Create and run SageMaker pipelines using AWS SDKs
Amazon SageMaker is powerful for machine learning, but did you know you can automate SageMaker operations using pipelines with AWS SDKS?
rlhagerm
Amazon Employee
Published Aug 18, 2023
Last Modified Apr 23, 2024
Are you using Amazon SageMaker for machine learning operations? If you are, did you also know you can automate your ML operations using an Amazon SageMaker Model Building Pipeline, and deploy and run those pipelines using AWS SDKs?
A new example scenario demonstrating how to work with Amazon SageMaker pipelines and geospatial jobs is available now as part of the AWS SDK Code Example Library.
The code example library is a collection of code examples that shows you how to use AWS software development kits (SDKs) with your development language of choice to work with AWS services and tools. You can download all of the examples, including this Amazon SageMaker scenario, from the GitHub repository.
The code in this example uses AWS SDKs to set up and run a scenario that creates, manages, and executes a SageMaker pipeline. A SageMaker pipeline is a series of interconnected steps that can be used to automate machine learning workflows. You can create and run pipelines from SageMaker Studio using Python, but you can also use an AWS Software Development Kit (SDK). Using the SDK, you can create and run SageMaker pipelines and also monitor pipeline operations.
To follow along with this example, clone the repository and choose your preferred language SDK from the list below. Each language link will take you to a README file which includes setup instructions and prerequisites for that specific version.
A SageMaker pipeline is a series of
interconnected steps that can be used to automate machine learning workflows. Pipelines use interconnected steps and shared parameters to support repeatable workflows that can be customized for your specific use case.
interconnected steps that can be used to automate machine learning workflows. Pipelines use interconnected steps and shared parameters to support repeatable workflows that can be customized for your specific use case.
This example scenario demonstrates using AWS Lambda and Amazon Simple Queue Service (Amazon SQS) as part of an Amazon SageMaker pipeline. The pipeline itself executes a geospatial job to reverse geocode a sample set of coordinates into human-readable addresses. Input and output files are located in an Amazon Simple Storage Service (Amazon S3) bucket.
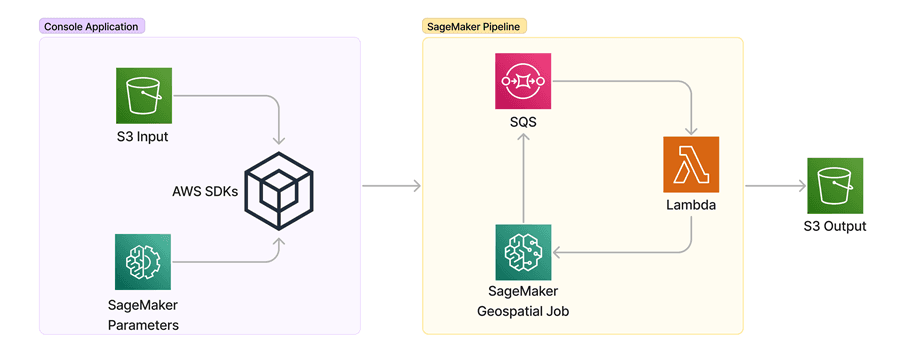
When you run the example console application, you can execute the following steps:
- Create the AWS resources and roles needed for the pipeline.
- Create the AWS Lambda function.
- Create the SageMaker pipeline.
- Upload an input file into an Amazon S3 bucket.
- Execute the pipeline and monitor its status.
- Display some output from the output file.
- Clean up the pipeline resources.
All of these steps are executed by the language code from the repository. For example, in the .NET solution the scenario is available within the SageMakerExamples.sln solution. You can run the example as-is or experiment by making changes to the pipeline, Lambda function, or input and output processing options.
The console example can be executed directly from your IDE, and includes interactive options to support running multiple times without having to create new resources. For .NET, run the example by selecting
Start Debugging in the toolbar or by using the command dotnet run. The example will guide you through the setup and execution of the pipeline.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
--------------------------------------------------------------------------------
Welcome to the Amazon SageMaker pipeline example scenario.
This example workflow will guide you through setting up and running an
Amazon SageMaker pipeline. The pipeline uses an AWS Lambda function and an
Amazon SQS Queue. It runs a vector enrichment reverse geocode job to
reverse geocode addresses in an input file and store the results in an export file.
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
First, we will set up the roles, functions, and queue needed by the SageMaker pipeline.
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Checking for role named SageMakerExampleLambdaRole.
--------------------------------------------------------------------------------
Checking for role named SageMakerExampleRole.
--------------------------------------------------------------------------------
Setting up the Lambda function for the pipeline.
The Lambda function SageMakerExampleFunction already exists, do you want to update it?
n
Lambda ready with ARN arn:aws:lambda:us-west-2:1234567890:function:SageMakerExampleFunction.
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Setting up queue sagemaker-sdk-example-queue.
--------------------------------------------------------------------------------
Setting up bucket sagemaker-sdk-test-bucket.
Bucket sagemaker-sdk-test-bucket ready.
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Now we can create and run our pipeline.
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Setting up the pipeline.
Pipeline set up with ARN arn:aws:sagemaker:us-west-2:1234567890:pipeline/sagemaker-sdk-example-pipeline.
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Starting pipeline execution.
Run started with ARN arn:aws:sagemaker:us-west-2:1234567890:pipeline/sagemaker-sdk-example-pipeline/execution/1234567890.
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Waiting for pipeline to finish.After the pipeline has completed an execution, sample output is also displayed. Then interactive options guide you through cleaning up the resources.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
...
Status is Executing.
Status is Succeeded.
Pipeline finished with status Succeeded.
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Getting output results sagemaker-sdk-test-bucket-rlhagerm2.
Output file: outputfiles/abcdefgabcdef/results_0.csv
Output file contents:
-149.8935557,"61.21759217
",601,USA,"601 W 5th Ave, Anchorage, AK, 99501, USA",Anchorage,,99501 6301,Alaska,Valid Data
-149.9054948,"61.19533942
",2794,USA,"2780-2798 Spenard Rd, Anchorage, AK, 99503, USA",Anchorage,North Star,99503,Alaska,Valid Data
-149.7522,"61.2297
",,USA,"Enlisted Hero Dr, Jber, AK, 99506, USA",Jber,,99506,Alaska,Valid Data
-149.8643361,"61.19525062
",991,USA,"959-1069 E Northern Lights Blvd, Anchorage, AK, 99508, USA",Anchorage,Rogers Park,99508,Alaska,Valid Data
-149.8379726,"61.13751355
",2372,USA,"2276-2398 Abbott Rd, Anchorage, AK, 99507, USA",Anchorage,,99507,Alaska,Valid Data
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
The pipeline has completed. To view the pipeline and runs in SageMaker Studio, follow these instructions:
https://docs.aws.amazon.com/sagemaker/latest/dg/pipelines-studio.html
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Finally, let's clean up our resources.
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Clean up resources.
Delete pipeline sagemaker-sdk-example-pipeline? (y/n)
n
Delete queue https://sqs.us-west-2.amazonaws.com/1234567890/sagemaker-sdk-example-queue? (y/n)
n
Delete Amazon S3 bucket sagemaker-sdk-test-bucket? (y/n)
n
Delete Lambda SageMakerExampleFunction? (y/n)
n
Delete Role SageMakerExampleLambdaRole? (y/n)
n
Delete Role SageMakerExampleRole? (y/n)
n
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
SageMaker pipeline scenario is complete.
--------------------------------------------------------------------------------The following sections describe some primary features of this code example. This, and related information, can also be found within each language README within the GitHub repository.
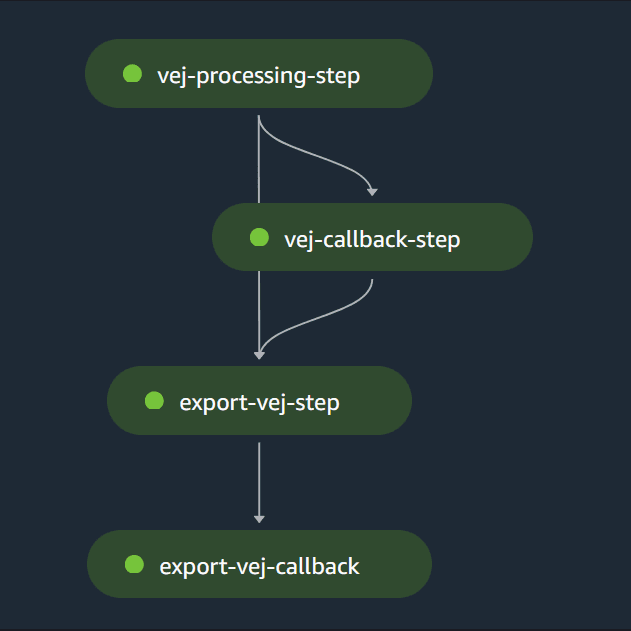
Pipeline steps define the actions and relationships of the pipeline operations. The pipeline in this example includes an AWS Lambda step
and a callback step.
Both steps are processed by the same example Lambda function.
and a callback step.
Both steps are processed by the same example Lambda function.
The Lambda function handler is included as part of the example, with the following functionality:
- Starts a SageMaker Vector Enrichment Job with the provided job configuration.
- Processes Amazon SQS queue messages from the SageMaker pipeline.
- Starts the export function with the provided export configuration.
- Completes the pipeline when the export is complete.
The example pipeline uses parameters that you can reference throughout the steps. You can also use the parameters to change
values between runs and control the input and output setting. In this example, the parameters are used to set the Amazon Simple Storage Service (Amazon S3)
locations for the input and output files, along with the identifiers for the role and queue to use in the pipeline.
The example demonstrates how to set and access these parameters before executing the pipeline using an SDK.
values between runs and control the input and output setting. In this example, the parameters are used to set the Amazon Simple Storage Service (Amazon S3)
locations for the input and output files, along with the identifiers for the role and queue to use in the pipeline.
The example demonstrates how to set and access these parameters before executing the pipeline using an SDK.
A SageMaker pipeline can be used for model training, setup, testing, or validation. This example uses a simple job
for demonstration purposes: a Vector Enrichment Job (VEJ) that processes a set of coordinates to produce human-readable
addresses powered by Amazon Location Service. Other types of jobs can be substituted in the pipeline instead.
for demonstration purposes: a Vector Enrichment Job (VEJ) that processes a set of coordinates to produce human-readable
addresses powered by Amazon Location Service. Other types of jobs can be substituted in the pipeline instead.
Using the AWS SDK, you can manage, execute, and update AWS SageMaker pipelines in your preferred programming language. Using pipeline parameters and steps alongside SDK actions, you can utilize the features of AWS SageMaker machine learning in a dynamic way that can be integrated into larger systems.
Check out the example code library for this and other detailed examples for your AWS services.
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.