Staff Pick
Navigating through failures, build resilient serverless systems
Serverless and event-driven workloads on AWS are well known for their inherent high availability and scalability, offering a robust platform right out of the box. In the world of cloud, it's well known that everything fails all the time. This reality becomes even more complex when serverless systems interact with non-serverless components. In this post, I'll dig into architecture concepts that can help you handle failures effectively.
Published Apr 26, 2024
Last Modified Apr 28, 2024
Navigating failures! Building resilient serverless workloads!
I have been building and architecting serverless systems for almost a decade now, for a variety of companies, from small start-ups to large enterprises. And I have seen many strange things over the years.
Serverless services from AWS come with high availability and resiliency built in. But that is on the service level, AWS Lambda, StepFunctions, EventBridge, and so on are all highly available and have high resiliency.
If all components in our systems were serverless that would be great. However, that is not the case. In almost all systems that I have designed or worked on there has been components that are not serverless. It can be the need for a relational database, and yes, I do argue that not all data-models and search requirements can't be designed for DynamoDB. It can be that we need to integrate with a 3rd party and their API and connections come with quotas and throttling. It could be that we as developers are unaware of certain traits of AWS services that make our serverless services break. And even sometimes our users are even our worst enemy. When we are building our serverless systems we must always remember that there are components involved that don't scale as fast or to that degree that serverless components does.
In this post I'm going to give some thoughts on navigating failures and building a high resiliency serverless system. This post is not about preventing failures, instead it's about handling and recover from failures in a good way. I'll start with a common serverless architecture and add architecture concepts, that I often use, that can help enhance its resiliency.
Many of the concepts in this post can also be found on My serverless Handbook all with different implementation examples and fully working and deployable infrastructure using CloudFormation and SAM.
My definition of serverless is probably the same as for many of you and AWS as well. Serverless services come with automatic and flexible scaling, scale down to zero and up to infinity (almost). Serverless services has little to none capacity planning, I should not have to do much planning how much resources I need before hand. Serverless services has a pay-for-use, if I don't use it I don't pay for it.
But. this is not black or white, there is a grey zone I think. Where services like Fargate and Kinesis Data Stream ends up.
Looking at services from AWS, in the red corner we have serverless services API gateway, Lambda, SQS, StepFunctions, DynamoDB and more. Services that we can throw a ton of work on and they will just happily scale up and down, to handle our traffic.
In the blue corner we have the managed services. This is services like Amazon Aurora, ElasticCache, OpenSearch. This is services that can scale basically to infinity, but they do require some capacity planning for that to happen, and if we plan incorrectly we can be throttled or even have failing requests. I will also put the grey zone services, like Fargate and Kinesis Data Streams in this blue corner.
Then there is the server corner, that would be anything with EC2 instances. We don't speak about them.....
So, what is resiliency?
Sometimes it gets confusing, and people mix up resiliency with reliability. As mentioned in the beginning, resiliency is not about preventing failures, it's about recovering from them. It’s about making sure our system maintain an acceptable level of service even if when other parts of our system is not healthy. It's about gracefully deal with failures.
Reliability focuses on the prevention of the failure happening in the first place, while resiliency is about recovering from it.
This is by far one of my favorite quotes by Dr. Werner Vogels. Because this is real life! Running large distributed systems, then everything will eventually fail. We can have down stream services that is not responding as we expect, they can be having health problems. Or we can be throttled by a 3rd party or even our own services.

It's important that the cracks that form when components in our system fail, doesn't spread. That they don't take down our entire system. We need ways to handle and contain the cracks. That way we can isolate and protect our entire system.

When our serverless systems integrate with non-serverless components. Which in some cases it can be obvious, like when our system interacts with an Amazon Aurora database. Other times it's not that clear, the system integrates with a 3rd party API that can lead to throttling that can affect our system and start forming cracks if not handled properly.
How does our system handle a integration point that is not responding? Specially under a period of high load. This can easily start creating cracks that can bring our entire system to a halt or that we start loosing data.
When we build serverless systems we must remember that every API in AWS has a limit. We can store application properties in System Manager Parameter Store, a few of them might be sensitive and encrypted with KMS. What now happens is that we can get throttled by a different service without realizing it. SSM might have a higher limit but getting an encrypted value would then be impacted by the KMS limit. If we then don't design our functions correctly, and call SSM in the Lambda handler on every invocation we would quickly get throttles. Instead we could load properties in the initialization phase.
Understanding how AWS services work under the hood, to some extent, is extremely important, so our systems doesn't fail due to some unknown kink. For example, consuming a Kinesis Data Stream with a Lambda function, if processing an item in a batch fails, the entire batch will fail. The batch would then be sent to the Lambda function over and over again.
What we can do in this case is to bisect batches on Lambda function failures. The processed batch will be split in half and sent to the function. Bisect would continue to we only have the single failing item left.
Now, I bet most of you run a multi-environment system, you have your dev, test, pre-prod, and prod environments. Many would probably say that your QA, Staging, Pre-prod, or what ever you call it, has an identical setup with your prod environment. But now, let's make sure we consider data and integrations as well. The amount of data, the difference in user generated data, the complexity in data, difference in integrations with 3rd party. I have seen system been taken down on multiple occasions due to differences in data and integration points. Everything works in staging but then fails in production.
One large system I worked on we had a new advanced feature that had been tested and prepared in all environments. But, when deploying to production, the database went haywire on us. We used Amazon Aurora serverless and the database suddenly scaled out to max and then could handle the load anymore. Our entire service was brought down. This was caused by a SQL query that due to the amount of data in production consumed all database resources, in a nasty join.
In a different system, I had a scenario where in production a 3rd party integration had an IP-Allow list in place, so when we extended our system and got some new IPs suddenly only one third of our calls was allowed and a success. In the staging environment, the 3rd party didn't have any IP-blocks. Intermittent failures are always the most fun to debug.
A good way to practice and prepare for failures are through Resiliency testing, chaos engineering. AWS offers their service around this topic, AWS Fault Injection Service, which you can use to simulate failures and see how your components and system handles them. What I'm saying is that when you plan for your Resiliency testing, start in your QA or staging environment. But, don't forget about production and do plan to run test there as well.
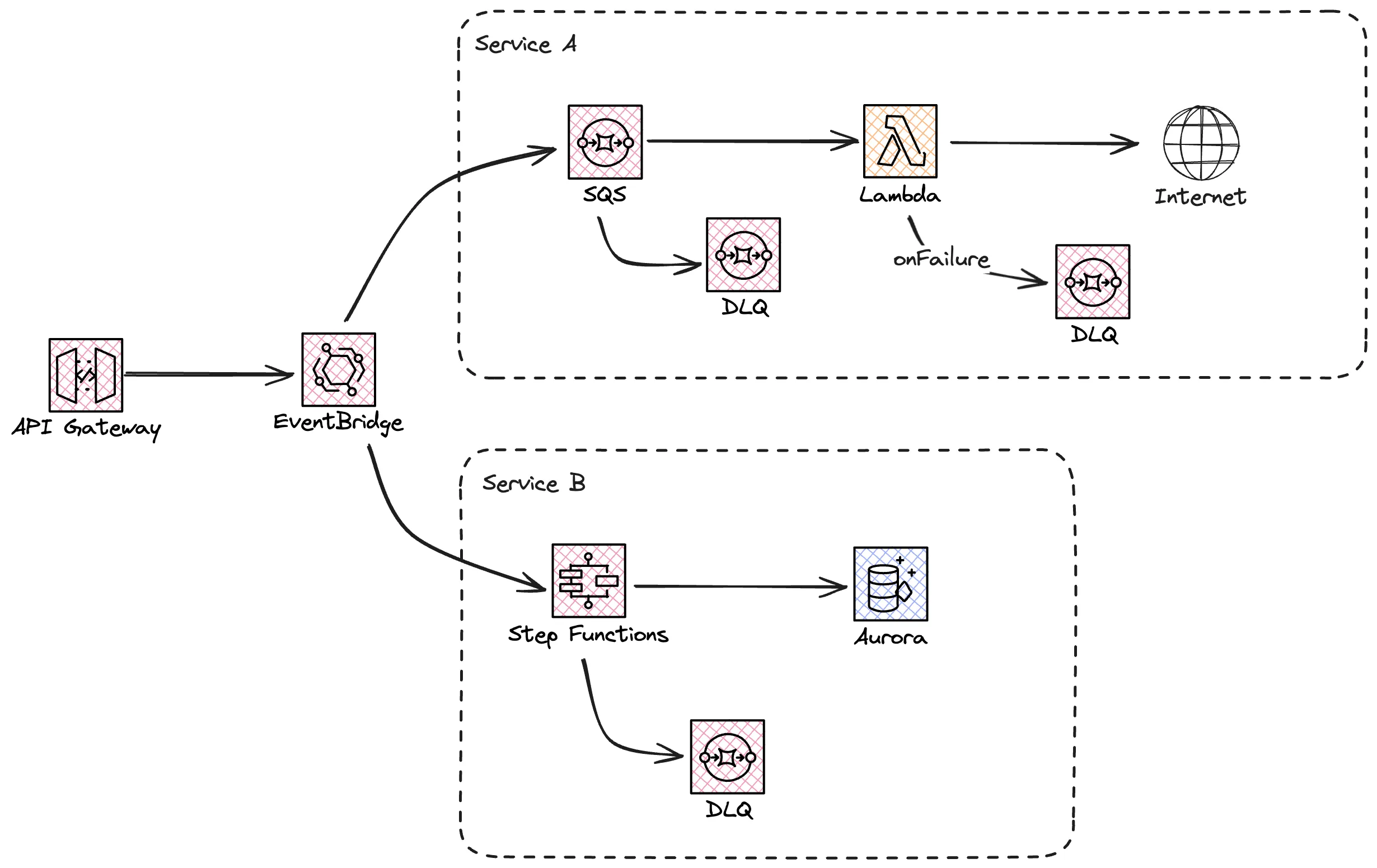
Now let's start off with a classic web application, single page application with an API. SPA hosted from S3 and CloudFront, API in API Gateway and compute in Lambda, finally a database in DynamoDB. That is one scalable application!
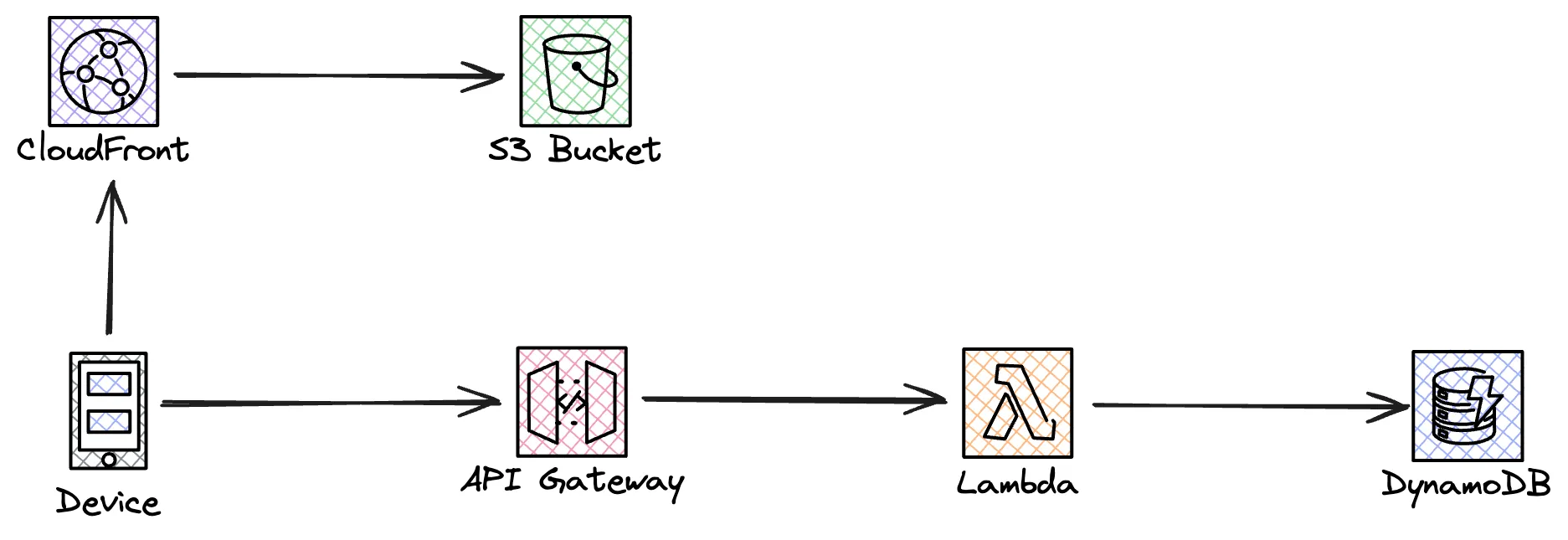
But, maybe we can't model our data in DynamoDB? Not everything will fit in a key/value model, we need an relational database like Aurora, or we need to integrate with 3rd party. This could be an integration that still run on-prem, it could be running in a different cloud on servers. With any form of compute solution that doesn’t scale as fast and flexible as our serverless solution. This application is setup as a classic synchronous request-response where our client expect a response back immediate to the request.

Most developers are very familiar with the synchronous request-response pattern. We send an request and get a response back. We wait for this entire process to happen, with more complex integrations with chained calls and even 3rd party integrations the time quickly adds up, and if one of the components is down and not responding we need to fail the entire operation, and we leave any form of retries to the calling application.
One question we need to ask when building our APIs is does our write operations really need an immediate response? Can we make this an asynchronous process? Now, building with a synchronous request-response is less complex than an asynchronous system. However, in a distributed system, do the calling application need to know that we have stored the data already? Or can we just hand over the event and send a response back saying that "Hey I got the message and I will do something with it". In an event-driven system asynchronous requests are very common.
With an asynchronous system we can add an buffer between our calls and storage of our data. What this will do is protect us and the downstream services. The downstream service will not be overwhelmed and by that we protect our own system as well from failures. This can however create an eventual consistency model, where read after write not always gives us the same data back.
Buffers leads us to our first good practice when building a high resiliency system, storage-first. The idea behind the storage-first pattern is to not do immediate processing of the data. Instead we directly integrate with a service from AWS, it could be SQS, EventBridge or any other service with a durable storage mechanism. I use the storage-first pattern in basically all systems I design and build.
So, let's get rid of the Lambda integration and instead integrate directly to the SQS. It doesn't have to be SQS it can be any service. The major benefits with the storage first pattern is that the chance of us loosing any data is very slim. We store it in a durable service and the process it as we see fit. Even if processing would fail we can still handle and process it later.
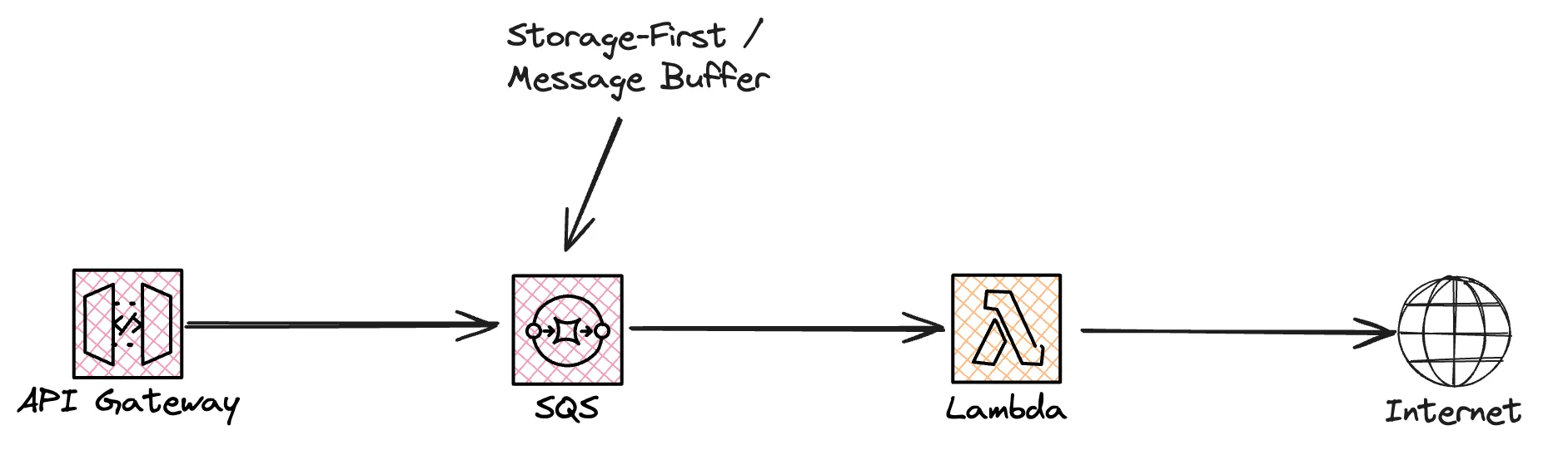
For more implementation examples check out My serverless Handbook and Storage-First Pattern
When using storage-first pattern with SQS we have the possibility to use one more pattern, that I frequently use, the queue load leveling pattern, here we can protect the downstream service, and by doing that our self, by only processing events in a pace that we know the service can handle. Other benefits that come with this pattern, that might not be that obvious, is that it can help us control. We could run on subscriptions with lower throughput that is lower in cost, when integrating with a 3rd party. We could also down-scale our database, as we don't need to run a huge instance to deal with peaks. Same goes if we don't process the queue with Lambda functions but instead use containers in Fargate, we can set the scaling to fewer instances or even do a better auto-scaling solution.
One consideration with this pattern is that if our producers are always creating more requests than we can process, we can end up in a situation where we are always trailing behind. For that scenario we either need to scale up the consumers, which might lead to unwanted downstream consequences or we need at some point evict and throw away messages. What we choose, and how we do it, of course come with the standard architect answer "It depends...."
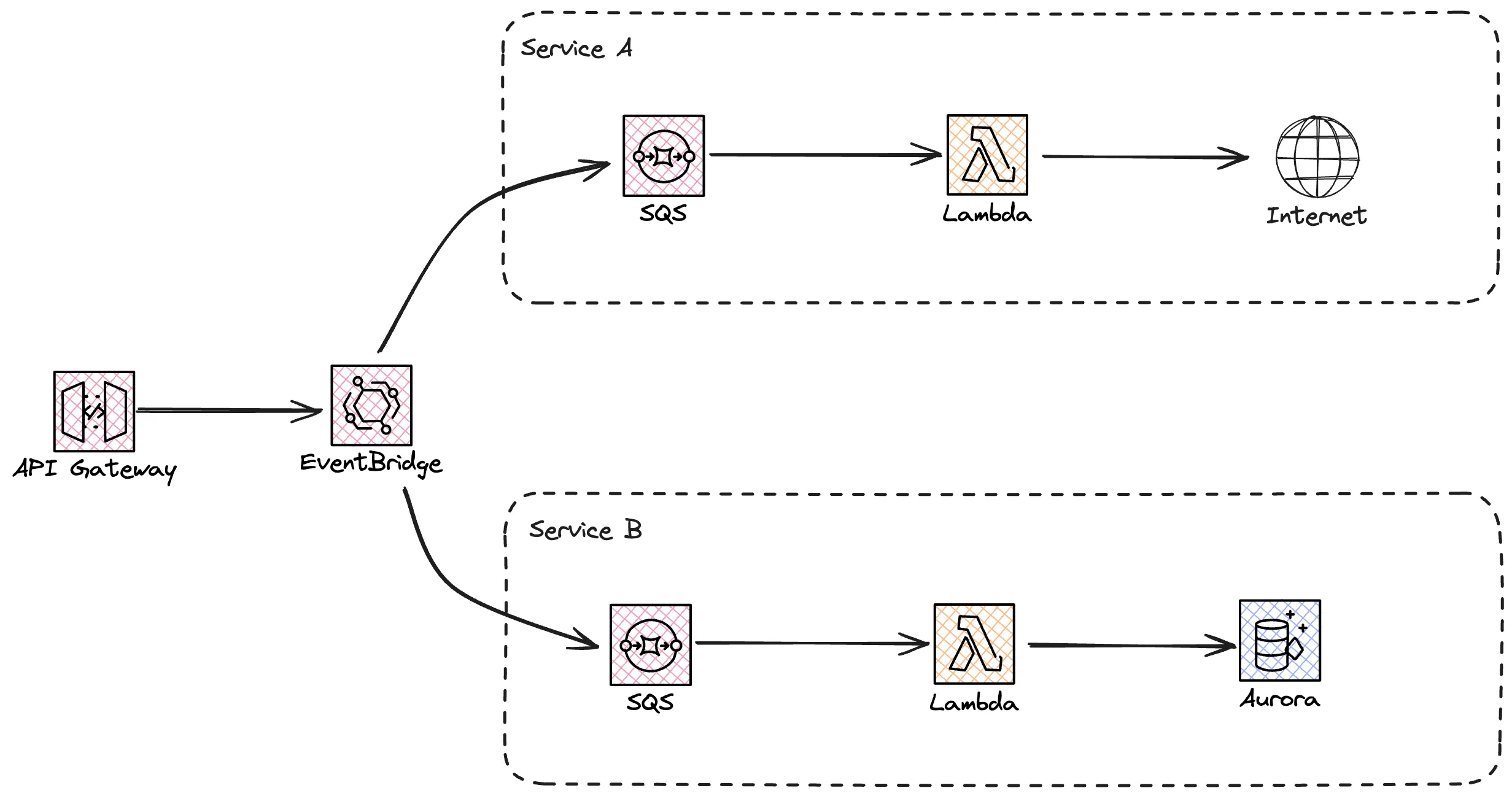
A good practice in a distributed system is to make sure services can scale and fail independently. That mean that we can have more than one service that it is interested in the request. For a SQS queue we can only have one consumer, two consumers can't get the same message. In this case we need to create a fan out or multicast system. We can replace our queue with EventBridge that can route the request or the message to many different services. It can be SQS queues, StepFunctions, Lambda functions, other EventBridge buses. EventBridge is highly scalable with high availability and resiliency with a built in retry mechanism for 24 hours. With the archive feature we can also replay messages in case they failed. And if there is a problem delivering message to a target we can set a DLQ to handle that scenario.
This is however one of the kinks that we need to make sure we are aware of. Remember that the DLQ only come into affect if there is a problem calling the target, lacking IAM permissions or similar. If the target it self has a problem and fails processing, message will not end up in the DLQ.
Even with a storage-first approach we are of course not protected against failures. They will happen, remember "Everything fails all the time".
In the scenarios where our processing do fail we need to retry again. But, retries are selfish and what we don't want to do, in case it's a downstream services that fail, or if we are throttled by the database, is to just retry again. Instead we like to backoff and give the service som breathing room. We would also like to apply exponential backoff, so if our second call also fails we like to back off a bit more. So first retry we do after 1 second, then 2, then 4, and so on till we either timeout and give up of have a success.
There is a study conducted by AWS, a couple of years ago, that show that in a highly distributed system retries will eventually align. If all retries happen with the same backoff, 1 second, 2 seconds, 4 seconds and so on they will eventually line up and happen at the same time. This can then lead to the downstream service crashing directly after becoming healthy just due to the amount of job that has stacked up and now happen at the same time. It's like in an electric grid, after a power failure, all appliances turn on at the same time creating such a load on the grid that it go out again, or we blow a fuse. We change the fuse, everything turn on at the same time, and the fuse blow again.
Therefor we should also use some form of jitter in our backoff algorithm. This could be that we add a random wait time to the backoff time. It would work that we first wait 1 second + a random number of hundreds of milliseconds. Second time we wait 2 second + 2x a random number, and so on. By doing that, our services will not line up the retries. How we add the jitter and how much, that well depends on your system and implementation.
A good way to handle retries is to use StepFunctions as a wrapper around our Lambda functions. StepFunctions has a built in retry mechanism which we can utilize in our solutions.
In some cases we just have to give up the processing. We have hit the max number of retries, we can't continue forever, this is where the DLQ come in. We route the messages to a DLQ where we can use a different retry logic or even inspect the messages manually. The DLQ also create a good indicator that something might be wrong, and we can create alarms and alerts based on number of messages in it. One message might not be an problem but if the number of messages start stacking up it's a clear indicator that something is wrong.
In case we are using SQS as our message buffer we can directly connect a DLQ to it. If we use StepFunctions as our processor we can send messages to a SQS queue if we reach our retry limit.
For a implementation examples check out My serverless Handbook and retries
For the final part in our system we look at the circuit breaker. Retries are all good, but there is no point for us to send requests to an integration that we know is not healthy, it will just keep failing over and over again. This is where this pattern comes in.
If you are not familiar with Circuit breakers it is a classic pattern, and what it does is make sure we don't send requests to API, services, or integration that is not healthy and doesn't respond. This way we can both protect the downstream service but also our self from doing work we know will fail. Because everything fails all the time, right.
Before we call the service we'll introduce a status check, if the service is all healthy we'll send the request this is a closed state of the circuit breaker. Think of it as an electric circuit, when the circuit is closed electricity can flow and the lights are on. As we do make calls to the service we'll update the status, if we start to get error responses on our requests we'll open the circuit and stop sending requests. In this state is where storage-first shine, we can keep our messages in the storage queue until the integration is back healthy again. What we need to consider is when to open the circuit, if we have 1000 requests per minute we don't want to open the circuit just because 10 fails. Also, checking the status before every invocation might also be a bit inefficient, so here we need to find a good balance when to check the status and when to open the circuit.
But! We just can't stop sending requests for ever. What we do is to periodically place the circuit in a half-open state to send a few requests to it and update our status with the health from these requests.
In case of an SQS queue we can't just stop calling the Lambda integration, instead we need to have some logic to add and remove the integration.


If now put all of the different patterns together we'll have serverless system that should be able to handle all kinds of strange problems.

In this post we have looked at how I normally design and build systems to make them handle and withstand failures. There is of course more to a ultra robust system and we always need to consider what happens if something fails. The different patterns and implementations in this post should however halp you a bit on your journey to resiliency.
Check out My serverless Handbook for some of the concepts mentioned in this post.
As Werner says! Now Go Build!