LLM explainability
New research into understanding how transformers work
Randy D
Amazon Employee
Published May 7, 2024
In the realm of data science, model explainability is a moving target. While non-deep learning algorithms like XGBoost could literally draw a decision tree showing how a particular inference is reached, understanding how a neural network operates is quite complex.
Over the past few years, algorithms like SHAP have helped us understand how neural networks make predictions for tabular data, text, and even computer vision. (Or at least, SHAP helps understand which input features are driving model behavior.) SageMaker incorporates tools like SHAP as part of Clarify.
Foundation models represent another milestone for model explainability. This is an area of active research, and a recent paper has a good survey of the state-of-the-art. These includes algorithms to help understand which input words (tokens) are most responsible for model output, as well as tools that help understand the internal representations captured in a model.
I ran one of the tools, [inseq](), on a Jupyter notebook on a g5.16xlarge instance. I used it to look at input attribution for Google's Gemma-2b model.
That yields a heat map showing the interaction between input tokens and generated tokens.
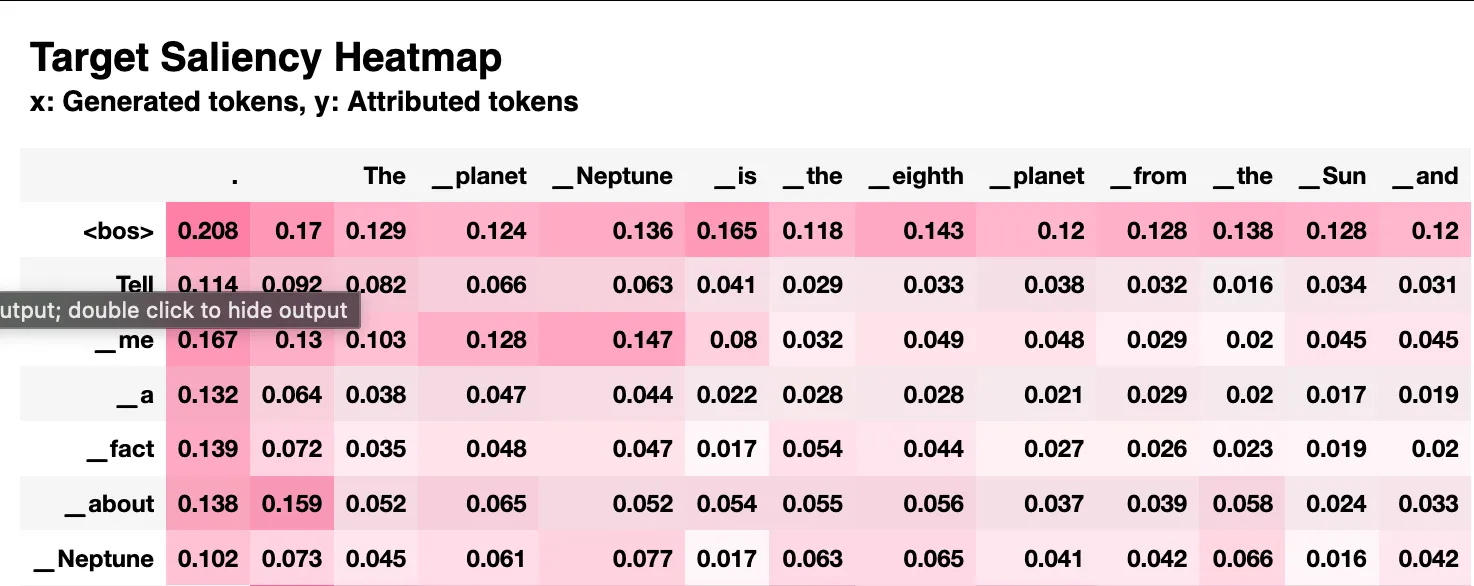
Keep in mind that most of these tools assume you have access to the model weights, so you can't use them for proprietary models.
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.