Relax and let the data flow: A Zero-ETL Pipeline
Real-time Data Visualization with OpenSearch and Amazon DynamoDB
Elizabeth Fuentes
Amazon Employee
Published May 24, 2024
Last Modified May 27, 2024
In the fast-paced world of data-driven decision making, real-time insights are crucial for staying ahead of the competition. Amazon OpenSearch Service and Amazon DynamoDB offer a powerful combination that enables organizations to visualize and analyze data in near real-time, without the need for complex Extract, Transform, Load (ETL) processes. This blog post introduces an AWS Cloud Development Kit (CDK) stack that deploys a serverless architecture for efficient, real-time data ingestion using the OpenSearch Ingestion service (OSIS).
By leveraging OSIS, you can process and transform data from DynamoDB streams directly into OpenSearch, enabling near-instant visualization and analysis. This zero-ETL pipeline eliminates the overhead of traditional data transformation workflows, allowing you to focus on deriving insights from your data.
The CDK stack provisions key components such as Amazon Cognito for authentication, IAM roles for secure access, an OpenSearch domain for indexing and visualization, an S3 bucket for data backups, and a DynamoDB table as the data source. OpenSearch Ingestion acts as the central component, efficiently processing data based on a declarative YAML configuration.

The flow starts with data stored in Amazon DynamoDB, a managed and scalable NoSQL database. Then, the data is transmitted to Amazon S3.
From the data in S3, it is indexed using Amazon OpenSearch, a service that enables real-time search and analysis on large volumes of data. OpenSearch indexes the data and makes it easily accessible for fast queries.
The next component is Amazon Cognito, a service that enables user identity and access management. Cognito authenticates and authorizes users to access the OpenSearch Dashboard.
AWS Identity and Access Management Roles is used to define roles and access permissions.
To create an OpenSearch Ingestion pipeline, you need an IAM role that the pipeline will assume to write data to the sink (an OpenSearch Service domain or OpenSearch Serverless collection). The role's ARN must be included in the pipeline configuration. The sink, which can be an OpenSearch Service domain (running OpenSearch 1.0+ or Elasticsearch 7.4+) or an OpenSearch Serverless collection, must have an access policy granting the necessary permissions to the IAM pipeline role. (Granting Amazon OpenSearch Ingestion pipelines access to domains - Granting Amazon OpenSearch Ingestion pipelines access to collections).
OpenSearch Ingestion requires specific IAM permissions to create pipelines, including
osis:CreatePipeline to create a pipeline, osis:ValidatePipeline to validate the pipeline configuration, and iam:PassRole to pass the pipeline role to OpenSearch Ingestion, allowing it to write data to the domain. The iam:PassRole permission must be granted on the pipeline role resource (specified as sts_role_arn in the pipeline configuration) or set to * if different roles will be used for each pipeline.The main link of this pipeline configuration is a YAML file format that connects the DynamoDB table with OpenSearch:
The pipeline configuration is done through a YAML file format like:
The pipeline configuration file is automatically created in the CDK stack along with all the other resources.
✅ Clone the repo
git clone https://github.com/build-on-aws/realtime-dynamodb-zero-etl-opensearch-visualization
✅ Go to:
cd dashboard
- Configure the AWS Command Line Interface
- Deploy architecture with CDK Follow steps:
✅ Create The Virtual Environment: by following the steps in the README
python3 -m venv .venv
source .venv/bin/activate
source .venv/bin/activate
for windows:
.venv\Scripts\activate.bat
✅ Install The Requirements:
pip install -r requirements.txt
✅ Synthesize The Cloudformation Template With The Following Command:
cdk synth
✅🚀 The Deployment:
cdk deploy
The deployment will take between 5 and 10 minutes, which is how long it takes for the OpenSearch domain to be created.
When it is ready you will see that the status changes to completed:
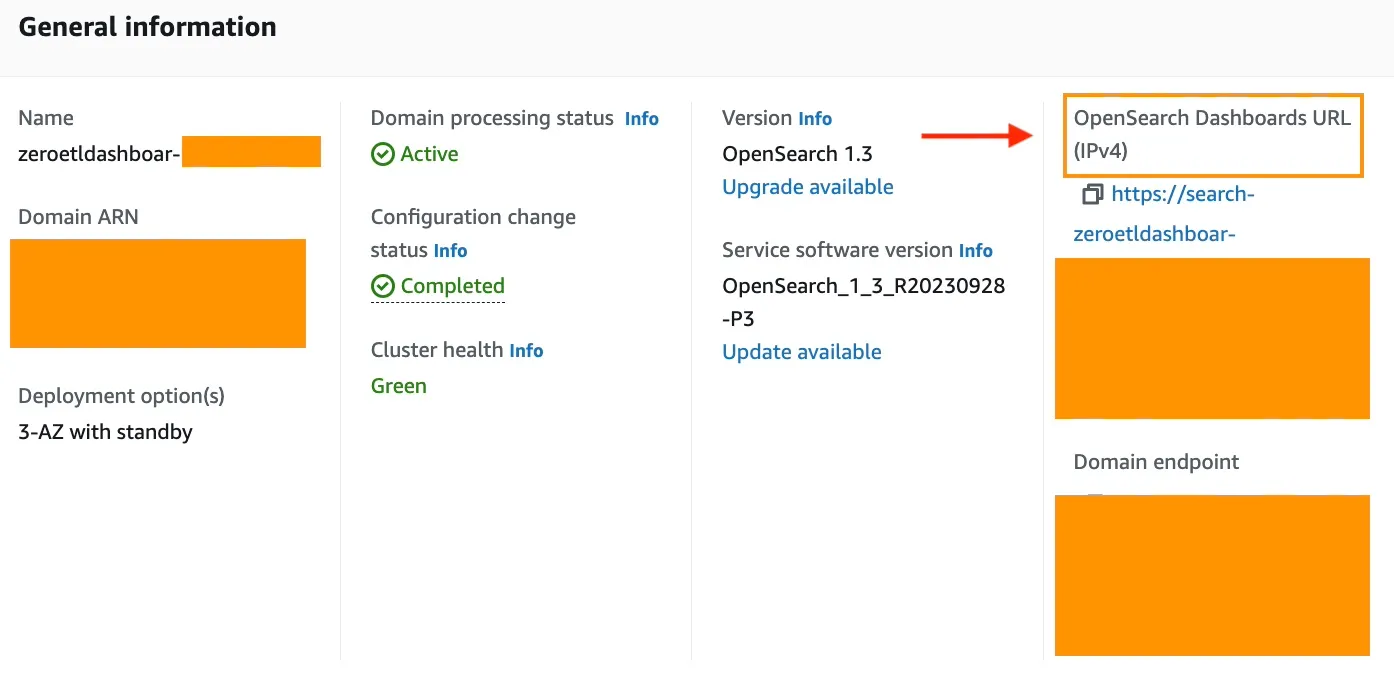
To access the OpenSearch Dashboards through the OpenSearch Dashboards URL (IPv4) you need to create a user in the Amazon Cognito user pools.
With the created user, access the Dashboard and begin to experience the magic of Zero-ETL between the DynamoDB table and OpenSearch.
In this repository you created a table to which you can inject data, but you can also change it by Updating Amazon OpenSearch Ingestion pipelines making a change to the YAML file or modifying the CDK stack.
The combination of Amazon OpenSearch and Amazon DynamoDB enables real-time data visualization without the complexities of traditional ETL processes. By utilizing the OpenSearch Ingest Service (OSIS), a serverless architecture can be implemented that efficiently processes and transforms data from DynamoDB directly into OpenSearch. Building the application with AWS CDK streamlines and simplifies the setup of key components such as authentication, secure access, indexing, visualization, and data backup.
This solution allows users to focus on gaining insights from their data rather than managing infrastructure. Ideal for real-time dashboards, log analytics, or IoT event monitoring, this Zero-ETL pipeline offers a scalable and agile approach to data ingestion and visualization. It is recommended to clone the repository, customize the configuration, and deploy the stack on AWS to leverage the power of OpenSearch and DynamoDB for real-time data visualization.
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.