Which data strategy should I use for my genAI application?
From RAG to fine tuning, there are many ways to adapt a generative AI model to our own data. Learn how to choose between them depending on your use case!
Ignacio Sanchez Alvarado
Amazon Employee
Published Jun 21, 2024
Generative AI models are trained on vast amounts of data from public sources such as the internet. This means that these models are capable of applying logic and solve problems for a really wide range of different use cases. Although this general knowledge is really useful for many different task when it comes to apply it to specific use cases or to work in a particular industry is not enough.
If we want to have a real business value we need to use our own proprietary data in the responses of these models.

Good news is that there are different ways that allow us to use our own data in the model responses. Let's explore first which are the most popular techniques for adapting the models behaviour to our application needs:
This is the most simple but still effective customization technique. Prompt engineering is not other than passing an instruction to the genAI model in each invocation we do. Some things that we can indicate in the prompt:
- A role model to be adopted. (e.g.: "You are an expert consultant in the finance domain...")
- Some specific examples about what we want as response (e.g.: we want the output to be in a certain structure).
- Long context prompts (e.g.: for long text summarizations, content creation..etc)
Prompt engineering is a really wide topic and can be really effective in most of the use cases. Here you can find a pretty good guide as a starting point if you want to dive deep in prompt engineering techniques: Master Prompt Engineering: Build AI apps with Claude & PartyRock.
Also always have a look at the prompt engineering guide of the specific model you are using, most of the model providers have their own guides published and those are the ones that are gonna perform the better for that certain model.
For instance, here you have the prompt engineering guide from Anthropic, the creators of the Claude models: Anthropic - Prompt engineering guide.
RAG is the next step in the customization techniques for generative AI applications. It allows you to use the knowledge of a large corpus of information that by default does not fit in the model's context window. By using RAG we add relevant information to the user's query as part of the prompt in each model invocation, with this info the model can elaborate a more accurate and precise response.
Have a look at how RAG is implemented:
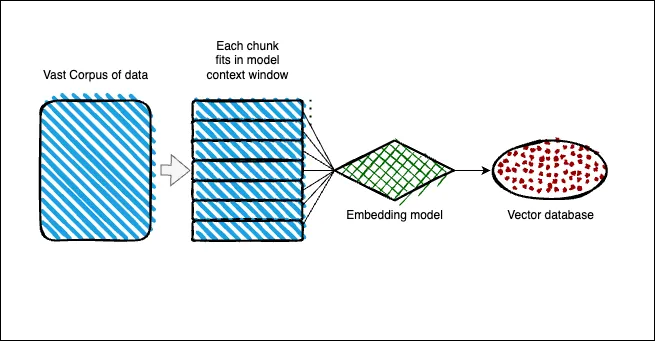
Setting up the architecture:
- Context is divided in smaller chunks that fits the model context windows.
- The chunks are transform into embeddings (converted into numerical values).
- Embeddings are stored in a vector database where we can perform semantic searches.
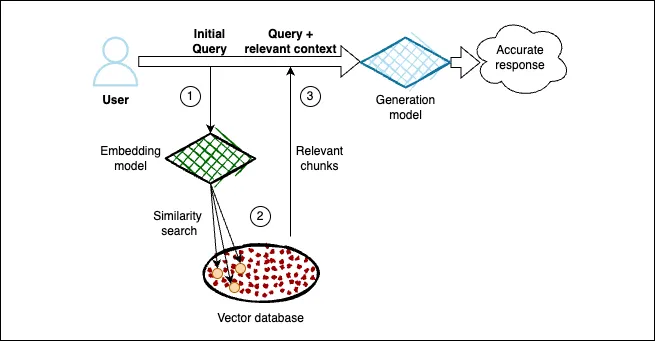
Using RAG at inference time:
- User query is transformed into embedding.
- With that embedding similarity search is perform against the vector database to retrieve the most relevant chunks to the query.
- Those chunks are added as context in to the initial user's query.
- Model responses accurately by using the relevant context information.
You can find more info about RAG architectures here: Retrieval Augmented Generation - blog post.
Don't worry if the diagram above seems too complicated, there are different frameworks and tools in the market that allow you to easily implement a RAG pipeline for your applications. (Some examples: Langchain, Llamaindex)
Additionally, if you are using Amazon Bedrock for building your genAI applications you can implement in just a couple of minutes a native RAG architecture for your models. Find more about this here: Knowledge Bases for Amazon Bedrock.
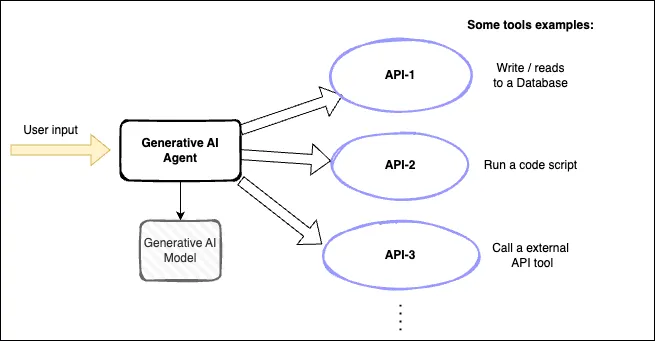
Another customization technique for our generative AI applications is the usage of AI agents. Agents take advantage of the logic that Generative AI models can apply to solve complex tasks. Thanks to agents the model can orchestrate a serie of steps in order to resolve an interaction and then execute automatically that plan.
Those steps or actions that the model can execute usually are API calls. We can create "tools", that are API calls, and give the models the ability to use them. Some examples of what tools we can have for an generative AI agent:
- Interact with software applications.
- Reads/writes to external databases.
- API calls to external services for retrieving information.
- Use a company-specific system.
- Run a code snippet or script and get the result.
More information on agents for genAI applications: How to Build the Ultimate AI Automation with Multi-Agent Collaboration.
Again here there are different tools that help you build your own AI agents. You can use frameworks like Langchain or Llamaindex . Also in Amazon Bedrock you can find a tool that builds natively an agent for your genAI applications: Agents for Amazon Bedrock.
Finally, the last customization technique is the possibility of fine-tuning our own model. This is the most time and money consuming technique, as we will continue the model training process with our own dataset, but it can achieve the best results.
This technique is specially useful if we want to adapt the model responses to a specific style or if we want to increase the model knowledge in a particular domain. We would need a dataset (raw data or labeled) and we would use techniques like LoRa to perform efficient re-training of a base model and obtain a final totally customized model to our own use case.
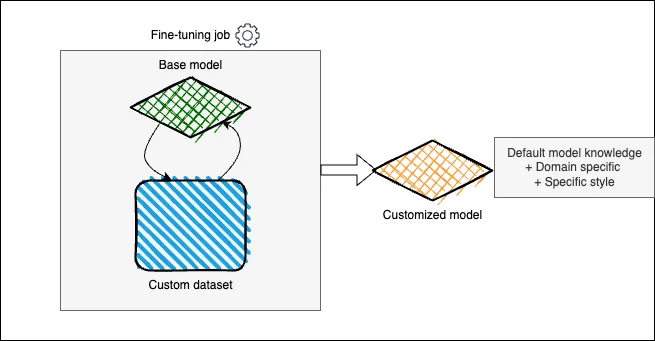
Amazon Bedrock offers you the possibility of create your own custom models. This feature allow you to start an automated customization job with your own dataset, once this is finished you will be able to use your own custom model in the service by calling its ID in the bedrock API call.
Now let's decide which technique we should apply depending on our use case. For that we will use a serie of questions to determine which options we should use.
1. Do you need to use specific information? Information that is outside the parametric knowledge of the model.
- If the answer is No: then you can rely just on prompt engineering techniques. You can stop here an go to build your application! (No need to continue with the other questions).
- If the answer is Yes: you will need to use either RAG, agents or fine-tuning. If you want to know which one to use continue with the next questions:
2.a Does the task require dynamic information reading and/or writing to external applications?
- If the answer is No: you can just simply rely on RAG.
- If the answer is Yes: You will need to use Agents.
You can combine also RAG and Agents to hace access to both dynamic and static types of information in the same application.
2.b Is the task relatively simple/generic and/or does it require specific domain knowledge or a particular response style?
- If the task is simple: you can rely on default models. Those have been trained on vast amounts of general data and usually perform really well in generic task such as: copywriting / summarization, Q&A answering / customer support, text classification, code generation...
- If the task requires specific domain knowledge or a particular style: you would need to create a customize model for your use case. In this case you should use any of the fine-tuning techniques available for the base model you want to use.
If you prefer a more visual resource, here is a selection diagram that can guide you through the data strategy selection process:
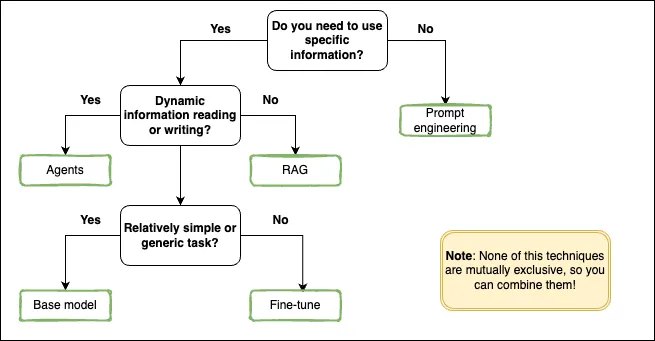
Finally is important to say that none of this techniques are mutually exclusive, so you can combine them! Indeed this is actually what most of the generative AI applications end up having: a combination of the different techniques to increase the final performance of the solution.
The key here is to start with the easiest techniques to implement (prompt engineering or RAG) and then move on to the next techniques (agents or fine-tuning) if the solution still does not meet the required performance.
We have seen how the different data customization techniques can be used and when to apply each one. The key value of a generative AI application is the possibility to use our own proprietary data to adapt the responses of the models. By doing this we move from a generic application to a generative AI application that knows our business and can be adapted to our customers.
There are many different ways about how we can customize generative AI applications, knowing all those techniques and most importantly knowing when to apply them is the key to success.
By following the previous guidelines you will be sure that your solutions adapt perfectly to your use case and that the technique that you are using is exactly the one that fits better for your use case!
- Build a data foundation to fuel generative AI session: Youtube link.
- Prompt engineering course: Skill builder link.
- Developing generative AI solutions course: Skill builder link.
- Customization techniques for generative AI course: Skill builder link.
- Amazon Bedrock documentation: Users guide.
- Amazon Bedrock workshop: Github repo.
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.