Build a Real-Time Streaming Analytics Application on Apache Kafka
Learn how to build an end-to-end real-time streaming analytics application on AWS using Apache Kafka and Apache Flink
Felix
Amazon Employee
Published Jun 20, 2023
Last Modified Mar 15, 2024
Step 2: Build the Flink Application
Step 3: Upload the File to Amazon S3
Step 4: Create a Stack using AWS CloudFormation
Step 5: Create the MSK Serverless Cluster
Step 6: Create the Kafka Topics
Step 7: Start a Container Application to Generate Clickstream Data
Step 8: Check Schema in AWS Glue Schema Registry
Step 9: Consume Clickstream Data Using Managed Service for Apache Flink
Step 10: View Clickstream Data in the Amazon OpenSearch Dashboard
In today’s fast-paced digital world, real-time streaming analytics has become increasingly important as organisations need to understand what customers, application and products are doing right now and react promptly. For example, businesses want to analyse data in real-time to continuously monitor an application to ensure high service uptime and personalize promotional offers and product recommendations to customers.
However, building such an end-to-end real-time streaming application with an Apache Kafka producer and Kafka consumer can be quite challenging.
However, building such an end-to-end real-time streaming application with an Apache Kafka producer and Kafka consumer can be quite challenging.
This tutorial shows you how to setup and implement a real-time data pipeline using Amazon Managed Streaming for Apache Kafka (MSK). More specifically, the guide details how streaming data can be ingested to the Kafka cluster, processed in real-time and consumed by a downstream application.
| About | |
|---|---|
| ✅ AWS Level | Intermediate - 200 |
| ⏱ Time to complete | 45 mins - 60 mins |
| 💰 Cost to complete | USD 4.00 |
| 🧩 Prerequisites | - An AWS Account - An IAM user that has the access to create AWS resources - Basic understanding of CLI - Java and Apache Maven installed |
| 💻 Code | Code sample used in tutorial on GitHub |
| 📢 Feedback | Any feedback, issues, or just a 👍 / 👎 ? |
| ⏰ Last Updated | 2023-06-20 |
In this tutorial, we will:
- Start a Serverless Amazon MSK Cluster
- Produce streaming data to MSK Serverless using Kafka Client Container
- Consume and process the streaming data using Amazon Managed Service for Apache Flink (MFA)
- Visualise streaming data in Amazon OpenSearch Service
Let’s get started!
The following architecture provides an overview of all the AWS resources and services that we will use to write real-time clickstream data to the Kafka cluster and subsequently consume it. We make use of AWS Fargate to deploy a container application that produces sample clickstream data to the MSK Serverless cluster. The clickstream data is consumed by an Apache Flink application running in Amazon Managed Service for Apache Flink. More specifically, the Flink application processes the clickstream by windowing, which involves splitting the data stream into buckets of finite size. We rely on these windows to apply computations and analyze the data within each one. Finally, the resulting analyses are written to Amazon OpenSearch Service for visualisation.
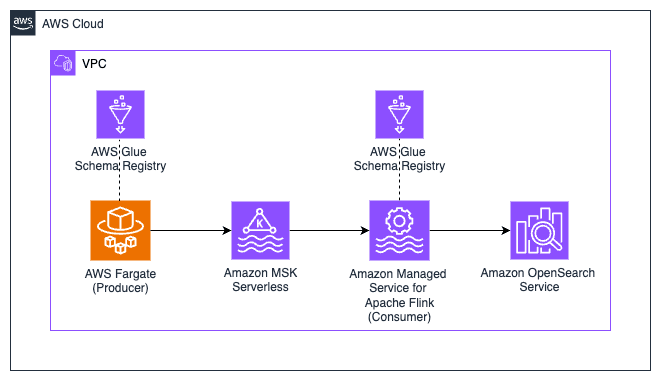
The following provides a step-by-step tutorial to implement a real-time streaming analytics application on Apache Kafka. Before you start, make sure you have the following pre-requisites installed on your machine:
- Java JDK
- Apache Maven
The repository
build-on-aws/real-time-streaming-analytics-application-using-apache-kafka contains the required files that help us to get started. Run the following command to download the repository to your local machine:After you have successfully installed Apache Maven on your machine, navigate to the
flink-clickstream-consumer folder using the following command inside the previously downloaded repository:Then, you can build the Flink application from inside the
flink-clickstream-consumer folder by running:Once the application is successfully built you should see a following message in your terminal:

Maven packages the compiled source code of the project in a distributable JAR format in the directory
flink-clickstream-consumer/target/ named ClickStreamProcessor-1.0.jar. If you want to better understand the inner workings of the Flink application, you can have a look at the ClickstreamProcessor.java file in the src directory. This is the entry point of the Java application where the main function resides.Next, we have to provide Amazon Managed Service for Apache Flink with the JAR file by uploading it to Amazon S3.
- Log into your AWS account, navigate to the Amazon S3 console, and click
Create bucket.

- Provide a unique bucket name of your choice and choose an AWS region (e.g.
us-east-1) and clickCreate Bucketat the bottom of the page. Take note of your bucket name.
- Click on the newly created bucket and click
Uploadto upload the following file to the S3 bucket.
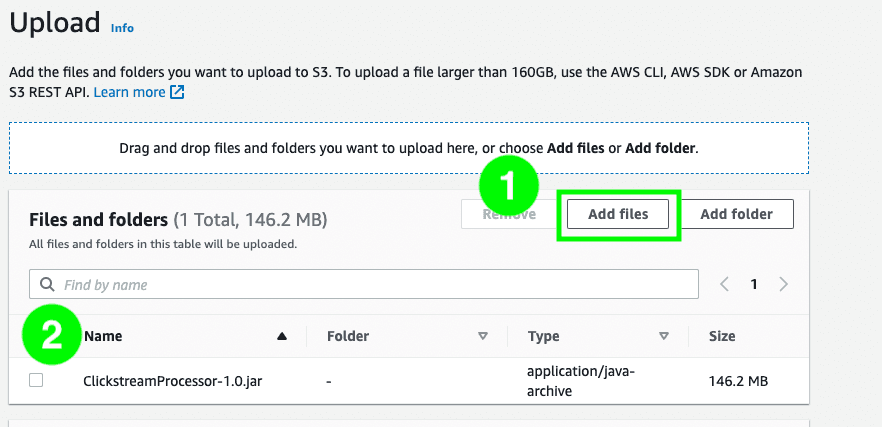
- Click
Add filesand select the JAR fileClickStreamProcessor-1.0.jarthat you have recently generated.
Perfect! Now, that the JAR file is uploaded to the S3 bucket, we can easily run the Flink application in Amazon Managed Service for Apache Flink without having to manage any servers. Note that we can either upload the package as JAR file, or can compress the package and upload it as a ZIP file.
Next, we'll create a CloudFormation stack and automatically deploy the following resources by uploading the CloudFormation template:
Amazon OpenSearch Cluster: This is where we can visualize the consumed clickstream data. It is deployed in private subnets of a VPC.Amazon ECS Cluster + Task definition: The container application that generates the sample clickstream data runs inside the ECS cluster as a Fargate task.Amazon Managed Service for Apache Flink: This is where the Flink application runs, consuming the clickstream data from the MSK cluster, processing it and writing it to the OpenSearch Service.Amazon EC2 Instance (Kafka client): This EC2 instance serves as a Kafka client and allows us to interact with the MSK cluster by among other things creating Kafka topics.Amazon EC2 Instance (Nginx proxy): This EC2 instance serves as a Nginx proxy and allows us to access the OpenSearch Dashboard from outside of the VPC, i.e., from the Internet.Security groups: Security groups help us to control the traffic that is allowed to reach and leave a particular resource.IAM roles: An IAM role is an IAM identity that has specific permissions attached to it and can be assumed by an IAM user or an AWS service. For example, an IAM role can be used to grant permissions to an application running on an EC2 instance that requires access to a specific Amazon S3 bucket.
Rather than creating the required resources manually we make use of the CloudFormation template to automatically deploy the resources in the AWS account.
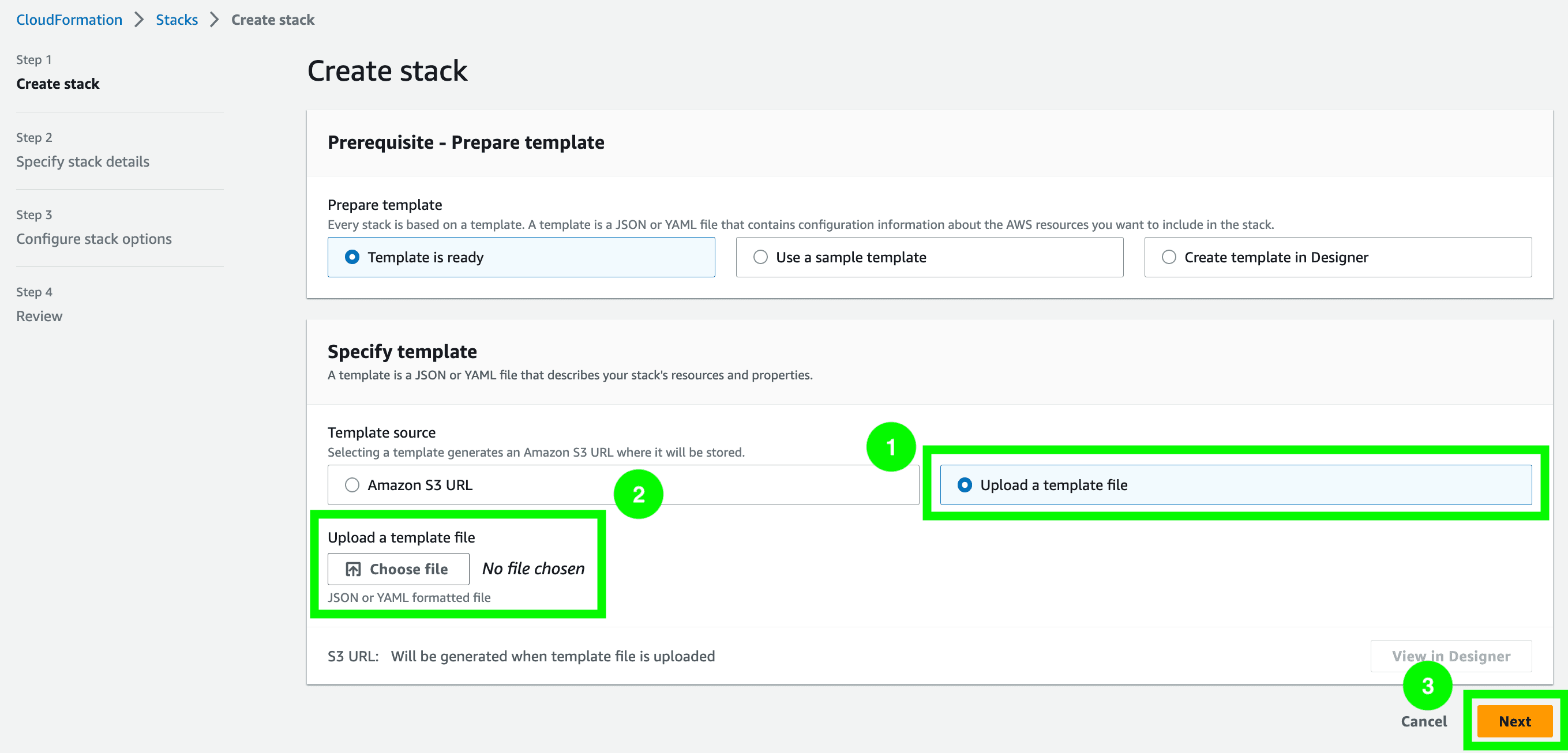
- Navigate to the CloudFormation console and click on
Create Stack. - Choose
Upload a template fileand clickChoose fileto upload the CloudFormation template filecf_template.ymlthat can be found in the root directory of the downloaded repository. Then, clickNext.
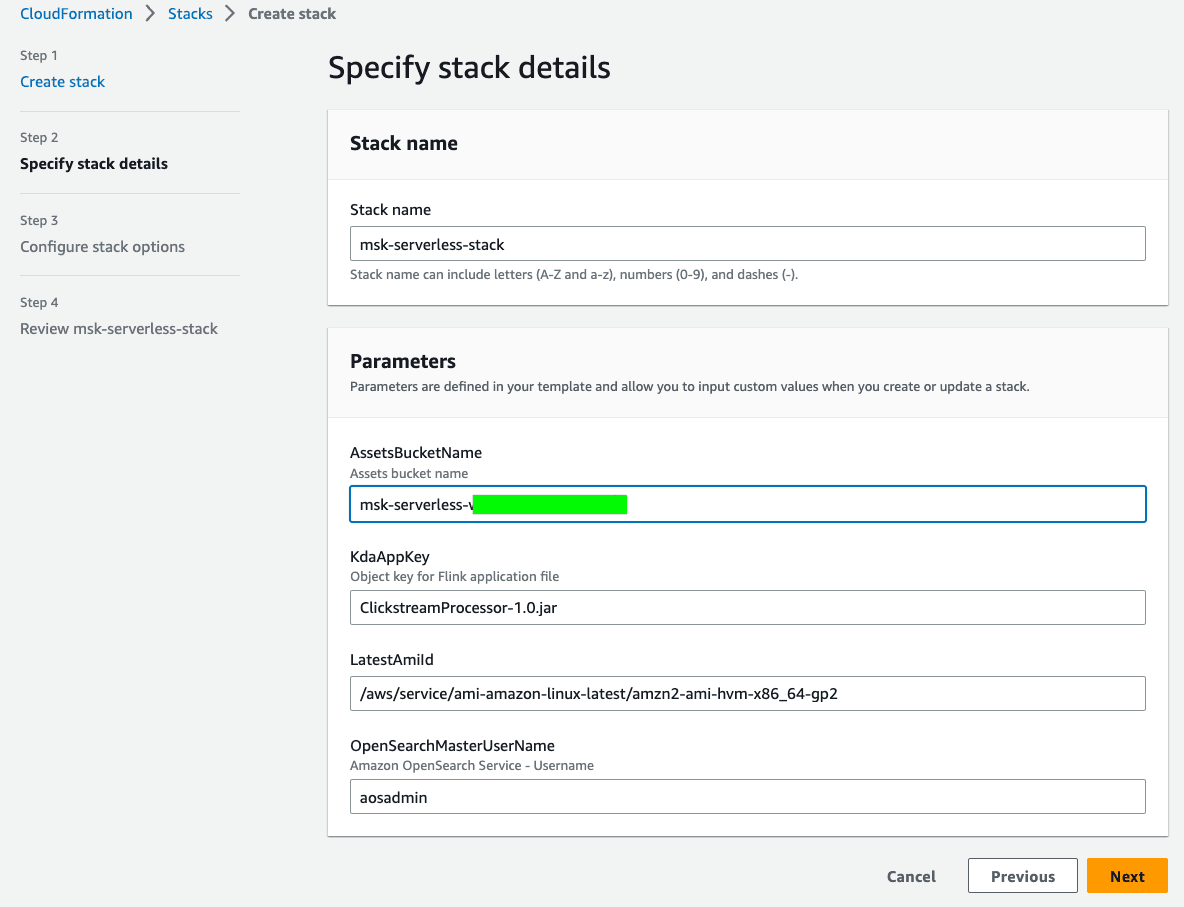
- Provide the stack with a
Stack nameof your choice (e.g.msk-serverless-stack). Additionally, you have to provide a value to the parameterAssetsBucketName. Enter the name of the S3 bucket that you created earlier. You can leave the defaultClickstreamProcessor-1.0.jarasKdaAppKeyunless you have changed the name of the JAR file that you have generated earlier. Leave theLatestAmiIdas well as theOpenSearchmasterUserNameas is. ClickNext.
- Scroll down the page
Configure stack optionsand clickNext. - Scroll down the page
Review <Your_Stack_Name>. Make sure to tick the box that reads,I acknowledge that AWS CloudFormation might create IAM resources with custom names. Lastly, clickSubmitto create the CloudFormation stack.
Wait until the status of the stack changes from
CREATE_IN_PROGRESS to CREATE_COMPLETE. Note: This can take some time.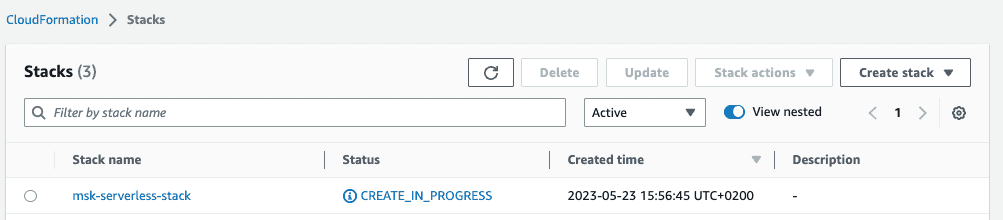
Once the status changes to
CREATE_COMPLETE, the resources that were defined in the CloudFormation template have been created in your AWS account. However, there are few more resources and configurations required until we end up with an end-to-end real-time streaming application.Next, we will create the MSK cluster on AWS. There are two types of clusters available on AWS: MSK Serverless that provides on-demand capacity with automatic scaling, and MSK Provisioned which grants greater control by allowing you to specify the number of brokers and amount of storage per broker in your cluster. However, MSK Provisioned does not scale automatically as your application I/O demand changes. In this tutorial, we'll choose MSK Serverless as we do not want to worry about the underlying infrastructure and keep the management overhead to a minimum.
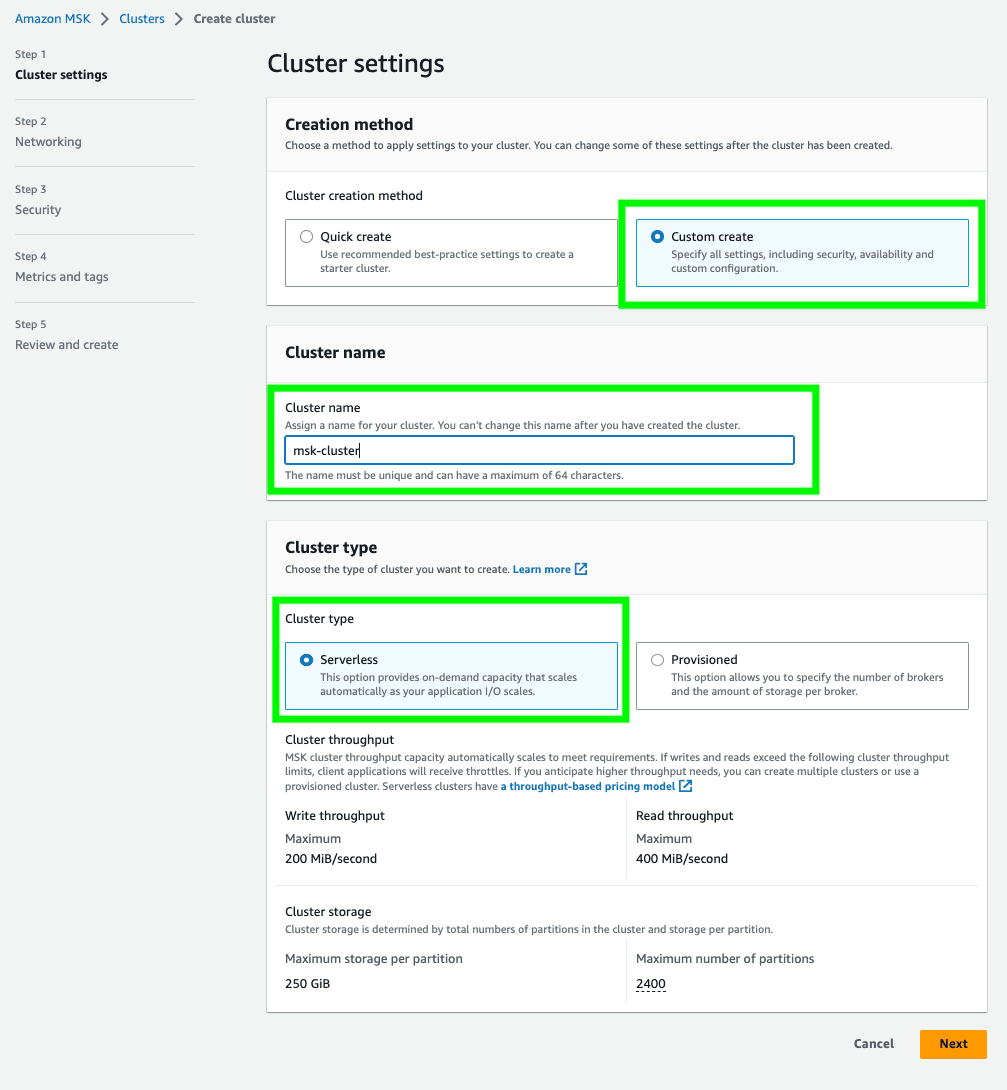
- Navigate to the Amazon MSK console and click
Create cluster. - Choose
Custom createand provide a cluster name of your choice (e.g.msk-cluster). SelectServerlessas cluster type. Then, clickNext.
- In the
Networkingview, select the custom VPC namedMMVPC. Then, clickAdd subnetto add a third subnet and choose the three available private subnets (PrivateSubnetMSKOne,PrivateSubnetMSKTwo,PrivateSubnetMSKThree) for the the different zones inus-east-1a,us-east-1bandus-east-1c. - Rather than the default security group, select the security group named
MSK Security Group. Lastly, clickNext.
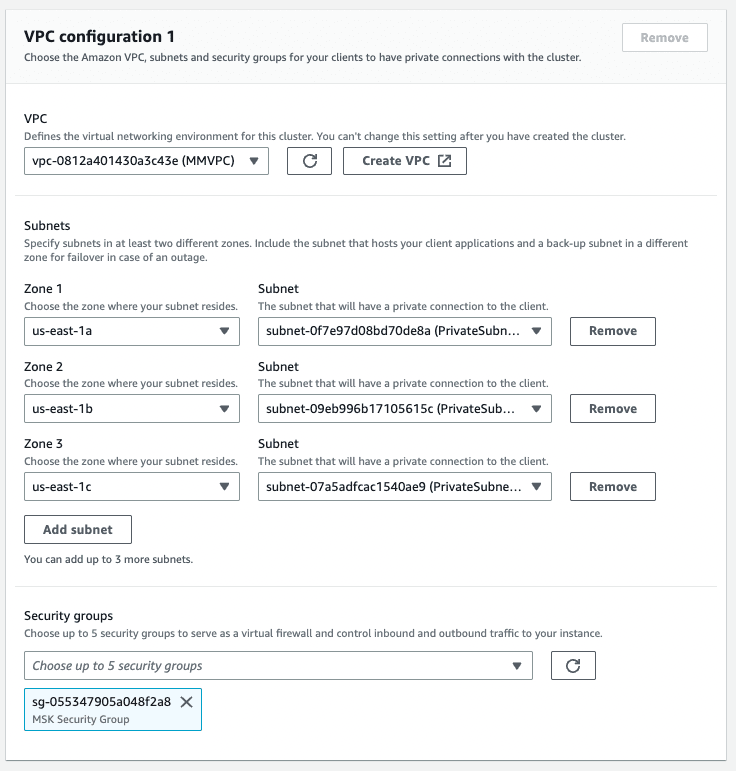
- Click
Next. - Click
Next. - Finally, click
Create clusterto create the MSK Serverless cluster. - Once your MSK Serverless cluster status changes to
Active, click onView client information.
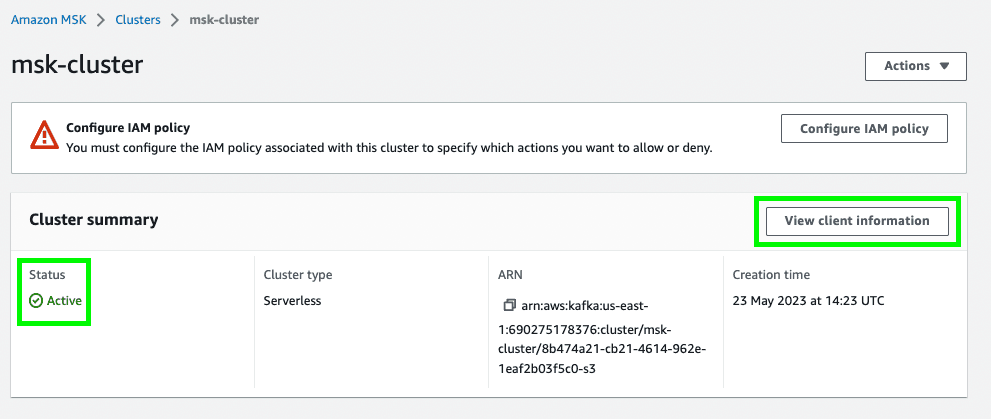
- Take note of the endpoint of your MSK Serverless cluster. Notice that we use IAM access control to handle the authentication to the MSK cluster.
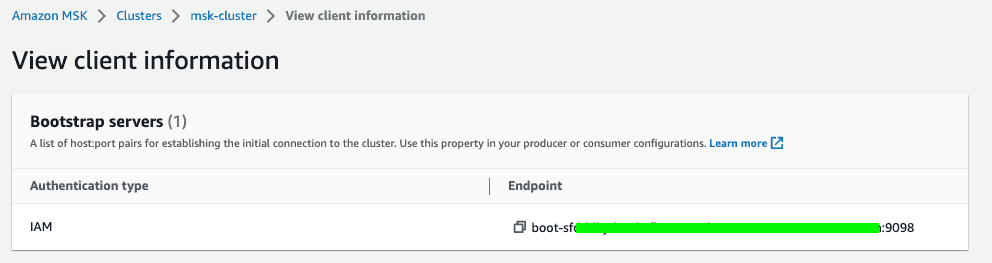
At the moment, MSK Serverless only supports IAM authentication. If you choose MSK Provisioned, you have the option of using IAM, TLS or SASL/SCRAM to authenticate clients and allow or deny actions.
Now that the MSK Serverless cluster is ready and available to use, we need to create a Kafka topic to produce and consume the data. We can create Kafka topics as shown below:
- Navigate to the Amazon EC2 console. On the EC2 home page click on
Instances (running).
- On the EC2 Instances page select the checkbox for the instance named
KafkaClientInstanceand click on theConnectbutton on top right as shown in the image below.

- On the page
Connect to instance, ensure to selectSession Managerand click theConnect button. This opens a new tab with an EC2 terminal window. - In the terminal window execute the following command to change to
ec2-user:

- Execute the command below to set your MSK cluster endpoint to the shell variable BS. Please replace
<Your_Cluster_Endpoint>with the endpoint you noted down after you created the MSK Serverless cluster.

- Then, execute the following command to create the Kafka topic.
You will encounter warnings printed to the terminal. You may ignore them.
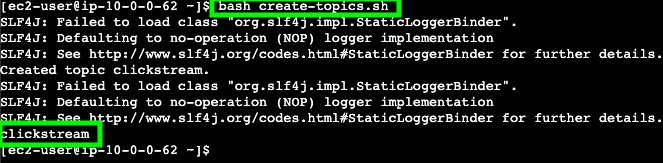
- You should see a single MSK topic that has been created:
clickstream.
You can run the following command to view the bash script and see details of the executed Kafka commands within:
If you'd like, feel free to run other Kafka commands to get a better understanding of your MSK cluster. For example, run the following command to view details of the topic that you have created:
After we have successfully created the MSK cluster, the next step is to set up the producer that will write data to the topic
clickstream. For that we'll deploy a serverless Amazon ECS Fargate container which runs an application, generating sample clickstream data to the MSK Serverless cluster.- Navigate to the Amazon ECS console. On the left side menu click on
Task Definitionsto view all available Task definitions. Select the checkbox of the available Task definition and selectRun taskfrom theDeploymenu.
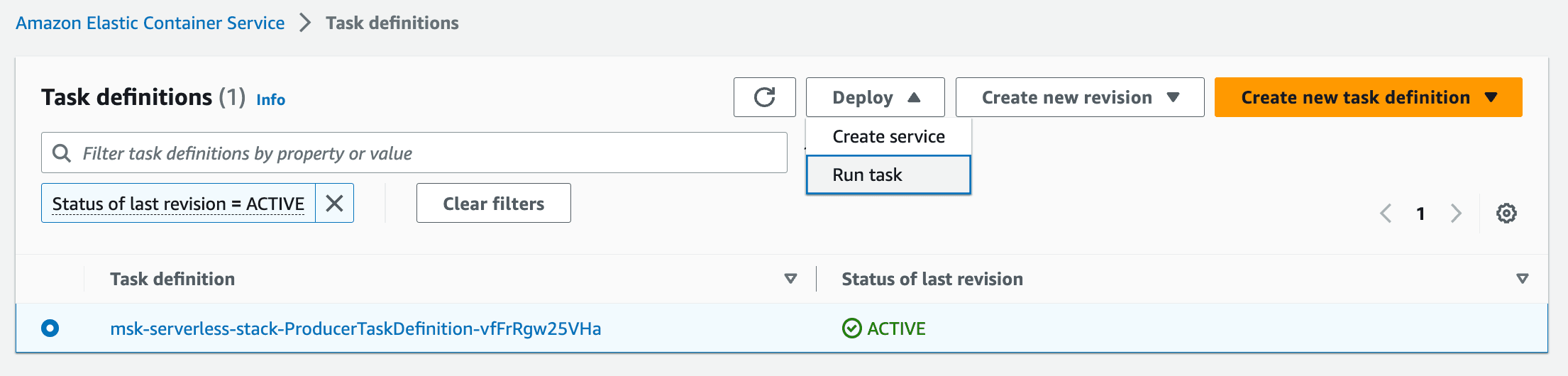
- On the Run Task page, select the existing cluster (
msk-serverless-[...]-cluster) and leave the default settings.
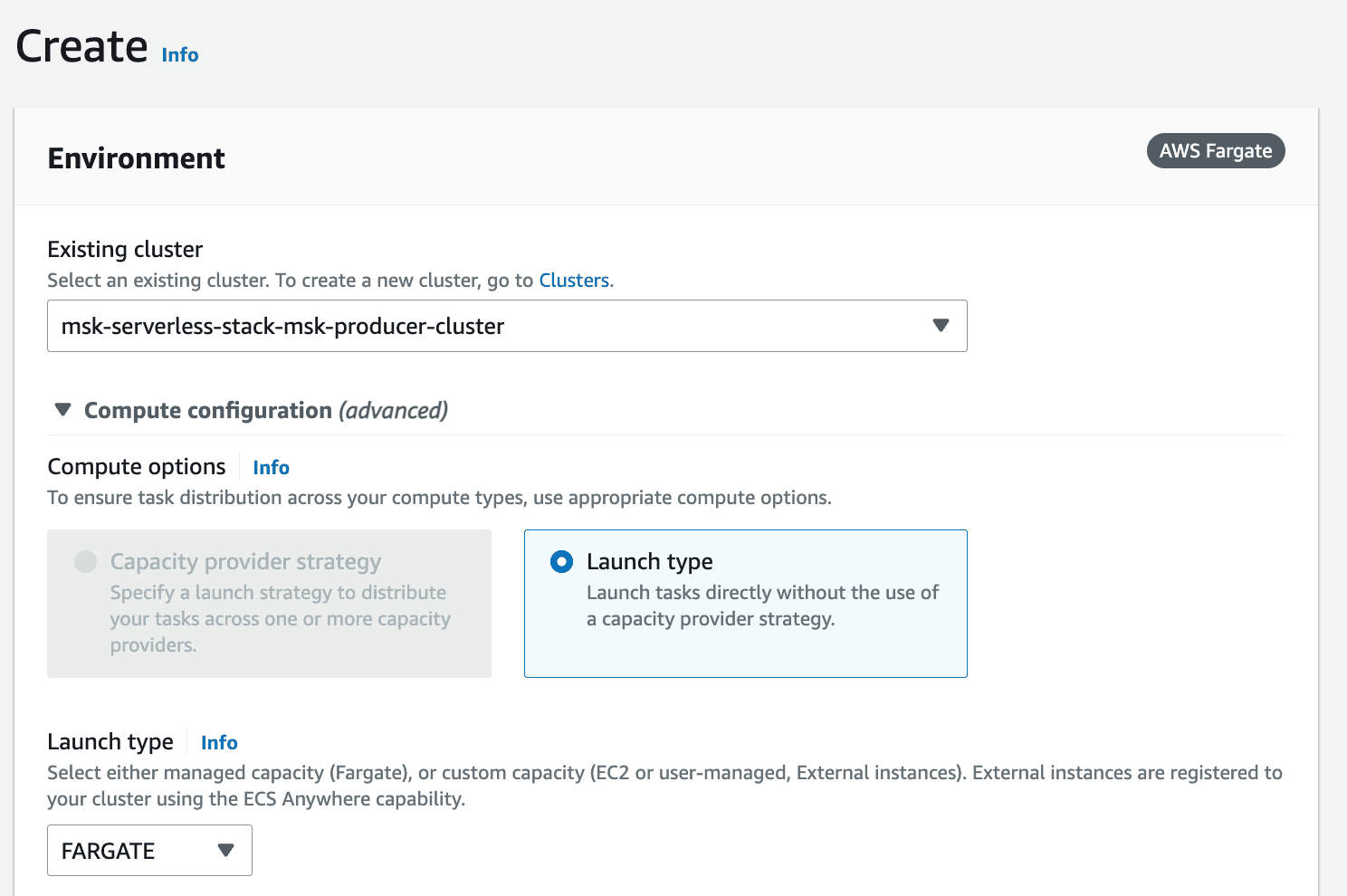
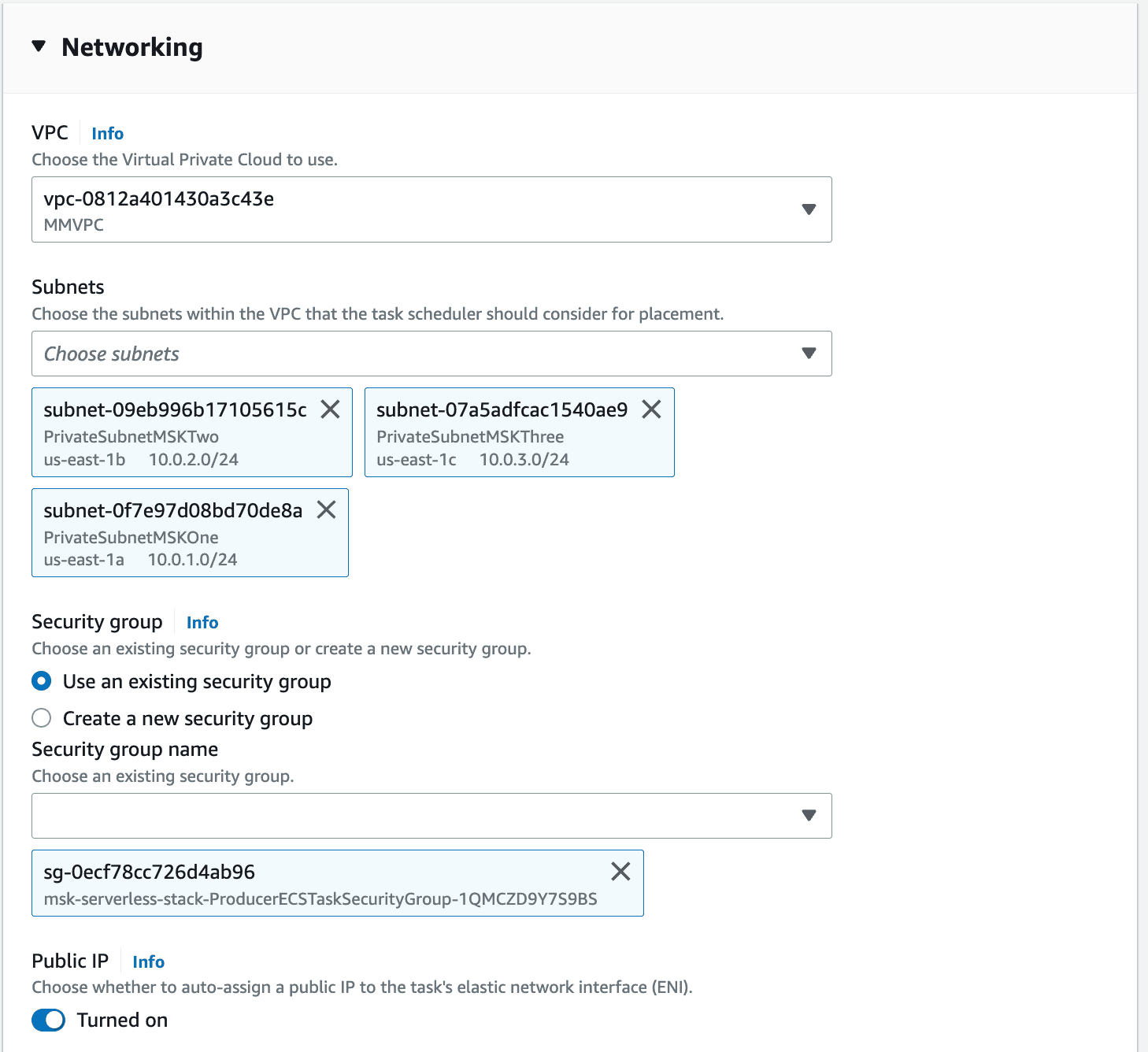
- Expand the
Networkingsection. Change the default VPC toMMVPC. Similar to before, select the three subnetsPrivateSubnetMSKOne,PrivateSubnetMSKTwoandPrivateSubnetMSKThree. Finally, uncheck the default security group and select the security group that contains-ProducerECSTaskSecurityGroup-.
- Expand the
Container overridessection. ForBOOTSTRAP_STRINGenter the value to your MSK Serverless cluster endpoint (written down earlier withView client informationfrom the MSK cluster console page).
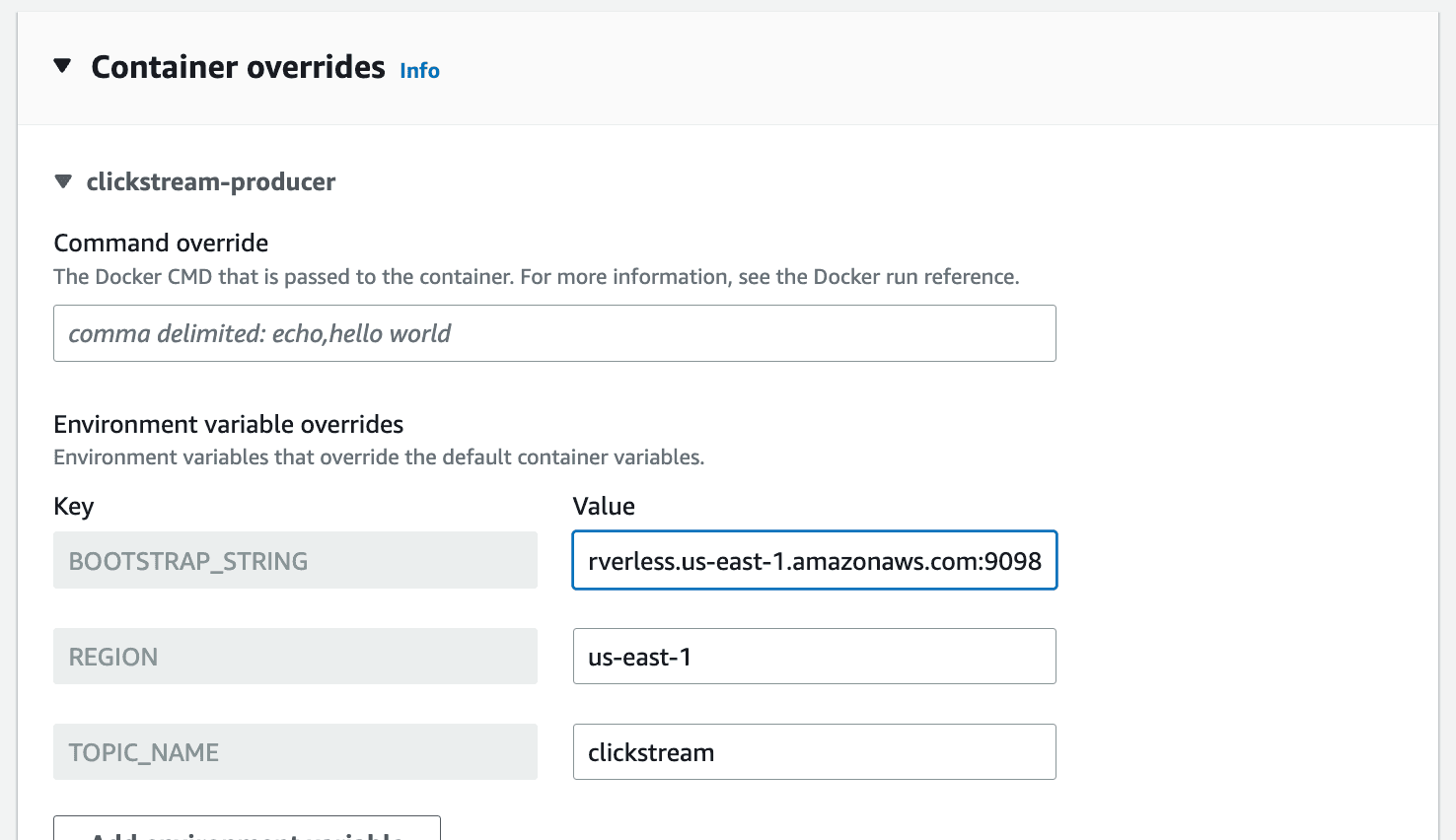
- Finally, click the
Create button. - Wait for your task to change to the
Runningstatus as shown below.

You have now successfully created a producer ECS task that will continuously generate clickstream data to the MSK Serverless cluster.
More specifically, the ECS task produces random click events. Hereby, an event comprises a user IP, a product type, an event timestamp and other information. There is also a user ID associated with each event, serving as key. The partition number of the event is determined by using a hash of that key. Before we send the data to the MSK cluster, the event data is serialized using a Avro serializer provided by the AWS Glue Schema Registry. Every generated event is sent to the previously created topic
clickstream.In the last step, we successfully created an ECS producer task. Now we have to create the clickstream schema in the AWS Glue Schema Registry.
- Navigate to the Amazon Glue console. Select
Stream schema registriesunderData Catalogfrom the left menu. You can see the schema registry namedserverless. Click on it. - You can see the available schemas of the schema registry
serverless. Click on the schemaclickstreamto see the different schema versions. You should see version1here.
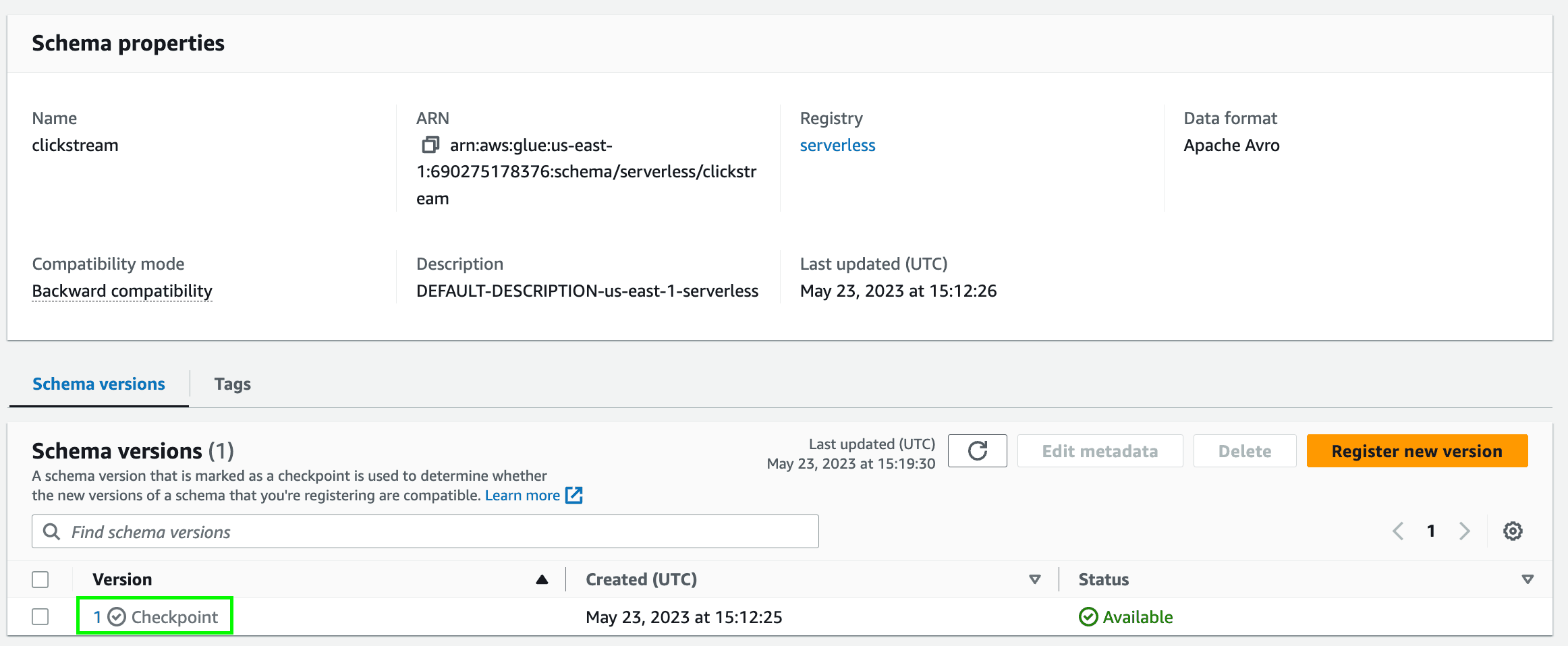
- Click on the version
1to see the Avro schema of the clickstream data produced by the ECS task.

Apache Avro is a data serialization system that allows for efficient and compact encoding of structured data, especially in big data or streaming data use cases. To this end, Avro provides a compact binary format for data storage and exchange. The producer makes use of a Avro serializer provided by the AWS Glue Schema Registry and automatically registers the schema version in the Glue Schema Registry.
We have set up the MSK Serverless Cluster and are continuously writing clickstream data to the cluster. Now, we would like to consume the clickstream data from the MSK Serverless cluster using Amazon Managed Service for Apache Flink. The Apache Flink application processes the clickstream data in real-time and writes the analyses to Amazon OpenSearch Service.
The OpenSearch Service is already deployed in your AWS account and the Dashboard is already configured. What's missing are the correct runtime parameters for the Flink application.
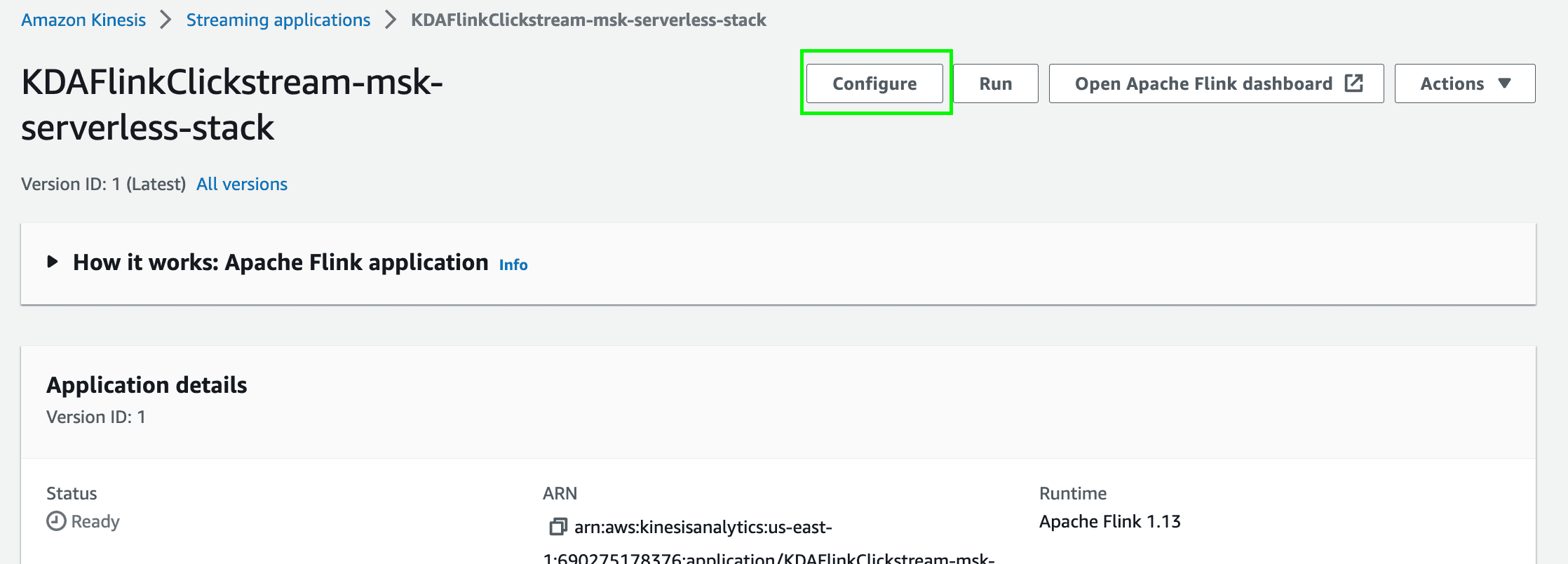
- Navigate to the Managed Apache Flink console and click on the open streaming application
KDAFlinkCLickstream-msk-serverless-stack. - Configure and update the application by clicking on the
Configurebutton.
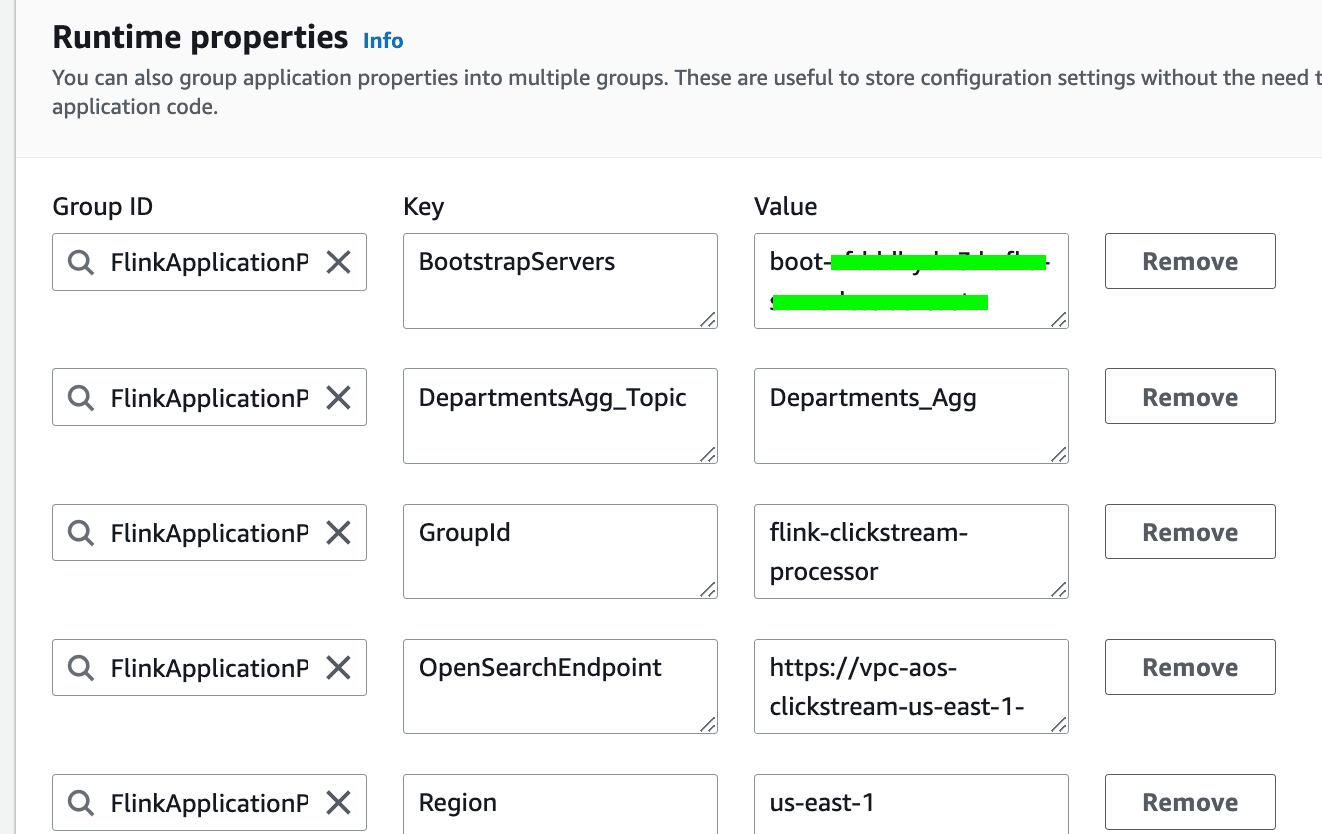
- Scroll down to the
Runtime properties. UpdateBootstrapServersto the MSK Serverless cluster endpoint you have written down earlier. Keep the rest of the values as default.
- Finally, save your changes.
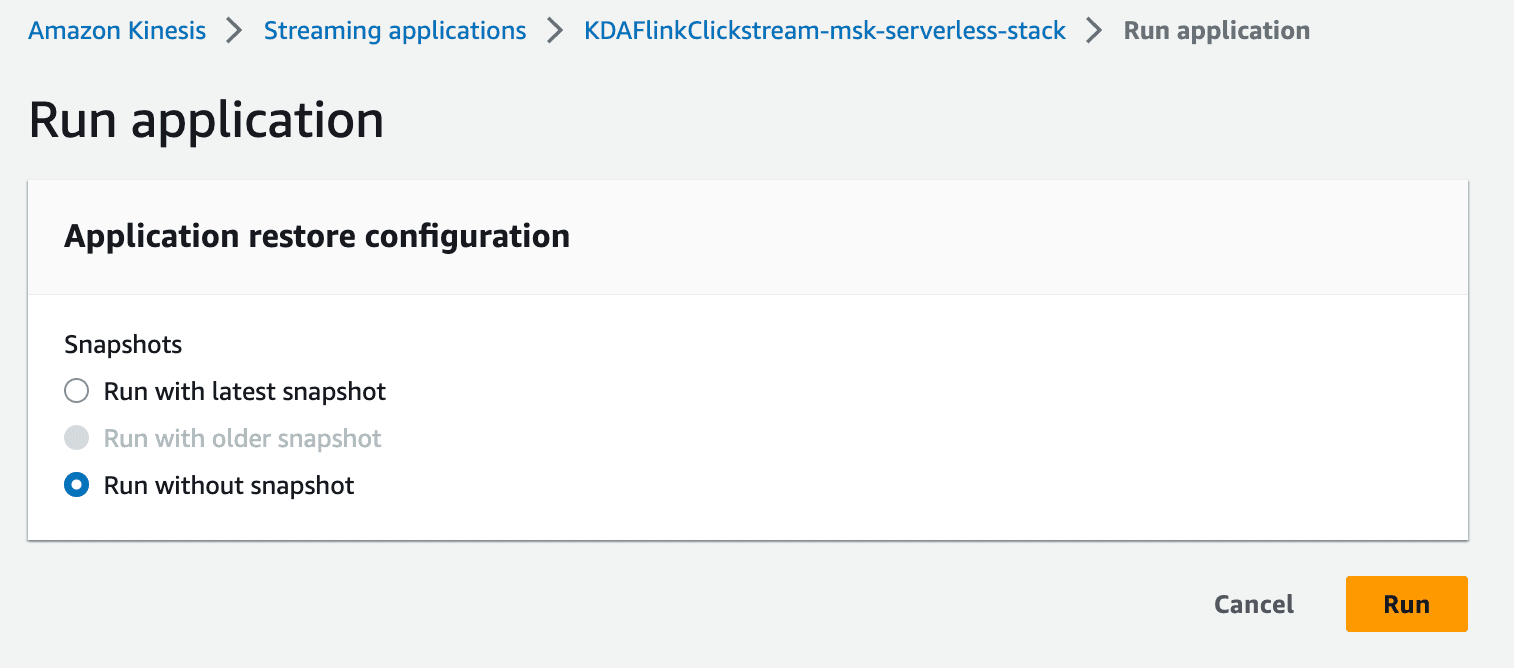
- Click on the
Runbutton to run the Flink application. ChooseRun without snapshot.
- Once the Flink application is running, click on
Open Apache Flink dashboardto open the Flink dashboard.
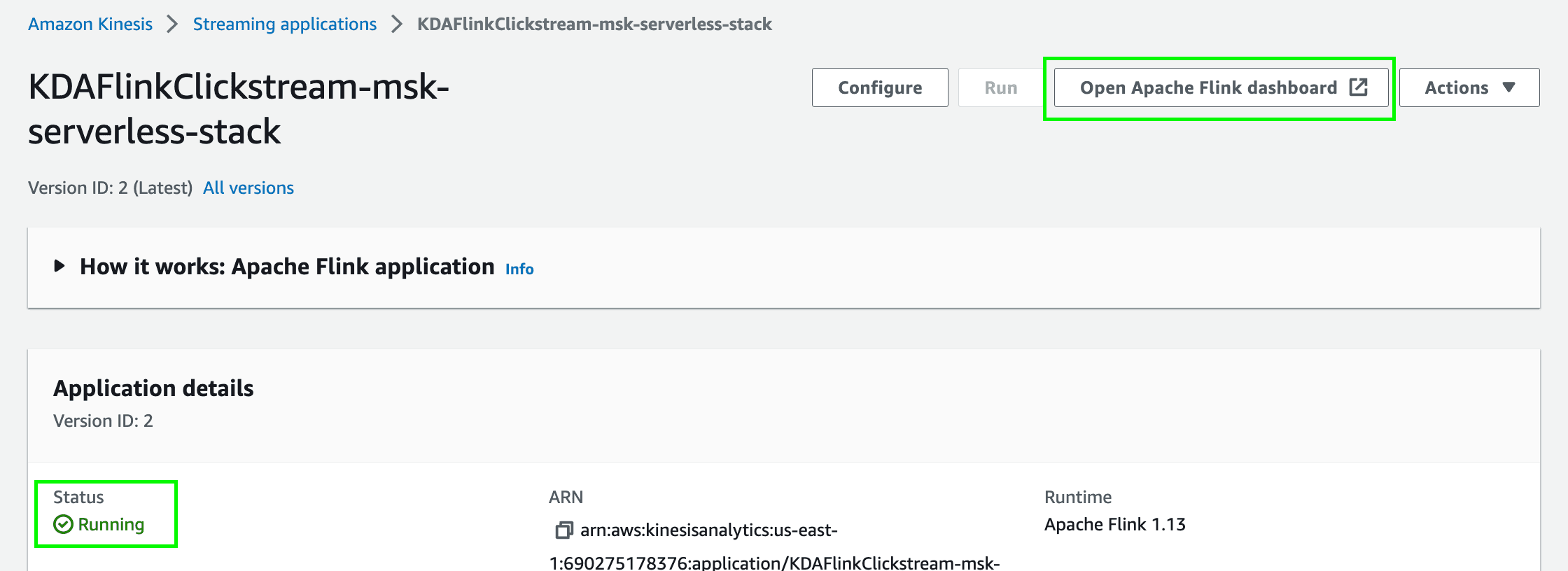
- Click on
Running Jobson the left side of the menu. Click onFlink Streaming Jobto access the details of the running job.

- This opens a screen with a directed acyclic graph (DAG), representing the flow of data throughout each of the operators of your application. Each blue box in the job workflow represents a series of chained operators, known as Tasks in Apache Flink.
As mentioned before, the Flink application processes the clickstream by windowing, i.e., dividing a continuous stream of data into finite, discrete chunks or windows for processing. More precisely, the Flink application uses
EventTimeSessionWindows to extract user sessions from the clickstream data by grouping events that are within a specified time gap of each other. Then, the application deploys TumblingEventTimeWindows to calculate specific aggregation characteristics within a certain period of time by dividing the clickstream in fixed-size, non-overlapping windows. For example, that could involve calculating the aggregate count of user sessions that have made a purchase within the past 10 seconds.In addition, we can see the status of each task, as well as the
Bytes Received, Bytes Sent, Records Received and Records Sent at the bottom of the screen. Note that Flink can only measure the bytes sent or received between operators. That’s why you can't see the metrics for the source or sink operator as the data is coming from outside of Flink.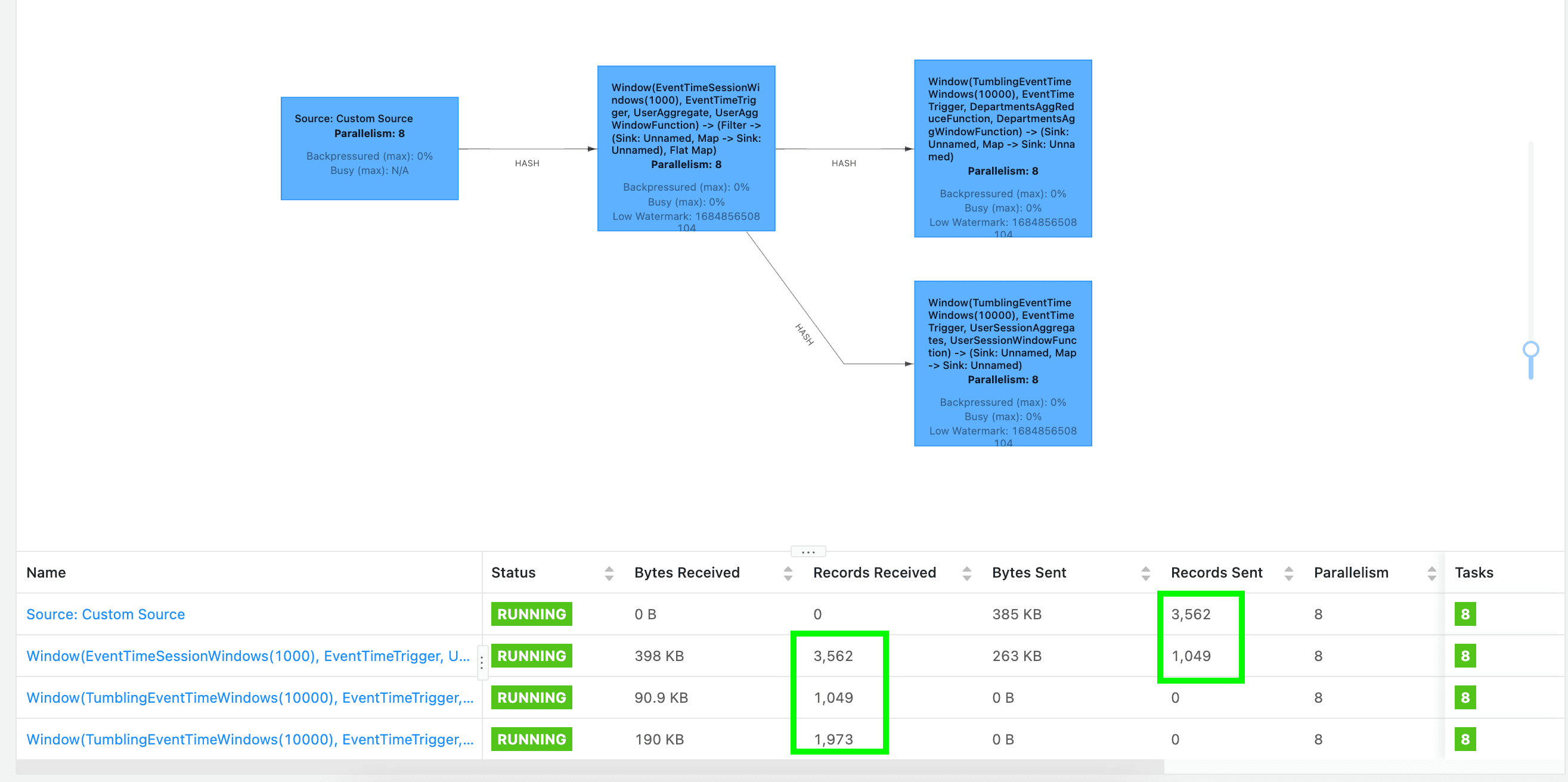
We have now successfully setup a Flink application that reads messages from a Kafka topic, processes the data, and then writes the analyses to Amazon OpenSearch Service. Let’s check the data in the OpenSearch dashboard!
In this final step, we want to see the dashboard visualisation generated based on the ingested data from the Flink application.
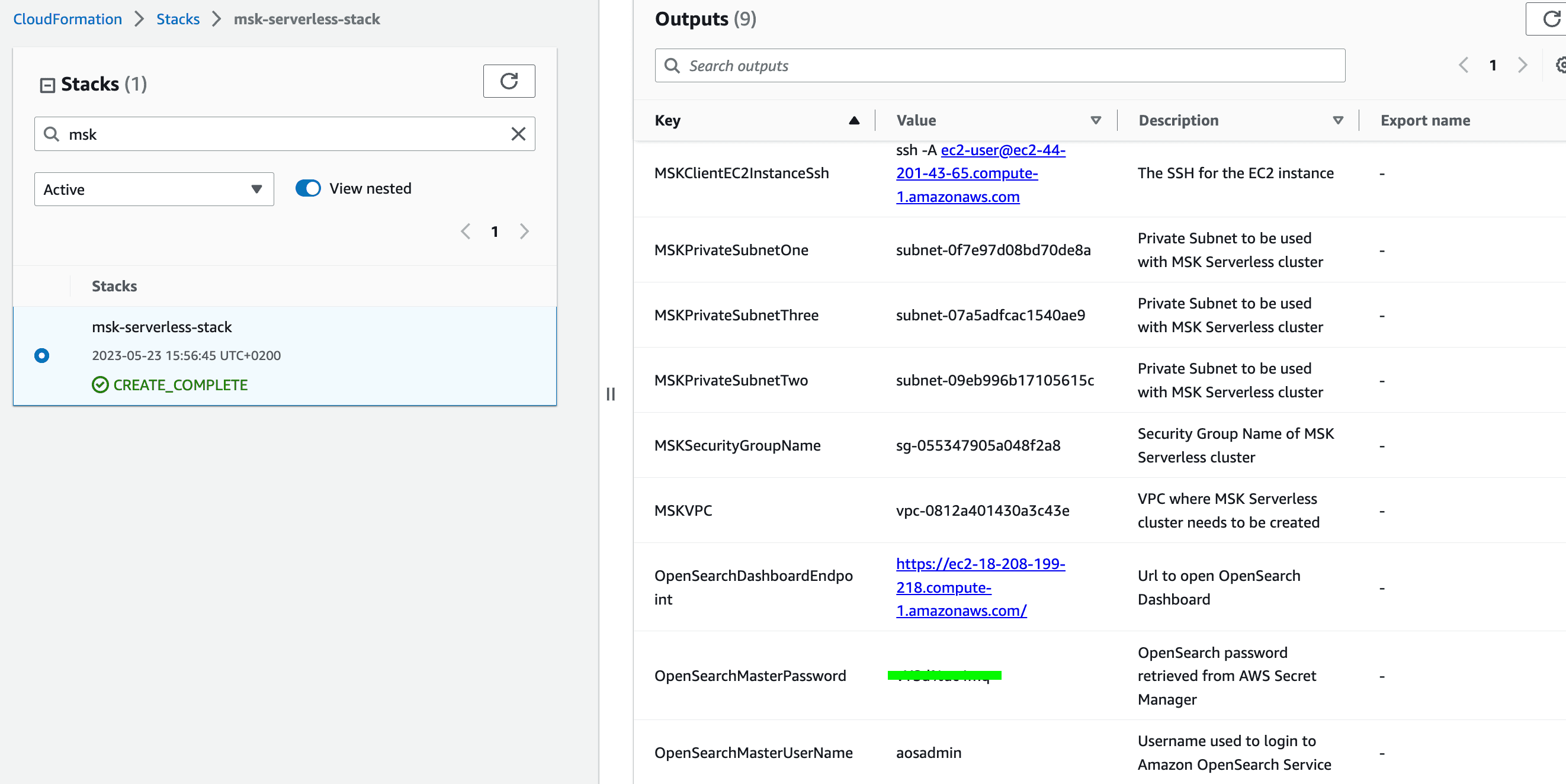
- Navigate to the CloudFormation console and click on the stack that we created earlier. Go to the
Outputstab of the stack. - Take note of the
OpenSearchMasterUserNameandOpenSearchMasterPassword. We will need the values in the next step.
- Click on the
OpenSearchDashboardEndpointto open the OpenSearch Dashboard login page in a new tab. As the OpenSearch Service is deployed in a VPC, we are relying on Nginx reverse proxy to access the OpenSearch Dashboard outside of the VPC. Note that we are using a self signed certificate for Nginx. However, we strongly recommend using a valid certificate for production deployments. - If you are accessing the URL using Google Chrome, click on the
Advancedbutton and click onProceed to <Your_EC2_DNS>.
- Use the
OpenSearchMasterUserNameandOpenSearchMasterPasswordfrom the previous step and log into to OpenSearch Dashboards.
- Select
Globaltenant on the popup dialog box. - Click on the hamburger menu on the left of the screen and click on
Dashboardsas shown below.
- In the
Dashboardsview select the dashboard namedClickstream Dashboardto see the plotted data:
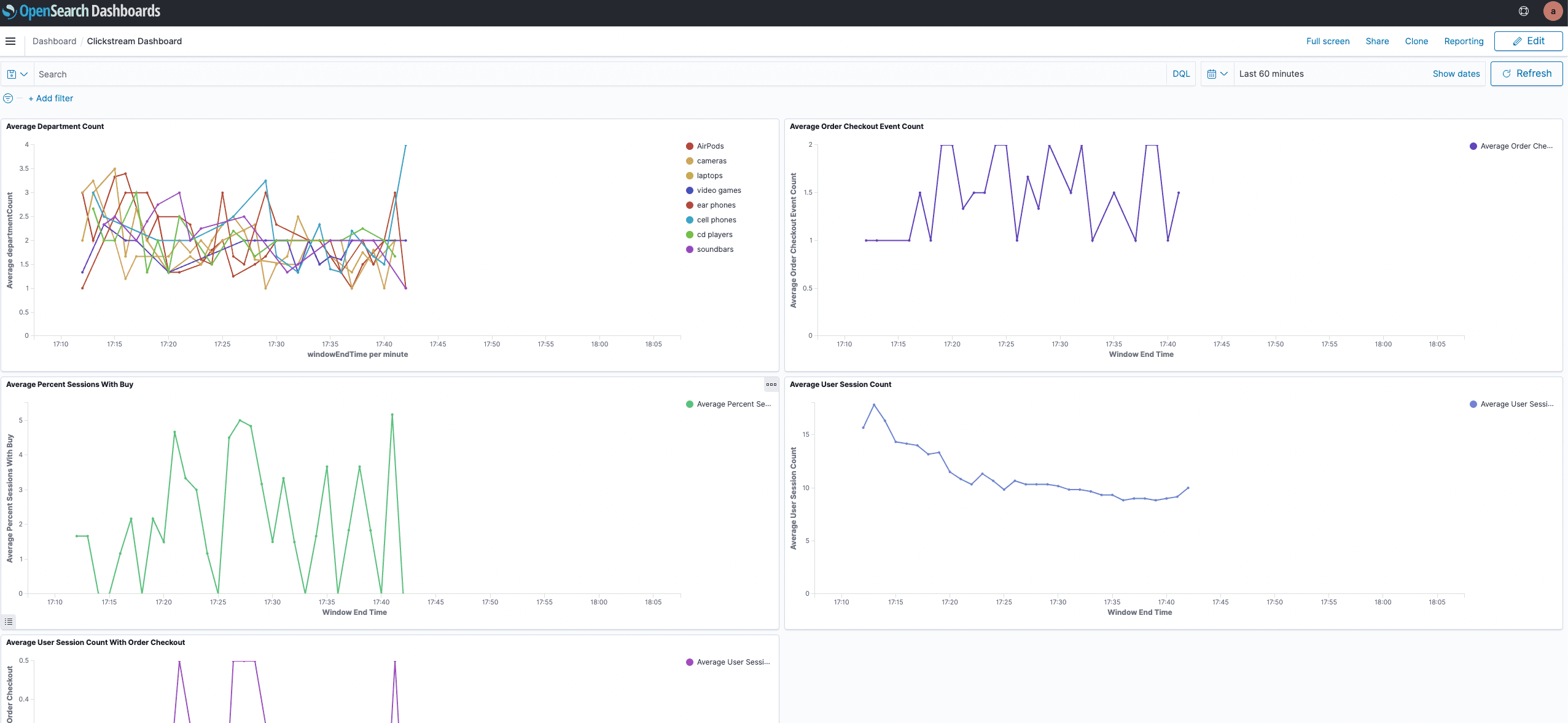
We have now confirmed data flowing to OpenSearch Service and visualisations are rendered. But how does the data come from the Flink application to Opensearch. Well, we make use of the Elasticsearch Connector of Apache Flink. This connector provides sinks that can request document actions to an Elasticsearch index. You can navigate to the file
AmazonOpenSearchSink.java in the downloaded repository to view the implementation of the connector.Now that you’ve finished building a real-time streaming analytics application on Apache Kafka, you can delete all resources to avoid incurring unexpected costs.
- Delete the MSK Serverless Cluster under the
Actionsmenu.
- Delete the CloudFormation Stack.

- Empty and delete the S3 Bucket you have created earlier.

Congratulations! You have built a real-time streaming analytics application on Apache Kafka. More specifically, you have set up an ECS task to produce sample clickstream data to the MSK Serverless Cluster. This clickstream data is then consumed by a Flink application running in Amazon Managed Service for Apache Flink, processed and written to Amazon OpenSearch.
If you want to learn more about streaming and Apache Kafka on AWS, you can check out the following blog posts:
If you enjoyed this step-by-step guide, found any issues or have feedback for us, please send it our way!
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.