Automating Multiple Environments with Terraform
How to manage a central main account for shared infrastructure with a dev, test, and prod account.
Cobus Bernard
Amazon Employee
Published Mar 27, 2023
Last Modified Mar 19, 2024
(Cover image generated with Amazon Bedrock)
As teams grow, so does the complexity of managing and coordinating changes to the application environment. While having a single account to provision all your infrastructure and deploy all systems works well for a small group of people, you will probably hit a point where there are too many people making changes at the same time to be able to manage it all. Additionally, with all your infrastructure in a single account, it becomes very difficult to apply the principle of least privilege (according to which persons or services should have the minimum permissions to accomplish their intended task), not to mention the naming convention of resources.
This tutorial will guide you in splitting your infrastructure across multiple accounts by creating a
main account for all common infrastructure shared by all environments (for example: users, build pipeline, build artifacts, etc.), and then an environment account for the three stages of your application: dev, test, and prod. These environments will help you support a growing team and create clear separation between your different environments by isolating them into individual AWS accounts. The approach will make use of Terraform, Amazon CodeCatalyst, and assuming of IAM roles between these accounts. It is an evolution of my 2020 HashTalks session. We will address the following:- How to split our infrastructure between multiple accounts and code repositories
- How to set up a build and deployment pipeline to manage all changes in the environment account with Terraform
- How to keep
dev,test, andprodinfrastructure in sync without needed to copy files around
| About | |
|---|---|
| ✅ AWS experience | 300 - Advanced |
| ⏱ Time to complete | 60 minutes |
| 💰 Cost to complete | Free tier eligible |
| 🧩 Prerequisites | - AWS Account - CodeCatalyst Account - Terraform 1.3.7+ - (Optional) GitHub account |
| 💻 Code | Code sample used in tutorial on GitHub |
| 📢 Feedback | Any feedback, issues, or just a 👍 / 👎 ? |
| ⏰ Last Updated | 2023-03-07 |
As a first step, we need to set up a CI/CD pipeline for all the shared infrastructure in our
main account. We will be using the approach from the Terraform bootstrapping tutorial. Please note, we won't be covering any of the details mentioned in that tutorial. We are just following the steps, if you would like to understand more, we recommend working through that tutorial first. You can continue with this tutorial after finishing the bootstrapping one, just don't follow the cleanup steps - just skip to the next section. Here is a condensed version of all the steps.To set up our pipeline, make sure you are logged into your AWS and CodeCatalyst accounts to set up our project, environment, repository, and CI/CD pipelines. In CodeCatalyst:
- Create a new Project called
TerraformMultiAccountusing the "Start from scratch" option - Create a code repository called
main-infrain the project, using Terraform for the.gitignore file - Link an AWS account to our project via the CI/CD -> Environments section with the name "MainAccount"
- Create a Dev environment using Cloud9 under CI/CD -> Environments, and cloning the
main-infrarepository using themainbranch - Launch the
dev environment, and configure the AWS CLI usingaws configurewith the credentials of an IAM user in your AWS account
We first need to bootstrap Terraform in our account, please follow these steps in your Cloud9 dev environment's terminal:
For the next commands, please run them in the
main-infra directory:We will now create the required infrastructure to store our state file using Amazon S3 as a backend, Amazon DynamoDB for managing the lock to ensure only one change is made at a time, and setting up two IAM roles for our workflows to use. Edit
variables.tf and change the state_file_bucket_name value to a unique value - for this tutorial, we will use tf-multi-account - you should use a different, unique bucket name. We need to initialize the Terraform backend, and then apply these changes to create the state file, lock table, and IAM roles for our CI/CD pipeline. If you would like to use a different AWS region, you can update the aws_region variable with the appropriate string. Run the following commands for this:We now have our resources tracked in a state file, but it is stored locally in our Dev environment, and we need to configure it to use the S3 backend. We first need to add a backend configuration, and then migrate the state file to it. Use the following command to add it:
Edit
_bootstrap/terraform.tf and change the bucket key to the name of your bucket - Terraform variables cannot be used in backend configuration, so this needs to be done by hand. If you changed the region being used in the provider block, please also update the region key in terraform.tf. We are now ready to migrate our state file to the S3 bucket by running the following:Next, we need to allow the two new IAM roles access to our CodeCatalyst Space and projects. In your Space, navigate to the
AWS accounts tab, click your AWS account number, and then on Manage roles from the AWS Management Console. This will open a new tab, select Add an existing role you have created in IAM, and select Main-Branch-Infrastructure from the dropdown. Click Add role. This will take you to a new page with a green Successfully added IAM role Main-Branch-Infrastructure. banner at the top. Click on Add IAM role, and follow the same process to add the PR-Branch-Infrastructure role. Once done, you can close this window and go back to the CodeCatalyst one.Lastly, we need to create the workflows that will run
terraform plan for all pull requests (PRs), and then terraform apply for any PRs that are merged to the main branch. Run the following commands:Now edit
.codecatalyst/workflows/main_branch.yml and .codecatalyst/workflows/pr_branch.yml, replacing the 111122223333 AWS account ID with your one. In terraform.tf, change the bucket value to match your state file bucket created earlier, and optionally region if you are using a different region - this should match the region you used in the _bootstrap/terraform.tf backend configuration as we are using the same bucket. You can change the aws_region variable in variables.tf to set the region to create infrastructure in. Finally, we need to commit all the changes after making sure our Terraform code is properly formatted:Navigate to
CI/CD -> Workflows and confirm that the main branch workflow MainBranch is running and completes successfully. We now have the base of our infrastructure automation for a single AWS account. Next, we will set up additional environment accounts.Similar to the bootstrapping of the base infrastructure, we need to bootstrap the three new AWS account for our
dev, test, and prod environments. We will use our main-infra repository to manage this for us. Since we already have a bucket for storing state files in, we will use the same one, but change the key in the backend configuration block for our environment accounts to ensure we don't overwrite the current one. As we will be using different AWS accounts, we need a mechanism for our workflows to be able to access them. We will be using the IAM role assume functionality. This works by specifying that our main account may assume the roles in our environment accounts, and only perform actions as defined by this role. These actions are defined in a trust policy that is added to the IAM roles. We then add an additional policy to our existing IAM workflow roles in our main account allowing them to assume the equivalent role in each environment account. This means that the pull request (PR) branch role can only assume the PR branch role in each account to prevent accidental infrastructure changes, and similarly the main branch role can only assume the equivalent main branch role. The diagram below visualizes the process: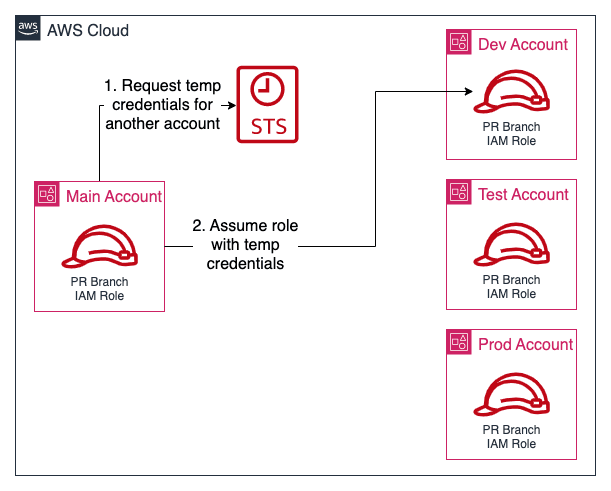
We need to create and modify the following resources:
- New AWS accounts: We will create three new accounts using AWS Organizations
- New IAM roles: Provides the roles for our workflow to assume in the environment accounts - one for the
mainbranch, one for any pull requests (PRs), with a trust policy for access from ourmainaccount. - New IAM policies: Set the boundaries of what the workflow IAM roles may do in the environment account - full admin access for
mainbranch allowing creation of infrastructure,ReadOnlyfor the PR branches to allow validating any changes - IAM policies: One each for the
mainand PR branch roles allowing them to assume the equivalent IAM role in environment accounts - IAM roles: Add the policy to assume the new environment account IAM roles
To do this, add the following to the
variables.tf file in the root of main-infra to define the three email addresses we will use to create child accounts, and also the name of the IAM role to create to allow access to the account. This IAM role is created in each of the environment accounts with admin permissions, and can be assumed from the top-level account. We will be setting up additional IAM roles for our workflows in the environment accounts further down.💡 Tip: You can use+in an email address to set up additional, unique email strings that will all be delivered to the same email inbox, e.g. if your email isjohn@example.com, you can usejohn+aws-dev@example.com. This is useful as each AWS account needs a globally unique email address, but managing multiple inboxes can become a problem.
Create a new file called
aws_environment_accounts.tf to create the accounts using AWS Organizations, and also to add them to OUs (Organizational Units) - this is a useful way to organize multiple AWS accounts if you need to apply specific rules to each one. Add the following to the file:💡 Tip: If you are applying this strategy to existing AWS accounts and using the import function of Terraform, take note of the instructions on how to avoid recreating the account when importing in the resource page. You will also need to import the AWS Organization if you already one set up in your account by runningterraform import aws_organizations_organization.org 111122223333, and replacing the number with your AWS account ID.
Let's look at these changes and then apply them by running
terraform init first, and then terraform plan in your CodeCatalyst environment's terminal. (Please note: If you are following on from the previous tutorial, you can still run these steps, it will not cause any issues):The proposed changes should be similar to this list:
Now go ahead and apply them with
terraform apply:While running the
apply, or shortly after, you will start to receive the welcome emails from the new accounts. There will be a mail with the subject AWS Organizations email verification request that you need to look out for, and click the Verify email address if this is the first time you are using an AWS Organization in your account.You may be wondering why we are running these commands directly instead of using our workflow we set up earlier. The reason is that we will be making quite a few changes to the
While you could do this with pull requests, it will add quite a bit of time for a process you should only be doing once.
main-infra repo to set up the environment accounts where we need to apply the changes before we can move on to the next set.While you could do this with pull requests, it will add quite a bit of time for a process you should only be doing once.
Next, we need to create the IAM roles and policies in the new accounts, and update our existing IAM roles with additional policies to allow them to assume these new roles in the environment accounts. First, we need to define additional
AWS providers to allow Terraform to create infrastructure in our new accounts. Terraform provider aliases allow you to configure multiple providers with different configurations. In our case, we will create the default provider to use our Main account, and then set up 3 additional ones for dev, test, and prod, and use IAM role switching to access them. We will use the IAM role created as part of our new accounts to do this. Add the following to the providers.tf file in the root of main-infra - since we created the new AWS accounts using Terraform, we can reference the account IDs via those resources:Now that we can access the environment accounts with these new providers, we need to also create IAM roles for the
main and PR branches inside each account for our workflows to use, as well as a read-only one for all users. This will ensure that the ReadOnly role we use for PR branches in the main account can only assume the equivalent ReadOnly role in each of the environment accounts, the AdministratorAccess one the same in each one, and the a ReadOnly role for our team members in each of the environment accounts - they should not be changing anything by hand via the AWS Console, AWS CLI, or API calls. To add these roles in each account, run the following commands:The contents of each file that we downloaded should be the following:
We are creating a default, read-only role for users (developers, DevOps/SRE teams, etc) to use as all changes should be via Terraform, but we need to provide them with access to look at the console. We'll be setting up the users further down. The IAM roles above will look very similar to the original ones we created, but with the trust policy changed to allow assuming these roles from our
main-infra account instead of being assumed by the CodeCatalyst task runner - the runner will assume a role in the main account, and from there assume another role in each of our environment accounts.We also don't need to specify the main account's AWS account ID as we can use the
aws_organizations_organization data source to do the lookup for us.You will notice that the read-only roles do not have permission to access the S3 state file bucket, DynamoDB table for locks, or KMS key for state file encryption. There will be two roles at play in our workflows, the base IAM role that the workflow runs with, and then the role we specify in the
AWS provider. We configure our Terraform backend without specifying the role, so it will use the one supplied by the workflow, whereas the AWS providers for each account (that creates the resources) uses the role we specify in each of the provider configurations. This allows the state files to be updated without additional permissions inside each environment account as the state isn't stored in the environment accounts, but inside our main-infra account. We will use this same approach when setting up our new environments-infra repository further down.We can now add our new IAM roles by running
terraform apply, you should see 12 new resources to add. After adding them, we need to set up IAM roles for our developers to use in the different environment accounts. Before we continue, let's commit our changes to ensure we don't lose them accidentally:We have everything in place now to start adding infrastructure to our environment accounts, and need to create a new repository to store any infrastructure in. While we could use the
main-infra account to do this, we treat that as a sensitive repository since it controls all the infrastructure we need to manage our AWS accounts, and want to limit access to it. We will use a new repository called environments-infra to manage the day-to-day infrastructure. First, create a new repository in CodeCatalyst under Code -> Source repositories by clicking the Add repository button. Use environments-infra for the name, Manages the dev, test, and prod accounts' infrastructure. for the description, and select Terraform for the .gitignore file. Once created, click on the Clone repository button, then on the Copy button to copy the git clone URL:
The Dev environment is configured to use the AWS CodeCommit credentials helper, you can leave it as-is and generate a Personal access token to use from the
Clone repository dialog we just used, or edit ~/.gitconfig and change the credentials helper under [credential] from helper = !aws codecommit credential-helper $@ to helper = /aws/mde/credential-helper. This enables you to clone CodeCatalyst repositories without needing to specify a Personal access token every time.To clone the new repo, in your terminal, change to the
/projects directory to clone the environments-infra repo, and then type git clone , and paste the URL from the dialog (yours will be different based on your user alias, Space, and Project name):If you didn't change the credentials helper, it will now prompt you for a password, in the
Clone repository dialog in CodeCatalyst, use the Create token button, and then click on the Copy button next to it, and paste that into the terminal as your password:We need to define a backend for environment accounts first, please create
terraform.tf in the environments-infra with the following - it is the same as for the main-infra repo, except we changed the key by adding in -enviroments:Let's confirm the backend configuration is correct by initializing Terraform by changing into the
environment-infra directory, and then running terraform init:We will use
variables.tf again to manage our variables, this time in the environments-infra directory, and the first ones we need to add is aws_region and tf_caller - we will be using the aws_caller_identity data source to determine who is calling terraform plan and using the appropriate role for a user vs our workflows. Create variable.tf with the following content:We default the IAM role to
User and add an environment variable to our workflows to indicate if we are running for the main branch (and need permissions to create/updated/delete infrastructure) using a role with AdministratorAccess, or if it is a pull request, and only needs ReadOnly access.Next, we will create
providers.tf to configure our provider to use in a one of environment accounts, and we need to provide the AWS account ID. Previously, we were able to reference them directly via the aws_organizations_account resource, and we created a provider per AWS environment account. The aws_organizations_account resource is not referenceable as it is not managed in this repo, so we need a different solution. We will use Terraform's data source to do a lookup of the AWS Organization accounts, and store the values in a local value using an aliased 2nd AWS provider that uses the credentials in which the command is run. When it is in a workflow, this will be the IAM role of that workflow, and for a user, their IAM user. We will also not be configuring a provider per account, instead we will configure the default AWS provider, and change the account based on which Terraform Workspace is selected - we'll cover workspaces in the next section. This is why it is important to keep our workspace names the same as our environment names.Add the following to the
providers.tf file:Before we can test that everything is working, we need to cover Terraform Workspaces, and how we will be using them.
A Terraform Workspaces allows you to store the state file associated with that workspace in a different location, allowing you to reuse the same infrastructure definition for multiple sets of infrastructure. To clarify, we will be creating a single folder with Terraform files, but applying those to our three environments, and each one will need to store the state file independently so we don't overwrite the state by using the same backend configuration. Workspaces simplify this for us as it will change the location of the state file defined in our backend relative to the workspace name. To use this, we will name our workspaces the same as our environments by running the following commands:
You should see the following output:
We now have the ability to create and store the infrastructure state, but since we are using a single repo to store the infrastructure definition for all three of our environment accounts (dev, test, prod), we need a way to provide different configurations. The approach is to ensure that the infrastructure is the same in all three, but the quantities and sizes are different. We will use a variable definition file per environment to do this to store the values. To illustrate how we will use this further down in this guide, let's create the empty files and set up the rest of our CI/CD pipeline first. Run the following commands to create the empty variable files:
To use these, we would define a new variable in
variable.tf, and set different values based on the environment account in each file. These would be a key=value pair added to each of the .tfvars files corresponding with the variable name. As an example, if we needed a variable called db_instance_size, we could set db_instance_size=db.t3.micro in dev.tfvars, db_instance_size=db.m5.large for test.tfvars, db_instance_size=db.m5.8xlarge for prod.tfvars, and then include the .tfvars file with the plan or apply commands:One snag here: we didn't make sure we had the correct Terraform Workspace selected. To ensure that, we would need to run the following:
While this solves handling multiple environments, this is a lot of typing, or copy-pasting to do, and we need to hope (really hard) that someone doesn't make a mistake by combining the wrong variable file with an environment, for example:
This would use the
prod environment's values on the dev one. Luckily, there is a way to make it simpler and safer for people to use this approach.We will be creating a Makefile to wrap our commands and provide a single command for
init, plan, and apply. Create a Makefile (no file extension) in the root of the project with the following command:Our
Makefile should have the following content - please note that tabs and not spaces are required for indentation:Let's take a look at the commands and syntax used in the
Makefile:.PHONY:makeis intended to compile file, and it will fail if we ever create a file calledplan,apply, ordestroy. Using.PHONYaddresses this - you can read more in the GNU documentation for make@: prefixing a command with@tellsmaketo not print the command before running it-: by also adding-to a command, it tellsmaketo continue even if it fails, more on this below$(call check_defined, ENV ...: calls the function defined at the bottom of the file to ensure theENVenvironment variable is set, it will exit with an error if it is not specified.
When looking at the different targets (
validate, plan, apply, destroy), you will see that we call init, workspace new, and workspace select every time, and may wonder why would we do this if it is only needed once? The reason is to avoid depending on running steps in certain sequence, whether this is in the workflow, or for a new team member that has just onboarded. While it takes a bit longer to run, it avoids issues if people forget to follow the required steps.This now allows us to run
terraform plan with the correct Workspace and .tfvars file using the following:It is recommended to test the
Makefile now by running ENV=dev make plan - if you get an error, please ensure that you use tabs to indent the lines, not spaces. We are now ready to set up our workflows for our main and PR branches to test and apply changes to our infrastructure. The output should have the following:For subsequent runs, you will notice there is an error in the output highlighted in red, this is normal due to how we set up our
Makefile to always run the terraform workspace new command with each run, and can be safely ignored.Similar to before with the
Main-Infra repository, we will be creating a workflow to trigger on changes to the main branch to apply changes to our infrastructure, and then also one for any new pull request opened to run plan to ensure there aren't any errors. Let's create the workflows using the following commands:Here is the content of each file:
To use these workflows, please update the AWS Account Id from
111122223333 to your one in both of these files.Before we commit and push all the changes to kick off the workflows, we first need to include our
*.tfvars files. As you will see in the comment in the file, it is generally not recommended as the typical use-case for them is developer / local specific overrides. In our case, we want them to be maintained in version control, so we will be adding them with the -f flag to force git to add them. Any future changes will be picked up by git, but any new ones that are added will still be ignored, providing a way for users to still use them locally. Use the following to add them in the environments-infra directory:We now have all the base setup completed, let's commit all the changes, and then continue. Run the following:
You can now navigate to
CI/CD -> Workflows, and then select All repositories in the first dropdown. You should see four build jobs, a main and PR branch for both Main-Account and Environment-Accounts.Now that we have everything set up, let's create a VPC in each of our environment accounts. First, let's create a branch to work on and use our PR workflow to test. In the
environments-infra repo, run the following:We will be using the
terraform-aws-modules/vpc/aws module to help us, create a new file vpc.tf, and add the following to it:We will need to add the two new variables used,
vpc_cidr and public_subnet_ranges, so let's add them to our variables.tf:Lastly, we need to set the values for the two new variables in each of the environment
tfvars files. We will be using different IP ranges for each accounts to show the difference, but it is also good practice if you intent to set up VPC peering between them at some point - you cannot have overlapping IP ranges when using peering. Add the following to each of the .tfvars files - the content is split with a tab per file below:We will now commit the VPC changes to our branch, and then create a new PR:
Navigate to
Code -> Source repositories, click on environments-infra, and then on the Actions dropdown, selecting Create pull request. Set the Source branch to add-vpc, and the Destination branch to main, and add a descriptive Pull request title and Pull request description. Once created, navigate to CI/CD, Workflow, and select All repositories in the first dropdown. You should see the workflow for Environment-Account-PR-Branch for the add-vpc branch running under Recent runs. You can click on it to watch the progress. Once all the steps have completed successfully, expand the ENV=dev make plan step to view the output of the plan step - it should show you the proposed infrastructure to create the VPC. Similarly, you will see the test and prod infrastructure in each of their respective steps.
Once you have reviewed the changes, merge the PR by navigating to
Code, Pull requests, and then clicking on the PR. Finally, click the Merge button, and accept the merge. You can now navigate to CI/CD, Workflows, and again select All repositories from the first dropdown, then select the currently running workflow for the Environment-Account-Main-Branch on the main branch under Recent runs. It should complete successfully, and create a VPC in each account.We have now reached the end of this tutorial, and you can either keep the current setup and expand on it, or delete all the resources created if you are not. To clean up your environment, we will follow the following steps:
- In
environments-infra, rungit checkout mainandgit pullto ensure you have the latest version, then:- Edit
providers.tfand change therole_arnvalue in theawsprovider from"arn:aws:iam::${local.account_id}:role/${local.iam_role_name}"to"arn:aws:iam::${local.account_id}:role/Org-Admin"- since we restricted the developer role to be read-only, we need to use the administrator role created as part of setting up these accounts ENV=prod make destroyand confirm to delete all the resources in theprodenvironmentENV=test make destroyand confirm to delete all the resources in thetestenvironmentENV=dev make destroyand confirm to delete all the resources in thedevenvironment
- In
main-infra, rungit checkout mainandgit pullto ensure you have the latest version, then:- Run
terraform destroyand confirm. - Edit
_bootstrap/state_file_resources.tfto replace theaws_s3_bucketresource with:
Finally, run
cd _bootstrap && terraform destroy - this will error as you are removing the S3 bucket and the DynamoDB table during the run and it tries to save the state afterwards, but the resources no longer exists.Congratulations! You've now set up a multi-AWS environment CI/CD pipeline using Terraform with CodeCatalyst, and can deploy any infrastructure changes using a pull request workflow. If you enjoyed this tutorial, found any issues, or have feedback for us, please send it our way!
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.