GenAI Data Governance Assistant
Using an LLM to help catalog data, create data quality rules, and detect duplicate tables
Randy D
Amazon Employee
Published May 22, 2024
The topic of data strategy keeps coming up in generative AI (GenAI) conversations. I wanted to unpack what is really happening and try to figure out why it is slowing down GenAI adoption.
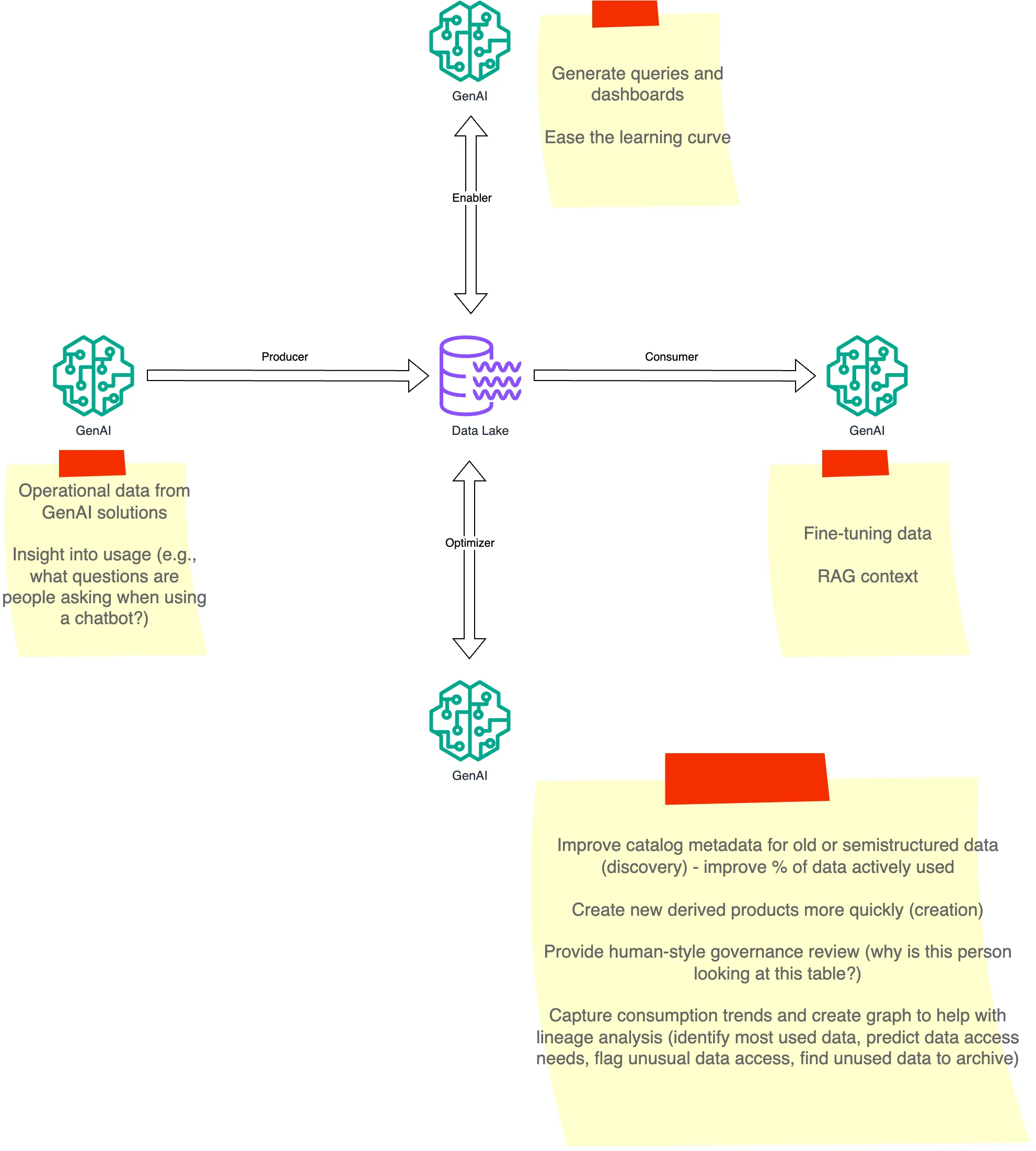
In a previous article I wrote about three patterns of GenAI interacting with data lakes, and then more recently I gave an example of using GenAI as a data producer (extracting useful information from unstructured data and populating a knowledge graph). Whether GenAI is acting as a data producer, data consumer, or just helping people interact with data, I think the data strategy question comes back to whether we have the right governance in place. Do we have an operating model that treats data as a product, so we can start building GenAI data-related projects quickly with clear ownership? Do we have a sound technical foundation, so we understand who owns the data, who is going to use it, and what security guardrails we need in place? In this sense, GenAI projects are just the latest victim of not being able to use data quickly and efficiently.
In this article I'm going to explore a fourth pattern for using GenAI in and around data - using GenAI as an assistant to help solve data governance challenges. This line of thinking is motivated by several recent conversations with AWS customers, where they asked questions like:
- How do I detect duplicate tables in the data catalog?
- How do I maintain a high standard for information in the data catalog, including useful descriptions of the content of the data?
- How do I help my teams maintain high data quality?
- How do I keep track of who is using data, and who should be notified when new data sets are made?
To help answer the first three questions, I built a simple data inspection workflow to use when creating a new data asset. The workflow is shown below.

The first step is to inspect the data. I used the Claude 3 Sonnet model for this step. I passed it a random sample of 1000 rows of data, and asked Claude to generate a schema, including column descriptions. Then I took another random sample, and asked Claude to look at the second sample and the schema from the first pass, and see if it would suggest any changes. You could repeat this step a few times to make sure that the LLM is seeing a sufficient set of data to really understand the schema.
Next, I used a method inspired by this paper to check for possible duplicate tables in the catalog. In a nutshell, it uses an LLM to write a description of each table in the catalog. We create embeddings for those descriptions. When a new table is being made, we use a RAG technique to check for tables that are similar to the new table. We rank those and show the results to the user, so they can consider if their new table is a duplicate or not.
Finally, a curation task populates the data catalog with information about the new table. It also suggests some Glue data quality rules to use against the new data asset.
The last question is really about finding connection patterns between data producers and data consumers. Who is using a data asset? Who's asking for access and being denied? Who doesn't know about a data asset that they really need?
Putting data catalog information into a knowledge graph is a great way to tackle this problem. Using a graph database, we can quickly see those types of connections, run queries on data access patterns, and even use graph machine learning to predict who should be connected to a new data asset.
I wrote a sample Jupyter notebook to populate a graph database using information from Amazon DataZone business catalog, and then query that database to answer some data governance questions. I queried the database both directly and using an LLM to translate my questions into graph database syntax (GraphRAG).
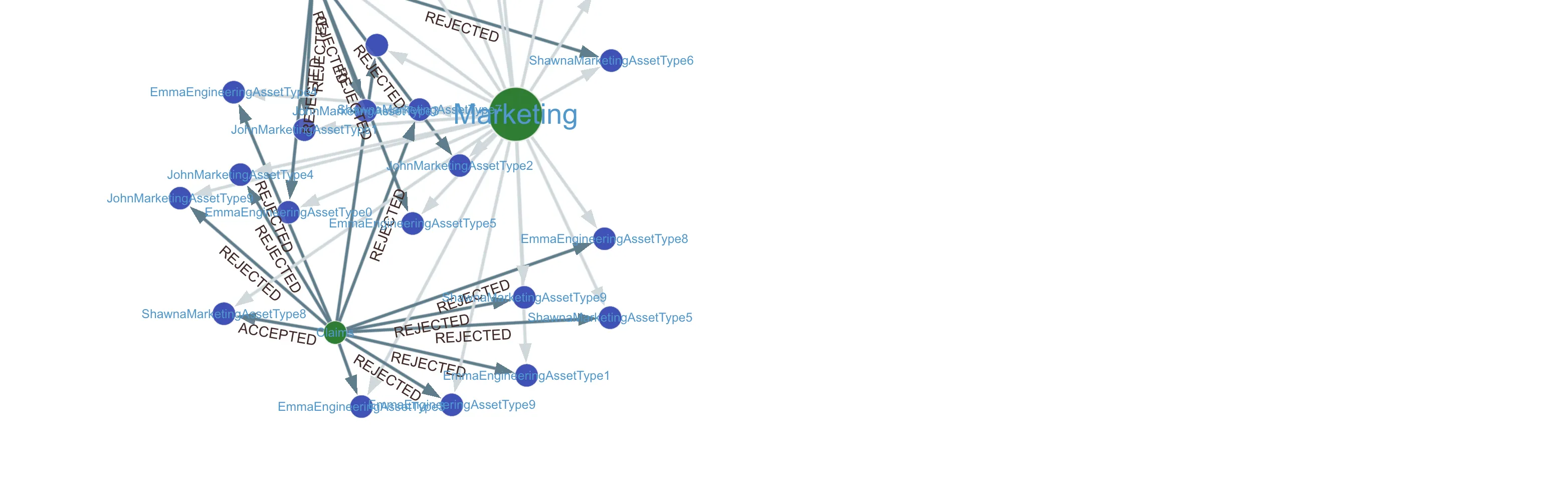
The image above shows a visualization of a simple graph query. It shows the major data owners, like a Marketing team, in the red circles. The blue circles are data assets, and the arrows show accepted and rejected data access requests.
Using GraphRAG makes it even easier to get answers to questions about data access patterns.
I see data strategy and governance as both a challenge and an opportunity for GenAI. It's very easy to get started with a simple GenAI project to help answer questions based on your business data. But when you try to scale that type of solution from a single team to an entire company, you start running into the usual challenges - you need to consider security policies, make sure data is easily visible to those who need it, and so on.
Data governance can be difficult to implement effectively, and GenAI is really good at helping automate the tedious and ambiguous parts of populating a data catalog and maintaining good data governance. By asking "what is difficult about data governance for us today", you will probably identify several ways to use GenAI as a data governance assistant.
The sample code I mentioned in this article is available in GitHub.
Finally, here's a summary of the four patterns for GenAI in and around data.
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.