Prod-One-Box on serverless
Releasing with confidence and reducing blast radius with AWS Lambda traffic shifting and a prod-one-box
Carlos Aller Estevez
Amazon Employee
Published Nov 2, 2023
Last Modified Oct 17, 2024
Automating gradual production releases
Wiring it all together using CDK
Defining AWS Lambda traffic shifting
Deployment to the one-box frontend
Delaying the deployment to one lambda 10 minutes.
Defining the order of the deployment
Implementing session stickiness in Amazon Cloudfront
A Lambda@edge viewerRequest function
A Lambda@edge originRequest function
This article summarises an approach to software releasing in a 3-tier serverless web architecture, using AWS Lambda, Amazon API Gateway and Amazon CloudFront. More specifically, it addresses the problem of reducing the blast radius in case of a bad release by deploying the release gradually to an increasing percentage of the users by combining two techniques: traffic shifting for AWS Lambda for the backend and prod-one-box using Lambda@Edge, CloudFront and API Gateway in the frontend.
Reference architecture
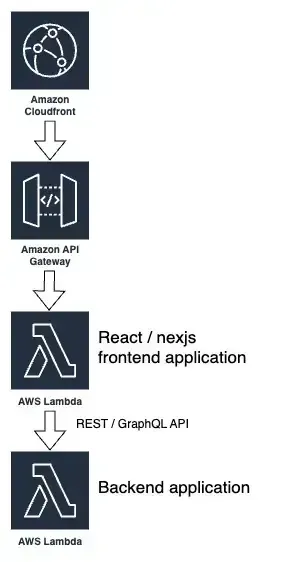
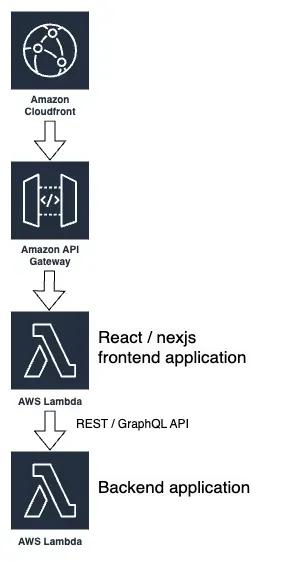
Let's assume an architecture with the following components:
- A web frontend, using any modern javascript framework such as React / NextJS, running on AWS Lambda behind a CloudFront distribution. An HTTP API Gateway provides an endpoint to CloudFront which serves as origin.
- A stateless REST / GraphQL backend offering an API to the frontend, exposed via a REST API Gateway and potentially behind a CloudFront distribution (which could be the same as before, mapping the API endpoints under a specific path, such as typically
/api) - State, if any, stored in a persistence layer, using any database engine. For the purpose of this article, this piece in the architecture is not relevant, but it highlights the fact that the other two layers are stateless.
The infrastructure is defined in CDK or any other infrastructure-as-code platform. For the purpose of this article and the solutions described later, I will assume CDK in typescript, but the same ideas are applicable in case of using other technologies.
No matter how many test stages and environments the software is deployed to before running in the production environment, even if there are automated tests and other mechanisms to prevent bad releases to impact customers, there is always the chance that things go wrong and bad releases are deployed to production environments. There are a variety of reasons for that:
- Differences in data in the production environment versus the test environments. That implies there could be scenarios that are not reproducible unless in the production environment.
- Configuration differences between environments. API keys, endpoints of 3rd party services, digital certificates, and other similar configurations are often exclusive to the production environment.
- Users navigation patterns. Websites exposed to the public are subject to an indefinite and unpredictable set of user navigation patterns, which in general cannot be reproduced accurately in test environments.
All this is to say, that there is certain probability that a production release, no matter how well tested it was in pre-production environments, can go wrong in production. In order to minimise the impact of such releases (reduce the blast radius), a gradual release should be implemented. The idea of a gradual release consists on opening up the new software version to end users traffic in small increments, so that in case of problems, they would affect a fraction of users before automated mechanisms roll back the release. As the release process progresses, more traffic is shifted from the old software version into the new one, gaining confidence gradually until 100% of the traffic is served with the new version and the release concludes.
It is a best practice to change your API in backwards-compatible increments. A backwards-compatible change means, in practice, that existing frontends would not fail when the new API is released. Depending on the exact technology of your API this can mean different things, but as a rule of thumb, in general, backwards-compatible changes are things like:
- Adding new endpoints or operations to your service. The old frontend would not use them, but their existence will not make the frontend fail.
- Adding new fields to existing outgoing messages. The old frontend does not read them, as long as it safely ignores unexpected response fields, it would not fail.
- Adding optional fields to existing incoming messages. The old frontend would not send them, but if they are optional and have reasonable default values, the backend will deal with them with no errors.
For the purpose of this article, I will assume that all API changes are backwards-compatible, which is a strongly recommended best practice, and has an interesting implication: The backend can be gradually rolled out while old versions of the frontend remain intact.
Notice however that frontend changes associated to backwards-compatible backend changes are generally backwards incompatible. That is to say, a new version of the frontend that makes use of new API features cannot generally operate on top of an old API version. For example, if the API added a new operation or response field and the frontend is calling this operation or expecting this field, if this frontend is configured on top of an older version of the API where such operations do not exist, it will most likely fail ungracefully.
The previous reasoning draws an interesting conclusion: If a release includes backend (API) changes and frontend changes, and I am going to do gradual rollout of both, the backend needs to be fully rolled out before the new frontend can connect to it. Either this or the backend and frontend partitions need to be coupled (the new frontend version connects exclusively to the new backend version). In this article I will use the former approach.
In the architecture above, gradually shifting frontend traffic requires some sort of session stickiness. The nature of a React frontend application consists on a series of static HTML pages that reference javascript files that change on every release. For example, a typical React application contains an almost empty index.html page referencing some static javascript/css files with unique names per release. These javascript / css files can be aggressively cached in a CDN such as CloudFormation since their names change on every release, and therefore there is no risk of collision. For the same reason, the javascript files from a previous release are not included in a new release.
If I were to simply split traffic randomly between two different versions of the frontend application, without any sort of session stickiness, every request for a javascript file would randomly be forwarded to a different instance of the frontend application. The probability that said file exists there, would be 50% if there are two partitions. If the index.html of the new version references even a small number of javascript files (such as 10-15) the probability that they all succeed is negligible and therefore, the page will not work for any user.
A possible solution implies copying the static assets to an S3 bucket and serve them from there. This is certainly a promising solution, however things can get more complicated if using a framework with Server Side Rendering like NextJS, where the server pages that reference the javascript/css static assets are dynamic, hence storing them in S3 is challenging.
In the architecture I have chosen, the frontend application runs in AWS Lambda and contains server-side rendered pages, hence I will propose a one-box setup consisting on two API Gateways (or two stages of the same API Gateway) with two different lambda functions running the same code underneath. One of this API Gateway+Lambda will be called one-box and will receive a precentage of user traffic as soon as it is possible (for example, 20%). The release to the other lambda is delayed for a fixed amount of time (for example, 10 minutes), so that if any condition is detected (via alarms) that would suggest that there is some problem with the release, it would be aborted and rolled back without distributing the new software version to the remaining percentage of users (in our example, 80%).
Given the constraints above, in order to fulfill the goal of incremental production releases you need the following mechanisms:
- Ability to control the order in which things are deployed. The frontend needs to wait until the backend is fully rolled out.
- Session stickiness. The solution needs to be able to consistently send users traffic to specific partitions of our frontend architecture.
- Timers and traffic increments. The system needs to be able to specify delays before specific parts of the release are done.
- Alarms and canaries. The solution needs to be able to detect problems with the ongoing release and automate the abort and rollback process accordingly.
As anticipated above, our architecture will contain the following components:
- Lambda traffic shifting for the backend. AWS Lambda provides the ability to shift traffic gradually between versions, using predefined AWS CodeDeploy templates. For example, you can choose to send traffic to the new version in increments of 10% every minute, which would imply that the backend lambda code is fully deployed in 10 minutes.
- Dual API Gateway+Lambda for the frontend.
- CloudFront session stickiness implemented using Lambda@Edge or CloudFront Functions.
- Alarms and canaries

The ideas above can be implemented using Cloudformation, Terraform or any similar technologies. Here I will use CDK for its simplicity and power.
I start by defining an auxiliary function that will create an Alias and a LambdaDeploymentGroup for our backend lambda. This function could also create the alarms and metrics that would automate the rollback decision process and attach them to the LambdaDeploymentGroup.
Then, I can use this function with our backend lambda, and connect the API gateway to the alias, not to the lambda itself.
I will duplicate the lambda and API gateway instances, and delay the deployment to the regular Lambda (the non one-box) by 10 minutes.
This is accomplished using a CDK CustomResource as follows:
The code for the OneBoxWaitResourceHandler Lambda function is as simple as this:
What all this does is creating a CDK resource (waitCustomResource) that simply takes 10 minutes to deploy while doing nothing (sleeping on a timer). During this time, the new frontend code will be deployed to the one-box lambda while the regular one still runs the old version.
As stated above, I opt for deploying the backend before the frontend. This is easy to configure with CDK. In CDK if a resource uses the output of another resource as input, they are naturally deployed in the right order.
You can always introduce a dependency on purpose if needed, with something like:
In the frontend, I enforce the following order of deploymennt:
- One box lambda and API Gateway.
- Custom resource that takes 10 minutes to deploy.
- Regular lambda and API Gateway.
The final piece of the puzzle is session stickiness in Amazon Cloudfront. As we saw before, randomly splitting incoming requests among the two frontend versions without taking into consideration the originating user would most likely render our page useless.
Session stickiness could be achieved in several ways, in our example, I will use:
This lambda calculates to which partition (one-box or regular) an incoming user request belongs. In order to make this decission, it takes into account a configured percentage of the traffic and assigns them to the partition by setting a request header (named, for example,
X-Req-Partition) with the partition value. In order to make this decision consistent for a given user, so that request from this user session always receive the same partition, different techniques can be implemented:- Setting a cookie on the first request of the session that would be honored in subsequent requests.
- Using the User-Agent header to calculate a pseudo-random hash that would be consistent accross requests, put this hash in module 100 and assign the one-box partition if the value is smaller than 20 (if I want 20% of the traffic assigned to the one-box partition).
This function reads the incoming
X-Req-Partition request header and honors it. Our Cloudfront distribution will be configured with the regular frontend API Gateway as origin, this function will change the Host header of the origin request to the URL of the one-box API Gateway if the X-Req-Partition header says so.The response from the origin cannot be cached by Cloudfront without taking into consideration that it differs depending on the value of the
X-Req-Partition header. Therefore, this function adds to the Vary response header from our origin the value X-Req-Partition. Additionally, I can configure the cache behaviour of the Cloudfront distribution to include this header in the cache key, and also I can add it to the http response, for debugging purposes (by observing the traffic with the browser network inspector I can see if a specific user is being served by the one-box or regular frontend).In this article we saw the challenges of doing gradual releases in a 3-tier serverless web architecture and offered solutions to reduce the blast radius of bad releases and automate the process so that releases can be done with confidence without human intervention.
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.