Add flexibility to your RAG applications in Amazon Bedrock
Use the right configuration options for your Knowledge Base
Abhishek Gupta
Amazon Employee
Published Jun 4, 2024
Knowledge Bases for Amazon Bedrock is a fully managed capability that helps you implement the entire RAG workflow from ingestion to retrieval and prompt augmentation without having to build custom integrations to data sources and manage data flows.
There are several configurations you can tweak to customize retrieval and response generation. This can be done via query configuration parameters which can be applied via the console, API or the SDK.
Let's walk through them one by one.
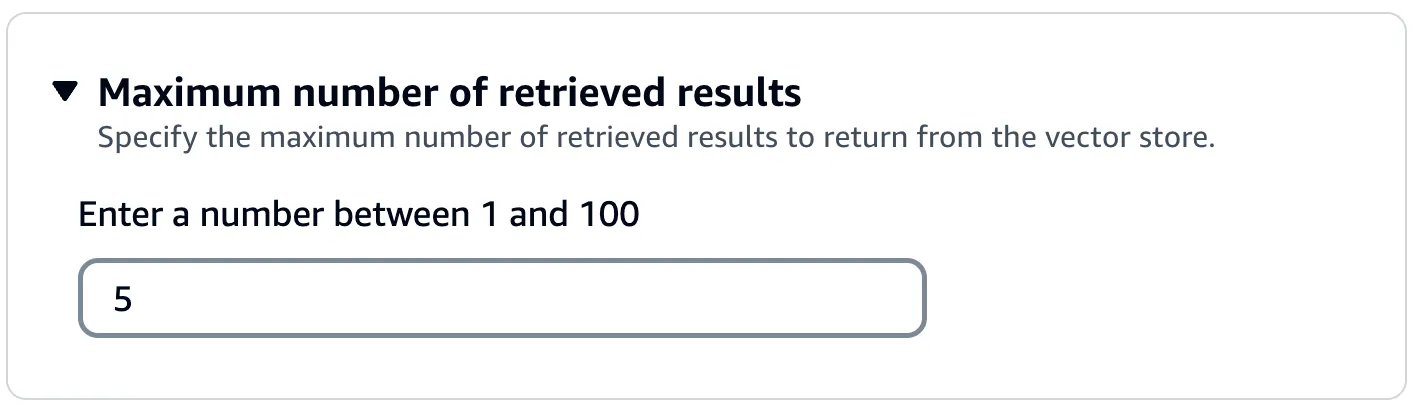
Semantic search (the retrieval in RAG) are usually Top-K searches i.e. "Give me the best K search results in response to my query". By default Amazon Bedrock returns up to five results in the response. But you can modify this:
You can actually decide to combine semantic search with the "good old" text based search - Choose the Hybrid search type if that's the case. Combines searching vector embeddings (semantic search) with searching through the raw text.
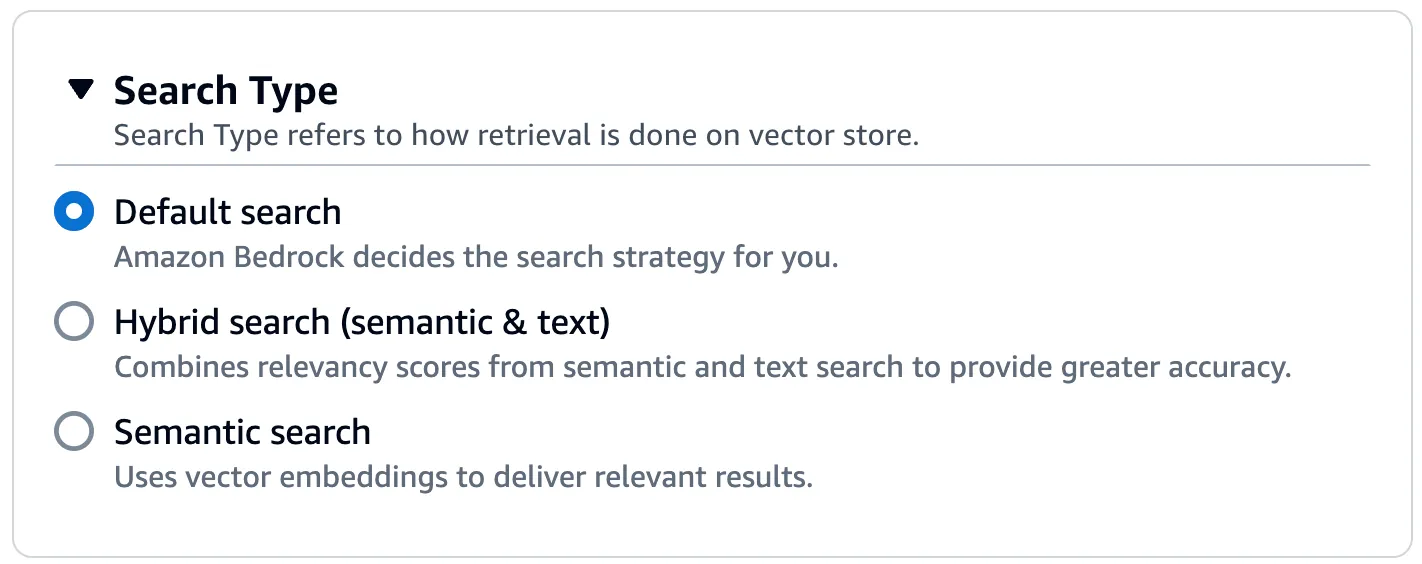
Opting for the Semantic option only searches through the vector embeddings.
Note: At the time of writing Hybrid search is currently only supported for Amazon OpenSearch Serverless vector stores that contain a filterable text field. Amazon Bedrock falls back to using semantic search if you configure a different vector store or your Amazon OpenSearch Serverless vector store doesn't contain a filterable text field.
The "A" (Augmented) in RAG is when the search results are combined with the prompt. Amazon Bedrock uses a default prompt template. But you can do further prompt engineering using prompt placeholders (such as
$query$, $search_results$, etc.). Note: This is only used with RetrieveAndGenerate API
Prompt templates differ based on the chose model. For example, here is the one for Amazon Titan Text Premier:

... and here is the one for Claude Haiku:

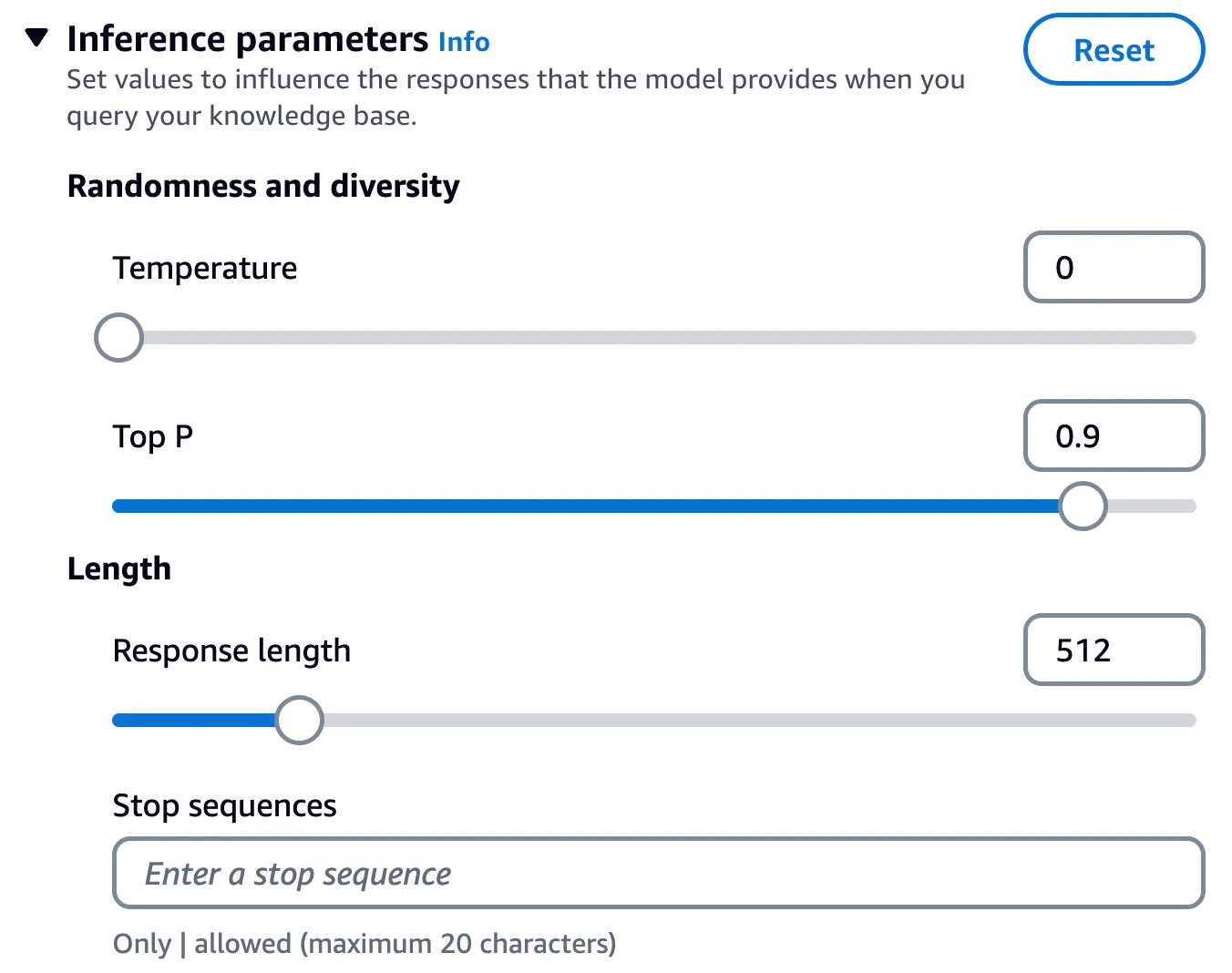
These are values that you can adjust in order to influence the model response. This includes temperature,
topP, topK, stop sequences, etc.You can set these with Knowledge Base RAG queries as well.
Note: This is only used with RetrieveAndGenerate API
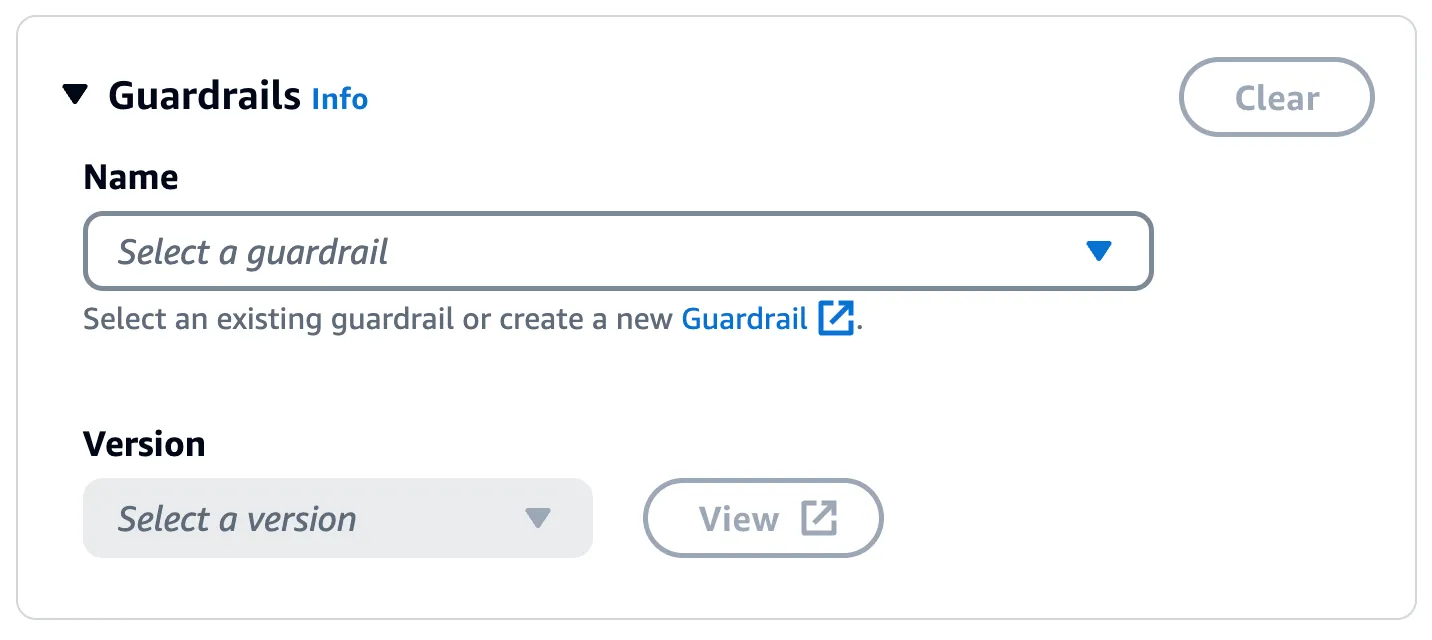
With Guardrails in Amazon Bedrock, you can implement safeguards for your generative AI applications based on your use cases and responsible AI policies. A guardrail consists of multiple policies to avoid content that falls into undesirable or harmful categories.
Note: This is only used with RetrieveAndGenerate API
Once you create a Guardrail, simple associate it with the knowledge base:
Retrieval does not have to be just limited based on the semantic search results. You can further tune queries by including additional metadata files with your source documents. It can contain attributes as key-value pairs that you define for a source document.
You can use filter (equals, greater than, etc.) and logical (and, or) search operators along for metadata based filters.
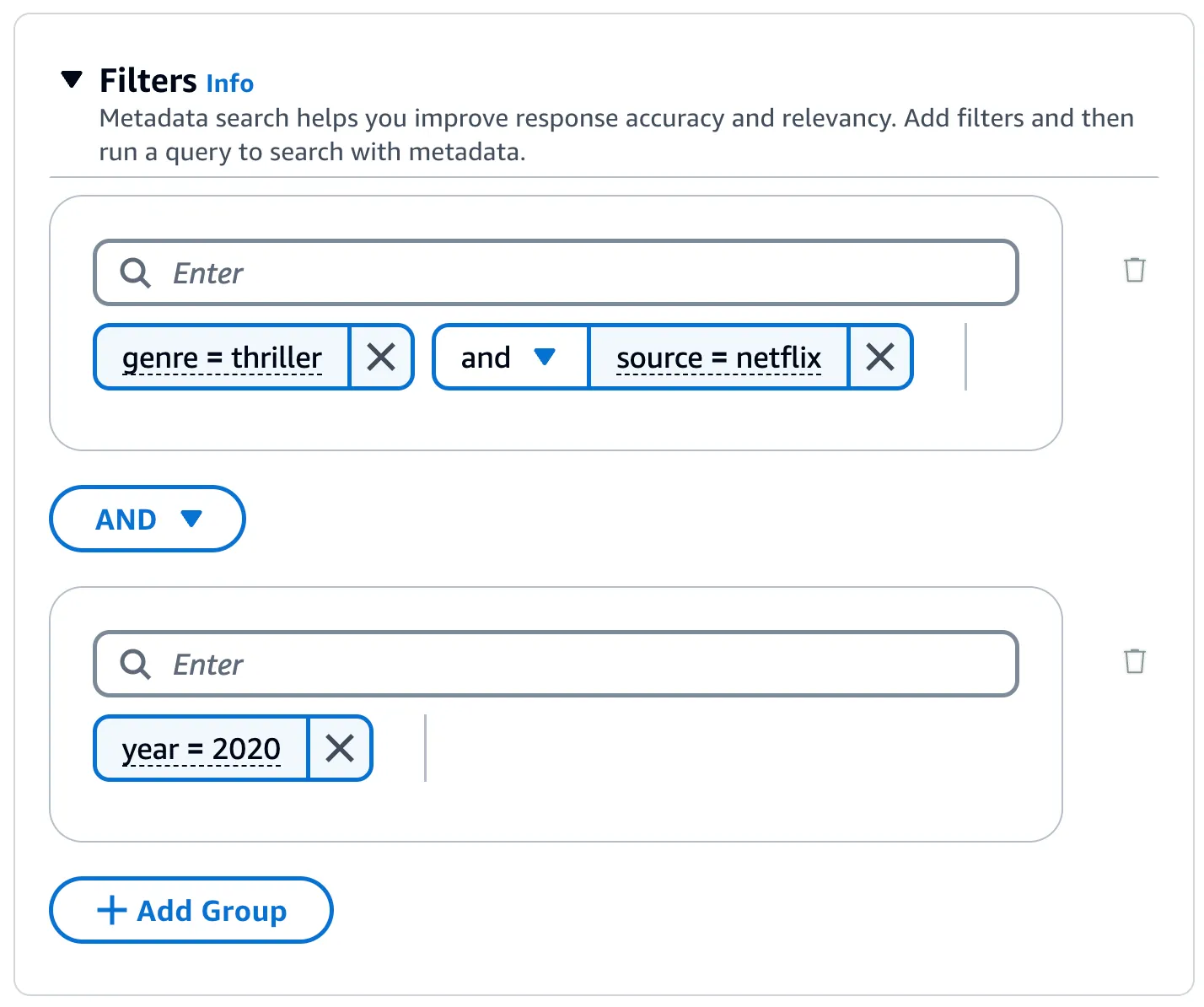
For details, you can refer to Add metadata to your files to allow for filtering
Strictly speaking, these are not query configurations, but definitely worth knowing
- Chunking: During data ingestion (from source to the chosen vector database), the each file is split into chunks using one of the following strategies - no chunking (each file = a chunk), default (each chunk = ~300 tokens), fixed size (you define the size)
- Data Deletion Policy: The default policy is
DELETE, which means that the underlying vector will be deleted along with the knowledge base. To change prevent the vector store deletion, change the policy toRETAIN.
I showed examples for AWS console, but like I mentioned earlier, these are applicable to the SDK and API as well. For example, here is how the RetrieveAndGenerate API uses these configuration parameters.
Read more in Query configurations. Happy building!
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.
Comments
Log in to comment