
Choose the right RAG Architecture for your AWS GenAI App
RAG reduces hallucination on Gen AI apps, it allows fine-tuning the LLMs with domain-specific knowledge. Rag results in better chat-bots and text generation apps. However, you might ask: "What AWS service should I use?"
Duvan Segura-Camelo
Amazon Employee
Published Jun 7, 2024
Retrieval-Augmented Generation (RAG) has emerged to enhance the capabilities of Large Language Models (LLMs) like Amazon Bedrock. This approach not only reduces hallucination, but also allows for fine-tuning the LLMs with domain-specific knowledge. This makes them better suited for tasks, such as chat-bots, virtual assistants or text generation applications. However, when the GenAI development starts, you might face questions like: "What AWS service should I use?" So, Let's dive into it.
RAG systems leverage services like Amazon Kendra, Amazon OpenSearch, and Amazon Bedrock Knowledge Bases to ingest and retrieve relevant information from a company's internal documents. This allows the LLMs to generate more accurate, knowledgeable, and contextually relevant outputs.
I have seen multiple cases where companies understand these concepts but they have some challenges choosing the right AWS service mentioned above. The idea of this blog is to go over each one these services and, share sample code on how to enable them within a RAG solution.
First, let’s understand how RAG works in a standard approach. The RAG architecture involves two key phases: Data Preprocessing and Runtime Execution.
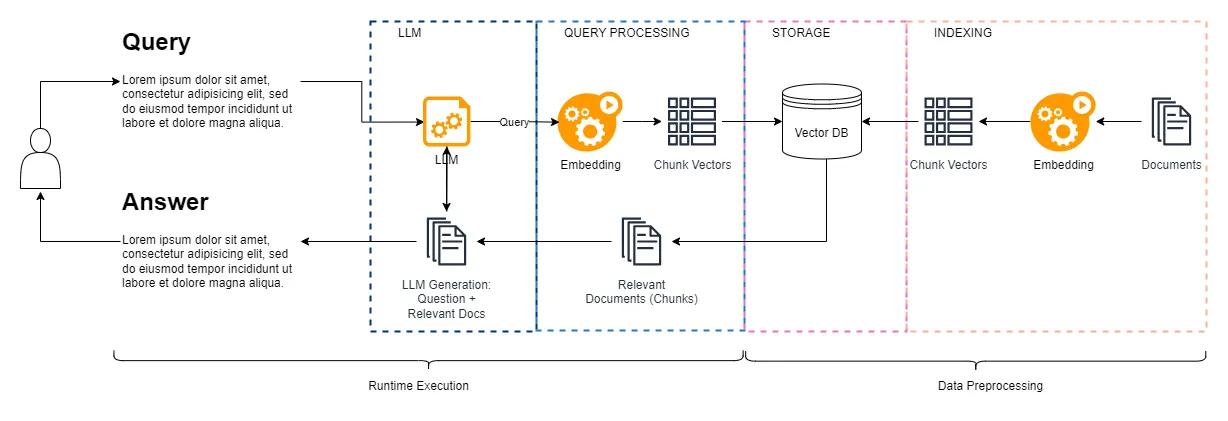
- The text embedding component is responsible for converting the input text (which could be a user query, document, or any other textual data) into a numerical vector representation. You need an Embedding LLM to perform this task.
- This vector preserves the semantic and linguistic relationships between the words or phrases -Chunk Vectors-. This allows the system to understand the meaning and context of the input, rather than just treating it as a sequence of characters.
- The vector database (vectorDB) component enables efficient retrieval and processing of relevant information. The vectorDB stores the vector representations (embeddings) of the text chunks or documents that were generated by the text embedding component.
- Query: The user's (human) input or query is passed into our GenAI system.
- The GEN AI system parses the information and send it over to the Embedding LLM to create the vector representation of our query.
- Relevant Documents (Chunks): Based on the user's query, the most relevant document chunks are identified by comparing the query vector to the vectors in the database. The vector-based matching ensures that the system can surface the most contextually relevant information.
- LLM Generation: Finally, the retrieved relevant chunks are then reassembled by the Large Language Model (LLM) to organize and summarize the necessary content. The results are presented to the user as the final output.
Now that we have a better understanding of the traditional components on a RAG architecture, let’s check each one of the possible designs with the AWS services mentioned previously, and analyze some bits of python code for each one of them. For this blog, I will be following the code posted in this Git repo
For all the cases we will explore, we need to make sure we are using the same libraries. I am using the following ones. You can find them in the requirement.txt from the git repo
Note that some of these libraries change constantly. If you decide to use these versions or newer ones is up to you, but make sure you define what versions to use. If you don't control them, or for example you use the latest ones every time you deploy your code, your application might fail due to new functionalities that can break your code, or maybe the functions you use were deprecated in the library version your are installing.
On the other hand, it is important to check what is included in the newer versions of these libraries and update your code accordingly. They always add new cool stuff or improve security controls. It is a delicate balance you just always keep an eye on.
Amazon OpenSearch is a fully managed service from AWS that allows you to easily deploy and scale OpenSearch clusters in the cloud. Additionally, Amazon OpenSearch Service now can serve as a vector store (VectorDB) for RAG based applications.
The following architecture represents how to use Amazon OpenSearch within a RAG solution. For this example, we will use the serverless version. This link will show you how to set up Amazon OpenSearch Serverless to work with vector search collections.
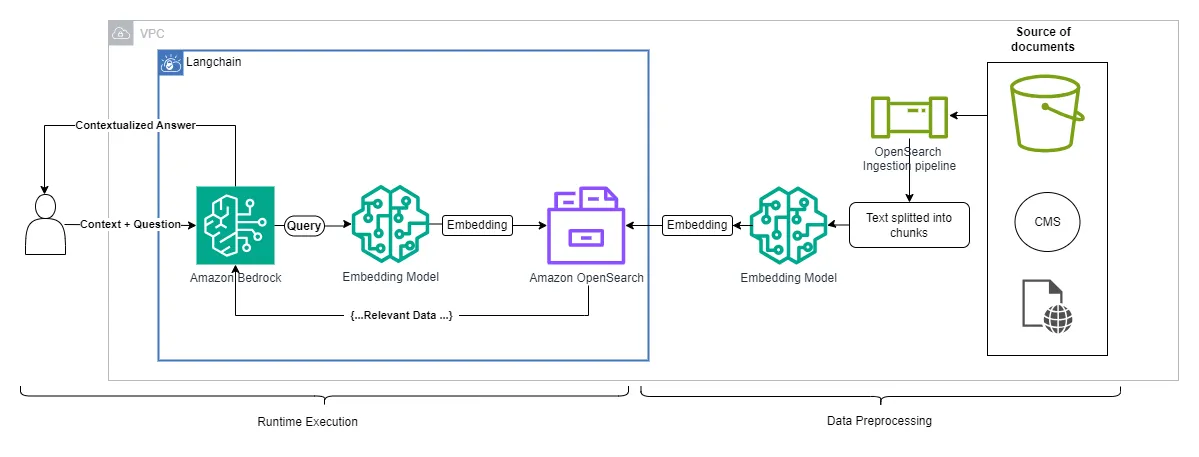
Once, you have Amazon OpenSearch enable for vector searches you are ready to enable Retrieval-Augmented Generation (RAG) in your application.
The code shared here can be found in the notebook called: 02_Rag_Processing_Bedrock from the git repo.
The data sources need to go through a processing pipeline. First, the data sources are chunked into smaller, more manageable pieces.
First, we need to import langchain and other libraries needed:
Then let’s load data, we are going to use an HTML file for this example. You might need to change your loader according to the data file you want to load.
Now the chunking. This is a step you might need to accommodate to your needs. The key is to preserve meaning for every chunk. In my case I define a chunk size of 1600 characters with an overlap of 200 characters. See here for more info RecursiveCharacterTextSplitter
These chunks are then transformed into vector embeddings using a foundation model, such as a large language model trained on a vast corpus of data.
Note: Keep in mind that the vectors must be in a supported numeric format like float32 and Metadata like IDs can be indexed along with the vectors.
Reference to Amazon OpenSearch Serverless service and endpoints. "AOSS" stands for Amazon OpenSearch Serverless, if you want to use a Amazon OpenSearch Managed service (not serverless), you would need to use "AOS".
I would be using the same AWS region for all the services tested in this blog
Let’s create AWS4Auth object to authenticate into Amazon OpenSearch
Setup the region where we have our Bedrock Models enable, the embedding we will use, and define the LLM that we will use for our application, in this case Claude 2. Feel free to add or modify the arguments of the model.
Now that we have all the parameters needed, we create a function that loads the document chunks into our OpenSearch index, during the process those chunks are vectorized. That’s why we need to provide the embedding LLM.
When a user interacts with the RAG-enabled application, their input is also transformed into a vector embedding using the same foundation model.
The embedding is used to query Amazon OpenSearch using vector similarity search. The database returns the most relevant document chunks based on the similarity between their embeddings and the user's input embedding.
The application can then leverage these retrieved document chunks, along with the user's input, to generate a more informed and factual response using a separate language model.
Let’s see how the code of the runtime execution would look like, let’s start with the imports needed.
Now, we setup the LLM to be use by our application
This content handler will help us to read the input as Json. As you see, I’m using SageMaker here.
No we define a chain for our application. See more of this in the langChain portal
Finally, you have everything ready for receiving a query from a user
After this, just print the results and you will get the response in the chain component.
Ok, that’s it. This is how you could enable Amazon OpenSearch as a VectorDB for your RAG application. You can think on using Amazon OpenSearch search if you:
- Need to have a detailed control on every element of the RAG architecture: chunking, embedding, indexing, ingestions, etc.
- Already have an Amazon OpenSearch index with your information.
- If you have specific requirement for the search function in the VectorDB.
- Have metadata associated with the index and you need to organize or filter your results based on it.
Amazon Bedrock provides a functionality to allow you to ingest your data into an embedded vector store that can then be queried to augment responses from large language models. These are called Knowledge Bases. Their key benefits are:
- They provide an out-of-the-box retrieval augmented generation (RAG) solution to quickly build natural language applications enriched with your custom data.
- Knowledge bases abstract away the complexity of building pipelines and managing the underlying datastore. Amazon Bedrock handles ingesting the data, embedding it, and making it available through APIs.
- Knowledge bases integrate seamlessly with other Amazon Bedrock services like models and agents. You can deploy an end-to-end natural language solution leveraging your knowledge base's data.
- Knowledge bases provide enterprise-grade security features like encryption and access controls to protect sensitive data.
The following figure represents the architecture of an Amazon Bedrock Knowledge Base. It's a bit simpler than the OpenSearch one because Bedrock is taking control of some of the steps on it. Let's see the details:
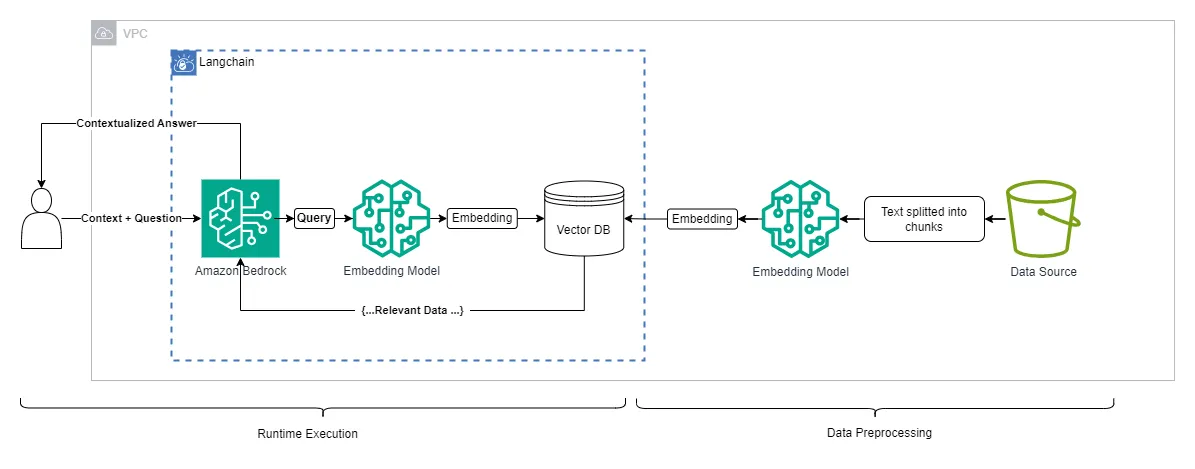
These steps can be found in the section called: Creating Knowledge Bases in Amazon Bedrock from this workshop or in the Amazon Bedrock documentation.
- Upload source document files to an Amazon S3 bucket. Supported formats include plain text, Markdown, HTML, Word docs, CSV, PDF, and Excel.
- (Optional) Set up a vector store like Amazon OpenSearch Serverless, Amazon Aurora, or others. This can be done through the Amazon Bedrock console.
- Create an IAM service role with permissions for Bedrock to access other AWS services. This can also be from Amazon Bedrock console.
- Create the knowledge base in the Bedrock console or using APIs, specifying the S3 bucket, chunking method, vector store, foundation -embedding- model, sync frequency, and IAM role.
- Bedrock preprocesses the query to understand the user request by embedding the request and create a vector from the customer’s question. You will see that the developer doesn’t have to embed the actual question. That process is performed by the Bedrock’s APIs.
- It queries the vector store to find text passages -chunks- semantically similar to the request.
NOTE: Using LangChain is optional when using Knowledge Bases. In the following example, we are not using it. Instead we use Bedrock’s APIs.
To test this out, you can use the Bedrock’s API called: retrieve, this API will give you all the relevant passages -chunks- from the Vector Store related to your question.
This code is shared from notebook called: "01-IntroBedrock_Kendra_AOSS-Rag" of the git repo we are following. You will find it in the last sections of the notebook.
This first step retrieves the chunks from the VectorDB and presents those fragments to the end user. We need to use the Knowledge Base Id to these API calls.
The previous code will give you the passages of chunks that match your criteria. There is no generation from Bedrock to consolidate this answer in your just one single answer.
That is when we need an API called Retrieve_and_Generate.
You will see that in this case the results in this case can include the references from which the answer was built upon.
In a development scenario, I would recommend using a bit of both APIs. The first one will tell you if you are collecting the right information from the VectorDB. The second one will show you how the LLM generates the actual answer from the passages collected.
As you saw, the usage of Amazon Bedrock Knowledge Bases is a bit simpler.
You can think on using Knowledge Bases under the following cases:
- You are starting with RAG solutions and want to build a quick scenario to test out a chat-bot using your own data.
- Your documents don’t require an advanced chunking strategy.
- You want to reduce maintenance and administrative tasks of your RAG solution.
- You want to explore different VectorDBs (Aurora DB, OpenSearch, Pinecone, etc) in a quick way.
- Don’t want or nor need to use LangChain.
- You need an end-to-end way to aggregate diverse data sources into a unified repository of information.
- You might be integrating it with Amazon Bedrock Agents to complete actions and full more complex requests. Although you can achieve the same with other options, this one is faster.
Amazon Kendra is an intelligent search service that uses natural language processing and machine learning to return specific answers to search queries rather than just lists of matching documents.
To use Kendra, you create an index and connect data sources -like Microsoft SharePoint, Google Drive, S3, Web Crawler and many others- to it. Kendra crawls and extracts text, metadata, and structure from documents in those sources.
You can enrich indexed content with custom metadata, user contexts, and advanced querying options like facet filtering. Kendra uses relevance tuning to optimize results. It provides a unified search experience across disparate siloed content with human-like responses to natural language queries.
You can see that Amazon Kendra is more than a VectorDB, but in this case, we will use it as such.
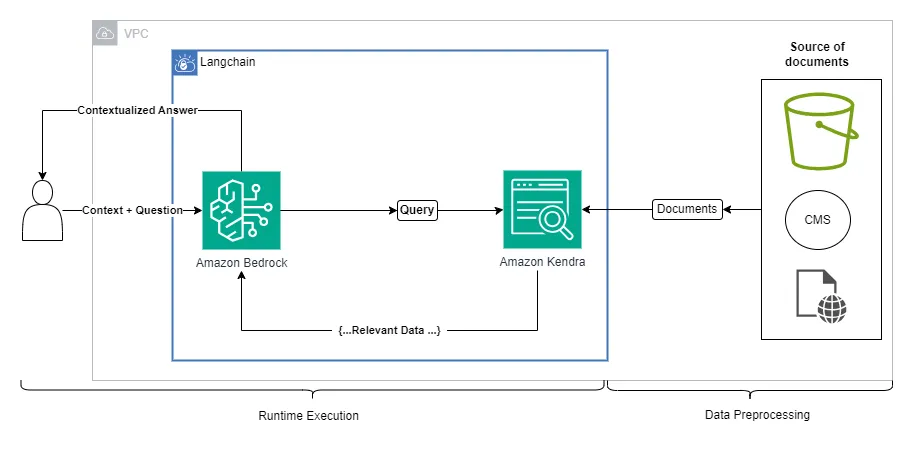
Let's use the sections from our Git Repo related to Amazon Kendra, you can find them in the notebook called: "01-IntroBedrockKendraAossRag"
Kendra can connect to multiple data sources and build a unified search index. This allows the RAG system to leverage a diverse corpus of documents for passage retrieval. You can use the Kendra console to connect to your sources of data and schedule the gathering of the data. Alternatively, you can use Kendra’s API to do so. See this documentation to get more information about this topic.
Amazon Kendra's Retrieve API can serve as the retriever component in a RAG system. It identifies and returns the most relevant passages from a corpus of documents based on a query.
Keep an eye on the prompt template. This is where you control what the LLM should say or not.
The passages returned by Kendra's Retrieve API can then be fed into a large language model (LLM) -using LangChain- to serve as the generator component in the RAG system.
You can play around the return_source_documents and verbose parameters to see what they do.
The LLM analyzes the passages from Kendra to understand the context and generates a useful response or answer for the original query.
In this case, I am building a quick chat-bot, you will see that the answers and prompt are printited in in different colors. I didn't include the coloring code here to keep it simple, but you can refer to the notebook to know how to added them.
Let’s check some characteristics of Amazon Kendra:
- Kendra uses natural language processing and machine learning to find semantically relevant content. This provides useful context to LangChain when generating responses.
- Kendra provides features like query suggestions, synonyms, and autocorrection to help expand and refine queries. This results in better passages retrieved to feed into the LLM.
- By combining Kendra's semantic retrieval with LangChain and a natural language generation (LLM), a powerful RAG system can be built to answer natural language questions on complex topics.
- When using Kendra, Users can connect to multiple sources of data and data Ingestion is orchestrated and scheduled by the service.
- Since Amazon Kendra owns the ingestion, users don’t need to use Embeddings to create the vector chunks.
- Users can adjust the capacity of processing required by understanding the number of documents that need to be ingested and readings needed.
- By using ACLs, you can control access to the documents, so you can be sure that even if you are using a chat bot, the documents accessed by it can be limited based on the human user asking questions.
Bedrock knowledge bases provide an out-of-the-box RAG solution by handling the underlying data processing like embeddings and vector indexes. This speeds up development time compared to building custom RAG pipelines.
On the other hand, AWS services like Kendra offers natural language search over documents. Kendra can automatically index sources like PDFs to handle document retrieval.
OpenSearch delivers a scalable full-text search. It enables fast keyword search over knowledge base content.
Bedrock knowledge bases simplify setup while Kendra and OpenSearch handle robust enterprise-scale search and retrieval over knowledge base data.
I hope this guide has provided you some guidelines when choosing your Vector Store when creating a AWS RAG-Based application for a GenAI project.
Finally, be mindful that this space is moving fast, especially within AWS. Every day there are more Vector stores available and changing approaches. For instance, another way to accomplish a RAG solution is using Amazon Q Business but that would be part of another blog.
Happy Coding!!
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.