Build a Serverless Application to Automate Invoice Processing on AWS
Learn how to use Amazon Textract and AWS Lambda to process invoice images and extract metadata using the Go programming language.
Abhishek Gupta
Amazon Employee
Published Jun 13, 2023
Last Modified Mar 14, 2024
Amazon Textract is a machine learning service that automatically extracts text, handwriting, and data from scanned documents. It goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables. It helps add document text detection and analysis to applications which help businesses automate their document processing workflows and reduce manual data entry, which can save time, reduce errors, and increase productivity.
In this tutorial, you will learn how to build a Serverless solution for invoice processing using Amazon Textract, AWS Lambda and the Go programming language. We will cover how to:
- Deploy the solution using AWS CloudFormation.
- Verify the solution.
We will be using the following Go libraries:
- AWS Go SDK, specifically for Amazon Textract.
- Go bindings for AWS CDK to implement "Infrastructure-as-code" (IaC) for the entire solution and deploy it with the AWS Cloud Development Kit (CDK) CLI.
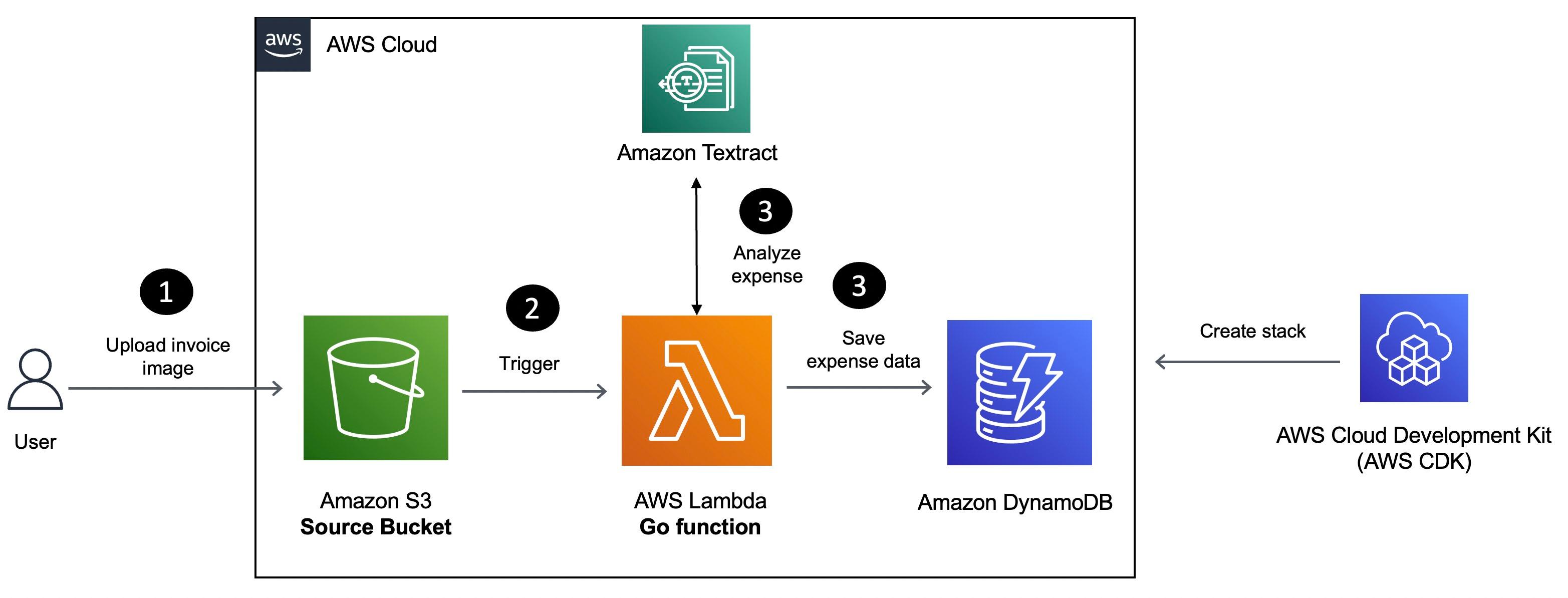
Here is how the application works:
- Invoice receipt images uploaded to Amazon S3 trigger a Lambda function.
- The Lambda function extracts invoice metadata (such as ID, date, amount) and saves it to an Amazon DynamoDB table.
Before starting this tutorial, you will need the following:
- An AWS Account (if you don't yet have one, you can create one and set up your environment here).
- Go programming language (v1.18 or higher).
- Git.
Clone the project and change to the right directory:
AWS CDK is a framework that lets you define your cloud infrastructure as code in one of its supported programming and provision it through AWS CloudFormation.
To start the deployment, invoke the
cdk deploy command. You will see a list of resources that will be created and will need to provide your confirmation to proceed.Enter
y to start creating the AWS resources required for the application.If you want to see the AWS CloudFormation template which will be used behind the scenes, runcdk synthand check thecdk.outfolder
You can keep track of the stack creation progress in the terminal or navigate to AWS console:
CloudFormation > Stacks > TextractInvoiceProcessingGolangStack.Once the stack creation is complete, you should have:
- A
S3bucket - Source bucket to upload images. - A Lambda function to process invoice images using Amazon Textract.
- A
DynamoDBtable to store the invoice data for each image. - And a few other components (like
IAMroles etc.)
You will also see the following output in the terminal (resource names will differ in your case) - these are the names of the
S3 buckets created by CDK:You are ready to verify the solution.
To try the solution, you can either use an image of your own or use the sample files provided in the GitHub repository which has a few sample invoices. Use the AWS CLI to upload files:
This Lambda function will extract invoice data (ID, total amount etc.) from the image and store them in a
DynamoDB table.Upload other files:
Check the
DynamoDB table in the AWS console - you should see the extracted invoice information.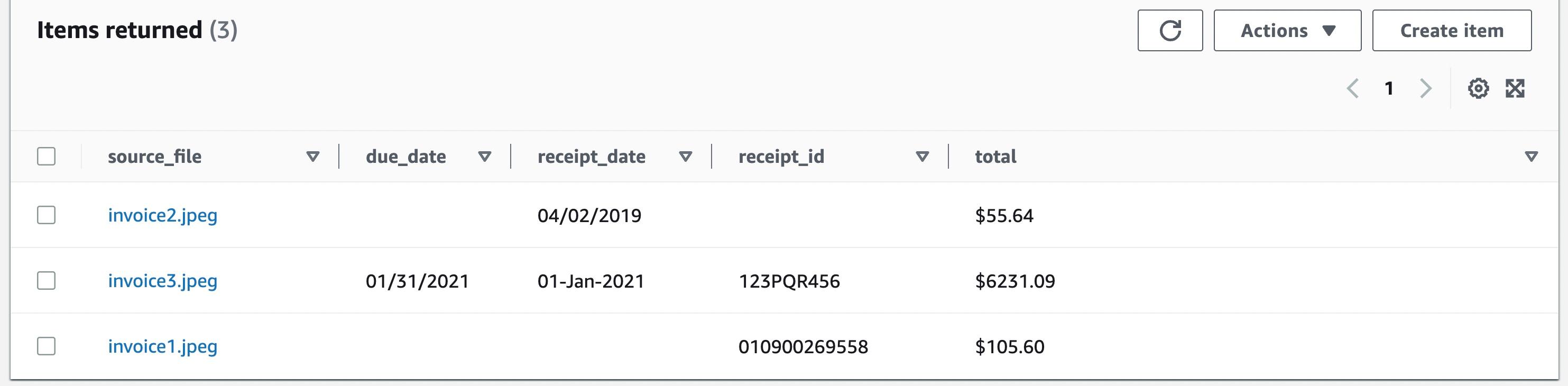
DynamoDB table is designed with source file name as the partition key. This allows you to retrieve all invoice data for a given image.You can use the AWS CLI to query the
DynamoDB table:Here is a quick overview of the Lambda function logic. Please note that some code (error handling, logging etc.) has been omitted for brevity since we only want to focus on the important parts.
The Lambda function is triggered when an invoice image is uploaded to the source bucket. The function iterates through the list of invoices and calls the
invoiceProcessing function for each invoice.Let's go through the
invoiceProcessing function.- The
invoiceProcessingfunction calls the Amazon Textract AnalyzeExpense API to extract the invoice data. - The function then iterates through the list of ExpenseDocuments and extracts information from specific fields -
INVOICE_RECEIPT_ID,TOTAL,INVOICE_RECEIPT_DATE,DUE_DATE. - It then saves the extracted invoice metadata in the
DynamoDBtable.
Once you're done, to delete all the services, simply use:
In this tutorial, you used AWS CDK to deploy a Go Lambda function to process invoice images using Amazon Textract and store the results in a DynamoDB table.
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.