Unleash the possibilities of Stable Diffusion
Practices for Large-Scale Deployment with Kubernetes
BettyZheng
Amazon Employee
Published May 11, 2024
Last Modified May 13, 2024
Today, Stable Diffusion is one of the popular and influential open source image generation models followed by developers. Released in August 2022, Stable Diffusion is a latent text-to-image diffusion model that generates photo-realistic images. The model is rapidly strengthening, and its open source ecosystem is growing, that bring significant productivity improve in the multiple industries. A variety of user-friendly, open source development tools continue to emerge, making Stable Diffusion easily accessible to designers and hobbyists.
- Extensibility: The Stable Diffusion ecosystem is vast and ever-evolving. The foundation model has three major versions (1.5, XL, and 2), with numerous plugins and supplementary models (e.g., LoRa, ControlNet) that can be seamlessly integrated. Additionally,enthusiasts fine-tuned the foundation model for specific use cases, such as portrait generation and anime drawing. For large-scale deployments, different models need to be deployed for various scenarios. However, keeping these components up-to-date without breaking compatibility is a challenging task, as they are continuously updated.
- Inference Speed: The Stable Diffusion foundation model is computationally intensive, trained using 256 NVIDIA A100 GPUs on AWS, consuming 150K GPU/hours and costing $600K. While such computing power isn't required for image generation. accelerated computing chips (e.g., NVIDIA GPUs or AWS Inferentia) are still necessary to improve single-task inference speed, reduce user wait times, and enhance the overall developer experience.
- Intelligent Scaling: In certain business scenarios, requests can be unpredictable yet time-sensitive. In such cases, quickly scaling up inference instances to handle surges crucial, but leaving too many instances running idle wastes resources and money. Intelligent scaling is needed to maintain a cost-effective balance, rapidly provisioning instances during peaks and scaling down during idle.
Initial ideas for designing a large-scale deployment of Stable Diffusion are shown in the figure below:
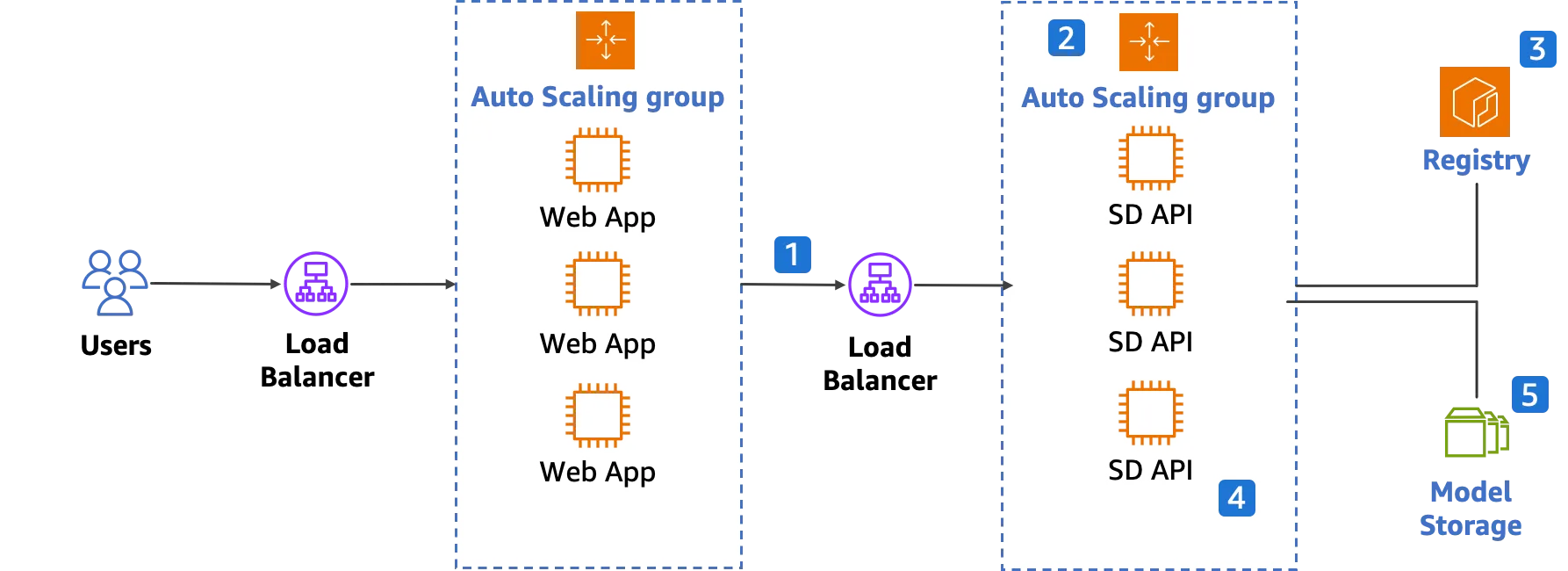
This popular 2-layer architecture shows a straightforward approach for deploying a Stable Diffusion inference cluster. However, it comes with limitations and risks:
- Synchronous Requests
- All requests are synchronization, and since each request takes seconds or even minutes, synchronized requests typically require a stable network connection between the client and the backend. Any network spikes will interrupt the connection, necessitating the implementation of retries to prevent lost requests.
- Scaling Mechanism Latency
- A typical scaling mechanism is target tracking based on CPU or GPU utilization. However, target tracking is slow to respond to surges. While over-provision of resources ahead of time is an option, it will lead to large idle resources and additional costs.
- Prolonged Cold Start
- The cold start stage is excessively long. When launching a new instance, it needs to load the Stable Diffusion runtime and model. The Stable Diffusion runtime contains many dependencies, such as Torch and CUDA drivers. With these dependencies, the size of the Stable Diffusion runtime is generally more than 10 GB. Pulling and extracting can take over 10 minutes. This extends the waiting period before the new instance. Getting ready not only tests patience but also incurs additional costs.
- Storage Bottleneck
- Stable Diffusion models will be loaded from disk to vRAM. The throughput bottleneck is the disk, as neither regular block storage nor file storage can provide sufficient performance for model loading. In most scenarios, model loading only runs once at the initialization of a runtime. Consequently, the high-performance storage purchased becomes redundant after the model is loaded, and costs continue to accrue.
To address these limitations is crucial for developers aiming to deploy Stable Diffusion inference clusters efficiently and cost-effective.
From all of above, the exist popular architecture falls short for large-scale deployment. However, by leveraging the power of cloud computing and Kubernetes, an interesting solution from China SSA team that address these challenges now.
The specific work flow like following figure:
The specific work flow like following figure:
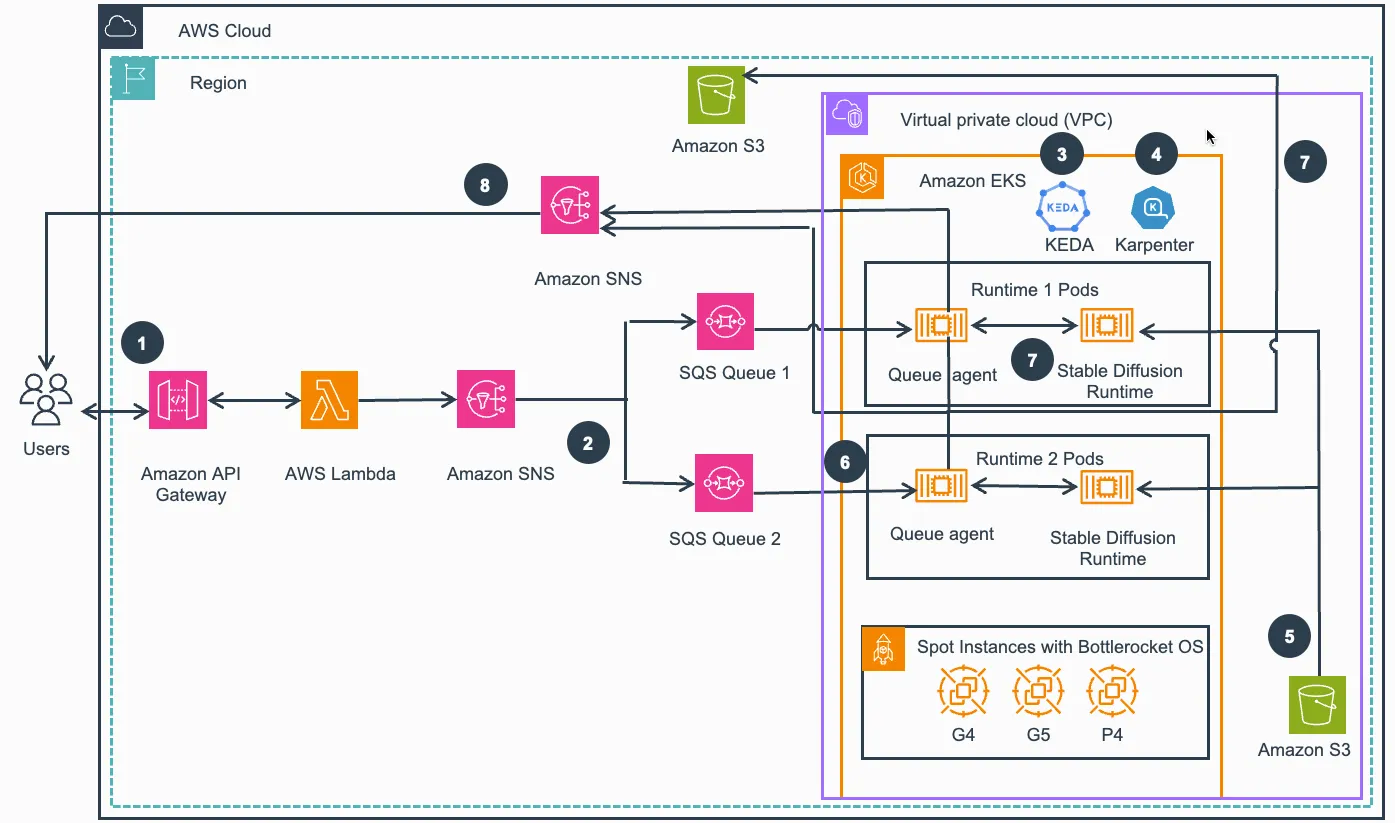
- The process begins when a user or an application sends a prompt to Amazon API Gateway, acting as an endpoint for the overall solution, including authentication. AWS Lambda function then validates the incoming requests and publishes them to the designated Amazon Simple Notification Service (Amazon SNS) topic. Notably, the lambda function immediately returns a response.
- Amazon SNS forwards the message to the corresponding Amazon Simple Queue Service (Amazon SQS) queues. Each message contains a Stable Diffusion (SD) runtime name attribute, ensuring deliver to the appropriate queues matching the specified SD runtime.
- Within Amazon Elastic Kubernetes Service(Amazon EKS) cluster, the pre-deployed open source Kubernetes Event Driven Auto-Scaler (KEDA) scales up new pods to process the incoming messages from SQS model processing queues.
- Also in the Amazon EKS cluster, the pre-deployed open source node auto-scaler, Karpenter, launches new compute nodes based on GPU Amazon Elastic Compute Cloud (Amazon EC2) instances (e.g., g4, g5, and p4) to schedule pending pods. These instances utilize pre-cached SD Runtime images and are based on Bottlerocket OS for fast boot time. Instances can be launched with on-demand or spot pricing model.
- Stable Diffusion Runtimes load model files from Amazon Simple Storage Service (Amazon S3) via Mountpoint for Amazon S3 CSI Driver during runtime initialization or on-demand.
- Queue agents (software component created for this solution) receive messages from SQS model processing queues and convert them into inputs for SD Runtime API calls.
- Queue agents invoke SD Runtime APIs, receive and decode responses, and save the generated images to designated Amazon S3 buckets.
- Queue agents send notifications to the designated SNS topic from the pods, users receive these notifications from SNS and can access the generated images in S3 buckets.
I’m glad you can find this AWS solution leveraging the power of cloud, serverless, and full-managed Kubernetes to be an effective approach for building a scalable, cost-effective, and asynchronous image generation architecture using Stable Diffusion.
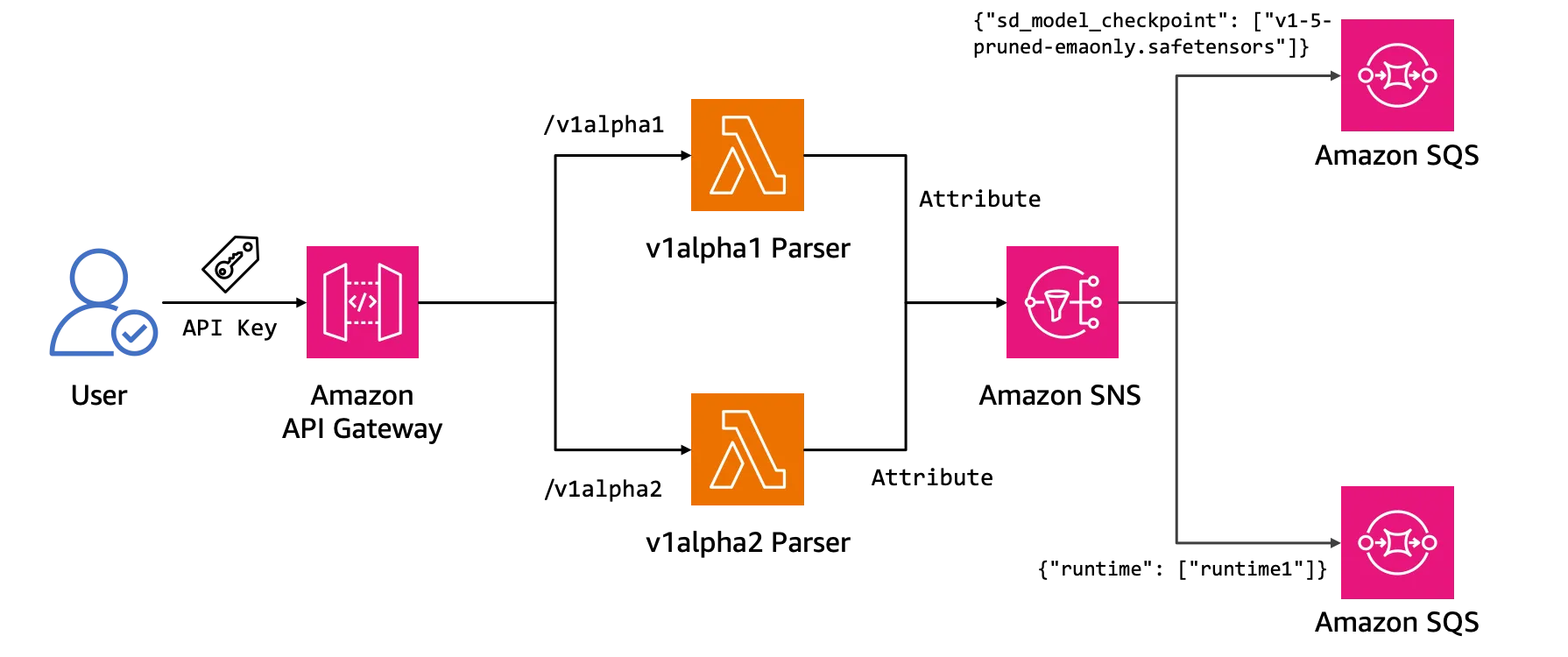
While GUI is more friend for individual user and designers, API remains the primary method for application-to-application interaction. This AWS solution leverages an API endpoint based on Amazon API Gateway to provide Stable Diffusion services.
Users or applications send requests (models, prompts, etc.) to the API endpoint. Amazon API Gateway validates these requests through an AWS Lambda function, which then publishes them on Amazon SNS topic. This decouples the request submission from the subsequent processing pipeline, enabling asynchronous handling of potentially long-running tasks.
Amazon SNS and Amazon SQS handle task distribution process. SNS routes each request to the appropriate runtime’s SQS queue based on the runtime name specified in the request. Since different runtimes may be required for various models or configurations, multiple runtimes are set up, and SNS intelligently directs each request to the right processing queue.
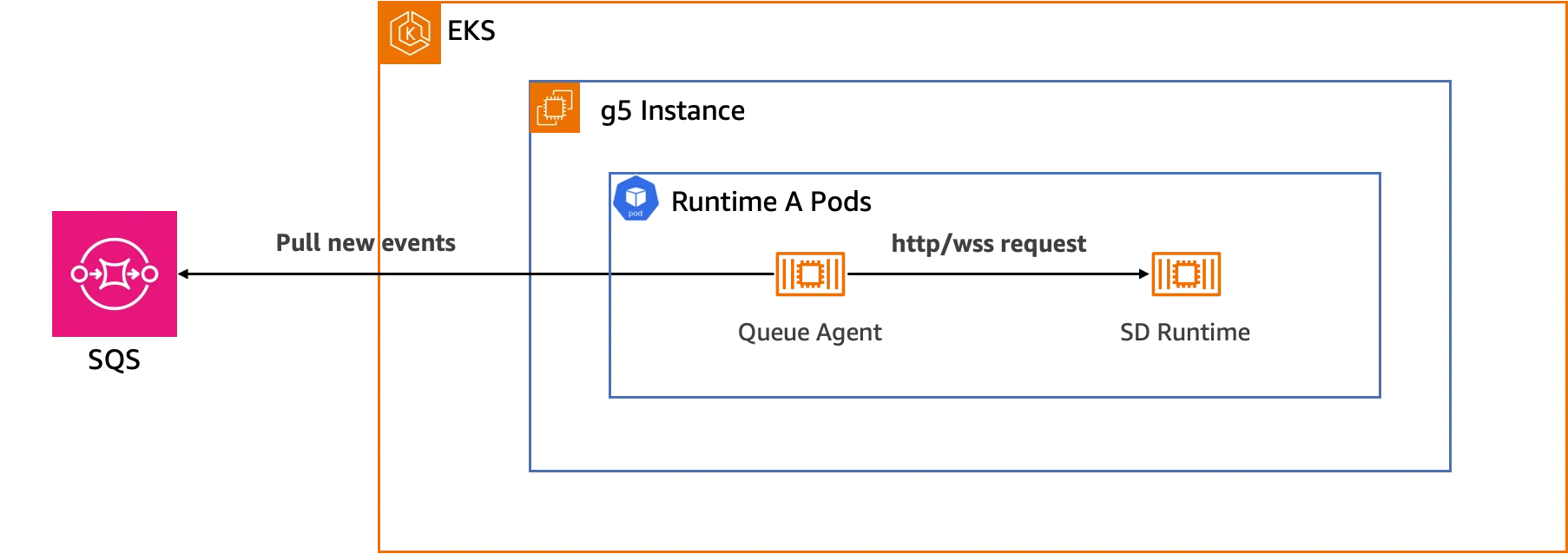
While each runtime has its dedicated Amazon SQS queue to receive requests, Stable Diffusion runtimes can differ in their API interfaces, behaviors, and support for asynchronous processing and queues. To address this heterogeneity, the Queue Agent component acts as a sidecar, deployed alongside each SD runtime.
The Queue Agent retrieves tasks from the Amazon SQS queue and seamlessly converts them into the appropriate API request format for the corresponding runtime. This abstraction layer decouples the processing pipeline from the specifics of each runtime, enabling support for a diverse range of Stable Diffusion models and configurations.
Additionally, the Queue Agent handles ancillary tasks, such as retrieving images from the internet or Amazon S3, task tracking, and error handling. By offloading these responsibilities from the Stable Diffusion runtime itself, the Queue Agent facilitates a more modular and extensible architecture, allowing for the seamless integration of new runtimes without disrupting existing components. This separation of concerns not only improves maintainability but also enhances the overall system's scalability and resilience.
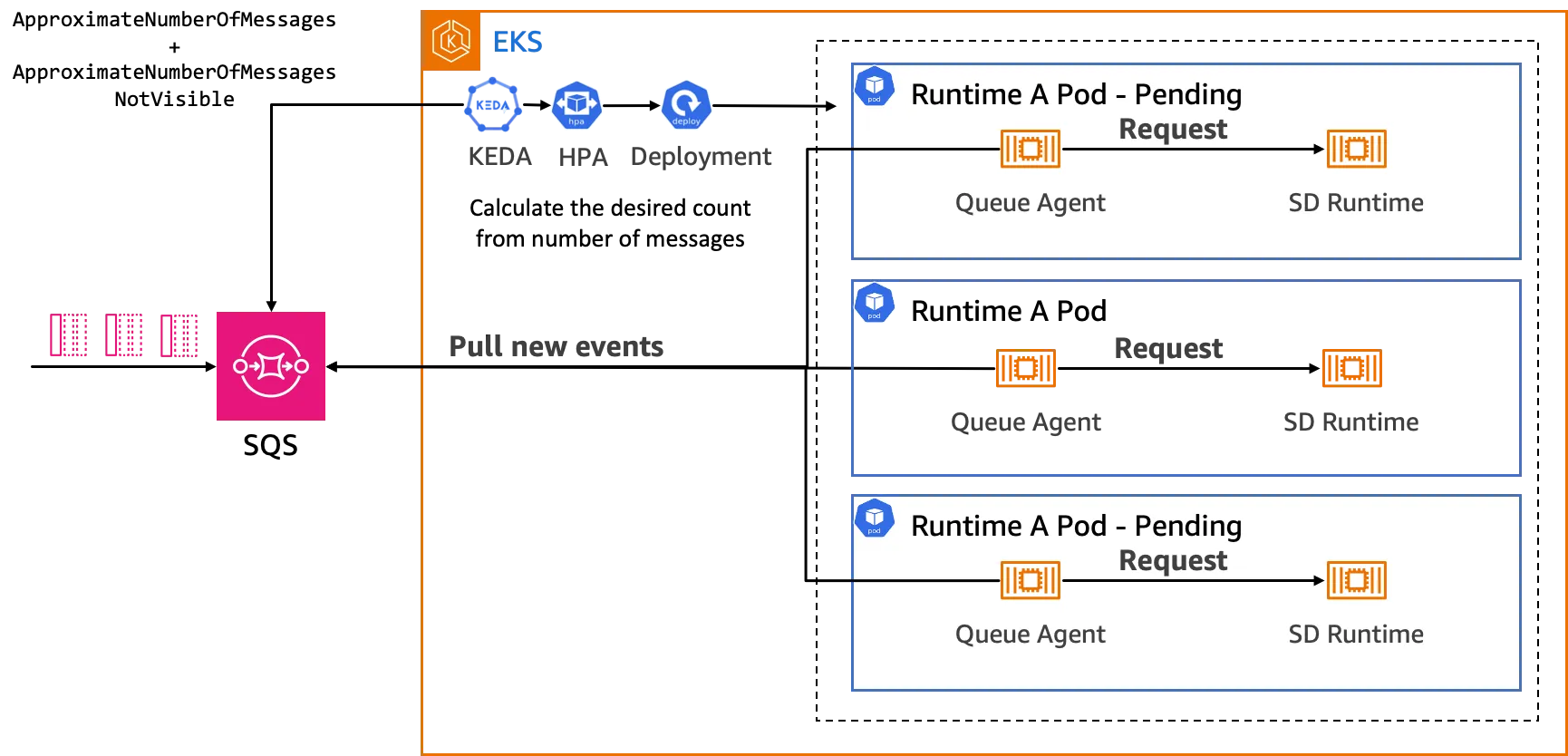
As messages accumulate in the Amazon SQS queue, the need to quickly process the backlogged tasks necessitates an increase in the number of container replicas. This is where the open source Kubernetes Event-Driven Auto-scaling (KEDA) comes into play.
KEDA continuously monitors the length of the SQS queue and determines the appropriate number of runtime replicas to be provisioned based on the message count. This event-driven scaling ensures that sufficient resources are available to handle incoming workloads, maintaining responsiveness and preventing excessive queuing.
Moreover, KEDA can scale runtimes down to zero replicas when there is no load, effectively optimizing resource utilization and cost savings. Runtime instances are only started when there are tasks to be processed, eliminating the need for idle resources during periods of low demand.
Beyond SQS queue length, KEDA supports scaling based on many metrics, called Scalers. For example, in business situations with expected busy times, a Cron Scaler can be used to scale up instances during the estimated peak times and release resources during slow periods. By combining multiple Scalers, this solution can handle different scenarios, ensuring efficient resource use and cost savings.
Adding KEDA to this AWS solution allows dynamic and responsive scaling. It also improves cost by making sure resources are only used when needed. This reduces waste and makes the most of the operating budget.
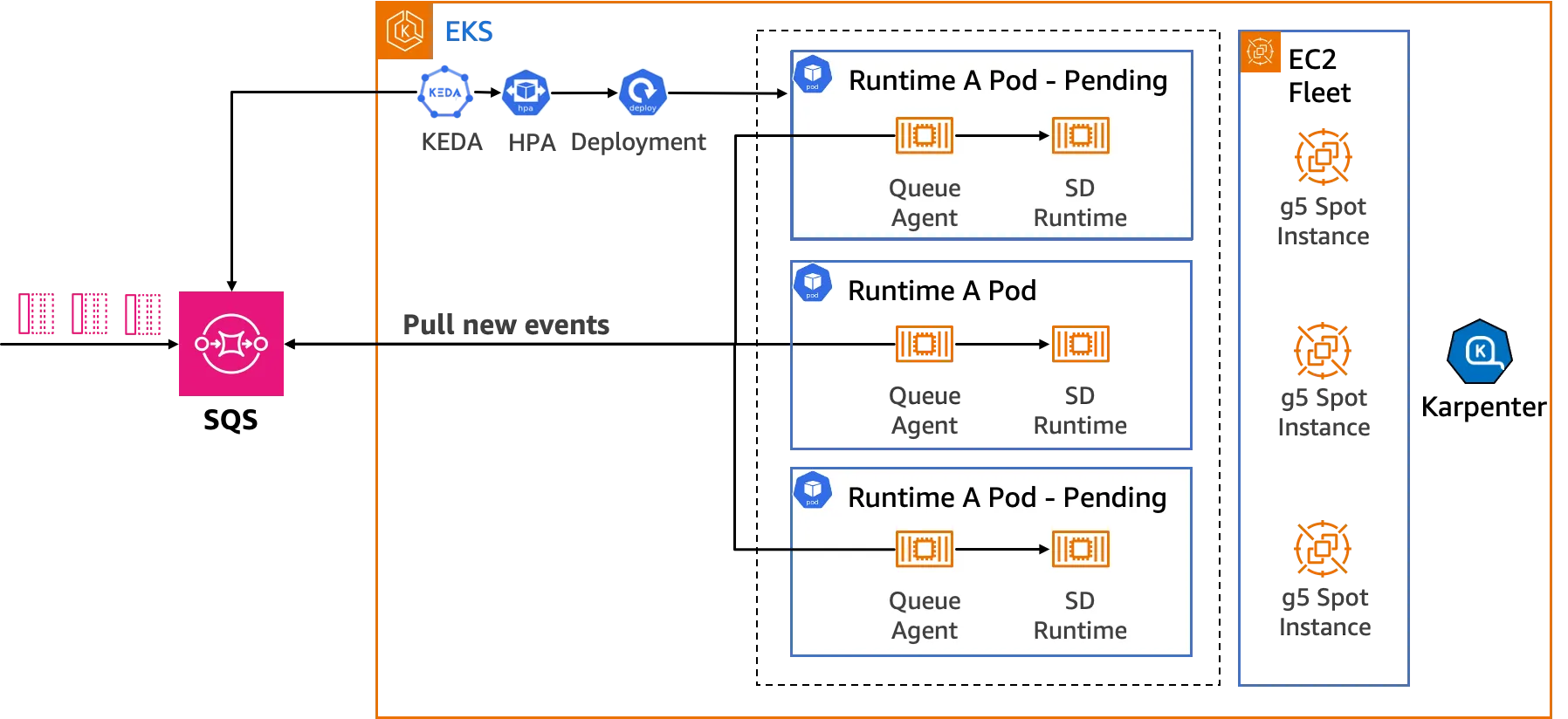
As the number of runtime replicas grows to handle increasing workload demands, a node scaling component is needed to create instances to host the new runtimes. This is where Karpenter, Amazon's open source elastic scaling component, comes in. It intelligently selects instance types and purchase methods.
Karpenter chooses the best instance type based on the number of pods launched at the same time. For example, when many pods are launched simultaneously, it can select instances with 2 or 4 GPUs to reduce the impact of instance startup time on cold start times. This ensures optimal performance and responsiveness.
Using EC2 Fleet, Karpenter starts instances faster than traditional node groups based on Auto Scaling Groups. This enhances the solution's ability to quickly provide resources when demand spikes.
Karpenter also helps reduce costs by launching Amazon EC2 Spot Instances, which offer spare EC2 capacity at up to 90% off On-Demand prices. However, AWS can interrupt Spot Instances with a 2-minute notification. To minimize the impact of such interruptions, Karpenter intelligently selects the instance types least likely to be interrupted, ensuring minimal disruption to ongoing tasks.
By integrating Karpenter into this AWS solution, developers benefit from intelligent instance selection, faster provisioning, and cost optimization through the strategic use of Spot Instances. All while maintaining high availability and fault tolerance for Stable Diffusion workloads.
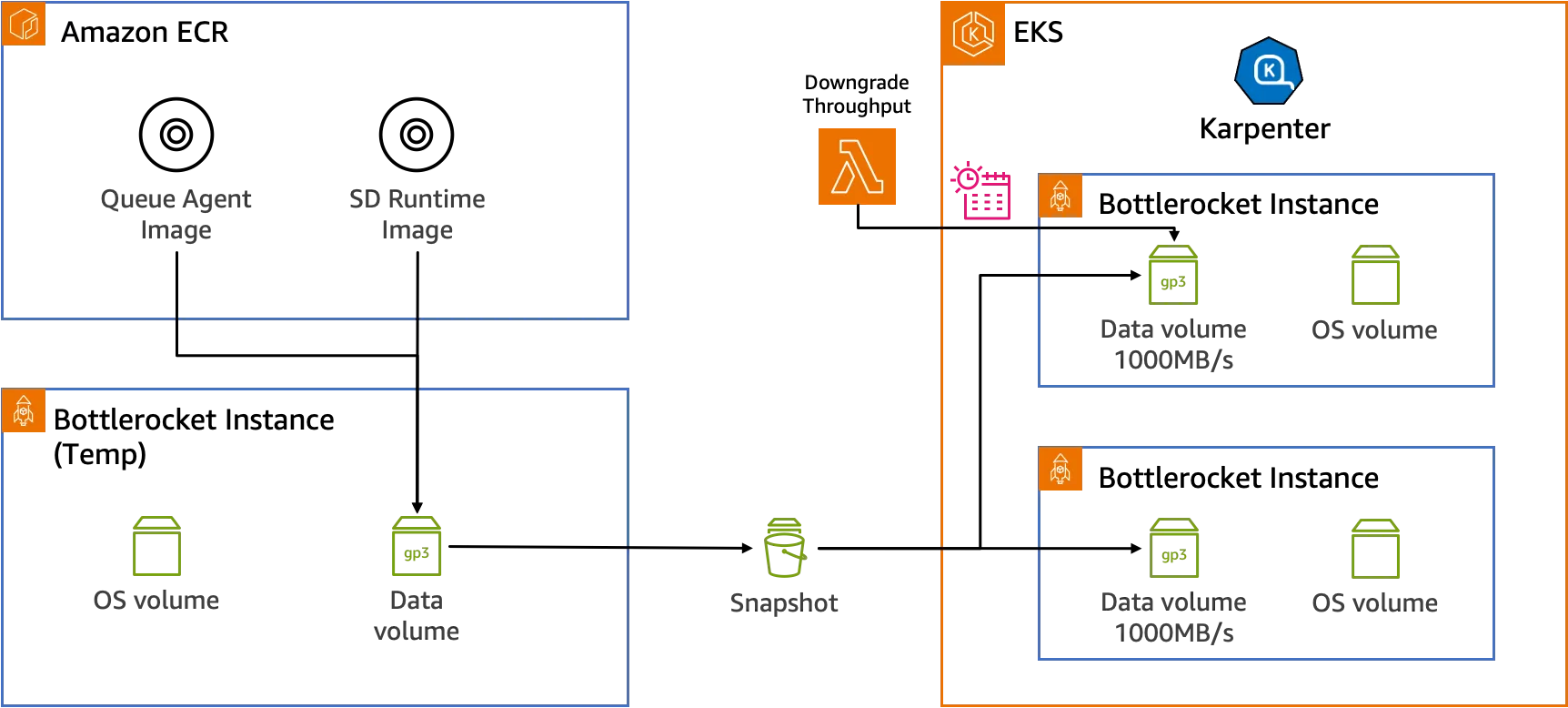
On the storage side, the solution uses different storage for Stable Diffusion runtimes and models. Newly created instances use the Bottlerocket operating system, an open source Linux-based OS built by Amazon specifically for running containers. Bottlerocket only includes the fundamental software needed to run containers, resulting in fast boot times.
For Stable Diffusion runtime images, since Docker pulls images in a single thread and requires decompression after pulling, image pulling takes a long time. The Stable Diffusion runtime images are preloaded onto the disk, and EBS snapshots are captured. When a new instance is created, the EBS snapshot is restored to the new instance's data disk, allowing the new instance to immediately start containers after joining the EKS cluster, saving time for pulling and decompressing images.
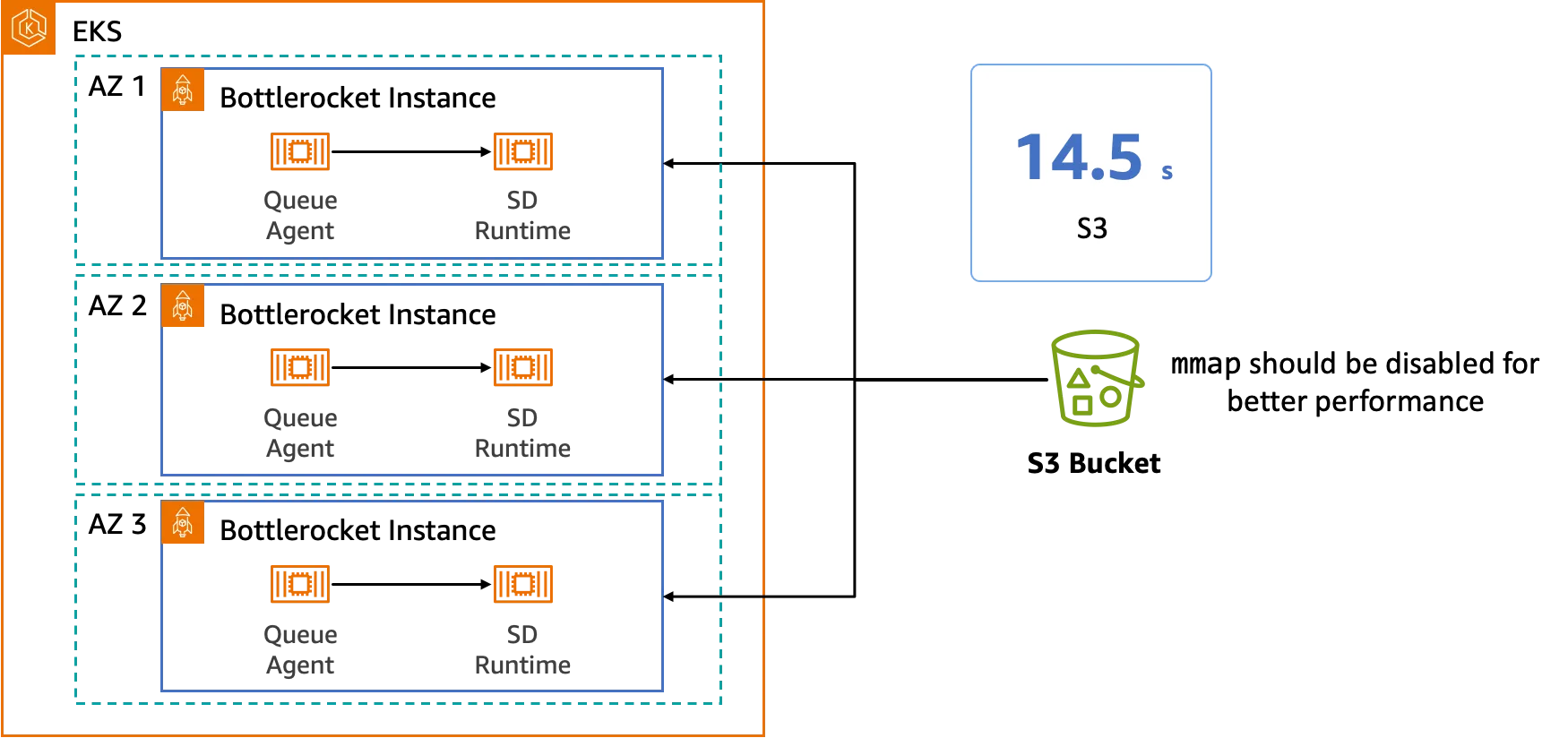
Mounting object storage has advantages for workloads, like model reading that involves continuous reads. Mount point for Amazon S3 can mount an S3 bucket to the file system, supporting multi-threaded reading when loading models, fully utilizing network resources. Performance tests on Amazon S3 show that using Mount point for Amazon S3 to load the base model of Stable Diffusion 1.5 only takes 14.5 seconds, further reducing cold start time.
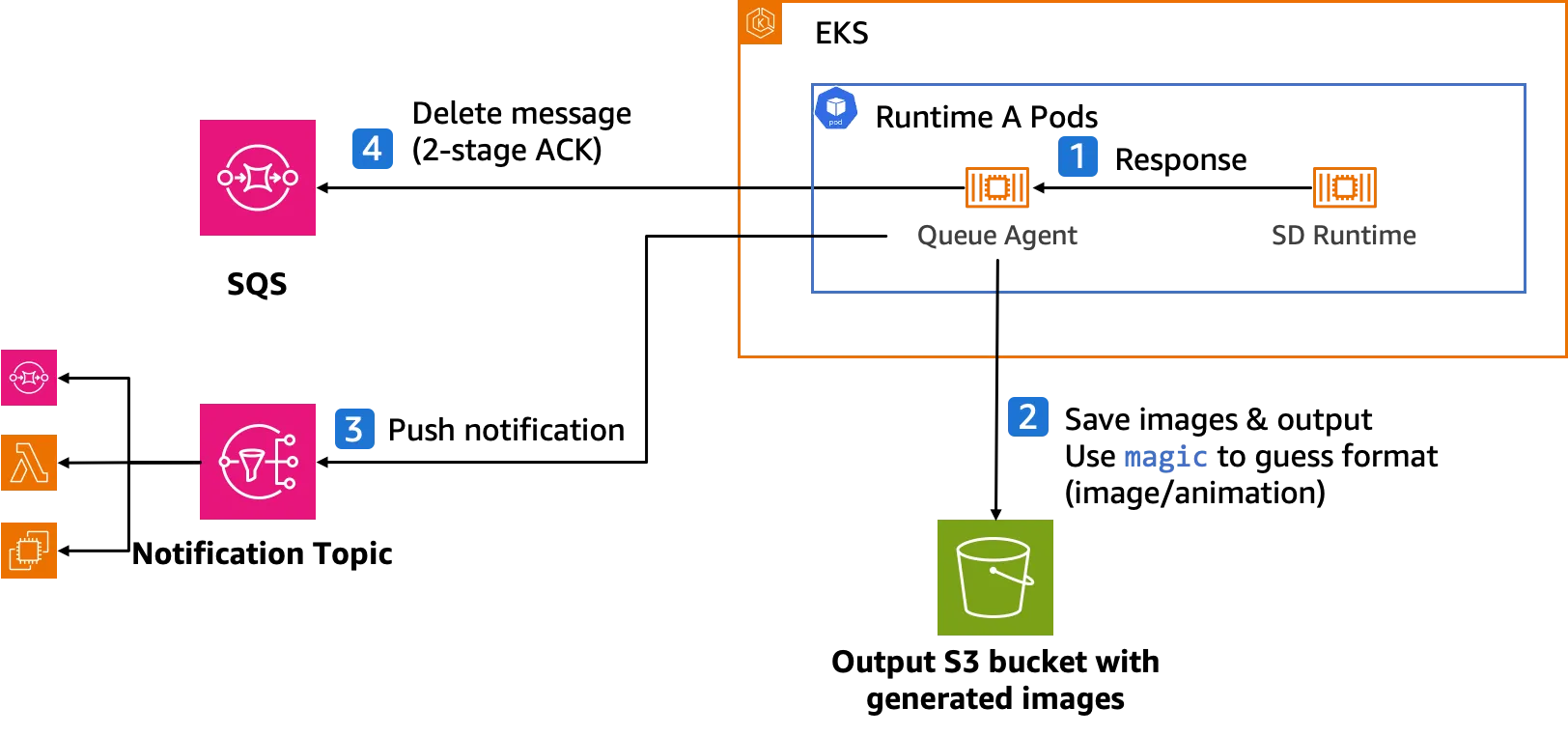
The generated images are stored by the Queue Agent in an Amazon S3 bucket, and a completion notification is sent to an Amazon SNS topic. Regardless of whether the task succeeds or fails, the runtime's return is also stored in the S3 bucket for debugging purposes. Queue Agent only deletes the corresponding task from the queue after the task is completed. When unexpected situations occur (such as SD runtime crashes), the task will reappear in the queue after a set period (known as Visibility Timeout), allowing other runtimes to retry the task. This "two-stage acknowledge" feature of Amazon SQS effectively improves the overall reliability of the solution.
In terms of observability, in addition to traditional CloudWatch metric monitoring and logs, distributed tracing allows us to understand the time consumption and performance bottlenecks of each step, making it easy for operations and maintenance personnel to quickly troubleshoot problems.
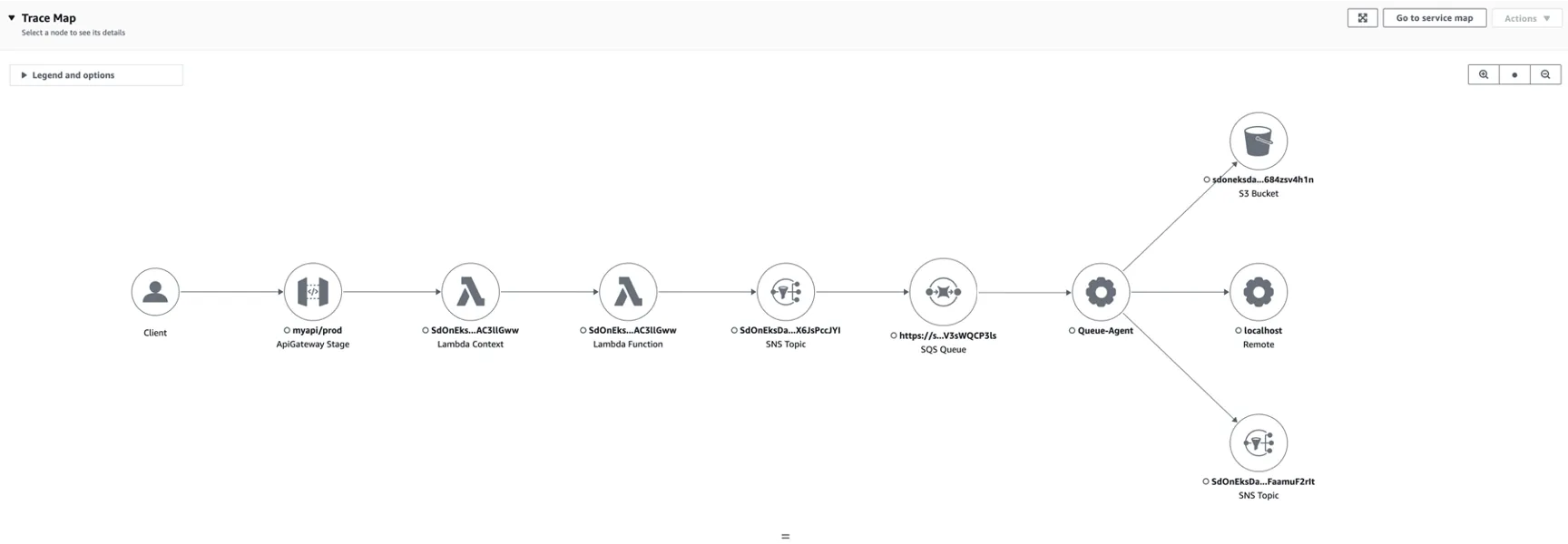
- Embracing the Open Source Ecosystem: This solution supports two popular open source Stable Diffusion runtimes: Stable Diffusion Web UI and ComfyUI. It also seamlessly integrates with the plugin ecosystems built around these runtimes, grants me a wealth of options to explore and customize.
- Rapid Scaling Made Easy: With the power of KEDA, Karpenter, and Bottlerocket, the solution can archive fast and fully automatic scaling capabilities. In the fastest scenarios, the new instance can be up and running within just one minute. This is perfect for handling high concurrency and situations where response time is critical.
- Significant Cost Savings: By leveraging Amazon EC2 Spot Instances and the Mountpoint for Amazon S3 CSI Driver, approximately 70% on computing costs can be saved compared to EC2 on-demand pricing. In multi-node scenarios, the storage costs can be reduced to 10% compared to other storage solutions. It's a fantastic way to optimize the budget without compromising performance.
- Effortless Extensibility: This solution is a cloud-native architecture built on Amazon EKS, serverless, and event-driven principles. Most components are managed service and loose coupled, making it incredibly convenient to extend and customize the system to specific needs.
- Visual Monitoring: The solution provides comprehensive observability components. Operators can have access to detailed visualizations of the invocation process, along with historical statistics. This means we can quickly pinpoint and resolve any problems that may arise, keeping the system running smoothly.
- Automated Deployment in Minutes: By utilizing Amazon CDK, the entire build process is automated. With just 30-40 minutes, we can have the system up and running, thanks to the expressive capabilities and efficient execution of the deployment scripts. It's a game-changer in terms of saving time and effort.
By adopting this solution, we can overcome the challenges associated with traditional deployment methods and build a cost-effective, scalable, and easily manageable asynchronous image generation architecture.
This solution has already been deployed in production environments for multiple Amazon Web Services users. We did internal testing in the Amazon Web Services US West (Oregon) region. The end-to-end scaling speed (from request sent to processing completed) can be as low as 60 seconds, which is perfect for scenarios that need fast scaling.
Currently, this solution can be deployed to all AWS commercial regions (incl. China regions). You can get the solution at https://aws.amazon.com/solutions/guidance/asynchronous-image-generation-with-stable-diffusion-on-aws and begin deploying on your AWS account.
Appreciated the solution provider Bingjiao Yu. He is a Specialist Solutions Architect for App Modernization at Amazon Web Services China. He provides expert guidance to customers on containers and serverless technologies.
Happy Building!
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.