GenAI under the hood [Part 4] - A shorthand notation to understand advanced RAG patterns
One liners to describe advanced RAG patterns
Shreyas Subramanian
Amazon Employee
Published Apr 24, 2024
Retrieval-Augmented Generation (RAG) pipelines have emerged as a powerful approach to integrating external knowledge sources into large language models (LLMs), enabling these models to produce more informed and context-aware outputs. As the field continues to evolve, researchers and practitioners are exploring various advanced techniques to optimize and enhance the retrieval and generation processes within RAG systems. However, communicating and comparing these complex workflows can be challenging, often requiring detailed explanations or visual representations. Here I introduce a concise shorthand notation designed to represent advanced RAG pipelines in a simple yet expressive manner, facilitating the communication and understanding of these workflows.
The proposed shorthand notation aims to strike a balance between simplicity and expressiveness, allowing for the clear representation of RAG pipelines while maintaining readability. It leverages a set of intuitive operators and conventions to convey the various stages and data flows within these systems. By adopting a concise yet informative notation, researchers and practitioners can effectively communicate and compare different RAG techniques, fostering collaboration and knowledge-sharing within the community.
The notation follows these conventions:
- Steps are spelled out explicitly for better understanding.
- Square brackets ([...]) denote the input data (documents, sentences, etc.) to the next stage.
- Arrows (->) represent the linear flow of operations from one step to the next.
- Parentheses are used to provide additional context or configurations for a particular step.
This shorthand notation offers a consistent and interpretable way to represent advanced RAG pipelines, enabling clear communication and facilitating the exploration and comparison of different approaches.
Query -> Retrieve Docs -> [Docs] -> Generate Response
This represents the most basic RAG pipeline, where a user query triggers the retrieval of relevant documents from a database, and these documents are then used to generate a response by an LLM. This naive RAG approach serves as a baseline for comparison with more advanced techniques. Now that you get the feel for this notation, let's proceed with more advanced methods introduced recently in literature. Feel free to read more using the links provided to the original papers/blogs.
Query -> Generate Hypothetical Answer -> Embed Hypothetical Answer -> Retrieve Docs with Embedding -> [Docs] -> Generate Response
The Hypothetical Document Embedding (HyDE) technique enhances document retrieval by leveraging an LLM to generate a hypothetical answer to the query, which is then embedded and used to refine the retrieval process. source: https://arxiv.org/pdf/2212.10496.pdf
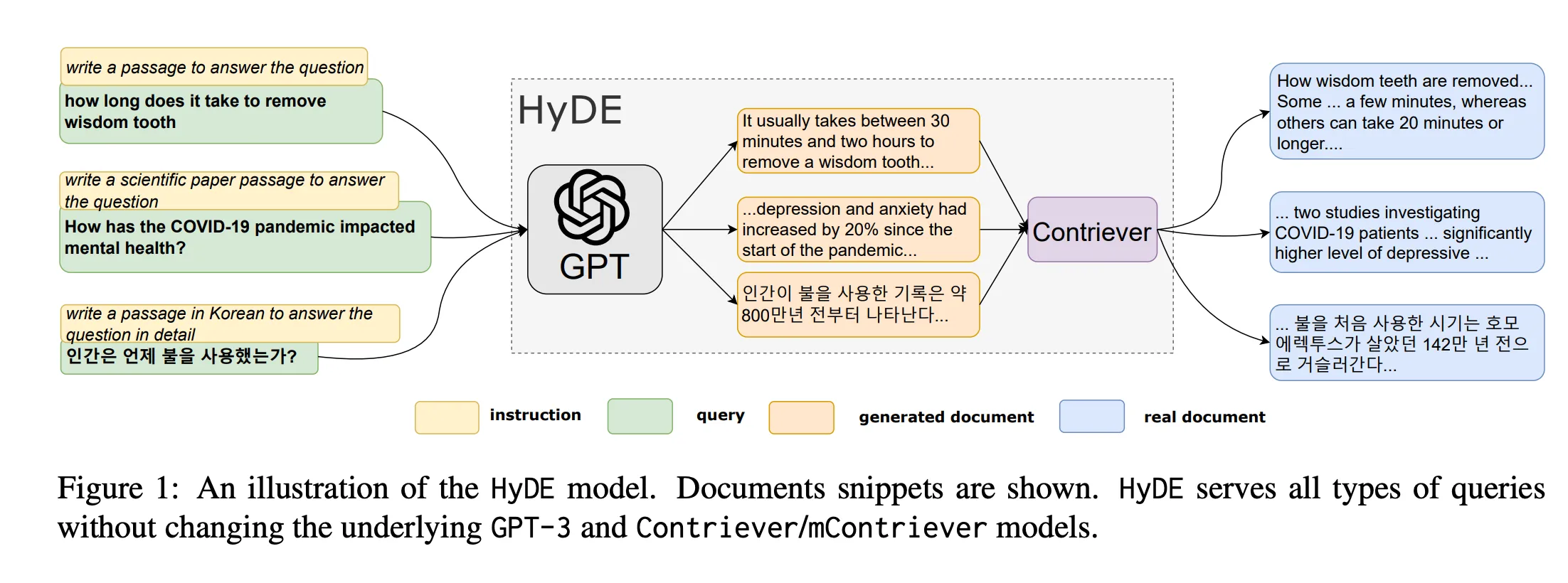
Query -> Generate Multiple Queries -> [Retrieve Docs(query 1), Retrieve Docs(query 2), ...] -> Rerank Docs -> [Reranked Docs] -> Generate Response
The Multi-query technique expands a single user query into multiple similar queries, each used for retrieving documents. The retrieved documents are then reranked, and the most relevant ones are used for generating the response.
When the Reranking is done using "Reciprocal rank fusion", the algorithm is called RAG-Fusion, and can be found here - https://arxiv.org/abs/2402.03367
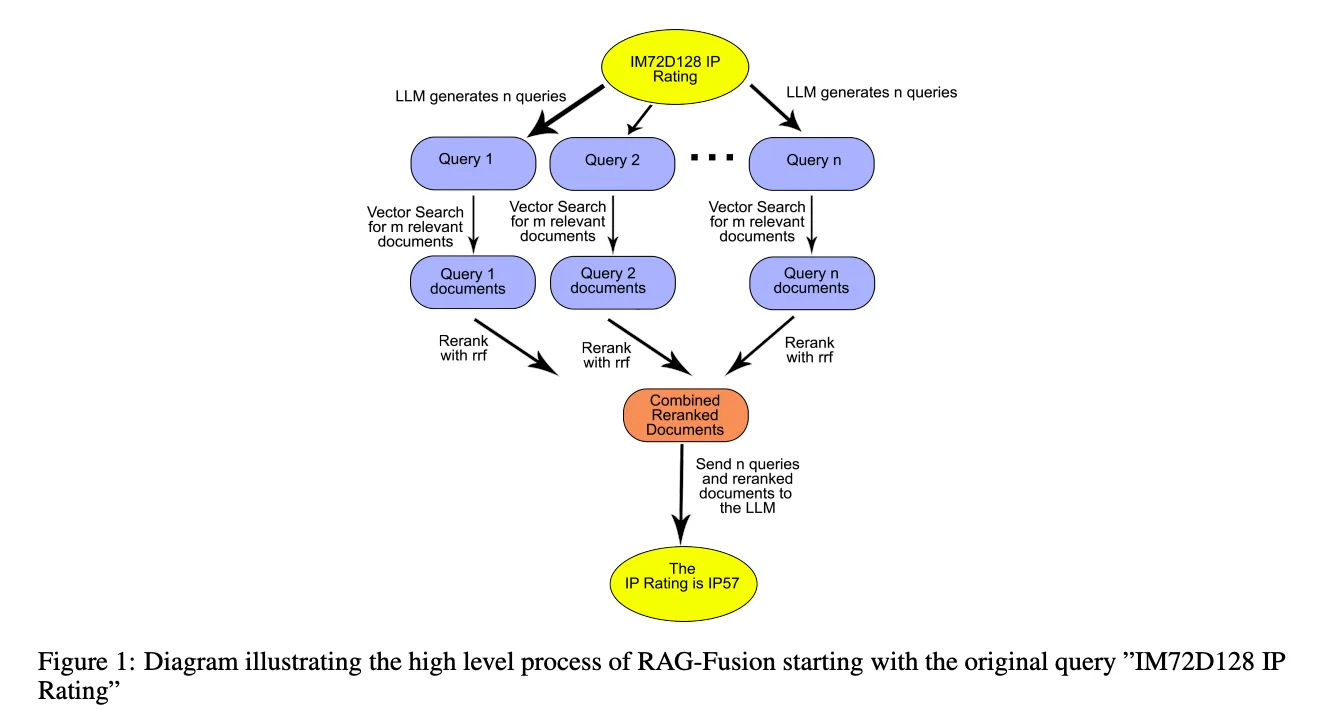
Reciprocal rank fusion (RRF) is an algorithm commonly used in search to assign scores to every document and rerank them according to the scores. The scores assigned to each document, or rrf scores, are:
where rank is the current rank of the documents sorted by distance, and k is a constant smoothing factor that determines the weight given to the existing ranks.
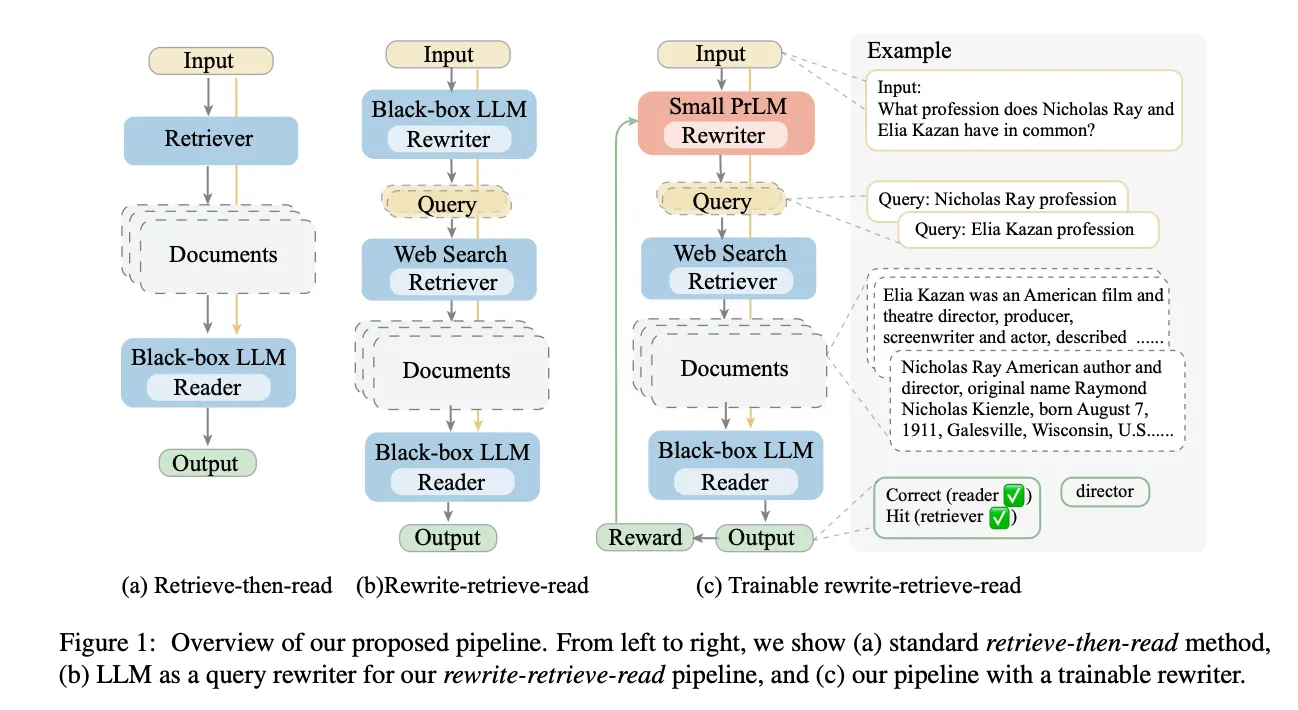
With the same overall algorithm, the Rewrite-retrieve-read paper rewrites the queries into what may be potentially required to answer the question (with an LLM). They also include a way to train various components of the workflow (source - https://arxiv.org/pdf/2305.14283.pdf )
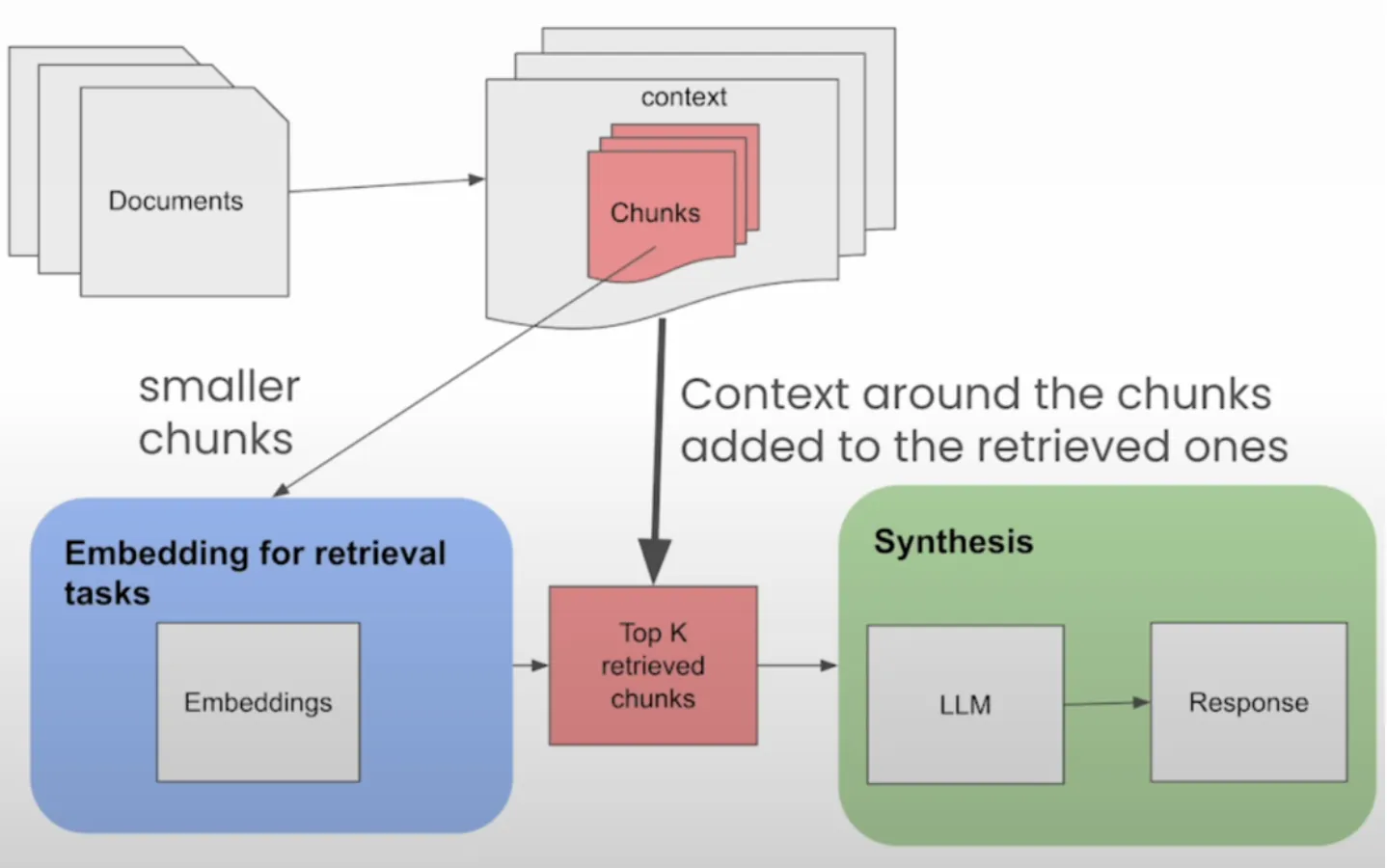
Query -> Retrieve Sentence Windows -> [Sentence Windows] -> Add Context -> Generate Response
The Sentence Window Retrieval approach optimizes retrieval by focusing on individual sentences as retrieval units, while providing additional context to the LLM during the generation phase.
Query -> Retrieve Document Summaries -> [Full Documents] -> Generate Response
The Document Summary Index method enhances retrieval speed and accuracy by indexing document summaries for retrieval, while providing the LLM with the full text documents for response generation.
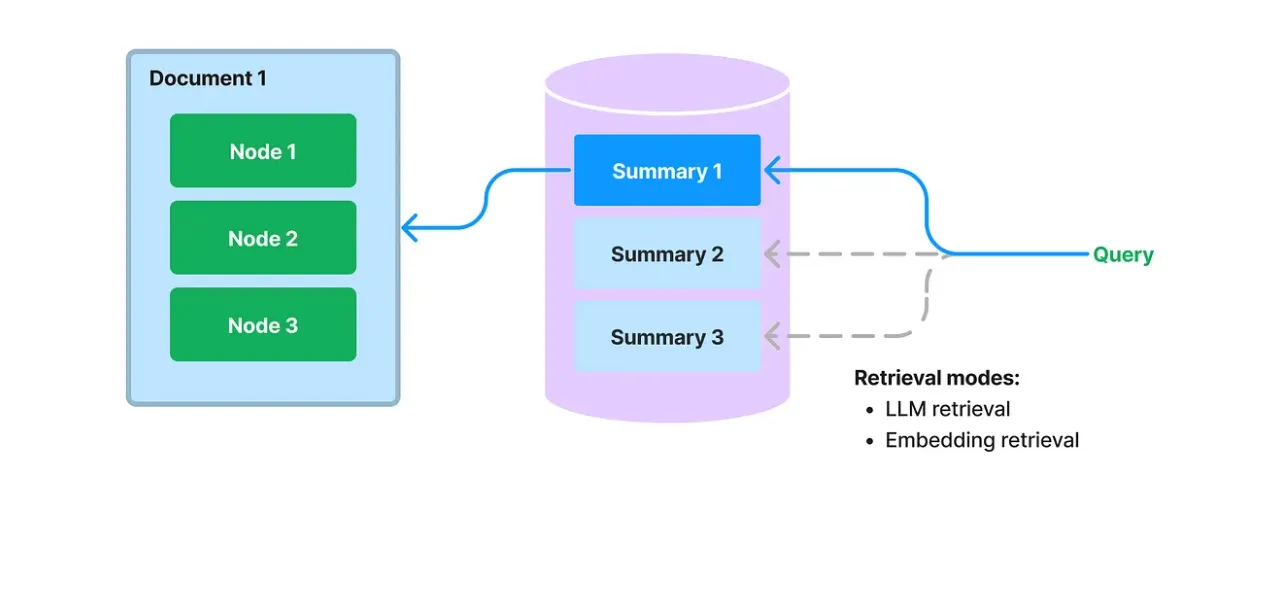
Here's a nice comparison between document summary index and sentence window retrieval methods implemented using llamaindex - https://www.linkedin.com/pulse/comparison-document-summary-index-sentence-window-methods-zhang-bplae/
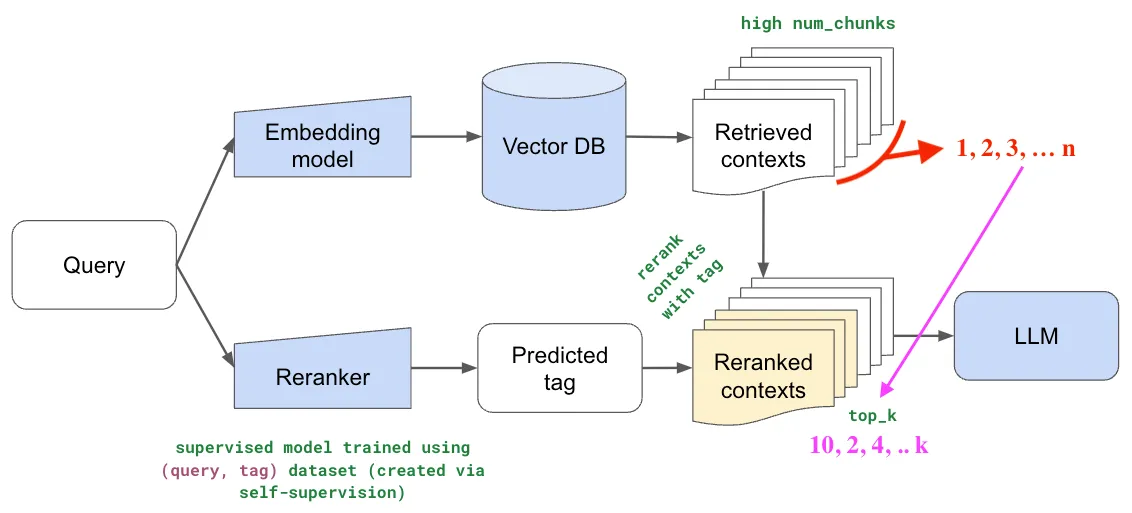
Query -> Retrieve Docs -> Rerank Docs -> [Reranked Docs] -> Generate Response
This notation represents RAG pipelines that incorporate a reranking step, where initially retrieved documents are reassessed and reordered based on their relevance to the query, using techniques like Maximal Marginal Relevance (MMR), Cohere reranker, or LLM-based rerankers. Here's an example of how to do this with Langchain - https://python.langchain.com/docs/templates/rag-pinecone-rerank/
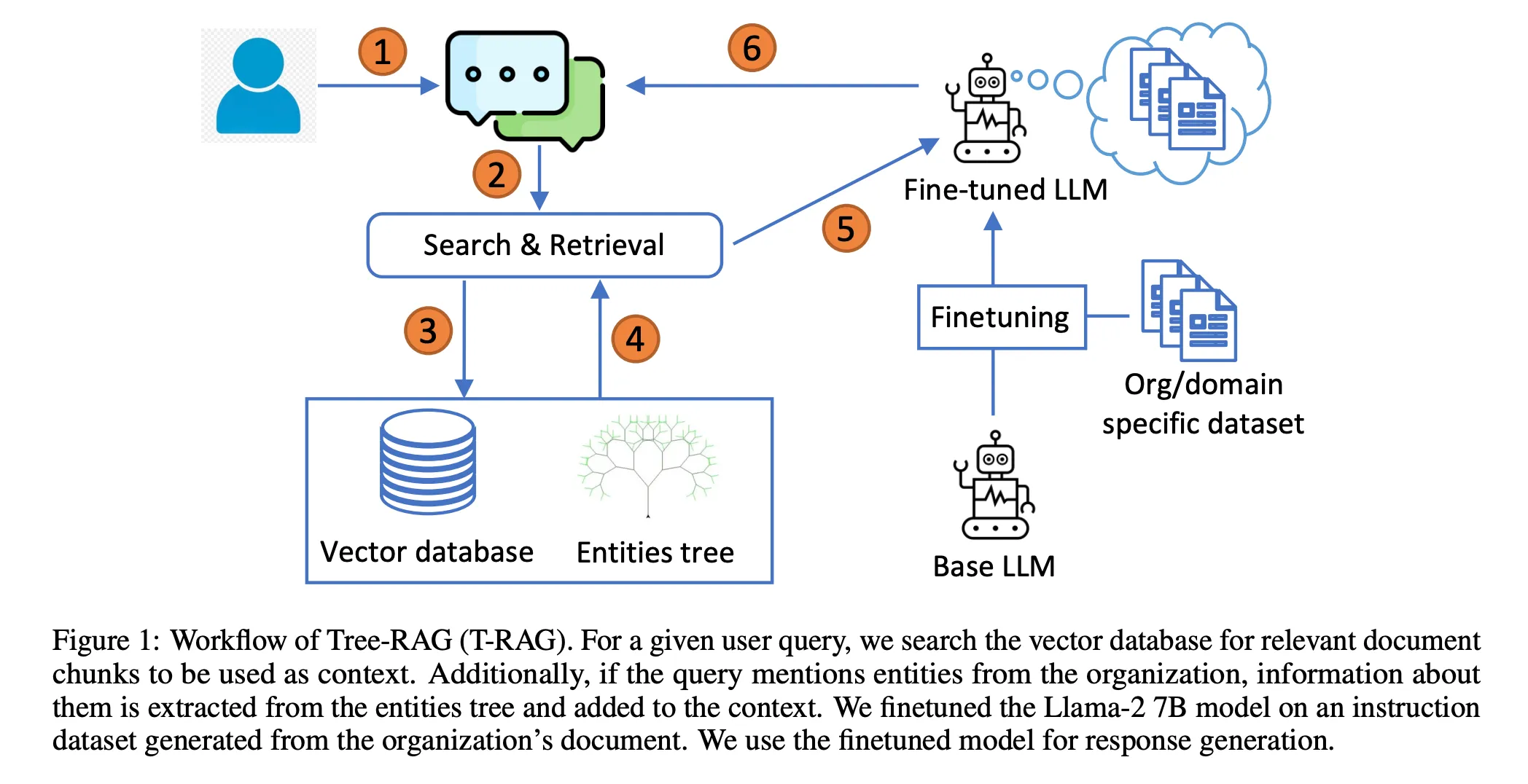
Query -> Generate Entities(Query) -> Search Tree for Entities Info -> Merge [Entities Info, Retrieved Docs] -> Generate Context -> Generate Response
The T-RAG (Tree-augmented RAG) pipeline incorporates entity information from a knowledge graph or database alongside the retrieved documents, merging these sources to generate a comprehensive context for the LLM to produce the final response (source - https://arxiv.org/pdf/2402.07483.pdf).
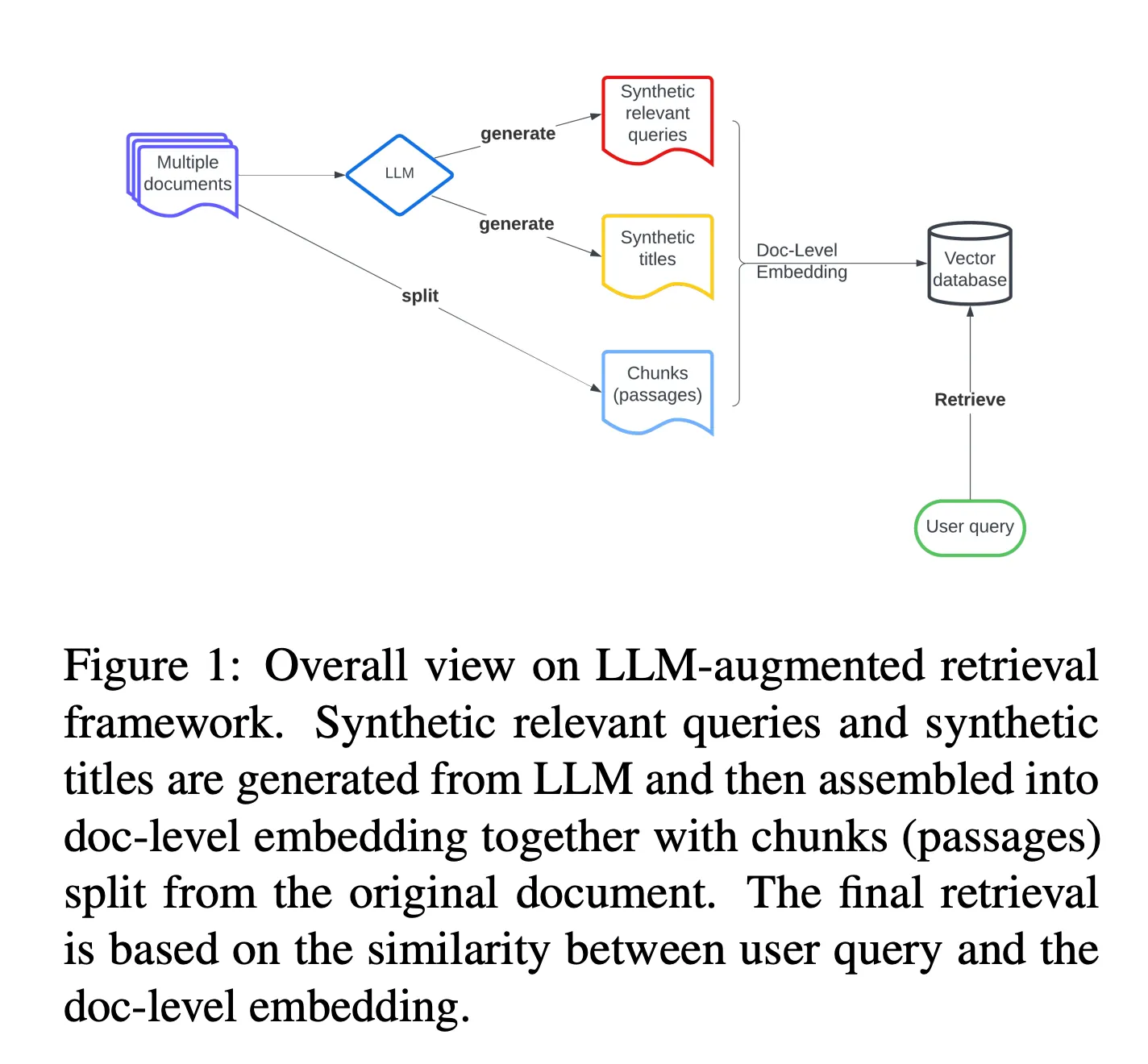
Documents -> Split -> [Chunks] -> LLM -> Generate [Synthetic Titles] -> Generate [Relevant Queries] -> Combine ([Chunks, Synthetic Titles, Relevant Queries]) -> Doc-Level Embedding -> Vector Database -> Retrieve ([Relevant Docs]) <- User Query
In this approach, an LLM generates synthetic titles and relevant queries based on the input documents. These synthetic elements, along with the document chunks, are combined to create doc-level embeddings, which are then stored in a vector database. User queries are matched against these embeddings to retrieve relevant documents (source - https://arxiv.org/pdf/2404.05825.pdf).
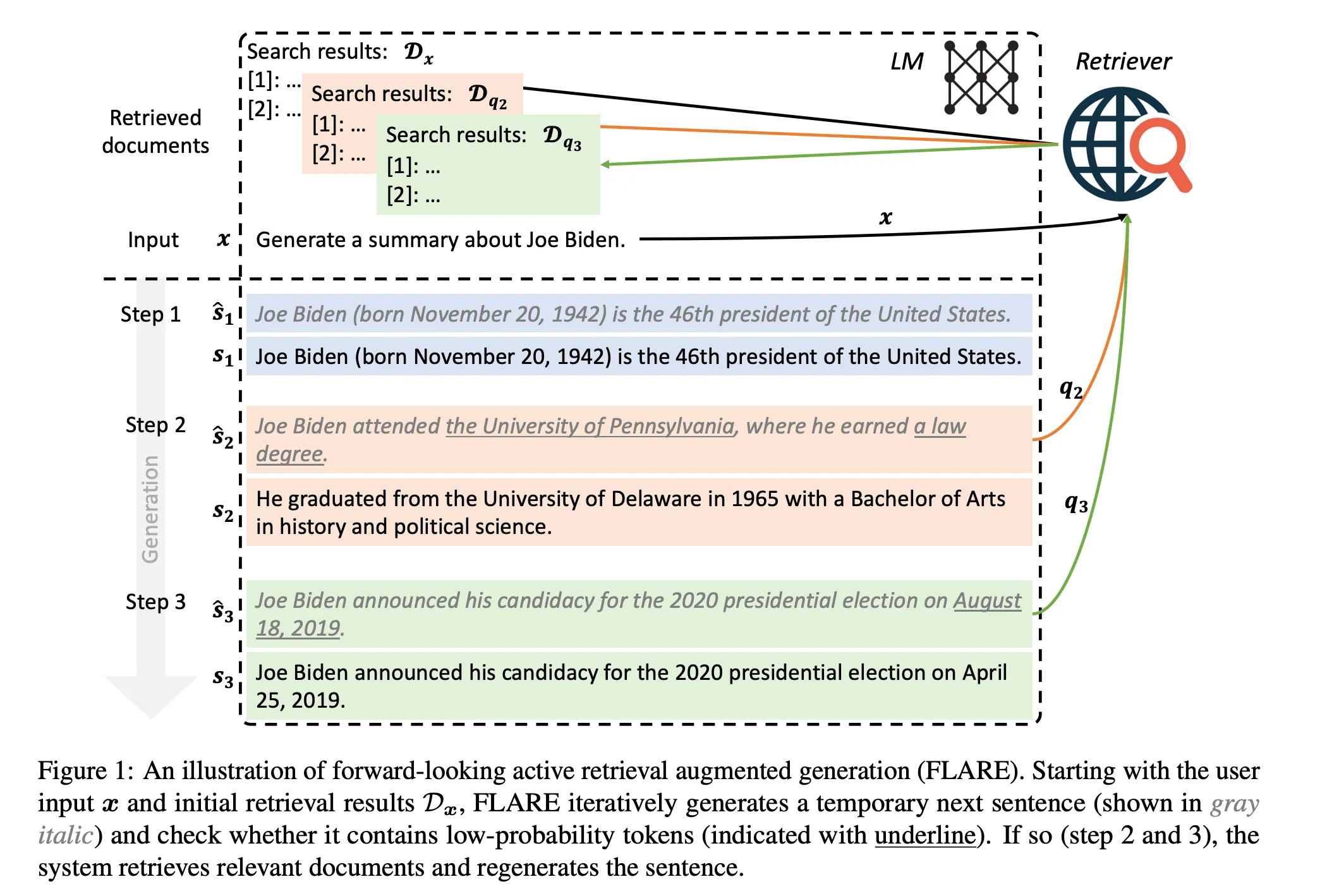
Documents -> Split -> [Chunks] -> LLM -> Generate [Temporary next sentences] -> Combine Search results -> Retrieve [Relevant Docs] <- User Query
Here the authors propose anticipating relevant completions by generating a temporary next sentence, using it as a query to retrieve relevant documents, and then regenerating the next sentence conditioning on the retrieved documents.
Agents that have access to tools, including but not limited to vector indexes or search APIs can dynamically select, use, and compile results based on workflows that are dynamic.
Query -> LLM selects tool(s) -> Send input to [tools] -> Receive response from [tools] -> LLM plans and loops -> LLM generates final Answer
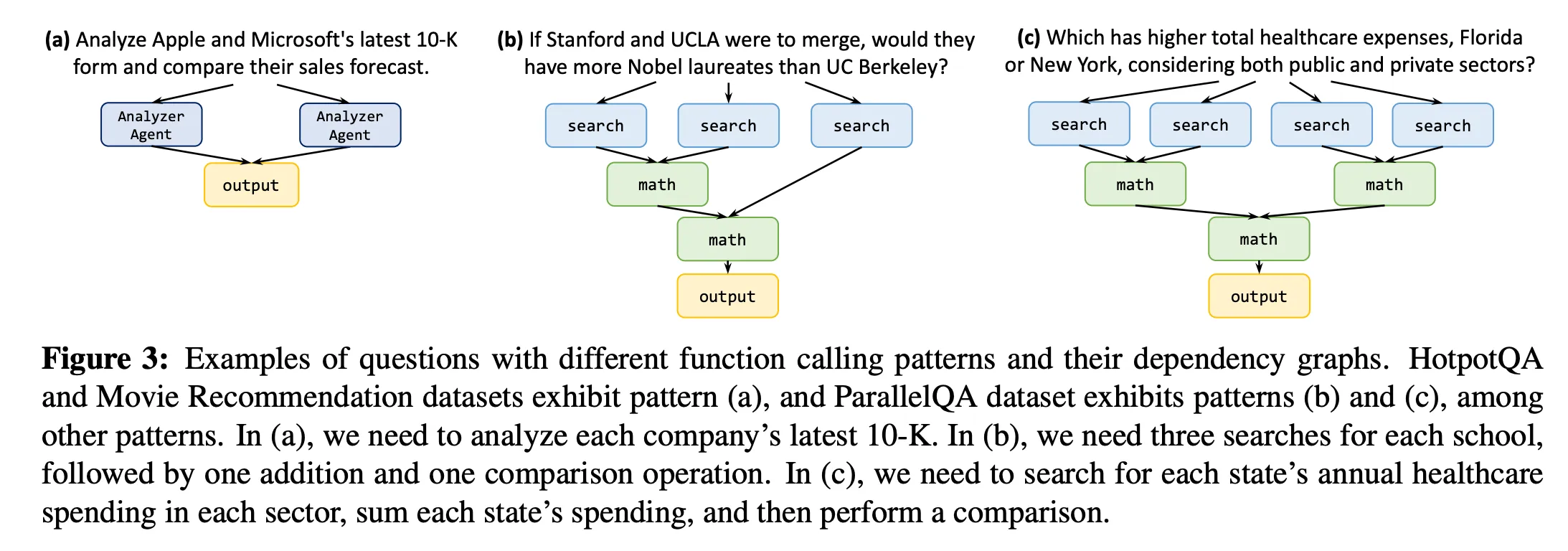
The tool used here can be a vector index (see how to use Agents with Bedrock Knowledge bases here - https://docs.aws.amazon.com/bedrock/latest/userguide/agents-kb-add.html). Now, here is a picture to show how different questions can result in different, dynamically generated agent traces in an agentic RAG system:
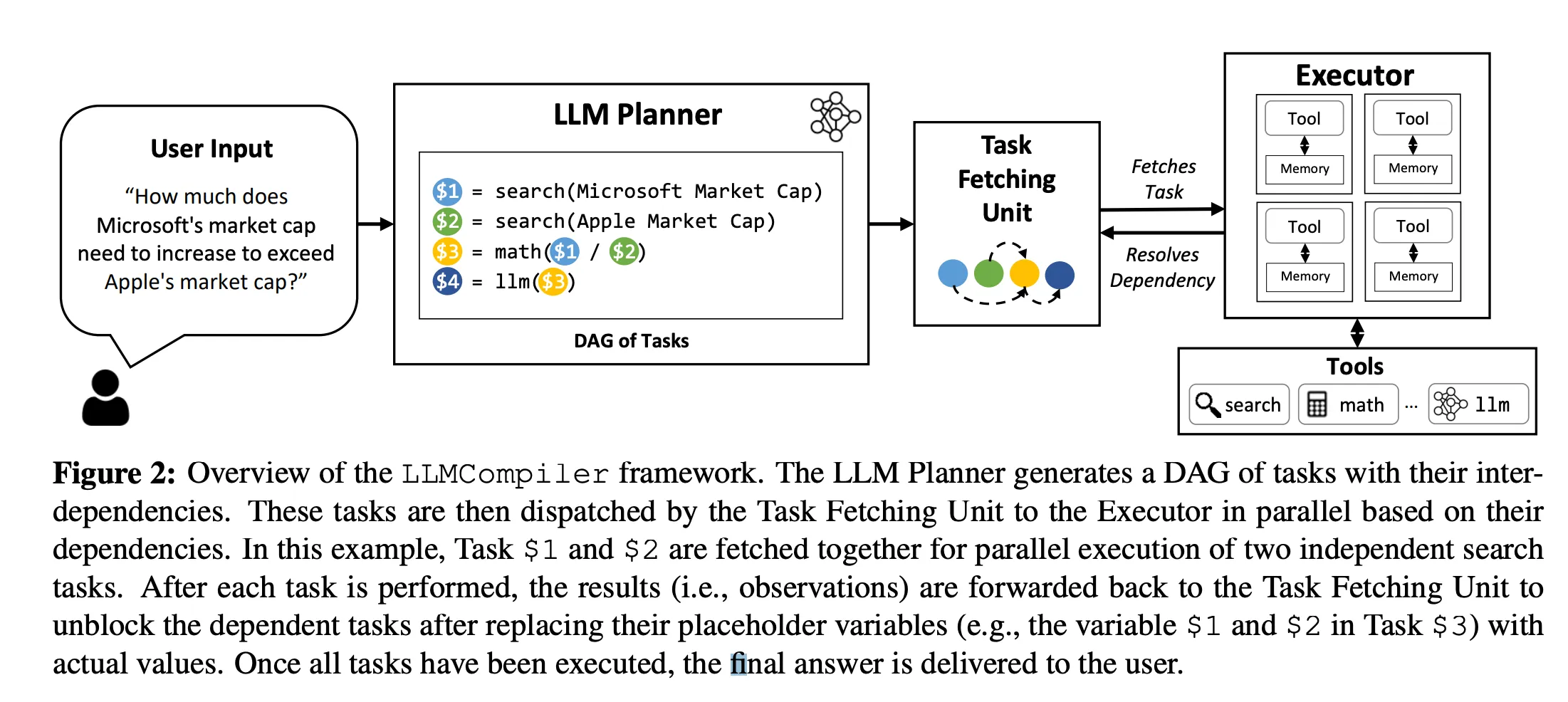
There are several variations and implementations of agentic workflows. For example, one popular method is LLM compiler (Integrated with RAG), which can be described as follows:
Query -> Generate Task DAG -> Dispatch [Tasks] -> Unblock Dependent Tasks with Results -> Final Answer
First, the Task DAG is generated to outline the tasks and their interdependencies. Then, tasks are dispatched for parallel execution based on their dependencies. Results are forwarded back to unblock dependent tasks, and once all tasks are executed, the final answer is delivered to the user (source - https://arxiv.org/pdf/2312.04511.pdf).
The proposed shorthand notation offers a simple way to represent and communicate advanced RAG pipelines, enabling researchers and practitioners to effectively share and compare different techniques.
As the field of RAG continues to evolve, with new techniques and approaches emerging, this shorthand notation can help document differences in these methods. I encourage the community to adopt and extend this notation, fostering collaboration and knowledge-sharing within the RAG domain.
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.