
Patterns for Building Generative AI Applications on Amazon Bedrock
With generative AI, we are introduced to a new, exciting and powerful primitive for building software. Learn how you can build generative AI applications without deep machine learning expertise. We cover foundational patterns, considerations, and practices learned from our experience working with early adopters.
Daniel Wirjo
Amazon Employee
Published Oct 3, 2023
Last Modified Mar 14, 2024
This post is written by Daniel Wirjo, Startups Solutions Architect, Aaron Su, Startups Solutions Architect, and reviewed by Mike Chambers, Senior Developer Advocate.
As software builders, we've been genuinely captivated by the continuing evolution of generative AI: from discovering new use cases, to emerging architectures for software. Now, with Amazon Bedrock, you can access leading generative AI foundation models (FMs) through APIs. Bedrock makes it simple for even small teams to build and scale generative AI applications.
In this post, you will delve into three high-level reference architectures, covering the key building blocks of generative AI applications. Drawn from our collaboration with early adopters, you will learn about practical considerations and emerging best-practices to guide your implementation.
Typically, traditional ML models can only perform a single task. They require a build, train and deploy lifecycle (MLOps) which can be challenging for smaller teams. On the other hand, FMs are trained on large datasets. They use broad knowledge to solve multiple tasks, such as text generation, classification, analysis and summarisation — all through natural language prompts. They enable emerging architectures previously not possible. And, they are significantly easier to build, scale and maintain.
Image not found
You can incorporate generative AI into your applications leveraging your own data. This is driven by a foundational architecture, retrieval-augmented generation (RAG). It solves inherent knowledge limitations of FMs by integrating with data that are not part of the model’s training. All achieved without complexities associated with re-training and MLOps.
To illustrate, imagine a skilled researcher (retrieval) that fetches the most relevant books from a vast library, and a creative expert professional (generation) that suggests ideas and answers with the knowledge in the books.
Now, consider a prompt with context (retrieval) and instruction (generation) elements. Here, you provide context by finding and inserting the relevant data to the question (retrieval). And, you provide instruction to conduct a task based on the context such as summarization (generation).
1
2
3
4
5
6
7
8
9
10
11
12
Context:
{Generative AI on AWS}
{AWS Machine Learning Blog}
{AWS Documentation}
{Well-Architected Framework}
{AWS Reference Architectures}
Instruction:
You are an expert AWS Solutions Architect.
Provide me with expert insights on {question}.
Summarize insights and recommendations based only on the Context.
If the Context does not provide the answer, say "I don't know".Note curly brackets
{placeholders} are template placeholders and you replace them with actual data.As FMs are fundamentally probabilistic models, they can hallucinate and may provide made up, erroneous outputs. To mitigate this, models such as Anthropic Claude support instructions to:
- Prevent hallucination by letting the model say “I don’t know”
- Provide a level of explainability by asking to cite sources
As a result, these instructions are commonly used in a prompt template. Crafting the right prompt (also known as prompt engineering) is a key component in building generative AI applications.
At a high-level, the architecture consists of two key components:
- RAG Pipeline to process data from your knowledge sources
- RAG Runtime to process user prompts using Bedrock
To orchestrate, you adopt an open-source tool, such as LangChain. LangChain contains pre-built libraries for integrating with various data sources and Bedrock. Alternatively, you can use LlamaIndex or Haystack.
First, you convert data from knowledge sources (such as Amazon S3 or Amazon DynamoDB) to an appropriate vector format for later retrieval.
Image not found
Consider the following steps:
Prepare: You collect, clean and transform data for later processing. For example, you transform raw data into a structured format such as JSON, identify metadata that are useful for filtering and access control, and remove any erroneous or unnecessary data.
Chunk: FMs have a limited context window. For large text, you use document transformers to split them into chunks. Typically, you find an optimal chunking strategy through trial and error. As it depends highly on the specific content, you will need to balance preserving context and maintaining accuracy.
Vectorize: You convert data into embeddings. An embedding is simply a vector representation of the data in a multi-dimensional space. It facilitates retrieval through similarity search. To get started, try an embeddings model from Bedrock. Alternatively, open-source models on Massive Text Embedding Benchmark (MTEB) leaderboard such as sentence-transformer.
Dimensionality: Consider dimensionality of vector embeddings. For example, Amazon Titan Text Embeddings have 1,536 dimensions. Dense vectors with higher dimensions provide greater factors for similarity. However, sparse vectors with lower dimensions may improve efficiency and performance. And, vector databases may also impose limitations on dimensions.
Store: You store the embeddings into a vector database, such as Amazon OpenSearch Serverless. Initially, you load data in bulk. As new data is generated, you build a pipeline. For example, you use knowledge bases for Amazon Bedrock. Or, an event-driven architecture with Amazon S3 events or Amazon DynamoDB streams with Amazon EventBridge Pipe to trigger a Lambda function to index new data.
Data security: As the vector database may handle sensitive data, consider data protection controls such as encryption, access control, and redaction/masking of sensitive personal information.
Multi-tenancy: For SaaS applications, consider multi-tenancy to keep data for a particular customer (tenant) private and inaccessible to others.
Vector databases: In addition to OpenSearch, you can use pgvector. For prototyping, you can use in-memory stores, such as Faiss and Chroma, which provide a convenient developer experience to get started. For third-party vector databases, AWS Marketplace provides access to leading providers including Pinecone, Weaviate and MongoDB Atlas Vector Search.
At runtime, your application will need to process the user’s original input prompt and augment it with the retrieved context.
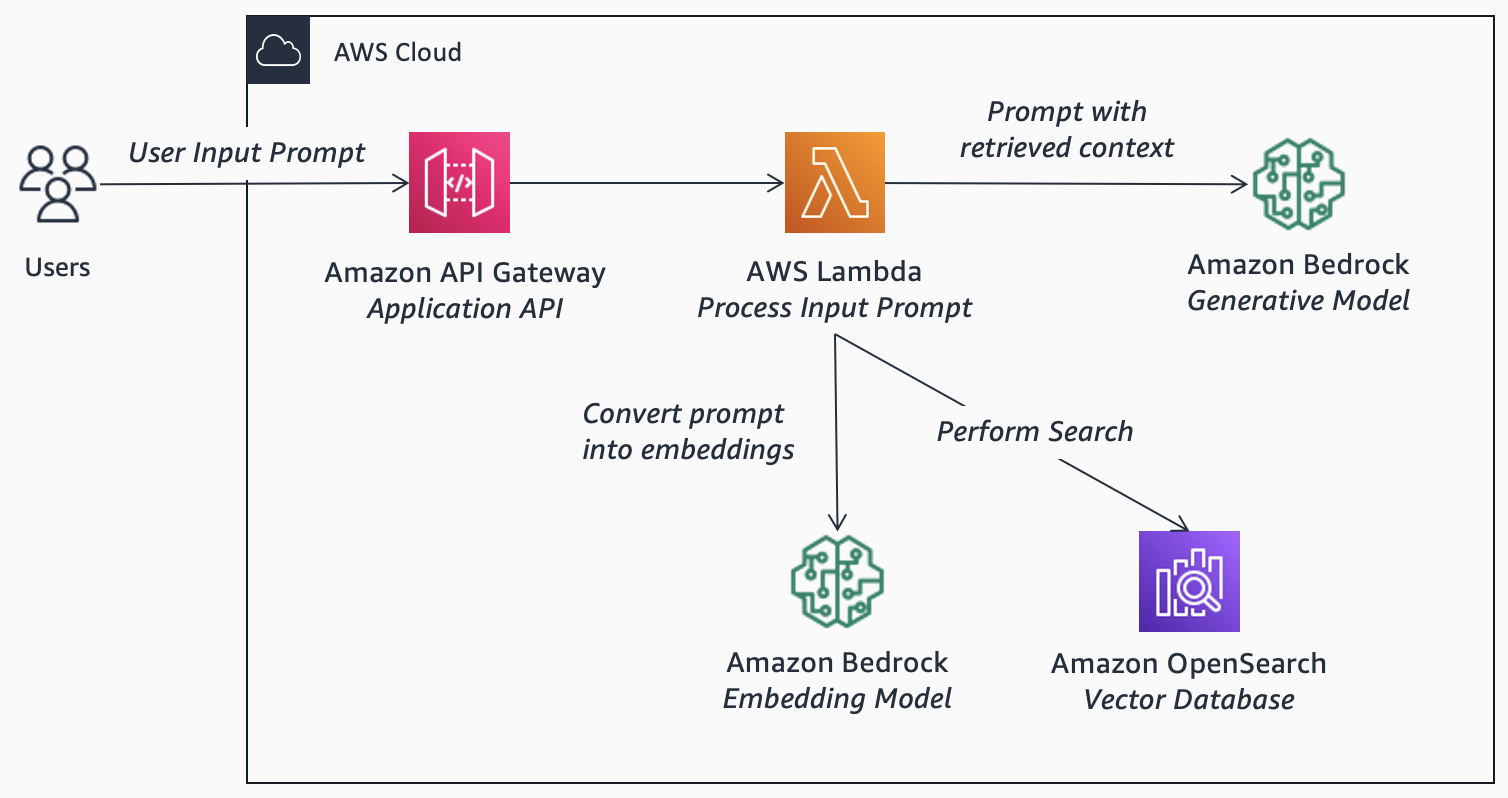
Consider the following steps:
Retrieve: You retrieve relevant data from the vector database. In addition to vector storage, vector databases provide indexing and retrieval capabilities. A starting approach is semantic search. Here, you convert the input prompt into embeddings. Then, you find similar embeddings in the vector database using a nearest neighbors search. By using vectors, you understand the meaning behind prompts and deliver contextually relevant results. (Under the hood, a popular algorithm for vector search is Hierarchical Navigable Small World (HNSW), see aws-samples/gofast-hnsw).
Advanced retrieval: Unfortunately, entities or domain-specific terminologies may not be represented well in the training data of popular embeddings model. As a result, using semantic search alone may produce less accurate results. You improve this with hybrid search. Here, you combine semantic search with a traditional document search (such as BM25). In addition, consider orchestrating advanced retrieval techniques. For example, contextual compression to remove irrelevant text, maximal marginal relevance (MMR) to diversify results, or ensemble retrieval to combine multiple strategies.
Generate: You generate an output by inputting a prompt with the retrieved data as context. The output depends on the model you select, and prompt you design.
Model selection: With Bedrock, you get access to leading foundation models with enterprise-grade security. You choose a model that supports your use case, context length, and price-performance requirements. You use InvokeModel via the AWS SDK. Consistent with other AWS services, you configure access using AWS IAM, view audit logs in AWS CloudTrail, optionally enable private connectivity using AWS PrivateLink.
Prompt design: For effective prompts, be specific with instructions. This includes the desired output format (such as text within specific template or length, or a structured format such as JSON, XML, YAML and markdown). Consider best-practices from the model provider. For example, see prompt design. For prototyping, you design a number of test cases. You set temperature to
0 to mitigate randomness in the output for evaluation.With RAG as foundation, you build a conversational chat feature to provide a fast, intuitive and natural experience for your users. While this may sound simple, it can be deceivingly challenging to build.
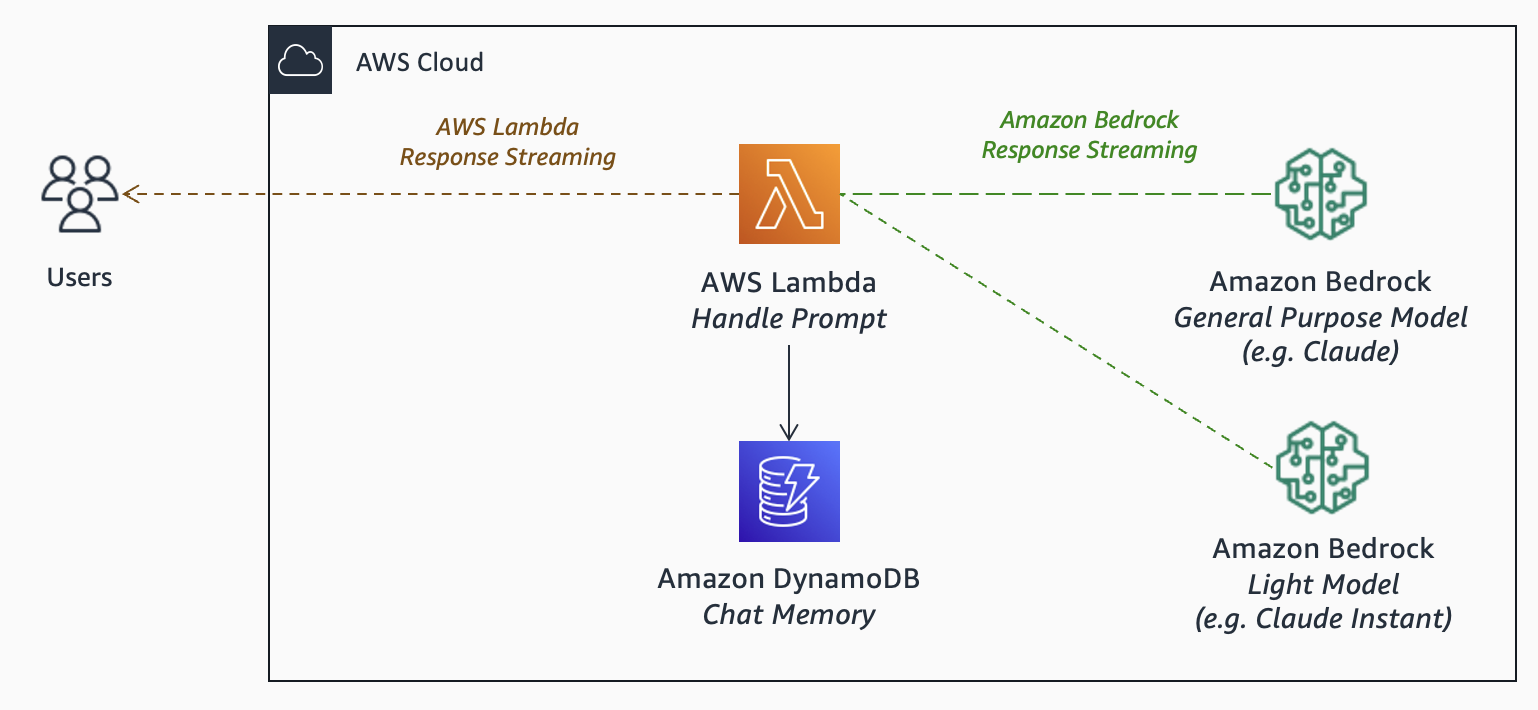
Consider additional elements:
Memory: You may need to remember previous interactions to understand follow-up questions. By default, models are stateless. However, you can incorporate memory with low-latency store such as DynamoDB. There are advanced types of memory. For example, conversation summary for handling long-chat interactions.
Latency: As users increasingly expect fast experiences, consider response streaming. Response streaming is supported in both Bedrock and Lambda. With streaming, you return a response to the user as soon as a chunk is generated by the FM. For less complex tasks, you use a smaller FM such as Claude Instant. Smaller models handle a narrower set of tasks, but can perform faster than larger models.
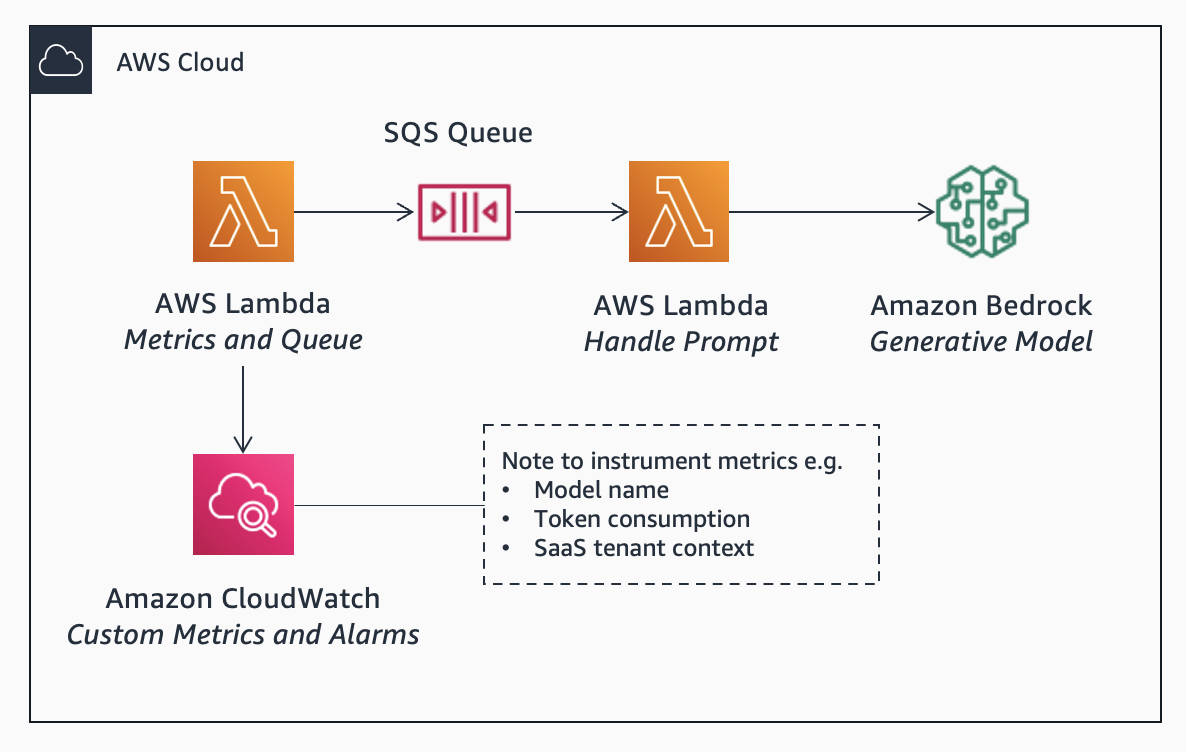
Throughput (requests): Your application may require high throughput. Consider service quotas. To manage requests per minute (RPM), you use an Amazon Simple Queue Service (SQS) queue to asynchronously process requests.
Throughput (tokens): With generative AI services, you also need to manage tokens processed per minute (TPM). Tokens consumed depends on the length of prompts, usage frequency which can vary widely depending on the use case. 1,000 tokens is approximately equivalent to 750 words. One approach is to limit input prompts to a maximum number of words. When you achieve scale, consider provisioned throughput.
Monitoring: You monitor performance and token consumption using the integration with Amazon CloudWatch. You can also instrument custom metrics to add any additional context that can help you understand and manage performance, such as the tenant context if you are building a SaaS application. In addition, consider the quota monitoring solution.
As you build AI applications, you may start with simple model interactions. However, your user journey may have multiple steps that benefit from AI. You may require advanced, multi-step and parallel processes integrating with various systems. For example, a content creation tool can invoke variation of prompts in parallel. Leveraging the creativity of generative models, they generate multiple outputs for users to select. These outputs can be further improved through additional prompts and operations.
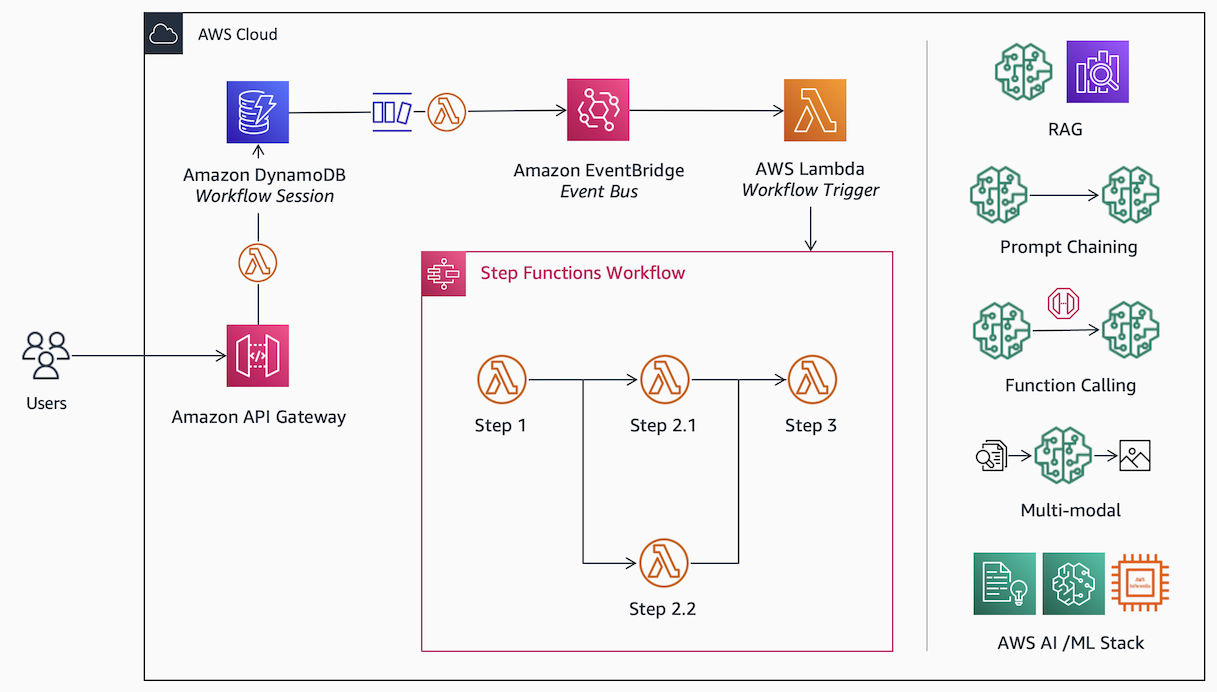
Consider additional elements:
Orchestration: In the infrastructure layer, you can orchestrate a workflow with event-driven services such as Amazon EventBridge and AWS Step Functions. In the application layer, tools such as LangChain support chains and agents.
Prompt Chaining: Many workflows require conditional logic, breaking down complex questions into multiple steps, and multiple retrievals. One approach is to feed the model’s response to a prompt, into the input for another prompt. See prompt chaining. They may also require a precise output. For example, a JSON format with a specific structure with no political content. Here, you can have an additional prompt to double check the previous prompt for validity.
Function Calling: Some foundation models, such as Claude, have been tuned for function calling. This enables a wide range of extensions, including performing mathematical computation, retrieval of data via APIs, and even actions, such as email notifications. Here, you convert a natural language instruction into function instructions. For example:
- Instruction:
What is the current weather in Sydney in celsius? - Output:
get_weather(location = "Sydney", units = "C")
With the output, you then call the function separately. For the model to recognize the function(s), you simply define them as context into a prompt. For example:
1
2
3
4
5
6
7
8
9
10
11
<function>
<function_name>get_weather</function_name>
<function_description>Returns the current weather for a given location</function_description>
<required_argument>location (str): Name of city or airport code</required_argument>
<optional_argument>units (str): Temperature units, either "F" for Fahrenheit or "C" for Celsius, default "F"</optional_argument>
<returns> weather (dict): - temperature (float): Current temperature in degrees - condition (str): Short text description of weather conditions </returns>
<raises>ValueError: If invalid location provided</raises>
<example_call>
get_weather(location="New York", units="F")
</example_call>
</function>For a managed solution, consider agents for Bedrock.
Multi-modal: In addition to text, many generative and embedding models process other modalities of data such as images, audio and videos. For example, embedding models such as CLIP can facilitate similarity search for images. And, generative models such as stable diffusion can generate images from text.
AWS AI/ML Stack: For advanced use cases, you can combine multiple AI/ML capabilities. For example, AI services such as Amazon Comprehend for entity detection. Amazon SageMaker to access open-source models from Hugging Face. And, purpose-built ML infrastructure, such as AWS Inferentia2 for cost optimization at scale.
For developers, generative AI with Amazon Bedrock is a new building block, opening doors to explore innovative and exciting use cases. In this post, you learned about foundational patterns for generative AI applications. You delved into retrieval-augmented generation (RAG) including the role of prompt engineering and vector search. Expanding on this foundation, you then explored common generative AI use cases, including chat and advanced workflows. This post hopes to serve as a valuable guide, reference and inspiration for your journey with generative AI.
To get started with Amazon Bedrock, try the hands-on workshop.
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.
Comments
Log in to comment