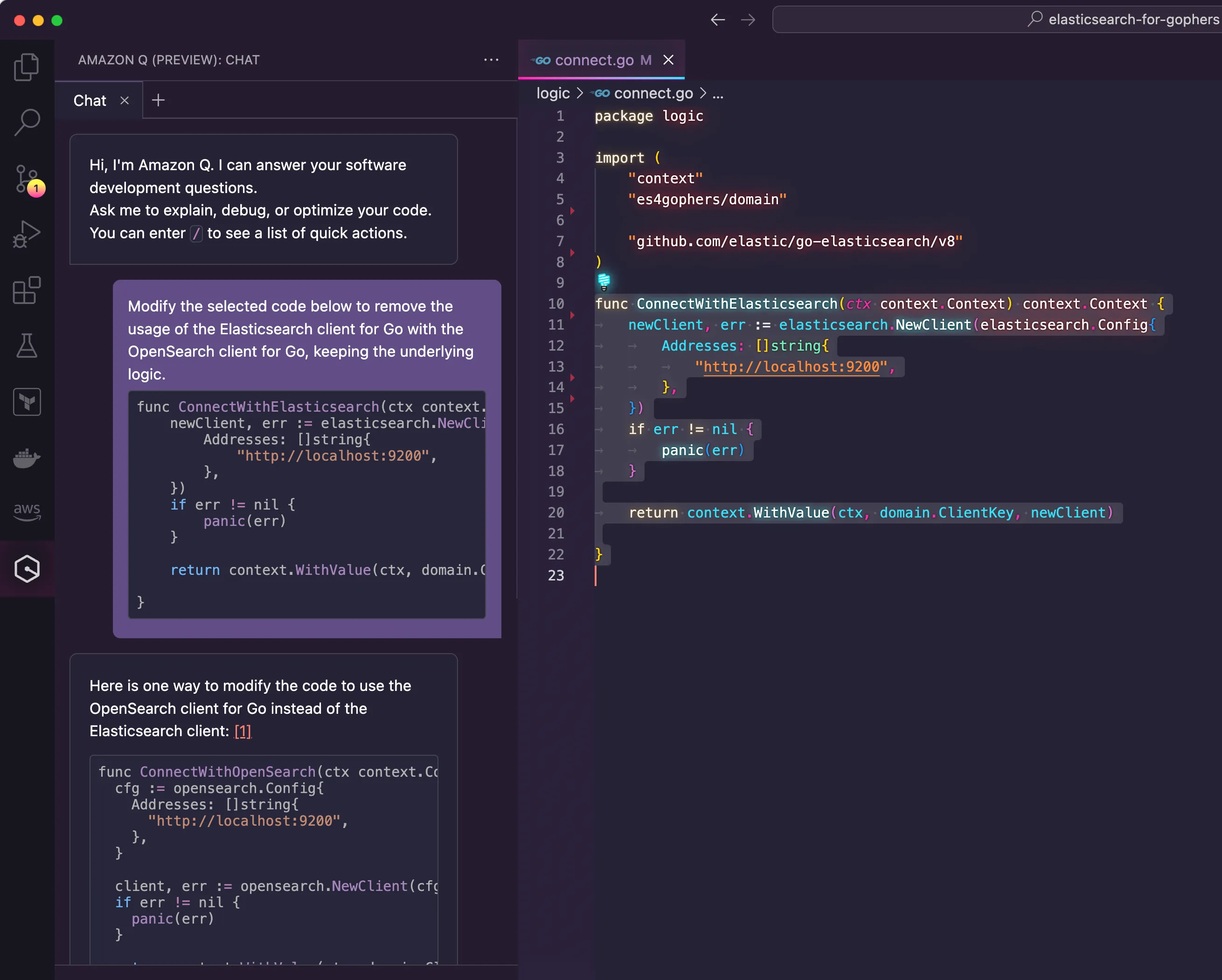
Instead of removing the previous function and just inserting the new one into the code editor, I decided to keep both functions there to compare the logic. For this case, I was dealing with a rather simple code that doesn't do much other than creating an instance of a client and storing it in the context for further reuse. But it could have been a function with a more elaborated logic, and I think it is a good idea to get both functions in place and make sure the implementation logic didn't vanish.
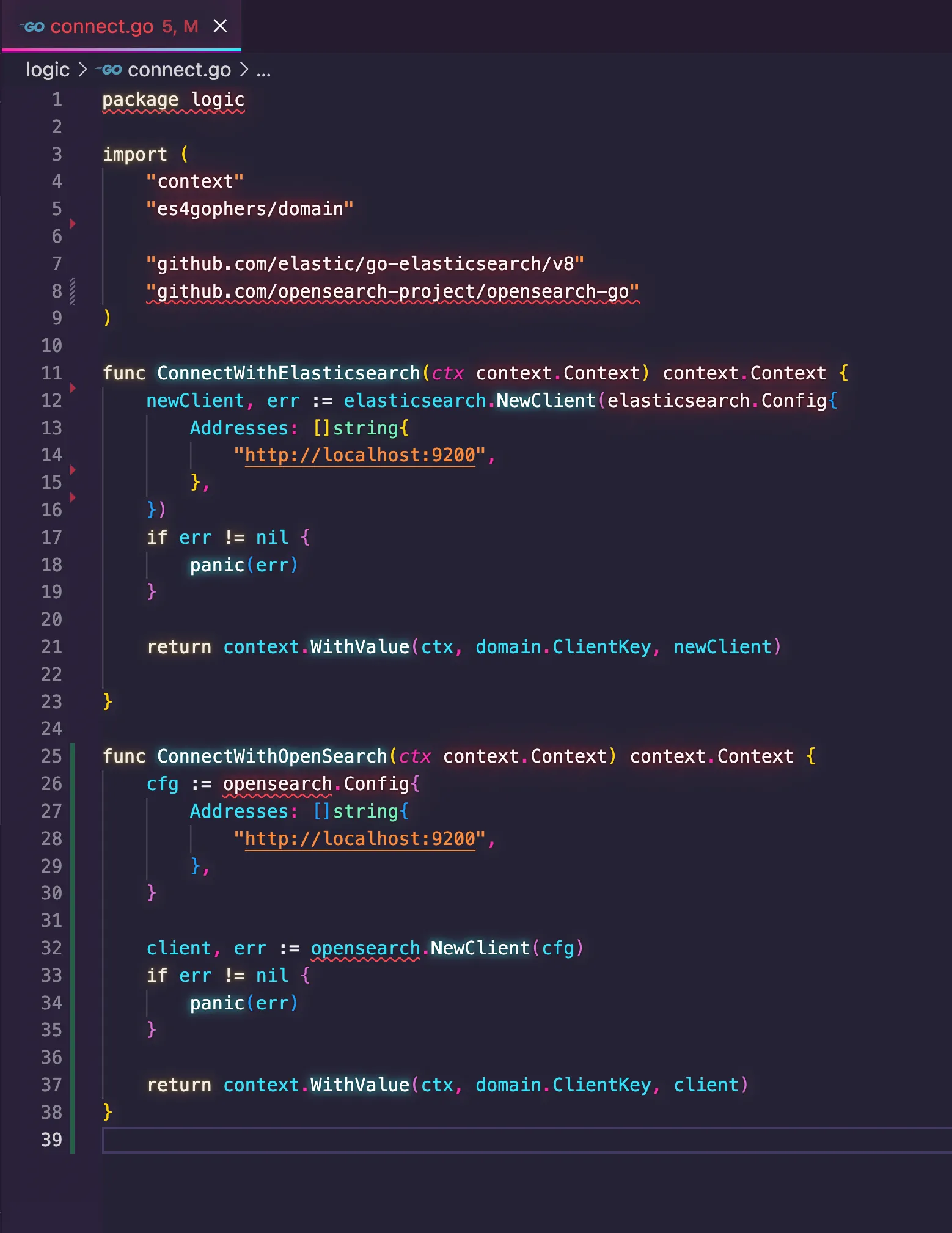
Given the compiler errors I got, I realized I needed to fix the dependencies missing before continuing. Without this, any code suggestion from Amazon Q will end up in a compilation error, as shown in the code above. Back to the time when I was learning Go, I remember struggling a lot with how dependency management work. I had come from Java, where frameworks like Maven and Gradle take care of these things. But in Go, you have to either import the dependencies manually using the
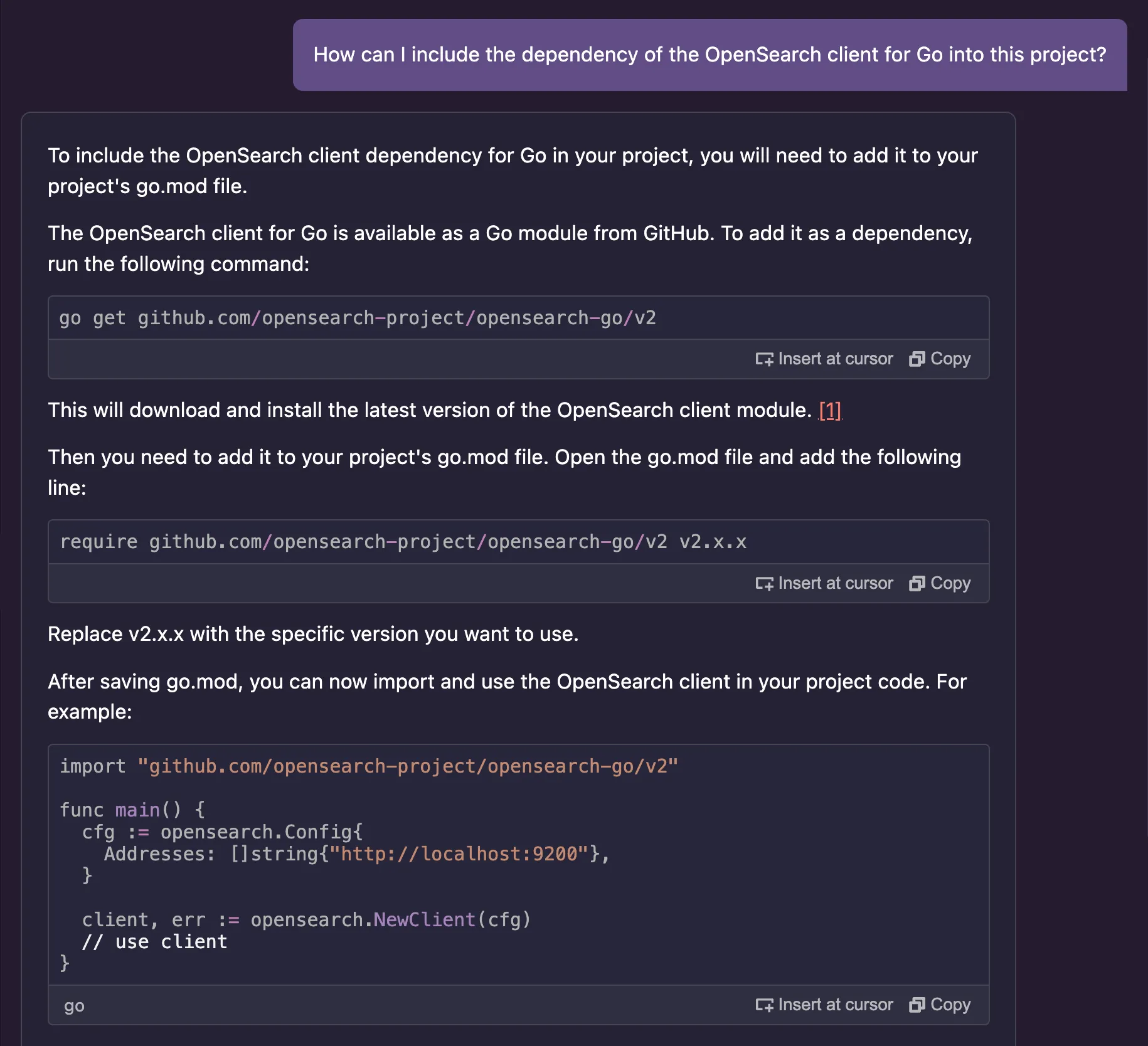
go get command, or include them into the go.mod file of your project. Either way, these are tasks that go beyond the coding part, so I wondered how much Amazon Q could help me with this.So, imbued by the spirit of curiosity, I went back to the prompt and asked:
"How can I include the dependency of the OpenSearch client for Go into this project?"
Once again, Amazon Q didn't disappoint.
After fixing the code and the dependencies, I could get my first code file successfully migrated. But then, I went back to the recommendations given by Amazon Q, and realized that beyond giving me the summary of the key changes, it also recommended some improvements in the code. It mentioned that it is a best practice to first check the state of the connection with OpenSearch before using the client to run data related tasks. Then it recommended using a
ping request to check if the client can reach OpenSearch and gave me a snippet of code showing that. I applied the snippet into my function, and here is the new version of the connect.go code.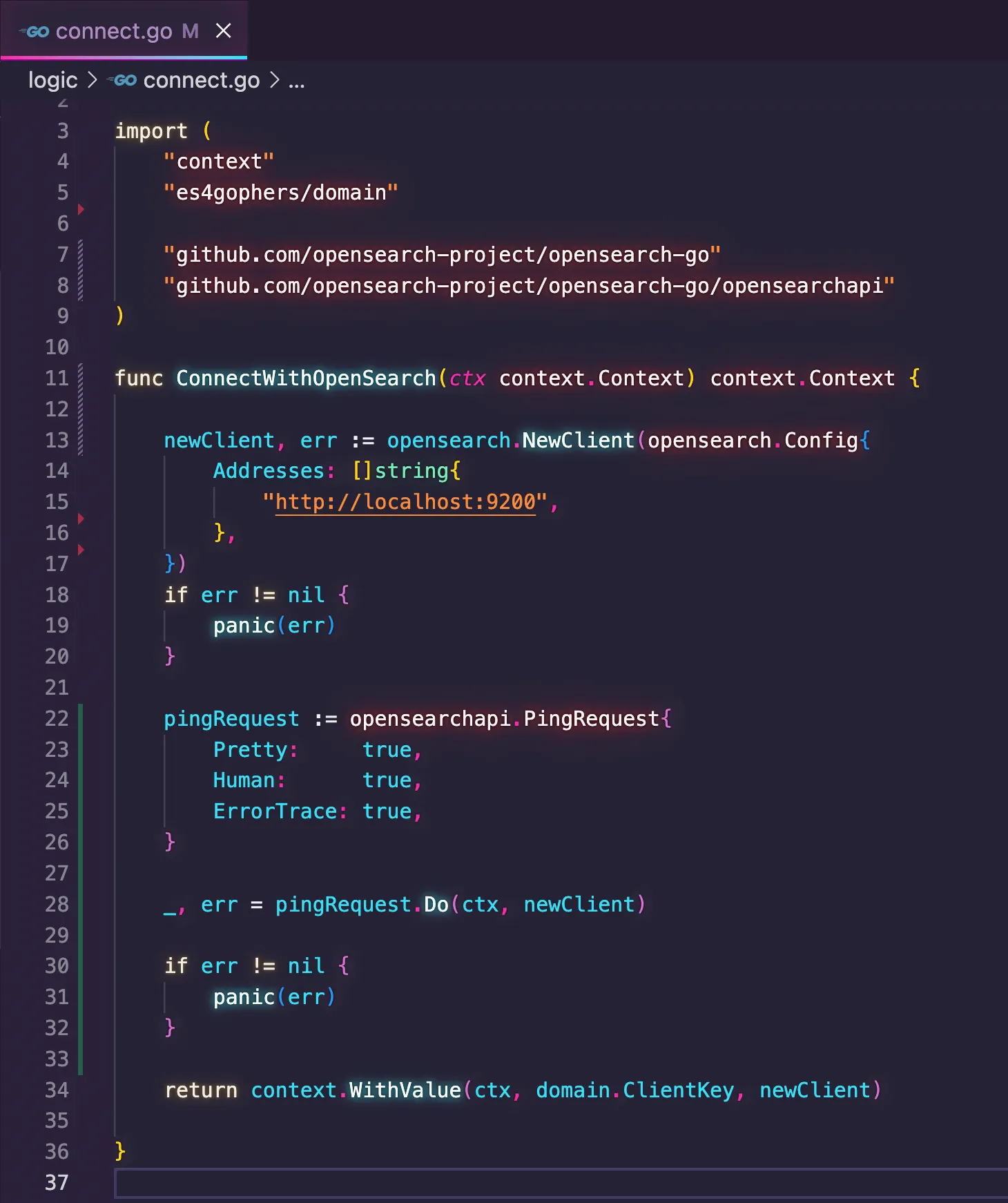
I executed a few tests with the new version of the code and, indeed, adopting the recommendation was a smart decision. Without the connection check, the code would invariably introduce the risk of breaking some important data processing logic elsewhere just because the client can't really reach the data store. To be frank, I felt a bit silly for not spotting this situation myself. But then again, I think that proves the value of Amazon Q because recommending something like that requires the understanding of two things:
- Whether the code is not doing this, and what this means for the rest of the code.
- Knowing OpenSearch provides an API to execute ping requests, and how to use it.
As far as pair programming sessions go, this is exactly the type of knowledge you would expect of another fellow developer that is helping you with a task. While you are still in charge of the task, you want your pair to spot details you are missing, and that will add value to the task beyond just get it done.
It would be naïve from anyone to think that a tool like Amazon Q would help the entire migration without any hiccups. After all, the mechanics in which these tools work are based on known AI/ML practices and technologies that are not designed to be precise. Which doesn't invalidate the value they provide, it is more a matter of properly align the expectations.
After migrating 90% of the code base using the same approach I used for the
connect.go code file, I stumped upon one edge case where Amazon Q wasn't able to help me on its first attempt. In the code file index.go, I have the implementation that takes the movies loaded in-memory and index them into the data store. Indexing is how data stores like Elasticsearch and OpenSearch call the operation of storing a dataset into the collection that will persist them durably. This is notably known in SQL-based data stores as the insert operation. This is the previous implementation using Elasticsearch.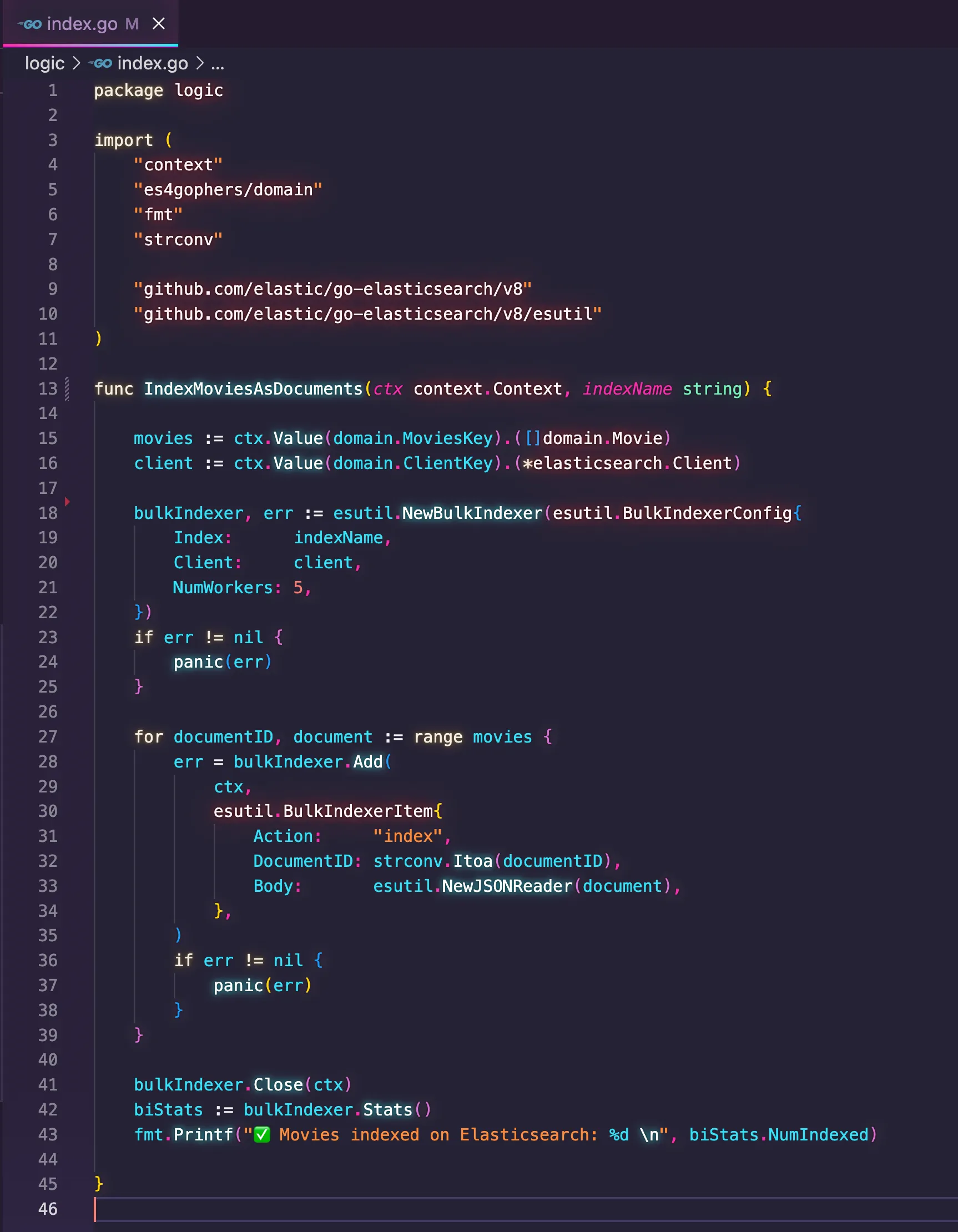
There are a few nuances in this code that need to be understood before we discuss what went wrong with the recommendation from Amazon Q. The function
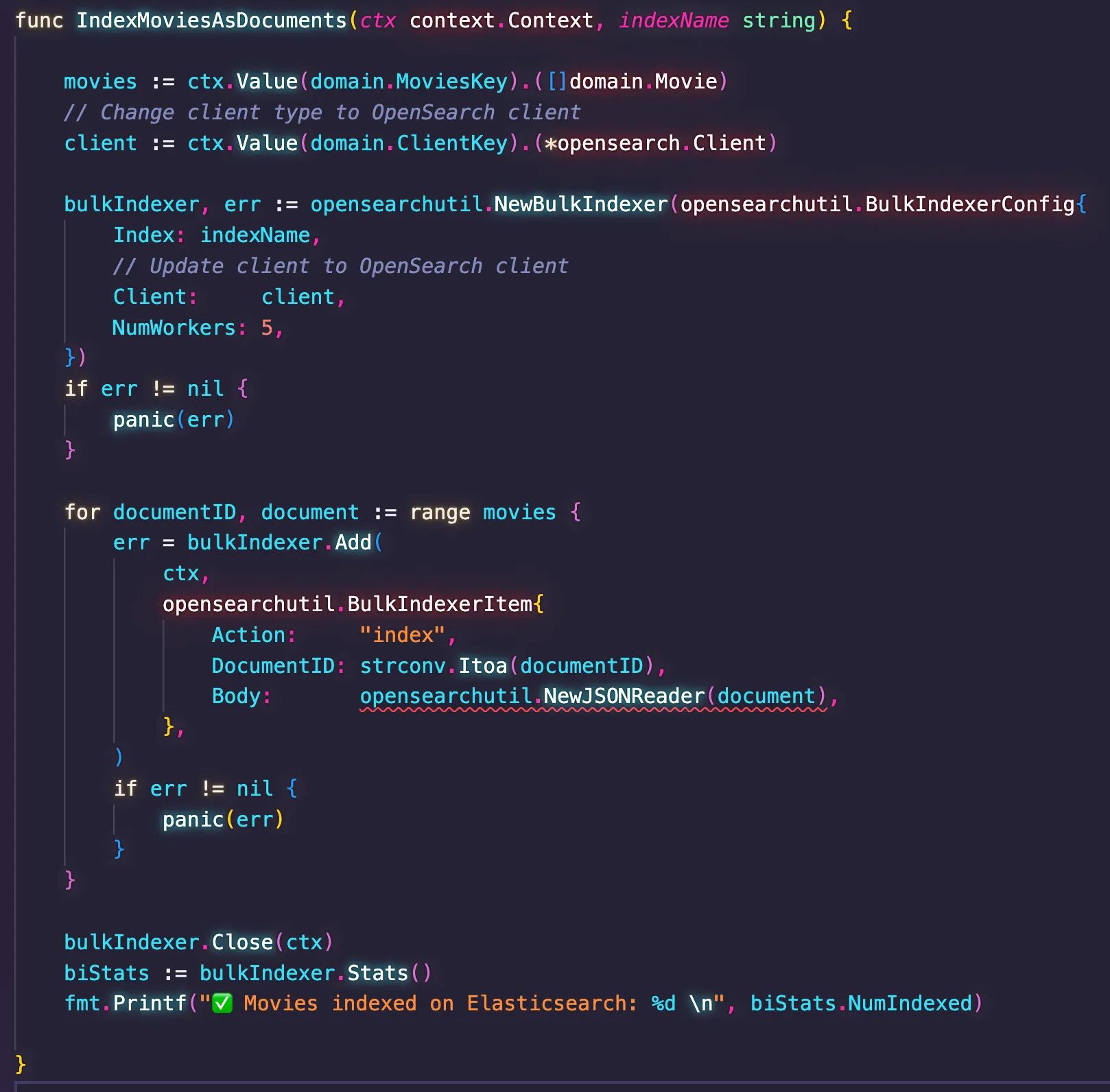
IndexMoviesAsDocuments()takes the index name as a parameter and the dataset to be indexed from the context. It uses the Bulk API from Elasticsearch to index all the movies with a single API call, which is faster than invoking the Index API for each movie, one at a time. Moreover, the Bulk API also takes advantage of Go's support for goroutines to execute the processing of the bulk concurrently, hence the usage of the parameter NumWorkers in the code. Considering there are roughly 5000 movies to be indexed, using 5 threads means indexing 1000 documents per goroutine, which provides a faster way to handle the dataset. Finally, the code also take advantage of the statistics provided by the BulkIndexer object, which allows the report of how many documents were indexed successfully.Now that you are caught up with the logic behind the code, let me share the prompt I used to start the migration to the OpenSearch client for Go.
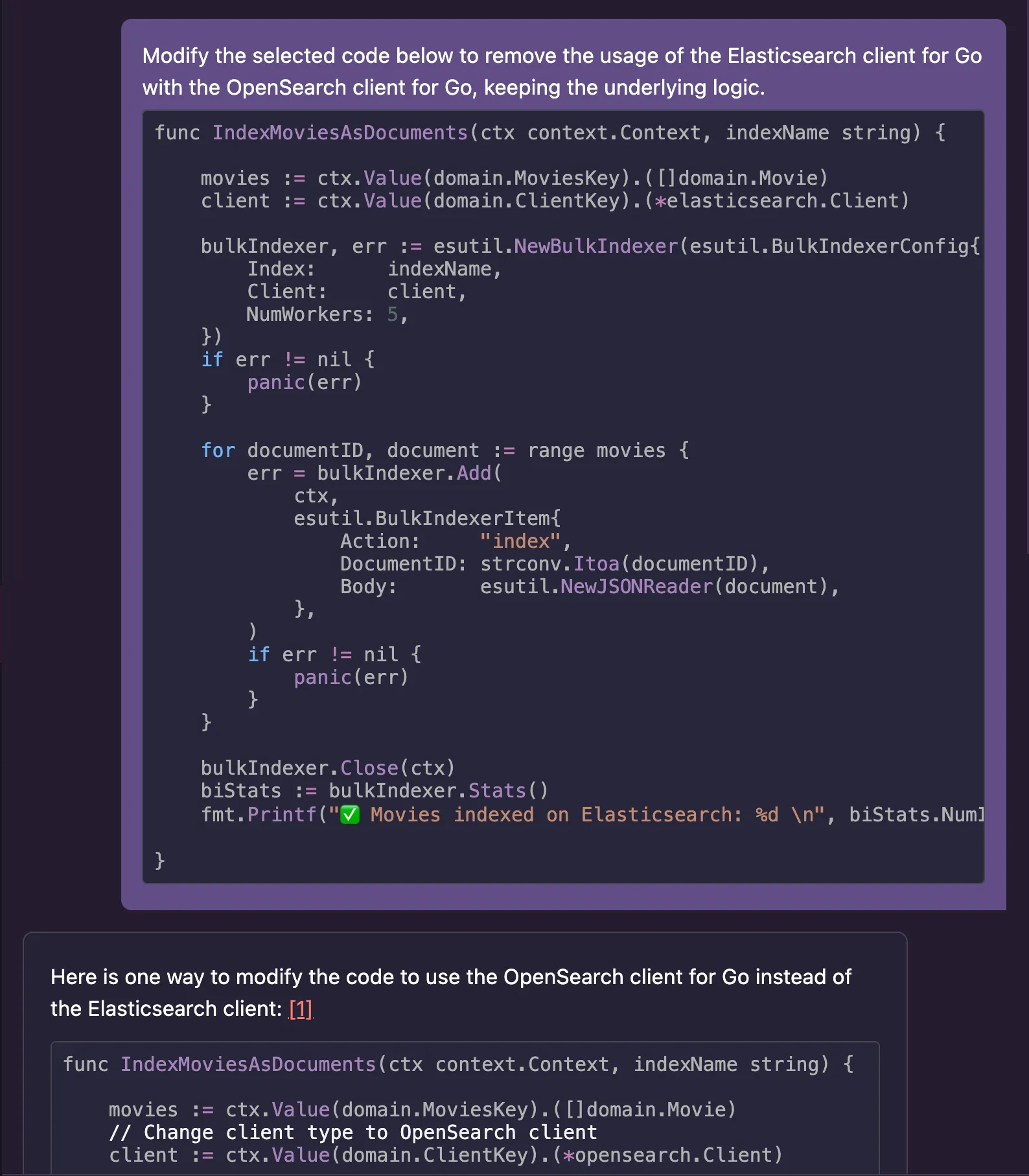
As you can see, exactly the same prompt that I used before with the other functions. However, this time, Amazon Q suggested me a code snippet that didn't fit into an acceptable solution. The suggested code snippet had a few compilations problems. Not really complicated ones—but a clear sign that something was missing.
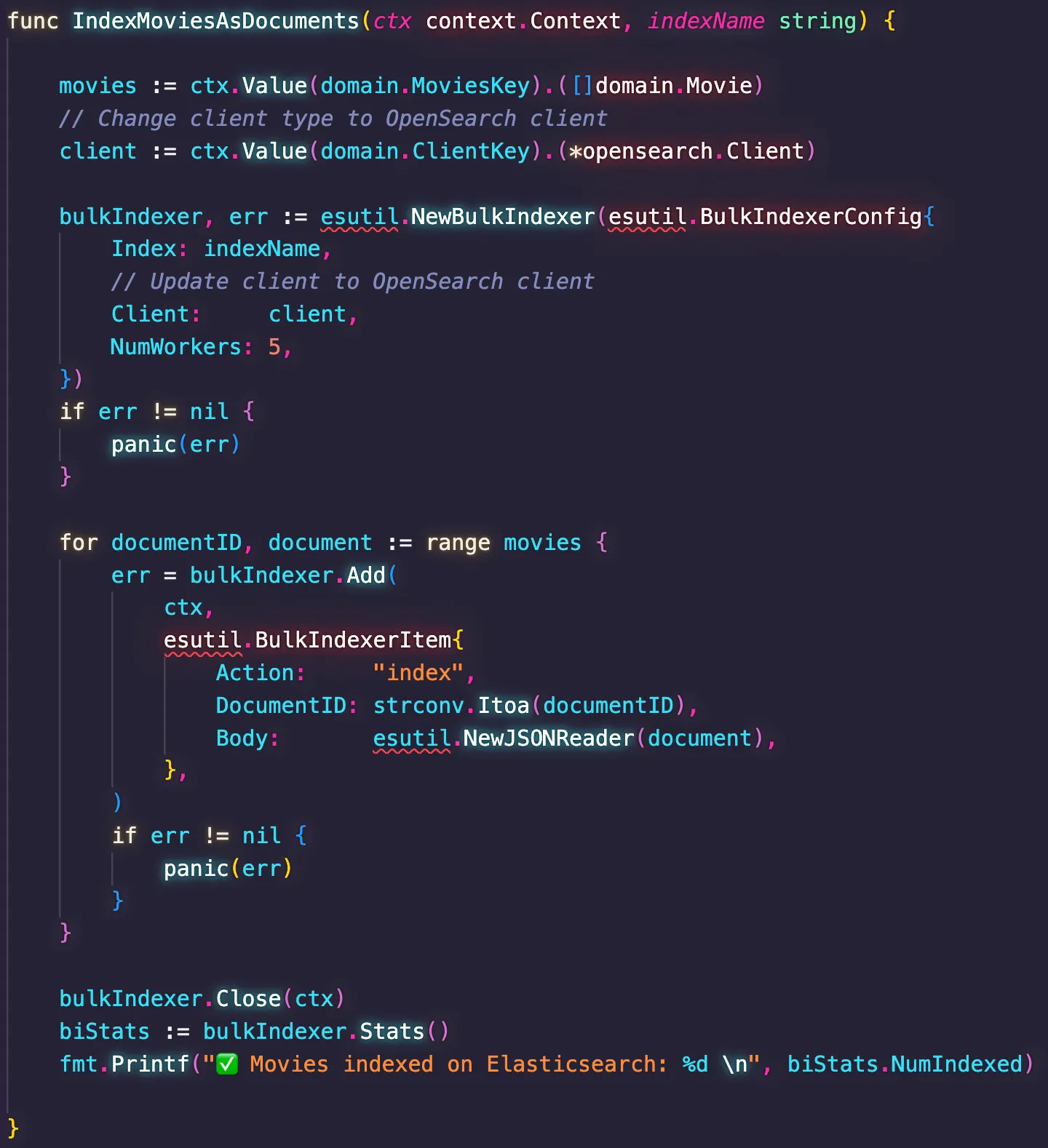
The problem here is that the package
esutil doesn't exist in the OpenSearch client for Go. Instead, developers should use the opensearchutil package, which is semantically similar but has a different name. This time, I decided to fix the problem manually as it would be faster than just creating clever prompts so Amazon Q could discern about the differences. I will provide some tips later about how to do this.After fixing this issue, I got another compilation error.
The crux of the problem lies in the mismatch of types expected by the Elasticsearch and OpenSearch clients for Go. Elasticsearch expects the body to be provided as a
io.Reader, whereas OpenSearch expects the body to be provided as a io.ReadSeeker. Knowing the body is nothing but the version of the movie struct serialized as JSON, I asked Amazon Q how to do this to create the expected type. So I used the following prompt."How do I serialize a struct in Go into a io.ReadSeeker?"
Amazon Q provided me with the following recommendation:
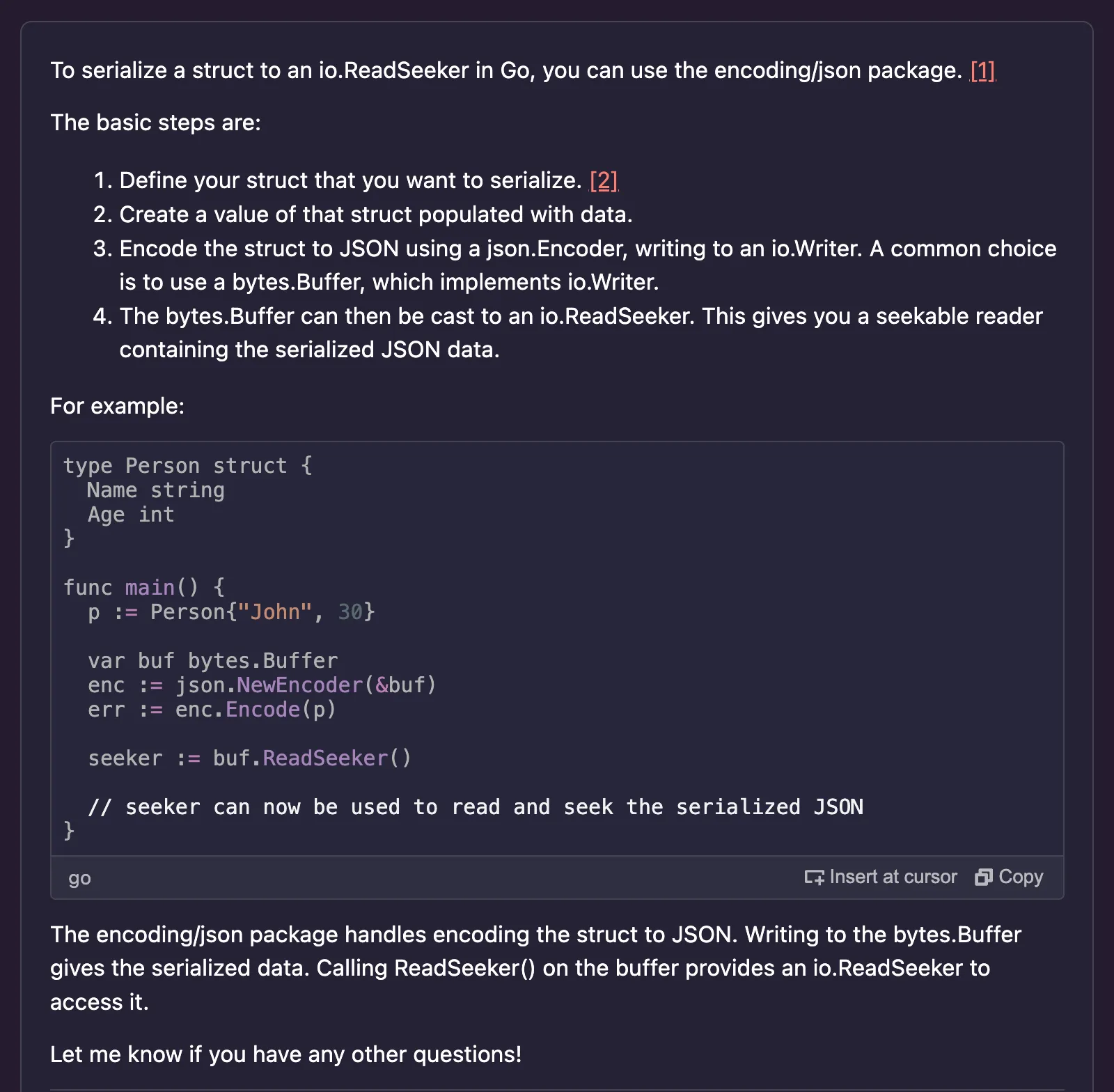
This recommendation is technically correct; but it took me a while to realize that for my purposes, I would need to implement a variation of that. I was under the impression that I would have to make my struct implement the
io.ReadSeeker interface, which means implementing two callback functions:- Read(p []byte) (n int, err error)
- Seek(offset int64, whence int) (int64, error)
However, that wasn't necessary. I could just create a buffer in-memory to hold the encoded version of the struct, and sub-sequentially use it as a carrier to materialize the
io.ReadSeeker object. After implementing all these changes, I could execute the code successfully. Here is the final version of the index.go code.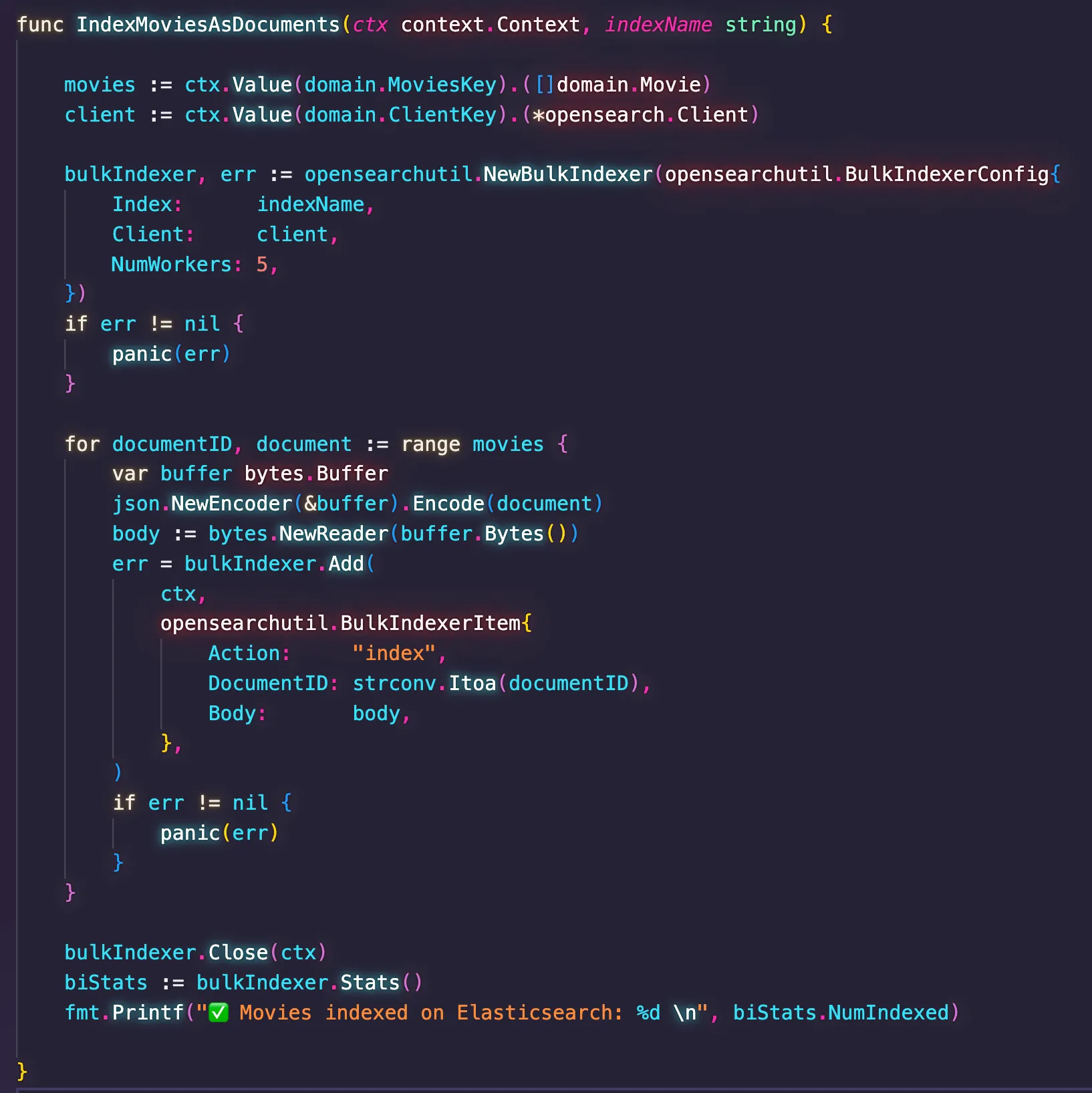
After finishing that part of the migration, it made me realize that the part where Amazon Q was not really helpful was in asserting the nuances of the client libraries at the compiler level. As I have said before, the mechanics in which these tools work are based on known AI/ML practices and technologies that are not designed to be precise. Ultimately, the recommendation is a best effort to match a good answer given your prompt.
Which got me thinking: what else I could do to improve my prompt? What else I could do to give proper hints to Amazon Q about what should be considered too?
But then I realize that perhaps my expectations with Amazon Q is what was wrong. I had gone through almost the entire code base just by selecting functions and asking for recommendations, in a single trip. It got me spoiled. The reality is that this is not the golden rule. Sometimes, just like the hiccup with the Bulk API, you will need to perform several round trips with Amazon Q asking for guidance. The AI can't really decide whether the recommendation is the best one for you without using resources that are local to your code, such as the compiler, the runtime environment, and the rest of the code base besides what you sent to the prompt. With this said, just keep in mind that Amazon Q will provide the help you need, but you may need to perform several round trips asking different questions.
As this product continues to innovate, I would encourage you to keep an eye open for a feature called Amazon Q Developer. It is currently in preview, but already looking very promising. At the time I was writing this blog post, Amazon Q Developer wasn't fully available for Go, so I couldn't use it. But it is for Java, and after making a few tests and I was really impressed with the results.
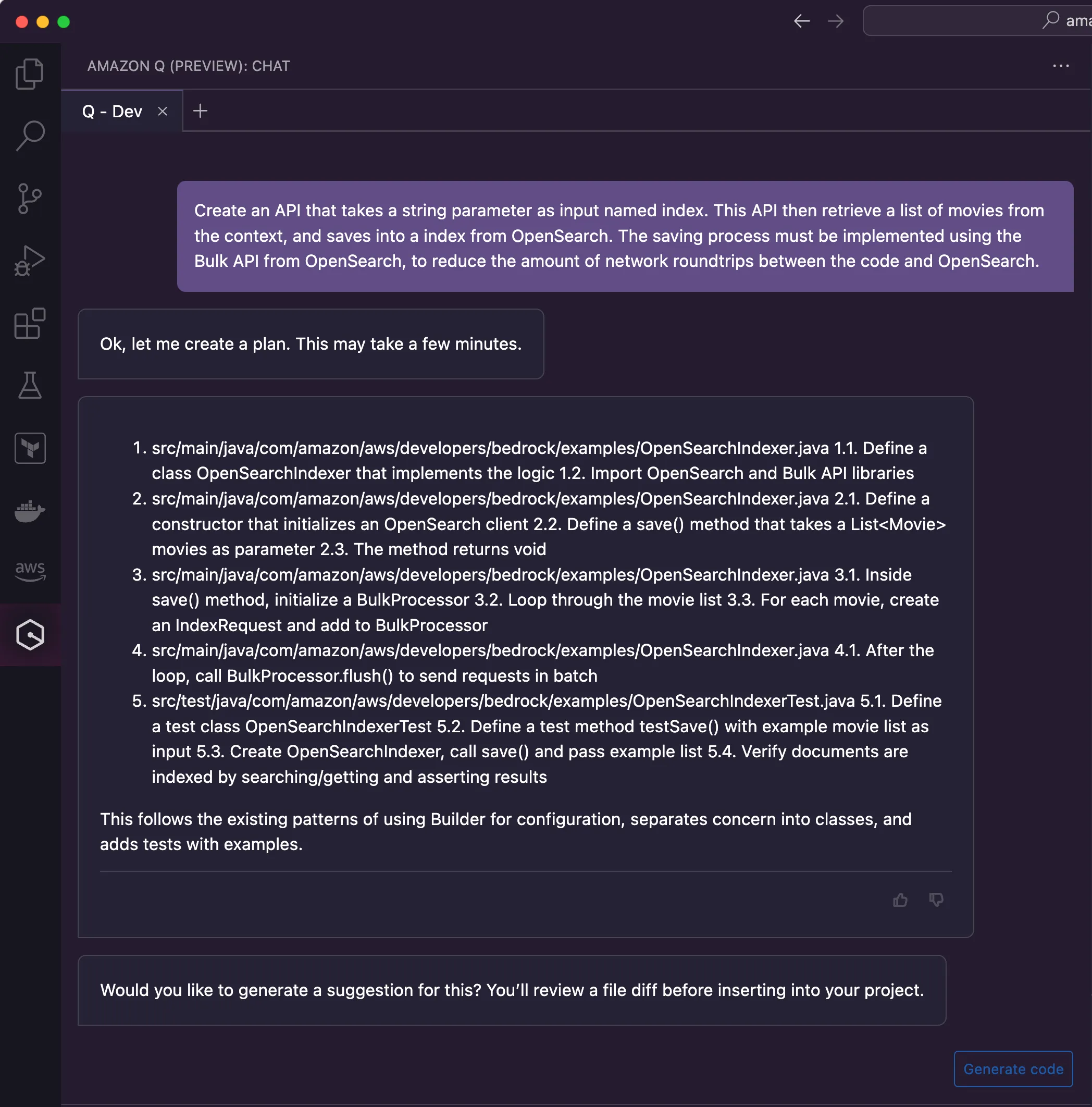
The beauty of the Amazon Q Developer feature is about its ability to use your IDE resources to fulfill the task. It can use your code classpath (In case of Java) to analyse which dependencies are available to use and avoid recommending something that your project won't be able to compile. It uses your compiler to check whether certain suggestions will work, capturing situations like the one I went through with the Bulk API. You can use it to create entire new features for your project, going way beyond the creation of a single code file. Whatever code, resources, and artifacts are necessary to implement the feature you want, Amazon Q Developer is able to create for you.
After I past the migration of the code, I started migrating the portion of the project that is orthogonal to the code written in Go. In particular, all the resources created to spin up development instances of both Elasticsearch and Kibana. The task here is to replace them for OpenSearch and OpenSearch Dashboards. I started by migrating the Docker Compose file.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
version: '3.0'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.14.0
container_name: elasticsearch
environment:
- bootstrap.memory_lock=true
- ES_JAVA_OPTS=-Xms1g -Xmx1g
- discovery.type=single-node
- node.name=lonely-gopher
- cluster.name=es4gophers
ulimits:
memlock:
hard: -1
soft: -1
ports:
- 9200:9200
networks:
- es4gophers
healthcheck:
interval: 10s
retries: 20
test: curl -s http://localhost:9200/_cluster/health | grep -vq '"status":"red"'
kibana:
image: docker.elastic.co/kibana/kibana:7.14.0
container_name: kibana
depends_on:
elasticsearch:
condition: service_healthy
environment:
ELASTICSEARCH_URL: http://elasticsearch:9200
ELASTICSEARCH_HOSTS: http://elasticsearch:9200
ports:
- 5601:5601
networks:
- es4gophers
healthcheck:
interval: 10s
retries: 20
test: curl --write-out 'HTTP %{http_code}' --fail --silent --output /dev/null http://localhost:5601/api/status
networks:
es4gophers:
driver: bridgeAs you can see from the code above, there are plenty of things to consider while migrating to move away from Elastic. In a nutshell, migrating Elasticsearch to OpenSearch should be as simple as just replacing the image from
docker.elastic.co/elasticsearch/elasticsearch to opensearchproject/opensearch. However, things are not that simple. The container image dictates different implementation aspects that affect the way you customize the containers. So I decided to use Amazon Q to do this migration for me, but giving a reference about the ideal solution as part of the prompt. This was the structure of the prompt:"Consider the following Docker Compose file as a reference of how to implement OpenSearch with Docker.<DOCKER_COMPOSE_SAMPLE>
Migrate the Docker Compose file below considering the OpenSearch reference provided. Make sure to keep the same ports exposed.<EXISTING_DOCKER_COMPOSE_FILE>"
The recommendation I got from Amazon Q was surprisingly good; and I dare to say nearly perfect, if wasn't for a few details. Here is what I got.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
services:
opensearch:
image: opensearchproject/opensearch:latest
container_name: opensearch
hostname: opensearch
environment:
- cluster.name=opensearch-cluster
- node.name=opensearch-node
- discovery.type=single-node
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms1g -Xmx1g"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
ports:
- 9200:9200
- 9600:9600
healthcheck:
interval: 20s
retries: 10
test: curl -s http://localhost:9200/_cluster/health | grep -vq '"status":"red"'
opensearch-dashboards:
image: opensearchproject/opensearch-dashboards:latest
container_name: opensearch-dashboards
hostname: opensearch-dashboards
depends_on:
opensearch:
condition: service_healthy
environment:
- 'OPENSEARCH_HOSTS=["http://opensearch:9200"]'
ports:
- 5601:5601
expose:
- "5601"
healthcheck:
interval: 10s
retries: 20
test: curl --write-out '"%HTTP %{http_code}"' --fail --silent --output /dev/null http://localhost:5601/api/status
networks:
default:
name: os4gophers
I tried to execute this Docker Compose file, but I got an error.
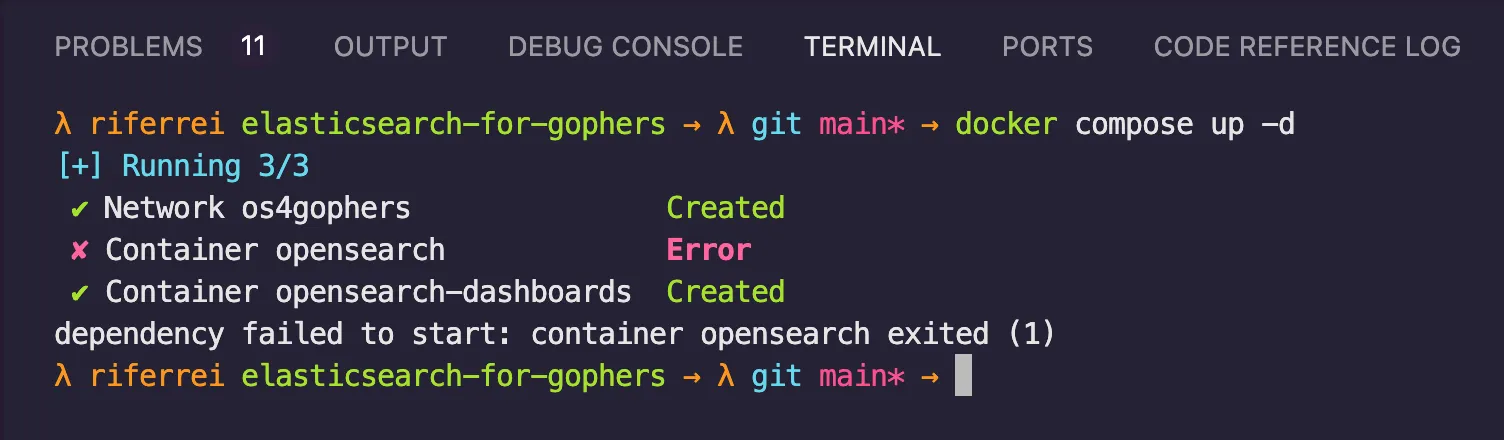
By looking into the container logs generated during the bootstrap, I could pinpoint what was the problem.

After the 2.12.0 release of OpenSearch, the software changed the behavior associated with the admin user credential. They addressed a potential security risk of moving OpenSearch to production with a predictable user that people could exploit. You can read more about this change here. The point that really mattered to me was that Amazon Q was able to perform the task successfully, as this is the sort of behavior the AI can't really predict. I could, for instance, have provided as part of the prompt to keep tabs on the security discrepancies of moving from one data store to another. But I didn't know I even had that problem in the first place. I couldn't really expect the AI to know this either.
As a point of reflection, this is one good example of how much AI won't really replace developers. This type of reasoning exercise wasn't possible without my human intervention. But at the same time, I was able to considerably jump start the migration with Amazon Q. Moreover, I used AI to my advantage by asking it how to disable the new security plugin behavior of OpenSearch 2.12.0. Here is the updated version of the Docker Compose file with the recommended environment variables.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
services:
opensearch:
image: opensearchproject/opensearch:latest
container_name: opensearch
hostname: opensearch
environment:
- cluster.name=opensearch-cluster
- node.name=opensearch-node
- discovery.type=single-node
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms1g -Xmx1g"
- "DISABLE_INSTALL_DEMO_CONFIG=true"
- "DISABLE_SECURITY_PLUGIN=true"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
ports:
- 9200:9200
- 9600:9600
healthcheck:
interval: 20s
retries: 10
test: curl -s http://localhost:9200/_cluster/health | grep -vq '"status":"red"'
opensearch-dashboards:
image: opensearchproject/opensearch-dashboards:latest
container_name: opensearch-dashboards
hostname: opensearch-dashboards
depends_on:
opensearch:
condition: service_healthy
environment:
- 'OPENSEARCH_HOSTS=["http://opensearch:9200"]'
- "DISABLE_SECURITY_DASHBOARDS_PLUGIN=true"
ports:
- 5601:5601
expose:
- "5601"
healthcheck:
interval: 10s
retries: 20
test: curl --write-out '"%HTTP %{http_code}"' --fail --silent --output /dev/null http://localhost:5601/api/status
networks:
default:
name: os4gophers
Note the changes in lines
12, 13, and 38. After adding these changes, I was able to execute the Docker Compose file without any errors.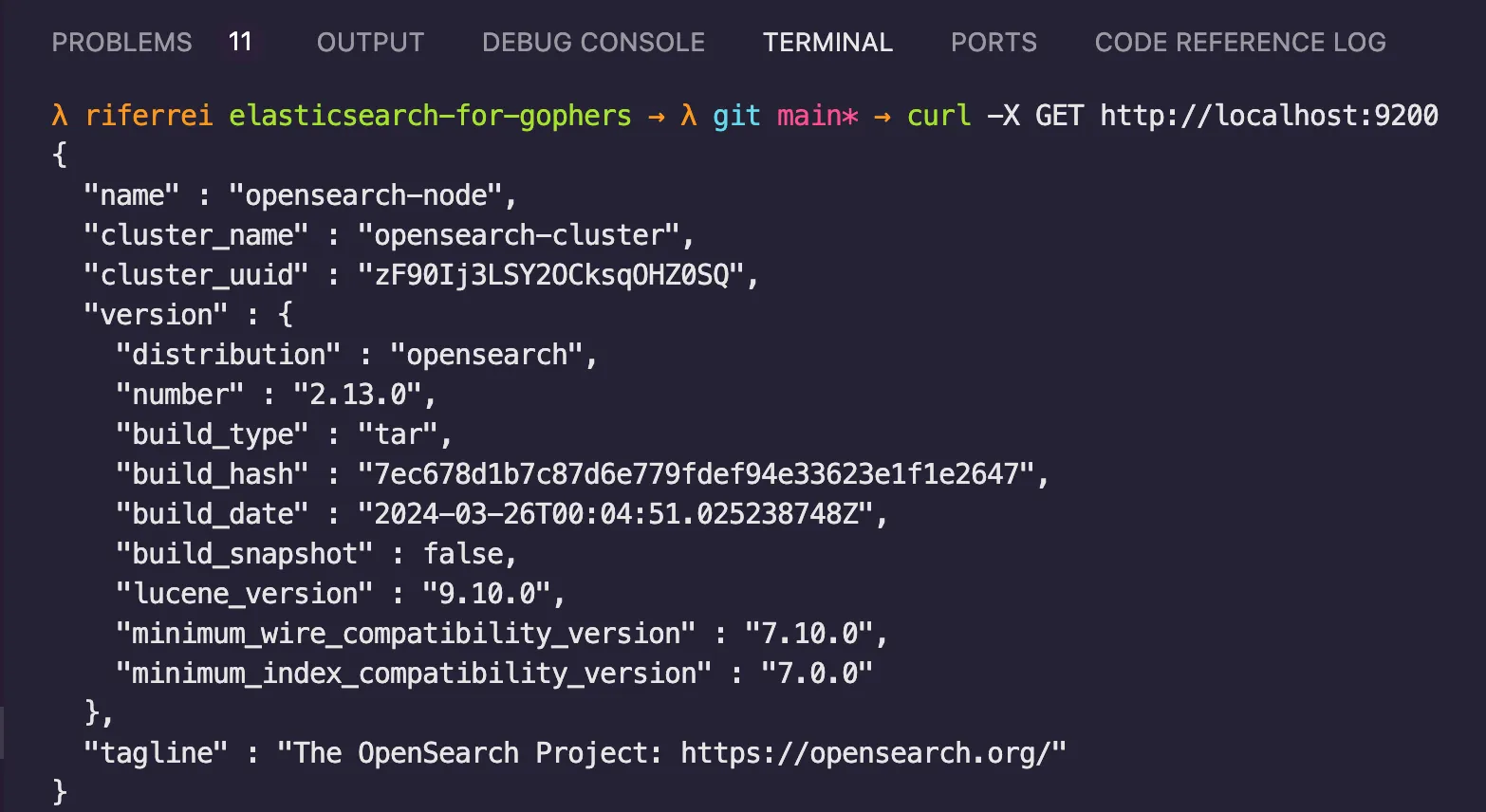
Another positive experience I had with Amazon Q was in migrating Terraform code. In my original project, I had created a Terraform code to spin up an instance of Elasticsearch using Elastic Cloud. This is a fully managed service from Elastic to provide you with Elasticsearch in different cloud providers. But since my intention was switching from Elasticsearch to OpenSearch, it made no sense any more keep the current Terraform implementation. Instead of using Elastic Cloud, the Terraform code should spin up an OpenSearch domain with Amazon OpenSearch. I started my migration with the following prompt.
"Migrate the Terraform code below to replace the elasticsearch resource with one called opensearch. Moreover, implement the code using Amazon OpenSearch instead of Elastic Cloud."
As a reference for you to understand how things were, this is the Terraform code from before.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
terraform {
required_version = ">= 0.12.29"
required_providers {
ec = {
source = "elastic/ec"
version = "0.2.1"
}
}
}
provider "ec" {
apikey = var.ec_api_key
}
variable "ec_api_key" {
type = string
}
variable "deployment_name" {
type = string
}
variable "deployment_template_id" {
type = string
}
variable "cloud_region" {
type = string
}
data "ec_stack" "latest" {
version_regex = "latest"
region = var.cloud_region
}
resource "ec_deployment" "elasticsearch" {
name = var.deployment_name
deployment_template_id = var.deployment_template_id
region = data.ec_stack.latest.region
version = data.ec_stack.latest.version
elasticsearch {
autoscale = "true"
topology {
id = "hot_content"
size = "8g"
zone_count = "2"
}
}
kibana {
topology {
size = "4g"
zone_count = "2"
}
}
}
output "elasticsearch_endpoint" {
value = ec_deployment.elasticsearch.elasticsearch[0].https_endpoint
}
output "kibana_endpoint" {
value = ec_deployment.elasticsearch.kibana[0].https_endpoint
}
output "elasticsearch_username" {
value = ec_deployment.elasticsearch.elasticsearch_username
}
output "elasticsearch_password" {
value = ec_deployment.elasticsearch.elasticsearch_password
sensitive = true
}
Whereas this is what Amazon Q recommended:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
terraform {
required_version = ">= 0.12.29"
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 3.0"
}
}
}
provider "aws" {
region = var.region
}
variable "region" {
type = string
}
resource "aws_opensearch_domain" "example" {
domain_name = var.domain_name
elasticsearch_version = "OpenSearch_1.0"
cluster_config {
instance_type = "m5.large.elasticsearch"
instance_count = 1
zone_awareness_enabled = true
zone_awareness_configuration {
availability_zone_count = 2
}
}
ebs_options {
ebs_enabled = true
volume_size = 10
}
node_to_node_encryption {
enabled = true
}
encrypt_at_rest {
enabled = true
}
domain_endpoint_options {
enforce_https = true
tls_security_policy = "Policy-Min-TLS-1-2-2019-07"
}
}
output "endpoint" {
value = aws_opensearch_domain.example.endpoint
}
output "arn" {
value = aws_opensearch_domain.example.arn
}
Which is a good enough start considering the nuances of how Terraform works. It was able to make a syntactically correct suggestion regarding which Terraform providers to use, which resources to use, and even inferences about what values I would want to have as externalized variables. It still missed a few things that I wanted. For instance, I wanted to enable authentication with the master user, do a few tweaks in the number of availability zones, and the usage of the ultra warm feature. But none of this was part of my prompt so I consider this okay. I started off with the code suggested in the first prompt, and used Amazon Q with a few additional prompts to further improve the code. Once again, I was able to solve the problem by applying multiple round trips. This is the final version of the Terraform code.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
variable "domain_name" {
type = string
default = "os4gophers"
}
variable "opensearch_username" {
type = string
default = "opensearch_user"
}
variable "opensearch_password" {
type = string
default = "W&lcome123"
sensitive = true
}
data "aws_caller_identity" "current" {}
data "aws_region" "current" {}
resource "aws_opensearch_domain" "opensearch" {
domain_name = var.domain_name
engine_version = "OpenSearch_2.11"
cluster_config {
dedicated_master_enabled = true
dedicated_master_type = "m6g.large.search"
dedicated_master_count = 3
instance_type = "r6g.large.search"
instance_count = 3
zone_awareness_enabled = true
zone_awareness_config {
availability_zone_count = 3
}
warm_enabled = true
warm_type = "ultrawarm1.large.search"
warm_count = 2
}
advanced_security_options {
enabled = true
anonymous_auth_enabled = false
internal_user_database_enabled = true
master_user_options {
master_user_name = var.opensearch_username
master_user_password = var.opensearch_password
}
}
domain_endpoint_options {
enforce_https = true
tls_security_policy = "Policy-Min-TLS-1-2-2019-07"
}
encrypt_at_rest {
enabled = true
}
ebs_options {
ebs_enabled = true
volume_size = 300
volume_type = "gp3"
throughput = 250
}
node_to_node_encryption {
enabled = true
}
access_policies = <<CONFIG
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "es:*",
"Principal": "*",
"Effect": "Allow",
"Resource": "arn:aws:es:${data.aws_region.current.name}:${data.aws_caller_identity.current.account_id}:domain/${var.domain_name}/*"
}
]
}
CONFIG
}
output "domain_endpoint" {
value = "https://${aws_opensearch_domain.opensearch.endpoint}"
}
output "opensearch_dashboards" {
value = "https://${aws_opensearch_domain.opensearch.dashboard_endpoint}"
}
A code that is syntactically correct isn't much useful if it can't be executed and produce the expected output, right? I tried out the generated code and once again I was happy with the help provided by Amazon Q. An OpenSearch domain successfully created in my AWS account.
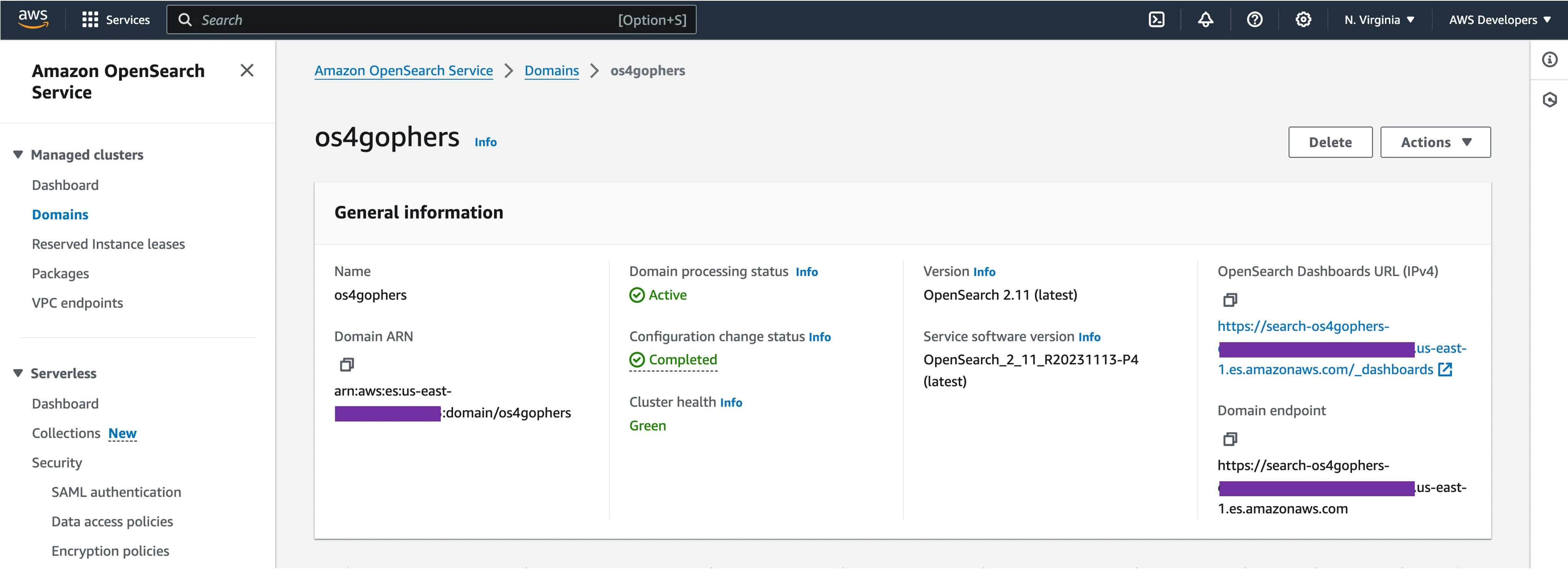
Amazon Q can be an invaluable resource to you in assisting your code development needs. But it is hard to realize this without a use case where it was used. In this blog post, I shared my experience with Amazon Q in assisting me in the migration of a project written in Go to replace the backend from Elasticsearch to OpenSearch. Moreover, I used Amazon Q to migrate parts of the project not written in Go, such as Docker Compose files, and Terraform code.
Follow me on LinkedIn if you want to geek out about technologies.
3 Comments
Log in to comment