I Solved a Nasty Data Deserialization Problem involving Kafka, Go, and Protocol Buffers using Amazon Q. Here is How.
Every once in a while, software engineers get stuck with a problem that torment them for days. In this blog post, I share how Amazon Q helped me solve a problem related to data deserialization using Protocol Buffers.
Published Apr 26, 2024
Last Modified May 31, 2024
In the world of software engineering, there are moments when the people responsible for some code have no clue about why it is not working. For reasons beyond their control, they simply can't understand why their code is misbehaving and letting them down. I was once part of a team building an application using the microservice architecture style. Originally, this application implemented the communication between services using REST APIs. As you may know, REST APIs are synchronous by nature, arguably slow, and not really fault-tolerant. Eventually, problems related to these limitations rose. That was when the team had the idea of changing the implementation to use Apache Kafka as the communication backbone instead of REST APIs.
This change served me the right opportunity to experiment with the cluelessness I mentioned before. Not because of Kafka, of course. But because of the curveball this change would bring to my implementation.
Using Kafka would solve many of the problems found with REST APIs. It is asynchronous by nature, meaning that calls from one service to another won't be blocking, allowing for scalability and lower latency. Kafka also scales horizontally with its built-in support for partitions. Adding more nodes to the cluster allows for massive parallelization of processing. Partitions in Kafka are persistent by default. This allows for more resiliency in the communication model, as messages won't be lost if services get down during data transmission. Finally, partitions can be replicated across the cluster. that grants durability and fault-tolerance.
Once everybody agreed to adopt Kafka, the next step was to define which serialization strategy to adopt. Through REST APIs, messages were exchanged as JSON documents. JSON is simple to read and widely available in every programming language—but it has lots of drawbacks. It is highly verbose, lacks a strong schema model, and is slow to process since it is string-based. Since Kafka allows the storage of any array of bytes, this would get the application the ability to adopt a serialization strategy based on binary format. As many of the microservices were written in different programming languages like Java, Python, and Go, the idea was to adopt a binary serialization strategy these languages could effortlessly adopt. Protocol Buffers as the final choice. It's fast, provides robust schema management, and it was supported by the required programming languages.
The established plan was: implement the new Kafka-based version of the application considering the flow of the transactions. For one of the transactions, I was responsible for a microservice in Go that executes right after one written in Java. Thus, the team responsible for the Java microservice refactored their project first. Once they finished, I started mine in Go. My implementation used the same
.proto file the other team used to generate the code for their project. This is the mental model Protobuf uses, different teams relying on the same domain model defined.1
2
3
4
5
6
7
syntax = "proto3";
message Person {
string userName = 1;
optional int64 favoriteNumber = 2;
repeated string interests = 3;
}
I used the Protobuf compiler for Go to generate the code. From the
.proto file, the person.pb.go code that describes the Person{} struct from the domain model. From this point on, the job was essentially to refactor the code to read the messages from Kafka, decode the message using Protobuf, and continue the logic of the code as usual. Protobuf is native to Go, so I assumed it wouldn't be that hard. Indeed, I could implement the code fairly quickly and get ready for the tests. Here is the initial version of the code I wrote.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
func main() {
sigchan := make(chan os.Signal, 1)
topics := []string{topicName}
c, err := kafka.NewConsumer(&kafka.ConfigMap{
"bootstrap.servers": bootstrapServers,
"broker.address.family": "v4",
"group.id": uuid.New(),
"session.timeout.ms": 6000,
"auto.offset.reset": "earliest",
"enable.auto.offset.store": false,
})
if err != nil {
fmt.Fprintf(os.Stderr, "Failed to create consumer: %s\n", err)
os.Exit(1)
}
c.SubscribeTopics(topics, nil)
run := true
for run {
select {
case sig := <-sigchan:
fmt.Printf("Caught signal %v: terminating\n", sig)
run = false
default:
ev := c.Poll(100)
if ev == nil {
continue
}
switch e := ev.(type) {
case *kafka.Message:
person := Person{}
err = proto.Unmarshal(e.Value, &person)
if err != nil {
fmt.Printf("🧑🏻💻 userName: %s, favoriteNumber: %d, interests: %s\n",
person.UserName, *person.FavoriteNumber, person.Interests)
}
_, err = c.StoreMessage(e)
if err != nil {
fmt.Fprintf(os.Stderr, "%% Error storing offset after message %s:\n",
e.TopicPartition)
}
case kafka.Error:
fmt.Fprintf(os.Stderr, "%% Error: %v: %v\n", e.Code(), e)
if e.Code() == kafka.ErrAllBrokersDown {
run = false
}
}
}
}
fmt.Printf("Closing consumer\n")
c.Close()
}
Of course, the actual logic of the microservice is fairly more complicated than what is shown here, but all I wanted at this point was to make sure the communication mode using Kafka and Protobuf was working. This is done primarily in the lines
34 to 36. There, I receive the message from Kafka in the format of byte[] and I start the process of deserializing it back to the data structure the message represents, the Person{} struct in this case. For this, I used the google.golang.org/protobuf/proto package to decode the array of bytes into a pointer of the struct.Even though I thought having everything under control, testing the code for the first time proved I was wrong. I got a flat out error while reading the message from Kafka. Up until this point I didn't stress much about it. I just had executed the code for the first time and historically, this never works anyway. So I went ahead and started a new debugging session and set a breakpoint exactly one line before the code was performing the deserialization.
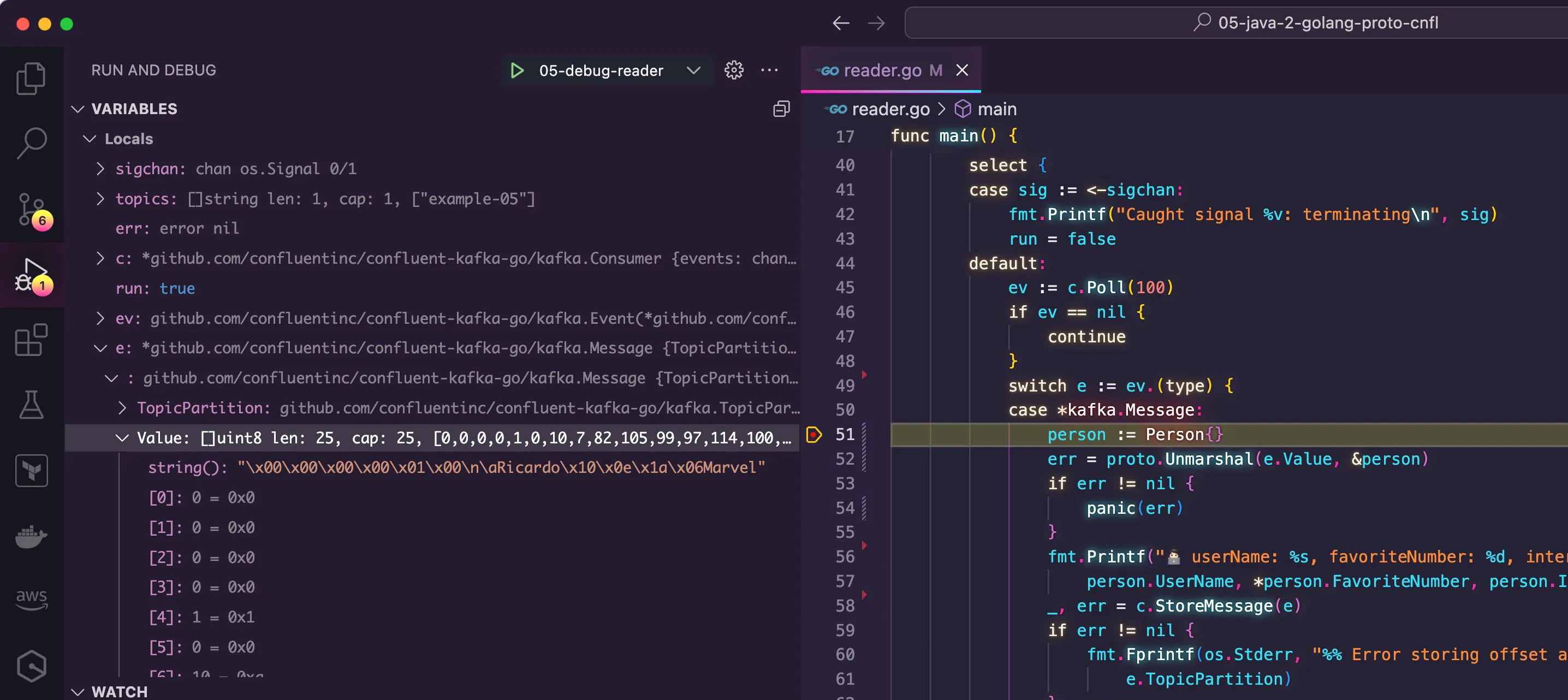
When the breakpoint finally hit, I was glad to see that the most important part had worked. I was able to see the message from Kafka being received. I expanded the message to check the details of the value and I could see that the data I had provided was there. However, after going through the line that performs the deserialization, I could see an error coming through.
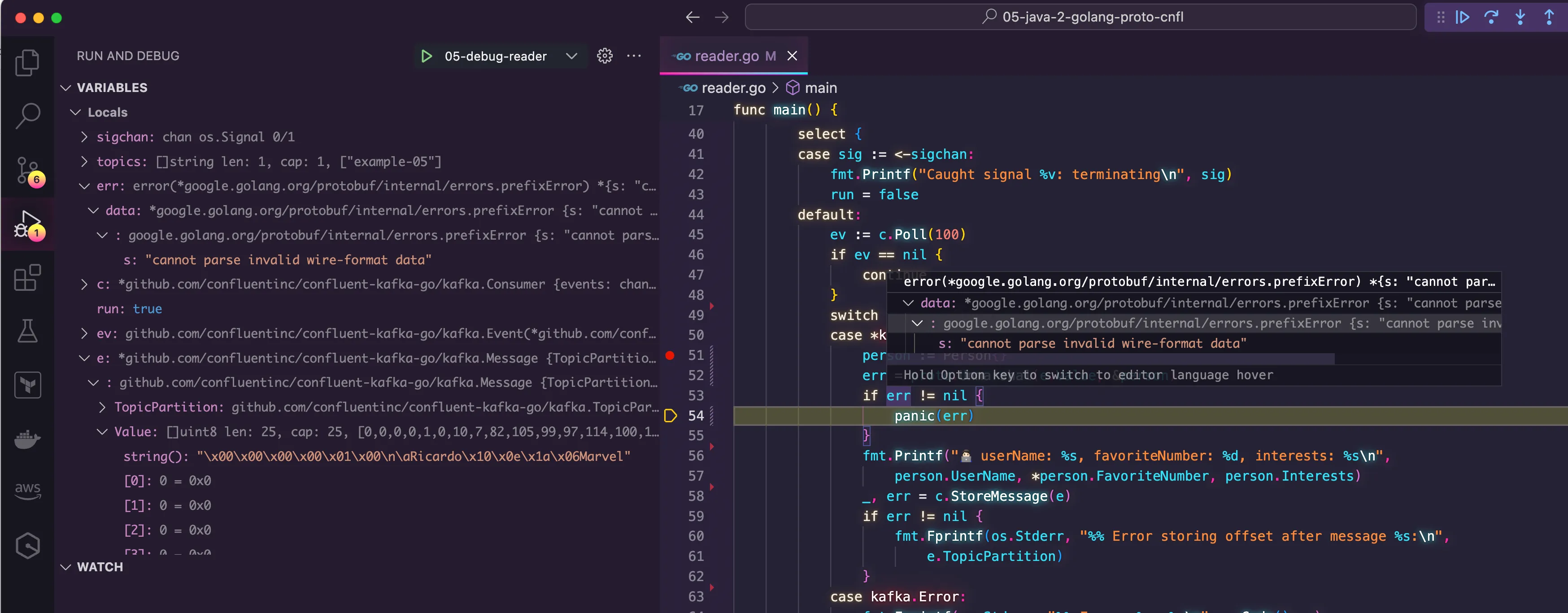
"cannot parse invalid wire-format data"
Then I hit the moment when I realized I don't know anymore what is going on. Worst, I had no clue of what to do next. Many software engineers know exactly this feeling. You go from thinking you know everything to questioning your life choice of even becoming a software engineer in the first place. Then I realized that I could ask Amazon Q for guidance. I started a new conversation session and asked the following question:

Even though I had provided the question with a typo, I got this from Amazon Q:
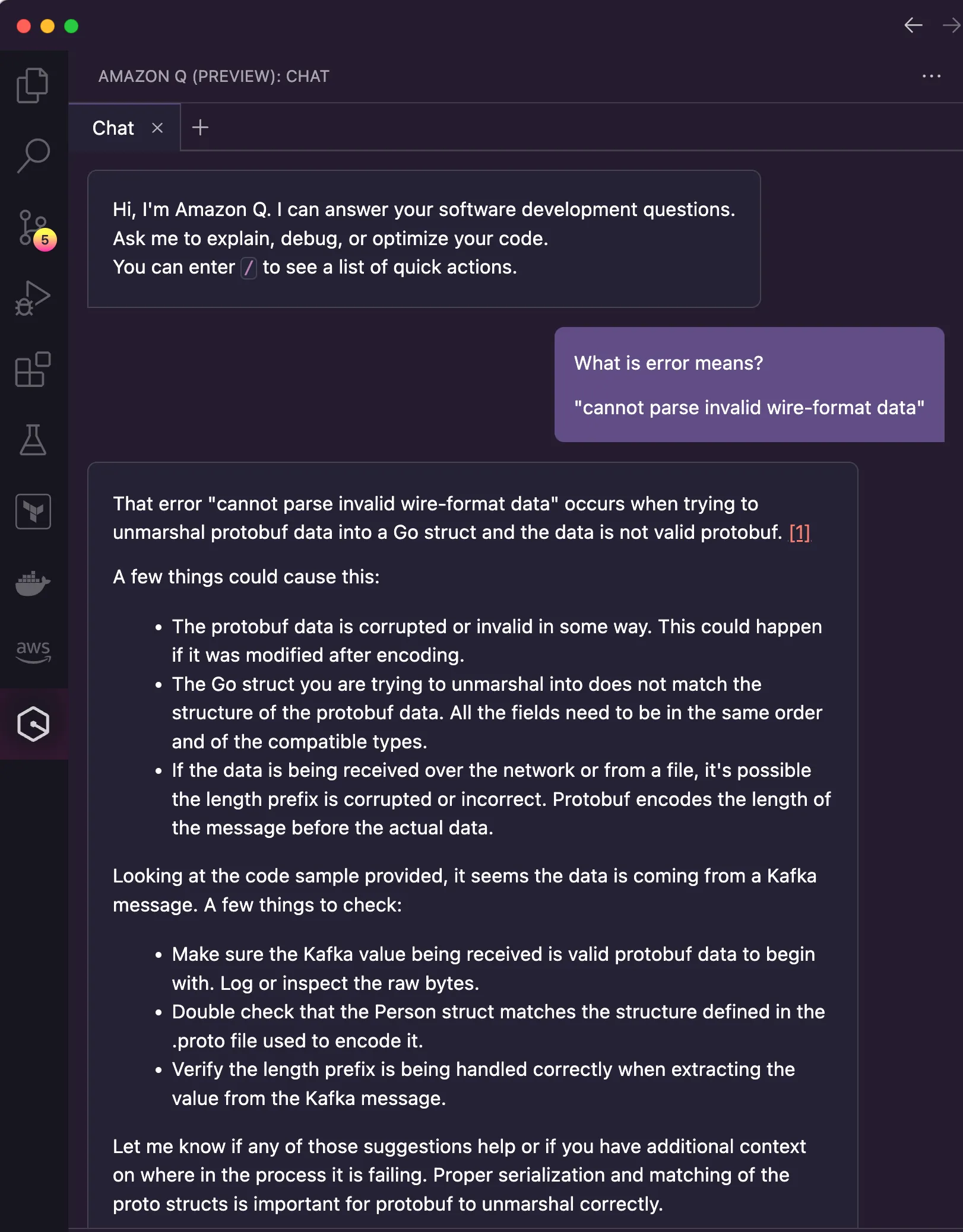
Before I go over the response, let me share something that I was positively surprised. The AI was able to provided me with a recommendation based on the code that I actually wrote. In my prompt, I didn't say that I was working with Go, nor that I was reading messages from Kafka. Yet, the AI was able to infer these details from the code I had open in the editor. Call me silly, but I think this is fantastic.
I went through each suggestion from Amazon Q, ruling out the ones that I knew were not causing the issue.
| Suggestion | It can't be because |
|---|---|
| The protobuf data is corrupted or invalid in some way. This could happen if it was modified after encoding. | I was the only who wrote the data into the Kafka topic. Moreover, I could check that the same message stored was the one that I received in my debugging session. |
| The Go struct you are trying to unmarshal into does not match the structure of the protobuf data. All the fields need to be in the same order and of the compatible types. | I was working with a fresh new copy of the code generated by the Protobuf compiler. No modifications were made in the created code. |
| Double check that the Person struct matches the structure defined in the .proto file used to encode it. | Yes, I double-checked and it matches. |
By ruling out these options, I ended up with the following investigation hypothesis.
- Check if the length prefix is corrupted or incorrect.
- Check if the data is valid Protobuf data to begin with.
I was really skeptical about checking for these two things, as I was coming from the assumption that once a message is serialized using Protobuf, deserializing would give me nothing but an actual working data. But then again, reality beats assumptions. My code wasn't working, and I had to investigate this further.
To start the investigation, I retrieved the message bytes received from Kafka. This is the array of bytes that represents the serialized message.
1
0000101078210599971141006f02000e074d61727665Having this is not much useful if I can't compare with anything. So I asked Amazon Q to produce an example of byte representing a message serialized using Protobuf given the
.proto file of the project.
Response:

I found this very useful, because not only it gave me what I asked for, but also explained byte by byte what each one represents. The first thing that caught my eye was learning that
08 represents the length of the string used for the userName field. In the example provided, John Doe was used as user name. This name has exactly 8 characters. The message that I sent to Kafka had Ricardo as the user name, so the first byte of the array should be 07and not, 00. Something indeed was wrong with the message that I was receiving in my Go code. Hands down, the investigation hypothesis that I got from Amazon Q was spot on.To make sure I was dealing with the right data, I came back to Amazon Q and asked for a more specific question.

Response:
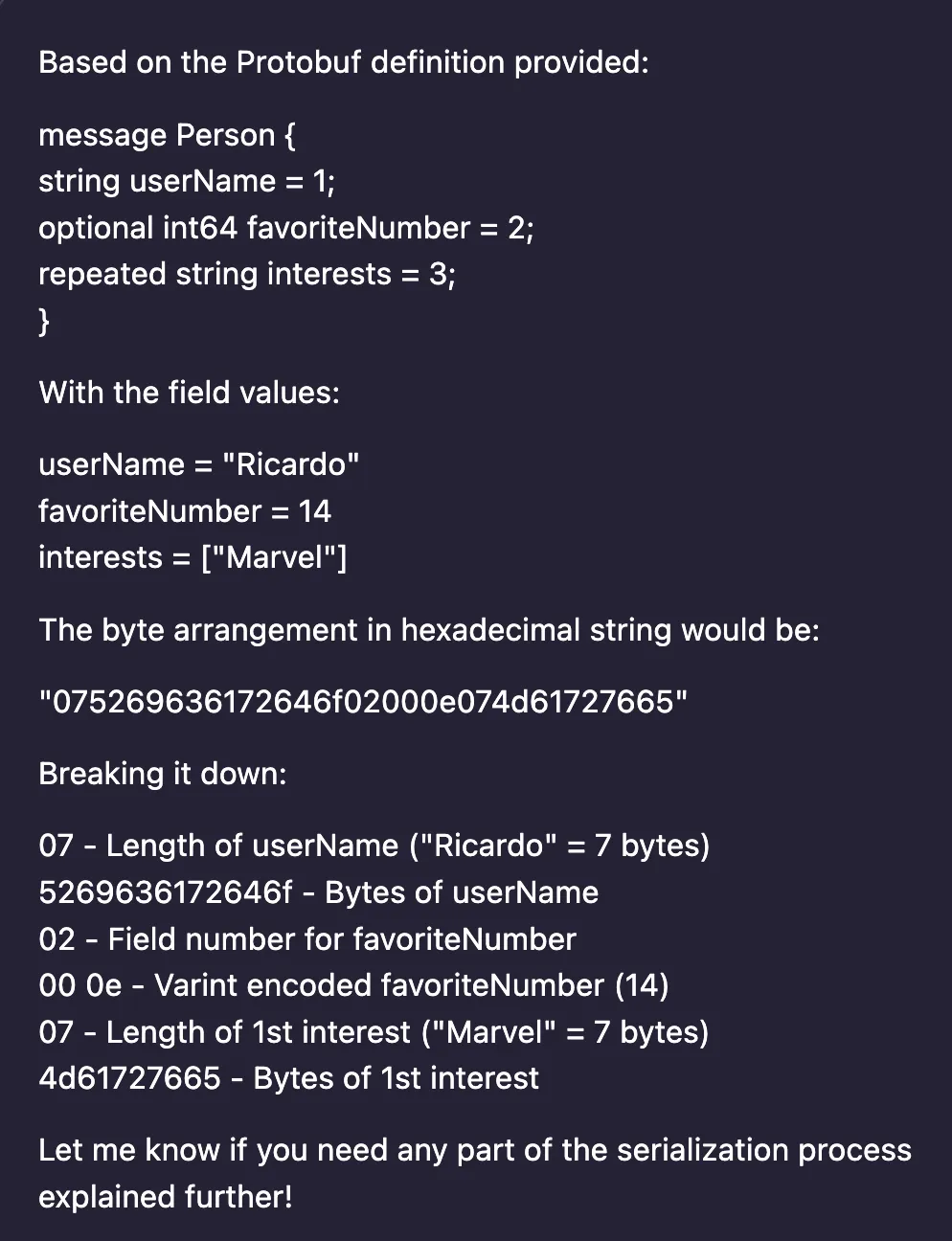
This was it. I had the undeniable proof that indeed my code was dealing with invalid Protobuf data, and a length format that didn't match with the values I had provided. After all, what I was getting with the byte sequence
0000101078210599971141006f02000e074d61727665 starts with a bunch of zeros instead of 07.With this information at hand, I had a meeting with the team responsible for the Java microservice. I asked them about the version of the Protobuf for Java they were using to serialize the messages. My suspicious was that perhaps they were using a version of the software that wasn't up to date, and this could be leading to the wrong bytes being used in the message. However, to my surprise, they replied saying they didn't use anything from Protobuf. They had used the Protobuf support provided by the Java client from Confluent.
They explained to me the Java client from Confluent takes care of handling the message serialization using Protobuf. However, I told them that my Go code wasn't being able to deserialize the messages because of issues related to byte arrangement incompatibility. I was surprised to see that they had a sample code in Java created to read the messages off the Kafka topic, and it was working as expected. Somehow, those bytes were being used correctly by Java. At least I got them intrigued with the fact that my Go code wasn't working. So we started a group debugging session backed by Amazon Q. They explained that the only Protobuf-y task they did was to generate the Person class using the Protobuf compiler for Java. Then they shared the Java code that uses that class to create the message into Kafka.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaProtobufSerializer.class.getName());
properties.put(KafkaProtobufSerializerConfig.SCHEMA_REGISTRY_URL_CONFIG, SCHEMA_REGISTRY_URL);
try (KafkaProducer<Integer, Person> producer = new KafkaProducer<>(properties)) {
Person person = Person.newBuilder()
.setUserName("Ricardo")
.setFavoriteNumber(14)
.addInterests("Marvel")
.build();
ProducerRecord<Integer, Person> record = new ProducerRecord<>(TOPIC_NAME, 1, person);
producer.send(
record, (recordMetadata, e) -> {
System.out.printf("➡️ Message sent successfully to topic [%s] ✅\n", recordMetadata.topic());
});
}
I grabbed that piece of code and added to Amazon Q as prompt. Then I asked to explain back to me how this code is serializing messages using Protobuf.
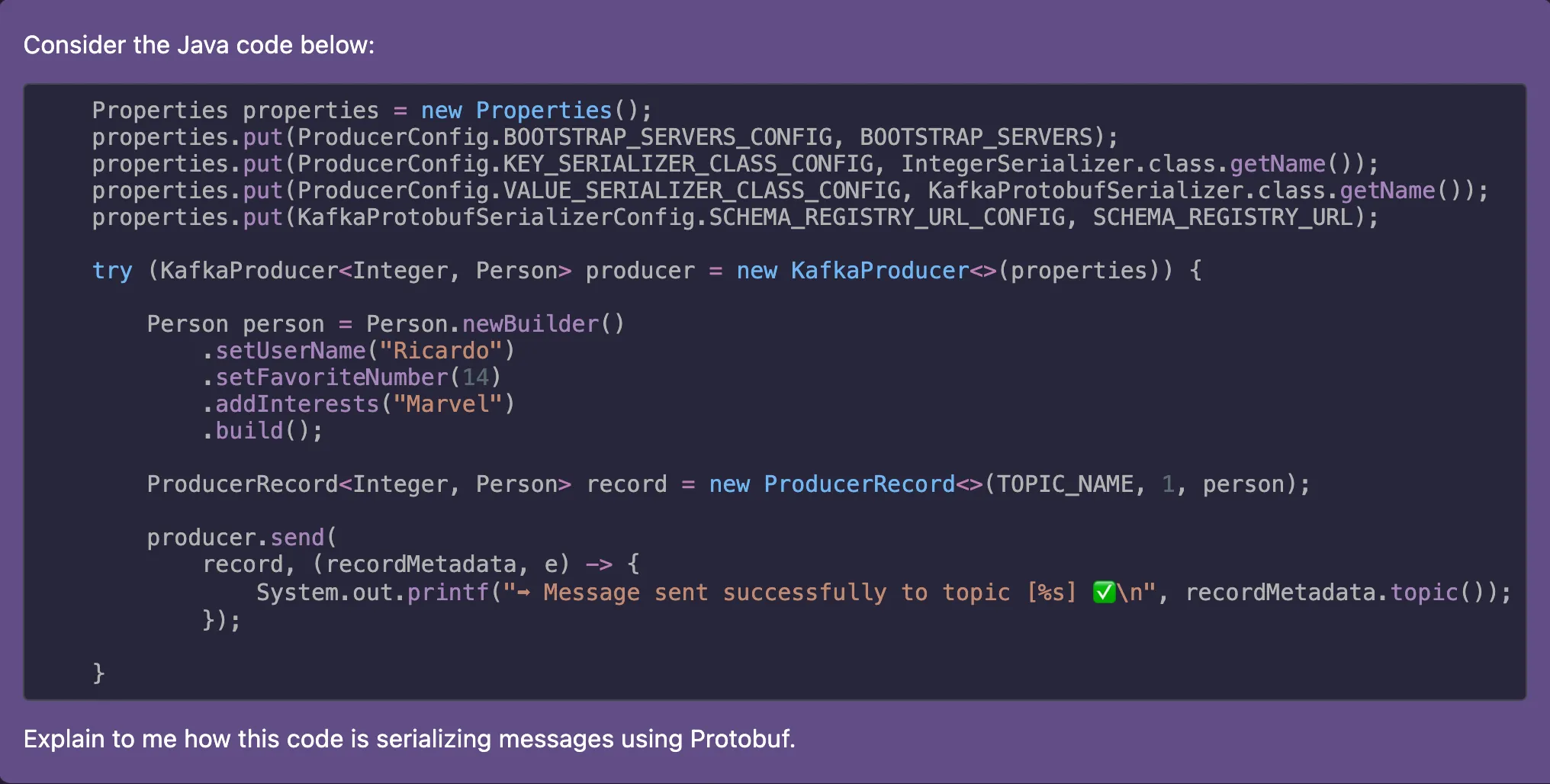
Response:

The most important aspect from this response is the point number
7. It shares that this class called KafkaProtobufSerializer is the one who effectively carry on the serialization. Understanding this was the key to understand how the message is ending up with the bytes in that order. I searched for the Java code that implements that class on GitHub and asked to Amazon Q:
Response:

Bingo. Amazon Q helped me find the problem. The implementation from Confluent first writes a few administrative bytes in the message to then use the Protobuf serialization. This causes the message to have more bytes than what is generated by the Protobuf client for Java. In this case, the culprit was not even being about Java, but the specific implementation from Confluent.
My first instinct was to ask the team responsible for the Java microservice to change their implementation approach and use the official Protobuf support. However, they claimed this wouldn't be possible, as other systems were already pulling data from Kafka using that format. These other systems are beyond their control, and changing them was certainly out of the scope. This meant that I had to absorb the technical debt in my Go code. ¯\_(ツ)_/¯
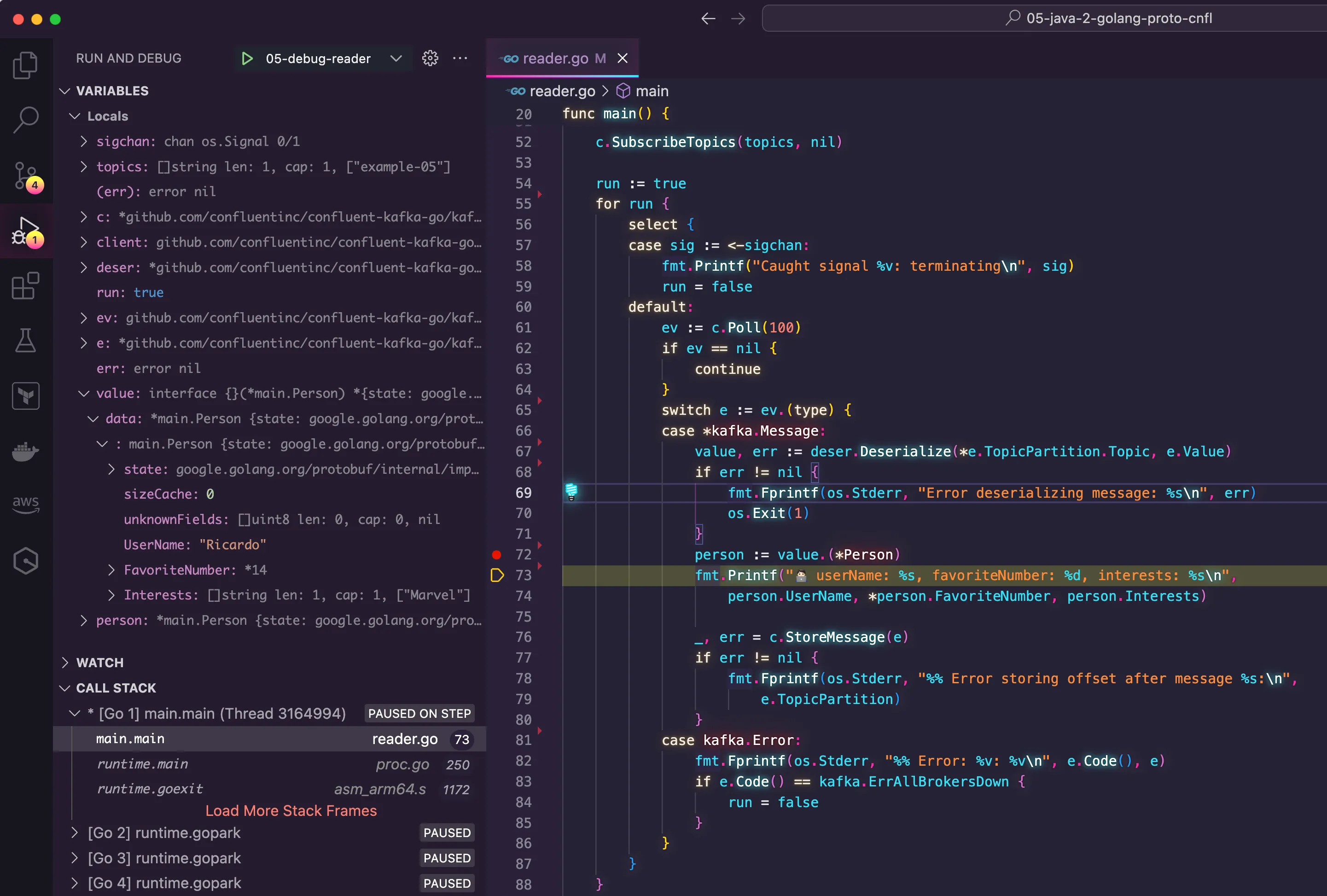
It turns out, Confluent's client for Go has the support to handle their proprietary format of serialization. I was just not using. This is the code that I ended up implementing.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
func main() {
sigchan := make(chan os.Signal, 1)
topics := []string{topicName}
c, err := kafka.NewConsumer(&kafka.ConfigMap{
"bootstrap.servers": bootstrapServers,
"broker.address.family": "v4",
"group.id": uuid.New(),
"session.timeout.ms": 6000,
"auto.offset.reset": "earliest",
"enable.auto.offset.store": false,
})
if err != nil {
fmt.Fprintf(os.Stderr, "Failed to create consumer: %s\n", err)
os.Exit(1)
}
client, err := schemaregistry.NewClient(schemaregistry.NewConfig(schemaRegistryURL))
if err != nil {
fmt.Printf("Failed to create schema registry client: %s\n", err)
os.Exit(1)
}
deser, err := protobuf.NewDeserializer(client, serde.ValueSerde, protobuf.NewDeserializerConfig())
if err != nil {
fmt.Printf("Failed to create deserializer: %s\n", err)
os.Exit(1)
}
deser.ProtoRegistry.RegisterMessage((&Person{}).ProtoReflect().Type())
c.SubscribeTopics(topics, nil)
run := true
for run {
select {
case sig := <-sigchan:
fmt.Printf("Caught signal %v: terminating\n", sig)
run = false
default:
ev := c.Poll(100)
if ev == nil {
continue
}
switch e := ev.(type) {
case *kafka.Message:
value, err := deser.Deserialize(*e.TopicPartition.Topic, e.Value)
if err != nil {
fmt.Fprintf(os.Stderr, "Error deserializing message: %s\n", err)
os.Exit(1)
}
person := value.(*Person)
fmt.Printf("🧑🏻💻 userName: %s, favoriteNumber: %d, interests: %s\n",
person.UserName, *person.FavoriteNumber, person.Interests)
_, err = c.StoreMessage(e)
if err != nil {
fmt.Fprintf(os.Stderr, "%% Error storing offset after message %s:\n",
e.TopicPartition)
}
case kafka.Error:
fmt.Fprintf(os.Stderr, "%% Error: %v: %v\n", e.Code(), e)
if e.Code() == kafka.ErrAllBrokersDown {
run = false
}
}
}
}
fmt.Printf("Closing consumer\n")
c.Close()
}
As you can see; this code is fairly more elaborated than my previous one. It connects with Confluent's Schema Registry to retrieve the schema being used for deserialization, and it registers a deserializer that will be responsible for handling the "byte mess" before retrieving the actual Protobuf message. In the end, it worked like a charm.
There are moments in life where software engineers feel completely clueless about why their code is not working. This is not a reason to feel ashamed, as it may happen to us all. If this ever happens to you, please know that you can use Amazon Q to be your troubleshooting friend.
In this blog post, I shared with you how I used Amazon Q to investigate a part of my code that was not working. Amazon Q was amazing in making inferences about this code, giving me some suggestions about what to investigate, providing me examples of how Protobuf deserialize data, and even about how to read code and explain it back to me. With this type of resource at your disposal, you can reduce your troubleshooting cycle considerably.
Follow me on LinkedIn if you want to geek out about technologies.
2 Comments
Log in to comment