My Event is Urgent than Yours: Prioritizing Event Processing with Apache Kafka
Apache Kafka doesn't support event processing prioritization. But you don't have to settle for this. Let's see how to solve this problem using the bucket priority pattern.
Ricardo Ferreira
Amazon Employee
Published Jun 9, 2023
Last Modified Mar 19, 2024
Event streams are growing in popularity among developers building data oriented architectures. Different from the brick-and-mortar batch architecture, event streams allow organizations to quickly act on the data, removing the barriers that often slow them down to innovate and differentiate. However, adopting event streams is not always easy. Many business processes were designed to think in data as this passive entity that just sits in data stores, waiting to be processed.
For example, think about how orders from customers are prioritized at the Amazon store. If an order is confirmed with same-day delivery, it should be processed faster than orders confirmed with less priority, right?. If we look at this business process from a batch-oriented lenses, we could have all the orders sitting in a data store such as Amazon Aurora, and have a scheduled AWS Lambda function that picks all the orders and prioritize them based on their delivery options. Then subsequent processes can simply process the orders as they are because they trust that the prioritization has been taken care of.
But what if we try to design the same process using event streams? One of the key characteristics of event streams is that data is always in motion, and they must be processed as they flow through the different processing layers. Because events are never actually parked anywhere, it is hard to think about ways to implement prioritization and ordering as they can come and go in different times. Design patterns like the Resequencer could be a potential solution, but ultimately it requires some sort of event parking and buffering to work. To make things a little harder, most event stores used to handle event streams treat each event as immutable. This means that their order cannot be changed. This is certainly the case of Apache Kafka, for example.
In this blog post, I will explain in more details why implementing event processing prioritization with Kafka is so difficult, but convince you that is not necessarily impossible. I will explain how to look at this technical problem from a different perspective and introduce you to a solution that may be useful for cases like this.
The first step to understand why implementing event processing prioritization with Kafka is difficult is by understanding its architecture. After all, Kafka's unique design differs from many messaging technologies that you may have worked with before. For instance, events in Kafka are organized into topics. Topics provide a simple abstraction such that as a developer, you work with an API that enables you to read and write data from your applications. Under the hood, it is actually a bit more nuanced than this; events are in fact written to and read from partitions.
Partitions play a critical role in making Kafka such a fast and scalable distributed system. Instead of storing all the data in a single machine, it automatically distributes the data over brokers in a cluster using a divide-and-conquer storage strategy. This is accomplished by breaking down topics into multiple parts (hence the name partition) and spreading those parts over the brokers. These partitions are used to store events in Kafka, allow parallel reads to speed up your event processing, and they also ensure that your data is not lost when brokers fail. If you need to understand more about partitions in Kafka before moving further, I recommend reading this other blog post I wrote, where I discuss them extensively.
But what do partitions even have to do with event processing prioritization? Well, quite a lot! First, because partitions are the unit of reading and write and how events are actually stored, you must keep this in mind while thinking about how to sort events in a given order. Events are spread over multiple brokers, so any implementation that you may come up with, such as implementing the Resequencer pattern, will have to first collect those events from the brokers to then sort them out. This makes the code extremely complex.
Kafka's consumer API certainly provides the means to accomplish this. The problem is that most of us don't want the hassle of having to keep track of where events are in order to process with them. Keeping track of events can be complicated when partitions are in constant movement—whether it is because of rebalancing, restoration from replicas, or just because someone increased the number of partitions. Writing code to keep track of events can easily become a nightmare, as you need to foresee virtually all scenarios that a complex distributed system like Kafka offers. In most cases, the code that you write to fetch events from topics will be a combination of
subscribe() and consumer.poll(), which requires no awareness whatsoever about partitions. Giving up this simplicity supersize the chances of creating code that is both hard to read and maintain.Another tricky part of implementing event processing prioritization with Kafka is how to handle high-load scenarios. Using a single consumer to process all events certainly works, but there will be a time where the rate of events being produced may surpass the rate of events being processed, and the consumer will certainly fall behind. Luckily, Kafka provides the concept of consumer groups. When multiple consumers are subscribed to a topic and belong to the same consumer group, each consumer in the group receives events from a different subset of the partitions on the topic.
Using consumer groups helps with high-load scenarios using a simple yet powerful construct. There is only one problem: All consumers within the consumer group will process the events with no notion of priority. This means that even if we add some information to each event, the consumers won't be able to use this information correctly because they will work on a different subset of partitions. Moreover, as these consumers may execute on different machines, so coordinating the execution of all of them will become by itself another distributed system problem to solve.
A naïve solution could be separating events by priority using different consumer groups. Events with higher priority would fall into one group, while events with less priority would fall into another group, and then each group could have a different number of consumers to work on them. However, this is not how Kafka works. Using different consumer groups won't split the events among the consumer groups. Instead, it will broadcast the same events to the different consumer groups.
In summary, Kafka's architecture makes it even harder to implement event processing prioritization. This may look like a bad thing at first, but it doesn't mean this is impossible. The next section is going to discuss a solution to this technical problem.
At this point, you must be convinced that sorting events is not the right way to implement event processing prioritization, given the limitations discussed in the previous section. But what if, instead of sorting events, we simply group them into different buckets as they are written? Events with higher priority would fall into one bucket while events with lower priority would fall into another. This eliminates the need to buffer events for the sake of sorting because now events are in specific buckets—each one with their own priority. Consumers can simply read from the buckets without worrying about sorting because the priority has been expressed in terms of grouping.
But how would you effectively implement prioritization? Each bucket could have different sizes. A higher-priority bucket could have a size that is bigger than the others and therefore fit more events. Also, higher-priority buckets could have more consumers reading events from it than others. So when these two approaches are combined, we can reasonably solve the problem of prioritization by giving priority buckets a higher chance of getting processed first.
Besides using the logic about bucket size and different number of consumers per bucket, another approach could be executing the consumers in an order that gives preference to higher-priority buckets first. With consumers knowing which buckets to work on, the consumers could be executed in an order that would first read from the buckets with higher priority. As these buckets become nearly empty, then the consumers of buckets with less priority would be executed.
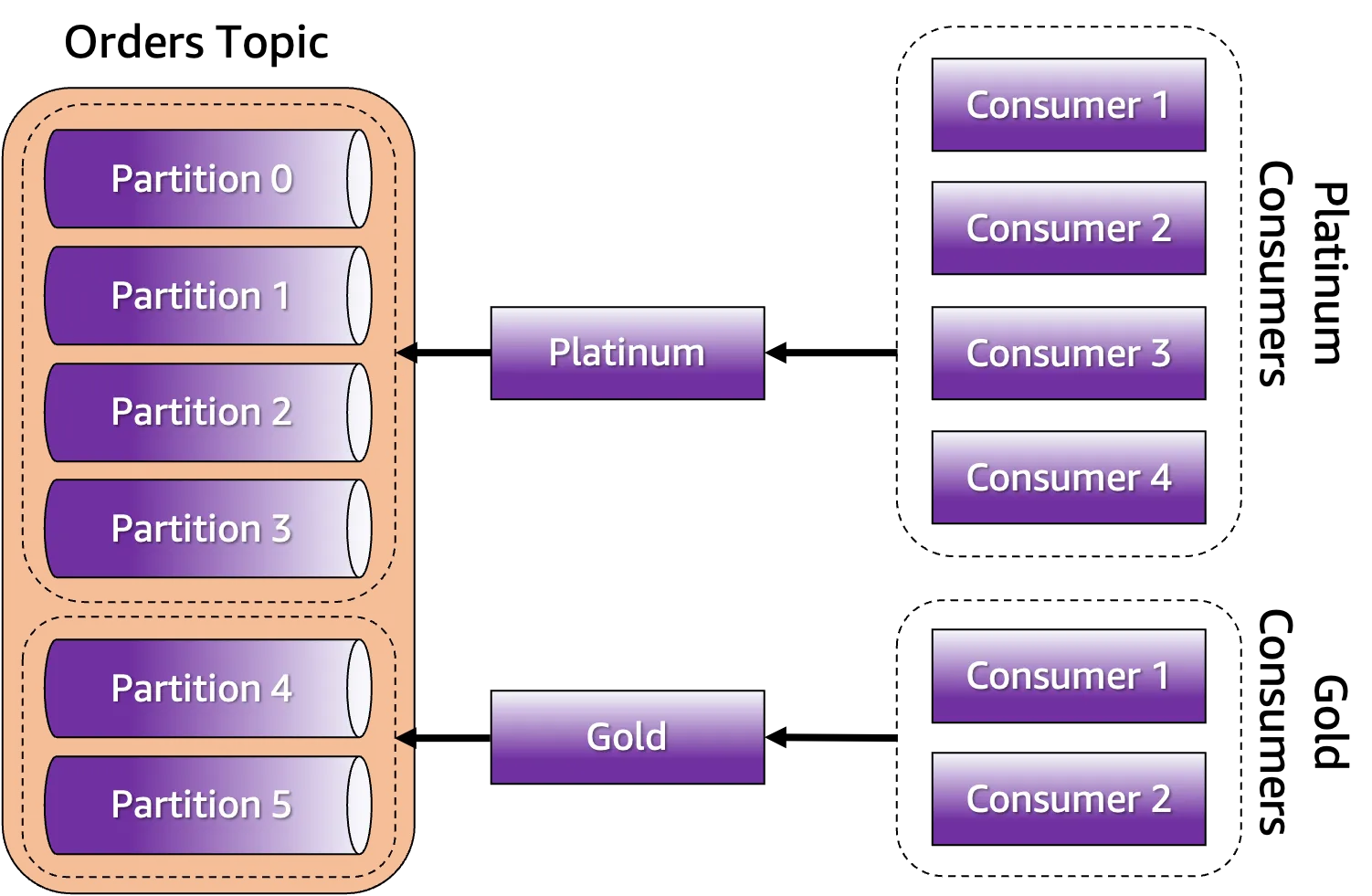
Figure 1 gives a summary about what has been discussed so far. There are two buckets: one called
Platinum and another called Gold. The Platinum bucket is obviously bigger than Gold and thus can fit more events. Also, there are four consumers working on the Platinum bucket, whereas there are only two consumers working on the Gold bucket. Conceptually, events in the Platinum bucket tend to be processed first and faster than any message ending up in the Gold bucket. If you need strict prioritization, meaning that events from the Platinum bucket must be executed before the ones from the Gold bucket, you can configure your consumers to execute in that respective order.
This is all great, but Kafka doesn't support the concept of buckets. Moreover, Kafka follows the smart endpoints and dump pipes principle, which means that the broker shouldn't be customized to implement buckets. This is technically not even possible. This has to come from the endpoints, notably the producer and consumer applications. We will discuss how can this be accomplished in the next section.
How can you change the behavior of your producer and consumer applications to implement the concept of buckets? Thanks to Kafka's client API pluggable architecture, there are ways to insert custom code in a declarative manner. On the producer side, there are the partitioners. This built-in concept is used behind the scenes by the Kafka producer to decide which partition to write the event to. Kafka provides a default partitioning logic, which is used natively when you execute your code unchanged. This is the reason you may not even be aware they exist. On the consumer side, there are the assignors. This is another built-in concept used behind the scenes by the Kafka consumer to decide how partitions will be assigned to consumers. Just like what happens with the producer, Kafka provides a default assignor. Again, you may be blissfully unaware that it even exists.
Both partitioners and assignors can be changed declaratively, which gives you a chance to change the way partitioning and assignment behave without forcing you to change your main code. But how can we come up with the concept of buckets? Well, buckets can simply be groups of partitions. A bucket can be composed of a certain number of partitions and, depending on this number, will express its size. A bucket can be deemed larger than others because it has more partitions belonging to it. In order for this to work, both the producer and the consumer need to share the same view about how many partitions each bucket will contain. We must express this sizing using a common notation.
Expressing in terms of numbers could work. For example, a topic with six partitions could be broken down into four partitions for a bucket with a higher priority and two partitions for a bucket with less priority. But what if someone increases the number of partitions on the topic? This would force us to stop the execution of our producers and consumers, change the configuration, and then re-execute them again. Not very practical. A better option would be to express the size of each bucket using a percentage. Instead of statically specifying the number of partitions for each bucket, we could say that the bucket with a higher priority has
70% of allocation and the bucket with a lower priority has 30%. In the previous example of the topic with six partitions, initially the bucket with a higher priority would have four partitions and the bucket with a lower priority would have two partitions. But if someone increases the number of partitions from six to twelve, for example, the bucket with a higher priority now would have eight partitions and the bucket with a lower priority would have four partitions.To make this work, the producer must use a custom partitioner. This partitioner must take data in the event key and decide which bucket to use, ultimately, deciding which partition to use. Using data from the event key allows developers to decouple their domain model design with a piece of data that is more tied to an infrastructure aspect of Kafka, such as partitioning.

Similarly, consumers must use a custom assignor. This assignor will take care of assigning consumers to the respective partitions belonging to the buckets they need to process. For instance, if there are four consumers interested in processing events from a certain bucket, then all partitions from that bucket must be distributed only to these consumers, regardless of which consumer groups they belong, which machines they are being executed, and even when a rebalance occurs. Figure 3 below shows what this looks like for the consumer.

In this GitHub repository, you can find an implementation of the bucket pattern I wrote. It contains a custom partitioner and a custom assignor, just like what we discussed here. In the following section, I will show how to use this implementation with an example.
It is time for you to get your hands dirty and experiment with this solution. As mentioned earlier, the complete implementation of the bucket priority is available on GitHub. Let's practice how to configure them with a ready to use example. To get a copy of the code, clone the repository containing the bucket priority pattern using the branch
build-on-aws-blog.1
git clone https://github.com/build-on-aws/prioritizing-event-processing-with-apache-kafka.git -b build-on-aws-blogThen, enter to the folder containing the code.
1
cd prioritizing-event-processing-with-apache-kafkaThis folder contains a Docker Compose file you can use to spin up a Kafka broker. To execute this broker, execute the following command:
1
docker compose up -dIt may take several seconds for the broker to start up, depending on your machine resources. To check if the broker is running and ready to be used, execute the following command:
1
docker ps -aIt should list a container called
kafka. Check if its status is set to healthy. If the broker is healthy, you can proceed.To play with the code, you must first build it. Since this code has been built with Java and Maven, you must have them installed in your machine. To build the code, execute the following command:
1
mvn clean packageA new folder called
target will be created. Inside this folder there will be a file named bucket-priority-pattern-1.0.0-jar-with-dependencies.jar, which contains the code of the bucket priority pattern, the example code, and all the dependencies required to execute this code properly.To play with this code, you will execute three different applications. Preferably, execute them in different terminals so you can follow up with the code execution. Let's start with the application that will continuously write events into a topic called
orders-per-bucket.Execute the following command.
1
java -cp target/bucket-priority-pattern-1.0.0-jar-with-dependencies.jar blog.buildon.aws.streaming.kafka.BucketBasedProducerThis is going to execute the producer application, that writes one event for each bucket, into the
orders-per-bucket topic. You should see an output like this:1
2
3
4
5
6
7
8
9
10
11
12
13
SLF4J: No SLF4J providers were found.
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See https://www.slf4j.org/codes.html#noProviders for further details.
Key 'Gold-1' was sent to partition 4
Key 'Platinum-2' was sent to partition 0
Key 'Gold-3' was sent to partition 5
Key 'Platinum-4' was sent to partition 1
Key 'Gold-5' was sent to partition 4
Key 'Platinum-6' was sent to partition 2
Key 'Gold-7' was sent to partition 5
Key 'Platinum-8' was sent to partition 3
Key 'Gold-9' was sent to partition 4
Key 'Platinum-10' was sent to partition 0In another terminal, execute the consumer application that will process all the events for the
Platinum bucket. The code for this application was written to simulate multiple concurrent consumers using threads. For this reason, you will specify how many threads you want to dedicate to this bucket.Execute the following command:
1
java -cp target/bucket-priority-pattern-1.0.0-jar-with-dependencies.jar blog.buildon.aws.streaming.kafka.BucketBasedConsumer Platinum 5You should see an output like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
SLF4J: No SLF4J providers were found.
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See https://www.slf4j.org/codes.html#noProviders for further details.
[Consumer-Thread-4] Key = Platinum-2, Partition = 0
[Consumer-Thread-3] Key = Platinum-4, Partition = 1
[Consumer-Thread-1] Key = Platinum-8, Partition = 2
[Consumer-Thread-4] Key = Platinum-10, Partition = 3
[Consumer-Thread-3] Key = Platinum-12, Partition = 0
[Consumer-Thread-2] Key = Platinum-14, Partition = 1
[Consumer-Thread-1] Key = Platinum-16, Partition = 2
[Consumer-Thread-4] Key = Platinum-18, Partition = 3
[Consumer-Thread-3] Key = Platinum-20, Partition = 0
[Consumer-Thread-2] Key = Platinum-22, Partition = 1
[Consumer-Thread-1] Key = Platinum-24, Partition = 2Note that, even though you specified that five threads must be created, only four of them are actually processing events. More on this later. In another terminal, execute the consumer application that will process all the events for the
Gold bucket.Execute the following command:
1
java -cp target/bucket-priority-pattern-1.0.0-jar-with-dependencies.jar blog.buildon.aws.streaming.kafka.BucketBasedConsumer Gold 5You should see an output like this:
1
2
3
4
5
6
7
8
9
10
SLF4J: No SLF4J providers were found.
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See https://www.slf4j.org/codes.html#noProviders for further details.
[Consumer-Thread-0] Key = Gold-13, Partition = 4
[Consumer-Thread-4] Key = Gold-15, Partition = 5
[Consumer-Thread-0] Key = Gold-17, Partition = 4
[Consumer-Thread-4] Key = Gold-19, Partition = 5
[Consumer-Thread-0] Key = Gold-21, Partition = 4
[Consumer-Thread-4] Key = Gold-23, Partition = 5
[Consumer-Thread-0] Key = Gold-25, Partition = 4Just like what happened with the consumer application processing the
Platinum bucket, the number of threads actually processing events differs from what you specified. In the command-line, you asked for five threads dedicated to the Gold bucket, but only two of them are processing events. Let's understand now why.For starters, the topic
orders-per-bucket was created with six partitions. The producer application is implemented using the Java class blog.buildon.aws.streaming.kafka.BucketBasedProducer. If you look at its code, you see that the first thing the code does is create the topic, using Kafka's admin API.1
2
3
4
public static void main(String[] args) {
createTopic(ORDERS_PER_BUCKET, 6, (short)1);
new BucketBasedProducer().run(getConfigs());
}After creating the topic, it will construct an instance of a
KafkaProducer<K,V> with a configuration that enables the bucket priority pattern.1
2
3
4
5
6
7
8
configs.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,
"code.buildon.aws.streaming.kafka.BucketPriorityPartitioner");
configs.put(BucketPriorityConfig.TOPIC_CONFIG, ORDERS_PER_BUCKET);
configs.put(BucketPriorityConfig.BUCKETS_CONFIG, "Platinum, Gold");
configs.put(BucketPriorityConfig.ALLOCATION_CONFIG, "70%, 30%");
try (KafkaProducer<String, String> producer = new KafkaProducer<>(configs)) {}This is where things get interesting. We have enabled the bucket priority pattern and configured how each bucket must be created. For the
Platinum bucket, it was configured to be created with 70% of the events allocation, and the Gold bucket was configured to be created with the remaining 30%. With this configuration in place, the producer application continuously creates one event for each bucket—determining which bucket to use via the event key.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
AtomicInteger counter = new AtomicInteger(0);
String[] buckets = {"Platinum", "Gold"};
for (;;) {
int value = counter.incrementAndGet();
int index = Utils.toPositive(value) % buckets.length;
String recordKey = buckets[index] + "-" + value;
ProducerRecord<String, String> record =
new ProducerRecord<>(ORDERS_PER_BUCKET, recordKey, "Value");
producer.send(record, (metadata, exception) -> {
System.out.println(String.format(
"Key '%s' was sent to partition %d",
recordKey, metadata.partition()));
});
try {
Thread.sleep(1000);
} catch (InterruptedException ie) {
}
}As you can see the output of the consumer applications, the events were properly written into the right partitions. Since the
orders-per-bucket was created with six partitions, the partitions [0, 1, 2, 3] were assigned to the Platinum bucket. This represents 70% of the events allocation. The partitions [4, 5] were assigned to the Gold bucket. This represents 30% of the events allocation.Now let's take a look at the consumer application code. The consumer application is implemented using the Java class
blog.buildon.aws.streaming.kafka.BucketBasedConsumer. If you look at its code, you see that during the bootstrap; the code instantiates one thread for each consumer of a bucket.1
2
3
4
5
6
7
private void run(String bucketName, int numberOfThreads, Properties configs) {
ExecutorService executorService = Executors.newFixedThreadPool(numberOfThreads);
for (int i = 0; i < numberOfThreads; i++) {
String threadName = String.format("Consumer-Thread-%d", i);
executorService.submit(new ConsumerThread(bucketName, threadName, configs));
}
}For each thread instantiated, a
KafkaConsumer<K,V> is created, also configured with the bucket priority pattern. The configuration is the same as the producer application, since both of them must agree on the percentages of each bucket. The remaining of the code is just plain-old Kafka consumer implementation. It continuously polls for new events, and process them as they arrive.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
private class ConsumerThread implements Runnable {
private String threadName;
private KafkaConsumer<String, String> consumer;
public ConsumerThread(String bucketName,
String threadName, Properties configs) {
this.threadName = threadName;
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
configs.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
configs.setProperty(ConsumerConfig.GROUP_ID_CONFIG, ORDERS_PER_BUCKET + "-group");
// Configuring the bucket priority pattern
configs.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,
"code.buildon.aws.streaming.kafka.BucketPriorityAssignor");
configs.put(BucketPriorityConfig.TOPIC_CONFIG, ORDERS_PER_BUCKET);
configs.put(BucketPriorityConfig.BUCKETS_CONFIG, "Platinum, Gold");
configs.put(BucketPriorityConfig.ALLOCATION_CONFIG, "70%, 30%");
configs.put(BucketPriorityConfig.BUCKET_CONFIG, bucketName);
consumer = new KafkaConsumer<>(configs);
consumer.subscribe(Arrays.asList(ORDERS_PER_BUCKET));
}
public void run() {
for (;;) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(Integer.MAX_VALUE));
for (ConsumerRecord<String, String> record : records) {
System.out.println(String.format("[%s] Key = %s, Partition = %d",
threadName, record.key(), record.partition()));
}
}
}
}As you can see, very little was changed in the code to implement event processing prioritization with Kafka. Apart from the event keys that had to be customized so the producer application would know which bucket to use, the code is the same to every Kafka application ever written. Everything related to the bucket priority pattern was configured via properties, so they can externalized and attached to existing applications.
Event processing prioritization with Kafka is one of the most popular topics discussed in social communities, like Stack Overflow. However, because of Kafka’s architecture and design principles, there is no out-of-the-box feature to support it. This post explained why Kafka doesn’t support event prioritization and also presented an alternative for this in a form of a pattern that uses the concept of custom partitioning and assignors.
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.