Exploring Hybrid Deployment Options for GenAI
Deploying GenAI apps in Hybrid Environment using Amazon Bedrock, Amazon Q and On-Premise.
Godwin
Amazon Employee
Published Jun 7, 2024
Many organizations have strict data residency requirements, mandating that sensitive or regulated data must remain within their on-premises infrastructure or specific geographic regions. This ensures compliance with local regulations and protects sensitive information from cross-border data transfer issues.
In some cases, customers or partners may have specific mandates or policies requiring data to be kept within their own data centers or on-premises infrastructure. This could be due to security concerns, industry-specific regulations, or organizational preferences. Keeping data on-premises ensures better control and security.
Certain use cases or applications of GenAI solutions may have stringent latency requirements, where real-time or near-real-time responses are critical. By deploying GenAI models on-premises or in edge locations, customers can minimize latency and ensure faster response times compared to cloud-based solutions. This is particularly important for applications like real-time processing, industrial automation, or time-sensitive decision-making scenarios.
While there are numerous factors compelling customers to explore hybrid options for deploying Generative AI (GenAI) solutions, the three aforementioned scenarios play a pivotal role. The need for flexibility, cost considerations, and compliance requirements are driving forces behind the adoption of hybrid architectures. These factors are prompting organizations to seek tailored solutions that strike a balance between the convenience of cloud-based services and the control afforded by on-premises deployments. By embracing hybrid approaches, customers can leverage the best of both worlds, addressing their unique requirements while capitalizing on the transformative potential of GenAI technologies.
As we delve into the diverse hybrid options below, it's essential to first explore and understand some of the Amazon Bedrock features that form an integral part of these hybrid architectures.
Bedrock is the easiest way to build and scale generative AI applications with foundation models. It is a fully managed service that allows you to get started quickly.
You can find the right model for your needs and customize it with your own data privately. Bedrock ensures that nothing feeds your data back to the base models.
Bedrock provides the necessary tools to combine the power of foundation models with your organization’s data to execute complex tasks securely and privately, ensuring responsible AI safety.
To equip the foundation model with up-to-date proprietary information, organizations can use Retrieval Augmented Generation (RAG). This technique involves fetching data from company data sources and enriching the prompt to deliver more relevant and accurate responses.
Knowledge Bases for Amazon Bedrock is a fully managed RAG capability that automates the end-to-end RAG workflow, including ingestion, retrieval, and prompt augmentation. This eliminates the need for custom code to integrate data sources and manage queries.
Built-in session context management supports multiturn conversations, enhancing the user experience. All retrieved information comes with source citations to improve transparency and minimize hallucinations.
Knowledge Bases for Amazon Bedrock works with popular vector databases like Amazon OpenSearch Serverless, Redis Enterprise Cloud, Pinecone, Amazon Aurora, and MongoDB, with additional databases being added over time.
Agents for Amazon Bedrock extend the capabilities of foundation models by planning and executing multi-step tasks using company systems and data sources. This includes solving problems, discovering timely information, and interacting with company systems to complete tasks.
With Amazon Bedrock, creating an agent is simple. Select a foundation model, provide access to enterprise systems, knowledge bases, and a few AWS Lambda functions. The agent analyzes user requests and automatically calls the necessary APIs and data sources to fulfill the requests.
Agents for Amazon Bedrock ensure secure and private operations. They offer visibility into the foundation model’s chain-of-thought reasoning, allowing for troubleshooting and prompt modification to improve responses [1].
Effective retrieval from private data involves splitting documents into manageable chunks, converting them to embeddings, and writing them to a vector index. These embeddings determine semantic similarity between queries and text from data sources.
At runtime, an embedding model converts the user's query to a vector, which is then compared with document vectors in the vector index. The user prompt is augmented with additional context from the retrieved chunks and sent to the model to generate a response.
Amazon Q-Based Architecture:
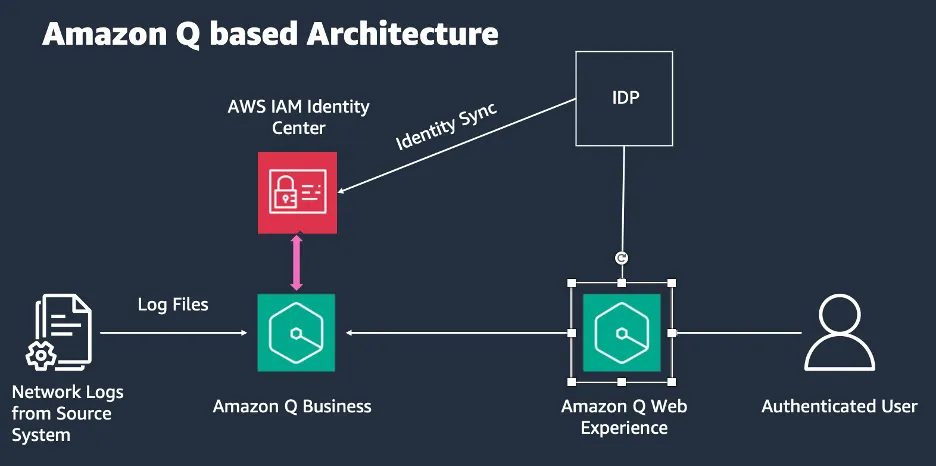
This architecture allows for quickly building ChatOps POCs with minimal effort, offering a fully managed end-to-end solution. However, it lacks visibility into the model and embeddings and does not support fine-tuning with domain data.
Advantages:
· Rapid development of Chat Ops Proof of Concept (POC) with minimal effort.
· Fully managed end-to-end solution, alleviating the need for complex configuration.
· No need to agonize over model selection, as this is handled seamlessly.
· Seamless propagation of Access Control Lists from Source Systems/documents to the Intelligent Document Comprehension (IDC) service.
· Flexible synchronization options, ranging from hourly to weekly intervals.
Limitations:
· Lack of visibility into the underlying model, embeddings, or vector database, often prompting customer inquiries about the employed Few-Shot Model (FM).
· Inability to fine-tune or pre-train the model with domain-specific data.
· Until recently, no actions could be performed (Custom Plugins are now available).
· Restricted from using custom Retrieval-Augmented Generation (RAG) or third-party vector databases.
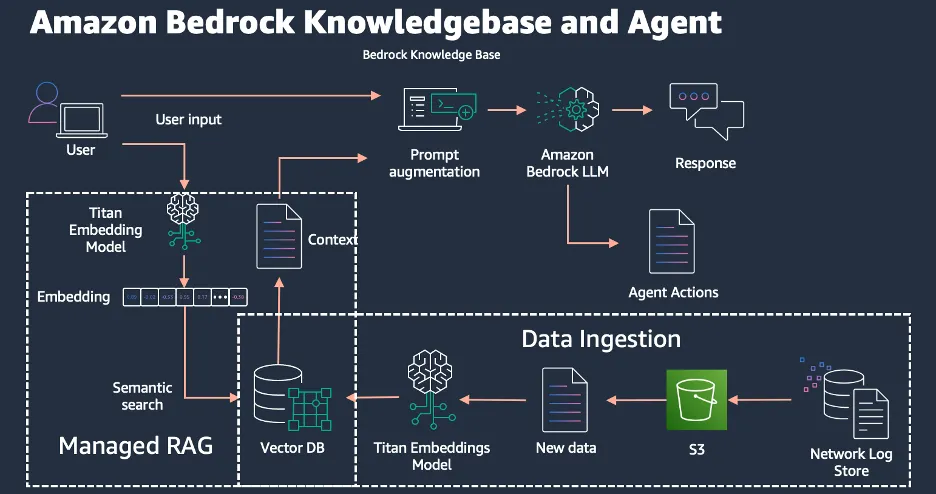
This managed RAG solution allows for choosing the right model and performing actions using agent groups. It can complete POCs quickly if the data is ready but requires manual data movement to S3.
Advantages:
· Seamless integration with a managed Retrieval-Augmented Generation (RAG) solution.
· Flexibility to choose the most suitable model tailored to your specific requirements.
· Ability to leverage agent groups and actions, enabling the execution of desired operations.
· Rapid Proof of Concept (POC) development, achievable within a few days if the necessary data is readily available.
Limitations:
· Data sources are limited to Amazon Simple Storage Service (S3), necessitating manual data transfer to S3.
· Restricted from utilizing fine-tuned or pre-trained models.
· Inability to inherit Access Control Lists (ACLs) from the source, requiring manual configuration of access controls.
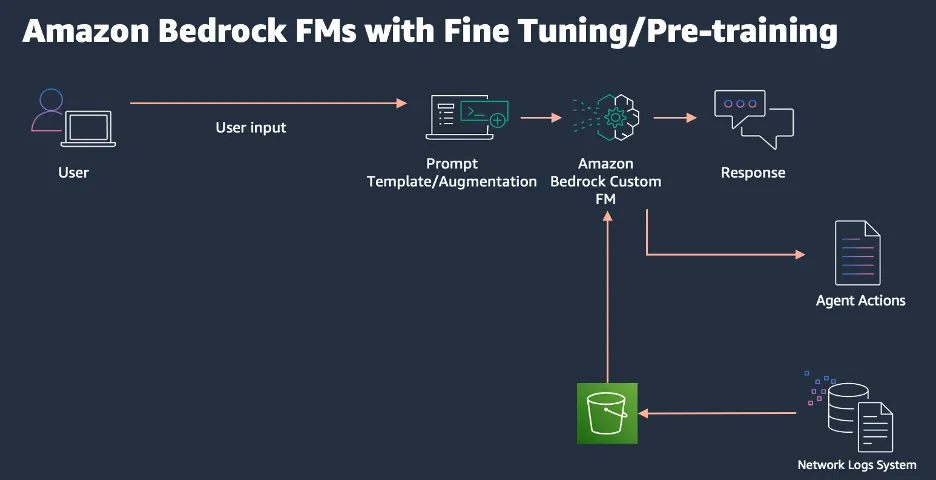
This approach eliminates the need for knowledge bases or embeddings but can be expensive and resource-intensive. It also requires expertise for fine-tuning or pre-training.
Advantages:
· Streamlined approach without the need for a knowledge base, embeddings, or vector databases.
· Simple architectural design, facilitating ease of implementation and maintenance.
· Flexibility to incorporate your own custom-built models.
Limitations:
· Inability to leverage the most relevant data sources for optimal performance.
· Costly and resource-intensive process of fine-tuning or pre-training models.
· Limited support for fine-tuning across all available models.
· Lack of readily available resources and expertise in the field of Generative AI (GenAI) for fine-tuning or pre-training tasks, including the intricate process of updating weights at different layers.
· Requirement to build and maintain your own access control list from scratch.
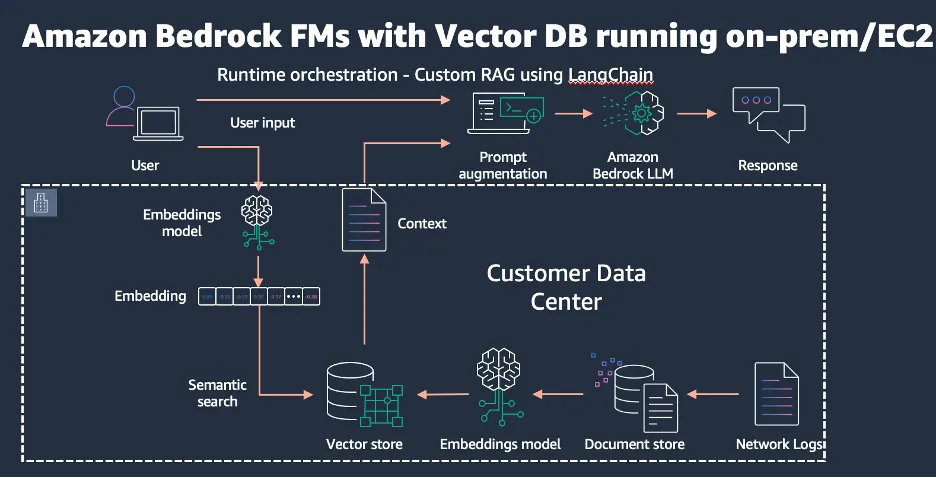
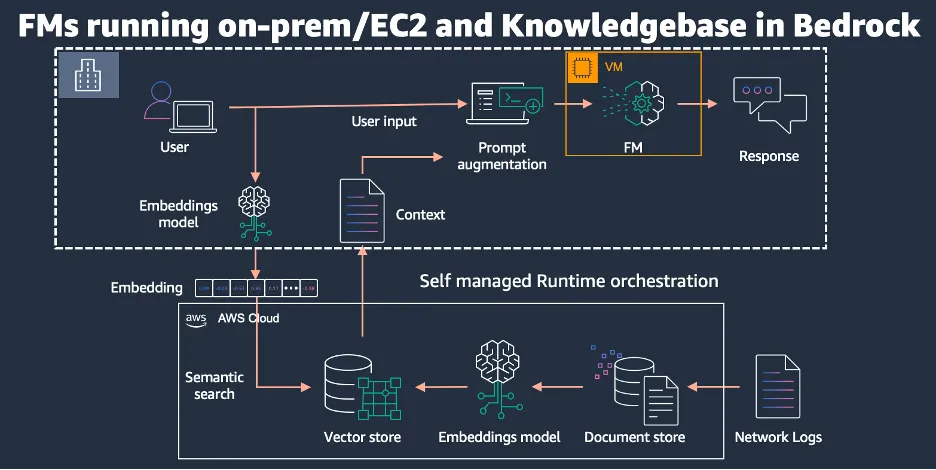
This architecture offers flexibility in choosing models and vector databases, ensuring data residency and meeting partner mandates. However, it requires secure communication channels and significant development effort.
Advantages:
· Increased flexibility in selecting models within the Bedrock framework.
· Freedom to choose from a variety of Vector Databases (such as Weaviate, Qdrant, or the self-hosted version of Pinecone).
· Flexibility in selecting Embedding Models, either on-premises or cloud-based, for converting words/queries into vector representations.
· Ability to comply with data residency and partner mandate requirements.
Limitations:
· Necessity to establish secure communication channels.
· Self-managed Retrieval-Augmented Generation (RAG) solution, requiring substantial development effort and resources.
· Time-consuming implementation and maintenance process.
· Requirement to convert every query into vectors before sending it to the vector database for similarity search, utilizing the same embedding model used for data ingestion.
· Responsibility for managing all data synchronization schedules on-premises.
· Manual management of access controls for source document access.
This architecture is suitable for cases where data residency and latency are critical. It allows for using fine-tuning or pre-training without relying on knowledge bases, but it is expensive and resource-intensive.
Advantages:
· Flexibility to select the Few-Shot Models (FMs) that best align with your specific use cases.
· Access to Trainium and Inferentia instances for optimized training and inference in the cloud environment.
· Ability to address data residency, partner mandate, and latency concerns.
· Option to utilize a knowledge base or forgo its use, focusing solely on fine-tuning or pre-training methods.
Limitations:
· Extremely costly process, requiring significant financial investment.
· Responsibility for overseeing the training and deployment of models, necessitating expertise and time-consuming efforts.
· Manual development and implementation of guardrails to ensure responsible AI practices.
· Manual implementation of all access controls, adding to the workload.
· Requirement to convert every query into vector representations before sending it to the vector database for similarity search, using the same embedding model employed for data ingestion.
· Continuous maintenance and version updates for the models, adding to the operational overhead.
· Adopting generative AI models can bring numerous benefits, but it also presents several challenges that organizations must address. As Amazon Bedrock introduces frequent updates and new models, selecting the most suitable option can become confusing. Conducting thorough iterations and comparisons is necessary to ensure the right model choice aligns with the specific use case and requirements.
· Understanding the context, including the use case, data, and domain, is crucial for choosing the appropriate approach. Starting with prompt engineering or leveraging existing knowledge bases is often recommended, as pre-training or fine-tuning models can be complex and costly processes.
· Generative AI models have the potential to perpetuate biases or generate harmful content, which raises ethical concerns. Implementing robust ethical guidelines and monitoring mechanisms is vital, especially in sensitive domains such as healthcare, finance, or legal services, where the impact of biased or inappropriate outputs can be significant.
· Integrating generative AI models seamlessly with existing systems and workflows requires a deep understanding of the organization's processes and data structures. Achieving this level of integration can be challenging but is essential for maximizing the benefits of AI adoption.
· Striking a balance between human expertise and AI-generated outputs is crucial, particularly in domains where human judgment and decision-making are highly valued. Fostering effective human-AI collaboration can help organizations leverage the strengths of both human and artificial intelligence.
· Generative AI models require continuous updates and maintenance to remain effective and relevant. This ongoing effort can be resource-intensive and may necessitate specialized expertise within the organization or through external partnerships.
· Ensuring compliance with industry-specific regulations is a significant challenge when adopting generative AI solutions. Organizations must carefully navigate regulatory landscapes and implement robust governance frameworks to ensure responsible AI adoption and mitigate legal and reputational risks.
· By proactively addressing these challenges, organizations can maximize the benefits of generative AI models while minimizing potential risks and fostering trust in their AI-powered solutions.
To effectively leverage generative AI capabilities, organizations must adopt a comprehensive strategy encompassing several critical components. To ensure alignment and support across the organization, it is crucial to involve stakeholders from the beginning. This should be coupled with continuous customer engagement, enablement sessions, and proactive follow-up to address concerns, enhance understanding, and drive project success.
Furthermore, early collaboration between cross-functional teams, including AI experts, domain specialists, and end-users, is essential for comprehensive planning and execution. This collaborative approach should extend throughout the hybrid deployment lifecycle to foster effective human-AI collaboration and leverage the collective expertise of all parties involved.
A thorough assessment of use cases and potential risks must be conducted to inform decision-making and mitigate potential challenges. This risk assessment should encompass ethical considerations, regulatory compliance requirements, and integration complexities with existing systems and workflows.
Continuous monitoring and evaluation of AI models are critical to ensure their relevance, effectiveness, and alignment with evolving business needs. This iterative process may necessitate ongoing maintenance, updates, and specialized expertise to optimize model performance and adapt to changing requirements.
By proactively addressing these key aspects and leveraging the capabilities of Amazon Bedrock and hybrid architectures, organizations can navigate the complexities of selecting, integrating, and maintaining generative AI models. This comprehensive approach enables organizations to deploy tailored AI solutions that meet their specific needs and operational constraints while ensuring ethical and regulatory compliance, seamless integration, and optimal human-AI collaboration.
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.