Build Your Own Knowledge Base with Multilingual Q&A Powered by Generative AI
Use Amazon Kendra, Amazon Translate, Amazon Comprehend and Amazon SageMaker JumpStart to build a multilingual knowledge base that can summarize search results.

Fig 1. Create an Amazon Kendra Index.
Part 1 - Build the Smart Database with Amazon Kendra 🤖
Fig 2. Create an Amazon Kendra Index.
Fig 3. add a data source to an Index.
Part 2 - Searching an Amanzon Kendra Index
Fig 4. Search in a Kendra Index.
Part 3 - Add Multilingual Features 🤖🌎: Detect the Language of the Text and Translate It
Fig 5. Amazon Kendra answer result in spanish.
Part 4 - Create ENDPOINT to Invoke Generative AI Large Language Models (LLMs) 🚀
Part 5 - Summarize Answers Using the LLM
Fig 6. Amazon Kendra answer summarized results in spanish.
Organizations often accumulate a wide range of documents, including project documentation, manuals, tenders, Salesforce data, code repositories, and more. Locating specific documents and then conducting searches within them amid this vast amount of information can be a tedious. What's more, once you find the desired document, it may be lengthy, and you might prefer a summary of its content.
Web applications that summarize information might seem like a simple solution, but using them could mean sharing your organization's sensitive information!
Luckily, there are better solutions. In this tutorial, we will build a comprehensive knowledge base using multiple sources. With this knowledge base you can seek answers to your queries and receive concise summaries along with links for further study. To ensure accessibility, we will facilitate this process through a convenient question-and-answer format available in multiple languages.
- How to set up an intelligent search service powered by machine learning with Amazon Kendra.
- How to utilize pretrained open-source Generative AI Large Language Models (LLMs).
- How to use Artificial Intelligence service to detect the dominant language in texts.
- How to use Artificial Intelligence service to translate text.
We are going to build the solution in Amazon SageMaker Studio, where we can interact with AWS services from the same account without the need for additional credentials or security configurations, using the SageMaker Identity and Access Management Execution Role.
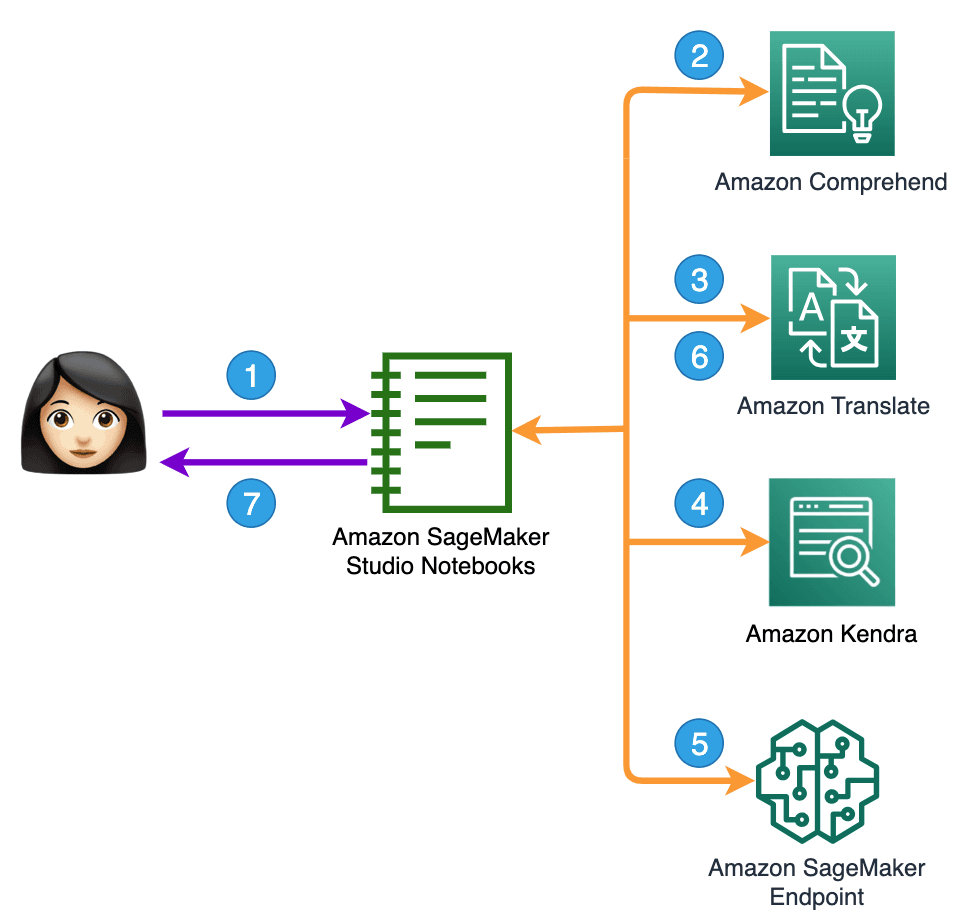
Fig 1. Create an Amazon Kendra Index.
In Fig 1 you can see what the solution consists of:
The user asks the question.
The language in which the query is made is detected using Amazon Comprehend.
Using Amazon Translate, the question is translated into the data soruce language.
The intelligent knowledge base is consulted.
Use Amazon Kendra's answer and user question to ask the LLM for a summarized and improved answer.
The answer is translated into the language of the question.
Provide the summary answer and the source where it can be expanded.
We will build it in five parts:
- Part 1 - Build the smart database with Amazon Kendra, using the sample data.🤖
- Part 2 - Queries to an index in Amazon Kendra.
- Part 3 - Add multilingual features 🤖🌎: detect the language of the text and translate it.
- Part 4 - Create ENDPOINT to invoke Generative AI Large Language Model (LLM) 🚀.
- Part 5 - Summarize answer using the LLM.
- Part 6 - 🚨Delete resources🚨.
Let’s get started!
Kendra is an intelligent search service powered by machine learning, where you can add, update, or delete automatically synchronize multiples data source, and also index web pages by providing the URLs to crawling.
First you need to create a Kendra Index, to hold the contents of your documents and structure them in a way to make the documents searchable. Follow the steps to create a Kendra Index in the console here.

Fig 2. Create an Amazon Kendra Index.
Once the Index is Active, add a data source to an Index (Fig. 3), select Add data source and then select Add dataset, add a name and select English(en) in Language.

Fig 3. add a data source to an Index.
At the end of the data synchronization, you will have the knowledge base ready for queries.
Here you can see more ways to upload sources to Kendra.
🚨Note: You can get started for free with the Amazon Kendra Developer Edition, that provides free usage of up to 750 hours for the first 30 days, check pricing here.
To search an Amazon Kendra index, you use the Retrieve API and it returns information about the indexed documents of data sources. You can alternatively use the Query API. However, the Query API only returns excerpt passages of up to 100 token words, whereas with the Retrieve API, you can retrieve longer passages of up to 200 token words.
Amazon Kendra utilizes various factors to determine the most relevant documents based on the search terms entered. These factors include the text/body of the document, document title, searchable custom text fields, and other relevant fields.
Additionally, filters can be applied to the search to narrow down the results, such as filtering documents based on a specific custom field like "department" (e.g., returning only documents from the "legal" department). For more information, see Custom fields or attributes.
You can make search the Amazon Kendra Index in several ways.
Go to the navigation panel on the left, choose the Search indexed content option, then enter a query in the text box and press enter (Fig. 4).

Fig 4. Search in a Kendra Index.
To search with AWS SDK for Python(Boto3) use this code:
1
2
3
4
5
6
7
8
9
import boto3
kendra_client = boto3.client("kendra")
def QueryKendra(index_id,query):
response = kendra_client.retrieve(
QueryText = query,
IndexId = index_id)
return response
You can also search with AWS SDK for Java and Postman.
In this segment, you will use two AI/ML services that you can use with an API call:
Amazon Comprehend, to detect the dominant language in which the question is asked, using DetectDominantLanguage from Boto3 Comprehend client
Amazon Translate, to translate the question to the language of the Kendra knowledge base (English in this case) and translate the answer back to the language of the original question, using TranslateText from Boto3 Translate client.
The TranslateText API needs the following parameters:
- Text (string): The text to translate.
- SourceLanguageCode (string): One of the supported language codes for the source text, if you specify auto, Amazon Translate will call Amazon Comprehend to determine the source language.
- TargetLanguageCode (string): One of the supported language codes for the target text.
This is the function we will use to perform the translation:
1
2
3
4
5
6
7
8
9
10
11
12
13
import boto3
translate_client = boto3.client('translate')
def TranslateText(text,SourceLanguageCode,TargetLanguage):
response = translate_client.translate_text(
Text=text,
SourceLanguageCode=SourceLanguageCode,
TargetLanguageCode=TargetLanguage
)
translated_text = response['TranslatedText']
source_language_code = response['SourceLanguageCode'] #you need SourceLanguageCode to answer in the original language
return translated_text, source_language_code
If you want to know more about these services as API calls, you can visit this blog: All the things that Comprehend, Rekognition, Textract, Polly, Transcribe, and Others Do.
🚨Note: Amazon Translate and Amazon Comprehend have Free Tier for up 12 months. Check pricing here and here.
To know the language code for documents in the data source in Amazon Kendra, you use Describe Data Source API:
1
2
3
4
5
6
def get_target_language_code(data_source_id,index_id):
response_data_source = kendra_client.describe_data_source(
Id = data_source_id,
IndexId = index_id
)
return response_data_source['LanguageCode']
🥳 The code of the multilingual Q&A intelligent knowledge base is:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
text = "¿que es Amazon S3?"
index_id = "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"
data_source_id = "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"
target_language_code = get_target_language_code(data_source_id,index_id)
query,source_language_code = TranslateText(text,"auto",target_language_code)
response = QueryKendra(index_id,query)
#print the result
for query_result in response["ResultItems"]:
print("-------------------")
document_title = query_result['DocumentTitle']
document_title_translated,language = TranslateText(document_title,target_language_code,source_language_code)
print("DocumentTitle: " + document_title_translated)
document_content = query_result['Content']
document_content_translated,language = TranslateText(document_content,target_language_code,source_language_code)
print("Content: ",document_content_translated)
print("Go deeper: ", query_result['DocumentURI'])
Amazon Kendra delivers a list of answers, which could be big (Fig. 5). Wouldn't a summarized result be better?

Fig 5. Amazon Kendra answer result in spanish.
In this part you are going to use Amazon SageMaker JumpStart, which provides pre-trained, open-source models for a wide range of problem types (including our summarization problem) to help you get started with machine learning. The best part is that you can also access models using the SageMaker Python SDK.
To summarize, you will use Flan UL2 fundamental model, a Text2Text Generation model based on the FLAN-T5 architecture, a popular open-source LLM, for:
- Text summarization
- Common sense reasoning / natural language inference
- Question and answering
- Sentence / sentiment classification
- Translation (at the time of writing this blog, between fewer languages than Amazon Translate)
- Pronoun resolution
👷🏻♀️🧰 Now let's start working with it:
| 1. Open the Amazon Sagemaker console |  |
| 2. Find JumpStart on the left-hand navigation panel and choose Foundation models. |  |
| 3. Search for a Flan UL2 model, and then click on View model. |  |
| 4. Open notebook in Studio |  |
| 5. Create a Sagemaker Domain using Quick setup, this takes a few minutes⏳... or Select domain and user profile if you already have one created. |   |
| 6. Follow the steps in jupyter notebook, explore it, and wait for me in step 5 |  |
In the jupyter notebook you can explore the functionalities of the FLAN-T5 model.
Go to part 3 in jupyter notebook to deploy a sagemaker endpoint. This is the call to do real-time inference to ML model as an API call, using Boto3 and AWS credentials.
You can get the Sagemaker Endpoint in two ways:
1
model_predictor.endpoint_name
- Console:
Find Inference on the left-hand navigation panel and choose Endpoints.
🚨Note: You have to be careful, because while the endpoint is active, you will be billing. Check pricing here.
In step 5 on Jupyter notebook, you can see the advanced parameters to control the generated text while performing inference definition that this model supports.
Let's define the parameters as follows:
1
2
3
4
5
6
7
8
9
10
import json
newline, bold, unbold = "\n", "\033[1m", "\033[0m"
parameters = {
"max_length": 50,
"max_time": 50,
"num_return_sequences": 3,
"top_k": 50,
"top_p": 0.95,
"do_sample": True,
}
Where:
- num_return_sequences: corresponds to the number of answers per query that the LLM will deliver.
- max_length: the maximum number of tokens that the model will generate.
- top_k: limit random sampling to choose k value of sample with the highest probabilities.
- top_p: Select an output using the random-weighted strategy with the top-ranked consecutive results by probability and with a cumulative probability <= p.
- do_sample: Set
Truebecause Flan-T5 model use sampling technique.
To get inferences from the model hosted at the specified endpoint you need to use the InvokeEndpoint API from the Amazon SageMaker Runtime, you do it with the following function:
1
2
3
4
5
6
def query_endpoint_with_json_payload(encoded_json, endpoint_name):
client = boto3.client("runtime.sagemaker")
response = client.invoke_endpoint(
EndpointName=endpoint_name, ContentType="application/json", Body=encoded_json
)
return response
To make the response readable to humans, use the following function:
1
2
3
4
def parse_response_multiple_texts(query_response):
model_predictions = json.loads(query_response["Body"].read())
generated_text = model_predictions["generated_texts"]
return generated_text
For the LLM to generate an improved answer, you provide a prompt (or text_inputs in the code) composed of Amazon Kendra document part and the user's question, so that the model understands the context.
A good prompt provides a good result. If you want to know more about how to improve the prompt, I leave you this Prompt Engineering Guide.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def summarization(text,query):
payload = {"text_inputs": f"{text}\n\nBased on the above article, answer a question. {query}", **parameters}
query_response = query_endpoint_with_json_payload(
json.dumps(payload).encode("utf-8"), endpoint_name=endpoint_name
)
generated_texts = parse_response_multiple_texts(query_response)
print(f"{bold} The {num_return_sequences} summarized results are{unbold}:{newline}")
for idx, each_generated_text in enumerate(generated_texts):
#Translate the answer to the original language of the question
answer_text_translated,language = TranslateText(each_generated_text,TargetLanguage,source_language_code)
print(f"{bold}Result {idx}{unbold}: {answer_text_translated}{newline}")
return
Play with the text_inputs and discover the best one according to your needs.
Bring all the code together and Build your own knowledge base with multilingual Q&A powered by Generative AI 🥳.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
text = "¿que es Amazon S3?"
target_language_code = get_target_language_code(data_source_id,index_id)
query,source_language_code = TranslateText(text,"auto",target_language_code)
response = QueryKendra(index_id,query)
for query_result in response["ResultItems"]:
print("-------------------")
document_title = query_result['DocumentTitle']
document_title_translated,language = TranslateText(document_title,target_language_code,source_language_code)
print("DocumentTitle: " + document_title_translated)
document_content = query_result['Content']
document_content_translated,language = TranslateText(document_content,target_language_code,source_language_code)
print("Go deeper: ", query_result['DocumentURI'])
summarization(document_content,query)
In Fig 6 you can see 3 results of the summarized text. This is because you set num_return_sequences parameter to 3:

Fig 6. Amazon Kendra answer summarized results in spanish.
If your intention was to create to learn and you are not going to continue using the services, you must eliminate them so as not to overspend.
- Open the Amazon Kendra console.
- In the navigation panel, choose Indexes, and then choose the index to delete.
- Choose Delete to delete the selected index.
In the notebook in Sagemaker Studio where you deploy an Endpoint, execute the following lines:
1
2
3
# Delete the SageMaker endpoint
model_predictor.delete_model()
model_predictor.delete_endpoint()
Thank you for joining me on this journey, where you gather all the code and build your own knowledge base with multilingual Q&A powered by generative AI. This database allows you to make inquiries in any language, receiving summarized responses in the desired language, all prioritizing data privacy.
You can improve the LLM response by applying Prompt Engineering Techniques. An interesting one is Self-Consistency, that is, answering in the same way we did here but for the most relevant documents from Amazon Kendra, and then use the LLM to answer based on all responses (most consistent answer). Just try by yourself!
Then you can place the code in an AWS Lambda Function and, to improve the performance of this application, you can introduce a caching mechanism by incorporating an Amazon DynamoDB table. In this table, you can store the responses obtained from Amazon Kendra, utilizing the response as the partition key and the summary as the sort key. By implementing this approach, you can first consult the table before generating the summary, thereby delivering faster responses and optimizing the overall user experience.
Some links for you to continue learning: