AWS Chalice Introduction
Developing applications has never been easier!
Published Feb 13, 2024
First of all, it's worth starting with a simple definition of "serverless." It's a cloud-native development model that allows developers to build and run applications without having to manage servers. In this series, I will focus exclusively on AWS among providers and try to cover as much as I can. If you notice any omissions or think something crucial is missing, please feel free to get in touch. Let's start by discussing which programming languages are supported. In fact, AWS supports a wide range of languages, including Node.js, Go, Python, Rust, Java, and more.
The question of which language to use ultimately comes down to personal preference. Use what you know well, but if we're talking about performance and speed, numerous benchmarks suggest that Rust and Go are currently leading the pack, with Node.js and Python not far behind. Java and C# appear to be trailing in these comparisons. In this article series, we will take a closer look at Chalice, a serverless framework derived from the Flask framework. The reason I love Chalice is its simplicity. As someone who has used AWS SAM, Zappa, and the Serverless Framework, I can say that if you want to do something serverless with Python, Chalice is the way to go!
pip install chaliceIf we want to create a project, we just say chalice new-project and choose what works for us from the options.
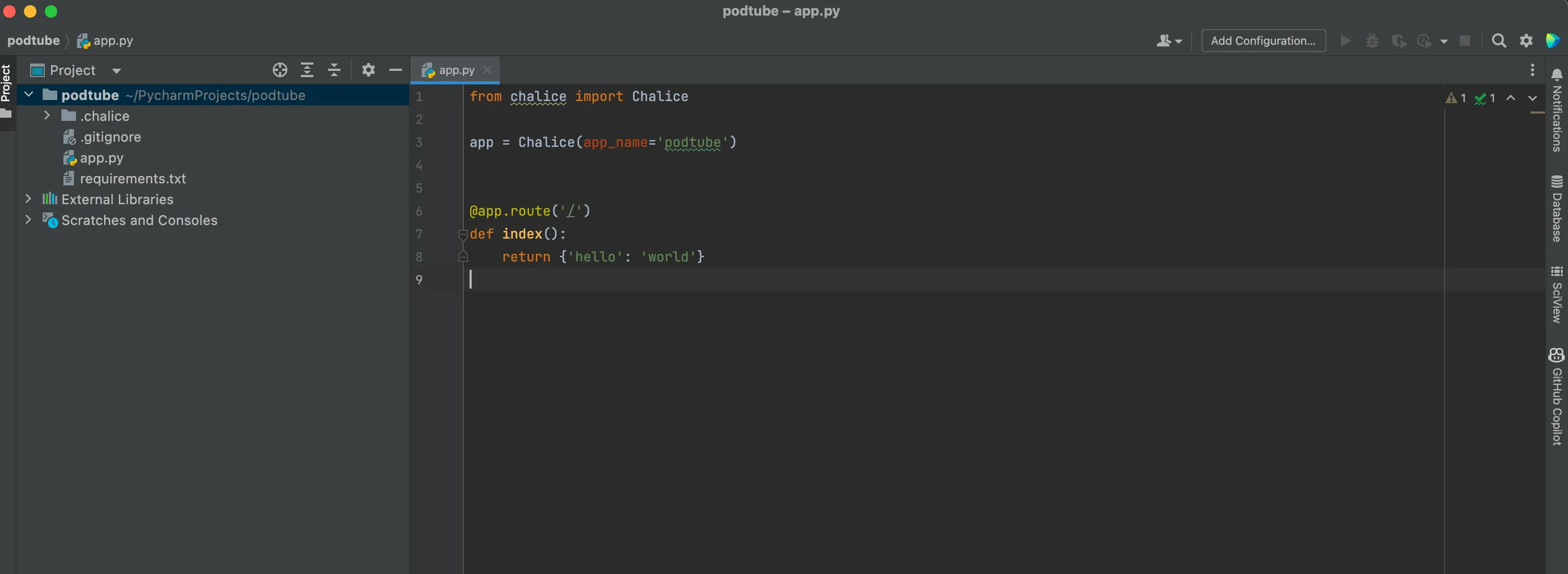
The screen you have seen is in fact the introduction of a project called podtube that I created, my goal is to use milk from flesh as much as I can in this article series and scribble something about chalice.
I’m starting with deploy, realizing that our AWS Credentials are ready, all we have to do is;
chalice deployyes we really deploy in such a simple way
chalice deleteWe can address this by asking, "What should we do if we want to deploy environments separately, such as having distinct setups for production and testing?" or "We need to deploy to a different AWS account, but our deployments keep defaulting to our primary account. What actions should we take?" Let's try to quickly answer these questions. First, we need the
config.json file so that we can differentiate between the test and production environments.Upon navigating to the
.chalice directory, you will find the config file. Here, we can actually separate configurations for test and production environments. We can specify details such as how much RAM each Lambda function should use, or set environment variables. I will provide a configuration example that includes all these details, serving as a complex, yet illustrative example. For now, we are capable of defining these settings.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
{
"version": "2.0",
"app_name": "podtube",
"automatic_layer": true,
"stages": {
"dev": {
"lambda_memory_size": 10240,
"reserved_concurrency": 100,
"lambda_timeout": 900,
"api_gateway_stage": "api",
"autogen_policy": false,
"api_gateway_policy_file": "policy-dev.json",
"environment_variables": {
"AWS_ACCESS_KEY_ID_IG": "BLA",
"AWS_ACCESS_SECRET_KEY_IG": "SECRET-BLA"
}
},
"test": {
"lambda_memory_size": 1024,
"reserved_concurrency": 100,
"lambda_timeout": 900,
"api_gateway_policy_file": "policy-test.json"
}
}
}What you saw above is that I have allocated the application to 2 stages on the dev side specifically reserved concurrency and set memory to you where api_gateway_policy file is again simply to which AWS services Let the relevant example lambda S3 access to SNS, just like you listen to this.
Now we can use this command line
chalice deploy --stage testHere is the most important point:
If you say Automatic Layer True, all the libraries that you use in the application chalice zips and pushups there by creating a layer under lambda.
Another question is that the work of switching between users is actually the point that we have to do there is even simpler let’s say you went through the terminal
tail -100 ~/.aws/credentialsyou have seen your registered accounts if your company/person or institution you are consulting is not using AWS and you are only using it as a hobby/your own business, most likely just default account If you will see, otherwise you will also have seen the accounts you added. Here, all we have to do is
chalice deploy --profile profile-nameIf you want to create a function that is not supported by Chalice or just wants to create Lambda functions but manages to process dependencies and deployments yourself if you do not want to use it For example you wrote a search algorithm on Python and you don’t want it to be endpoint and you want another NodeJS lambda to run it here as pure lambda and write NodeJS you can trigger via.
1
2
3
def search(event, context):
return {'hello': 'world'}You don’t need to name it here, but it’s good to add event, context. What does context contain here?
function_name– Lambda name.function_version– Function version.invoked_function_arn– Amazon Resource Name (ARN) used to call the function. Specifies whether the caller specifies a version number or alias.memory_limit_in_mb– The amount of memory allocated for the function.aws_request_id– Identifier of the request to call.log_group_name– Log groups.log_stream_name– Log flow for function instance.identity– (mobile apps) Information about the Amazon Cognito ID authorizing the request.cognito_identity_id– Authenticated Amazon Cognito ID.cognito_identity_pool_id– Amazon Cognito ID pool.client_context— (mobile applications) The client context provided by the client application to Lambda.
Now, let's start the project. The project will be an endpoint that is quite simple: as soon as we input a YouTube link, it will convert the video to MP3 and upload it to S3. Perhaps in the future, we might even send an email notification or something similar. But where will we write our code?
Amazon suggests, "As your app grows, you may reach a point where you prefer to configure your app across multiple files. You can create a
chalicelib directory, and anything in that directory is automatically included in the distribution package."Let's proceed and initially focus on YouTube videos. Later, we can explore other libraries for downloading videos from different platforms. For YouTube, I believe Pytube is the most suitable library.
pip install pytubeAfter installing, what we have to do is add this to the requirements.txt file
pytube==12.1.01
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from pytube import YouTube, exceptions
from abc import ABC, abstractmethod
import os
class VideoDownloader(ABC):
def download(self, url: str, path: str):
pass
class YoutubeDownloader(VideoDownloader):
def __init__(self):
self.out_file = None
def download(self, url: str, path: str = "./tmp"):
if url is None:
raise ValueError("URL is None")
try:
video = YouTube(url).streams.filter(only_audio=True).first()
self.out_file = video.download(output_path=path)
self.convert_to_mp3()
except exceptions.RegexMatchError:
raise ValueError("Invalid URL")
except exceptions.VideoUnavailable:
raise ValueError("Video is unavailable")
def convert_to_mp3(self):
base, ext = os.path.splitext(self.out_file)
new_file = base + '.mp3'
os.rename(self.out_file, new_file)I created a python file named downloader and wrote a little code for youtube and maybe other platforms that we would use later, and I added it to chalice lib.
First of all, there will be a POST method here, we have a few methods for this, one of them is query string URL-path and the other is body request.
Body Request:
- If the values are not human readable, such as serialized binary data.
- When you have lots of arguments.
1
2
3
4
5
def users():
body = app.current_request.json_body
username = body["username"]
return {'name': username}Query string:
- When you want to be able to call them manually while developing the code, e.g. with curl
- If you are already sending a different content type like application/octet-stream.
1
2
3
4
def users():
name = app.current_request.query_params.get('name')
return {'name': name}The most suitable situation for our case is to proceed as a query parameter. You can see the URL we will create as an example below.
0.0.0.0/convert?v=b-I2s5zRbHgIf we want to test it in our local, all we have to do is;
chalice local1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from chalice import Chalice
from chalicelib.downloader import YoutubeDownloader
app = Chalice(app_name='podtube')
def convert():
if app.current_request.query_params is not None:
if 'v' not in app.current_request.query_params:
return {'error': 'Parameter v is missing'}
else:
url_extension = app.current_request.query_params.get('v')
yt = YoutubeDownloader()
yt.download("https://www.youtube.com/watch?v={url_part}".format(url_part=url_extension))
return {'success': 'Video downloaded'}
else:
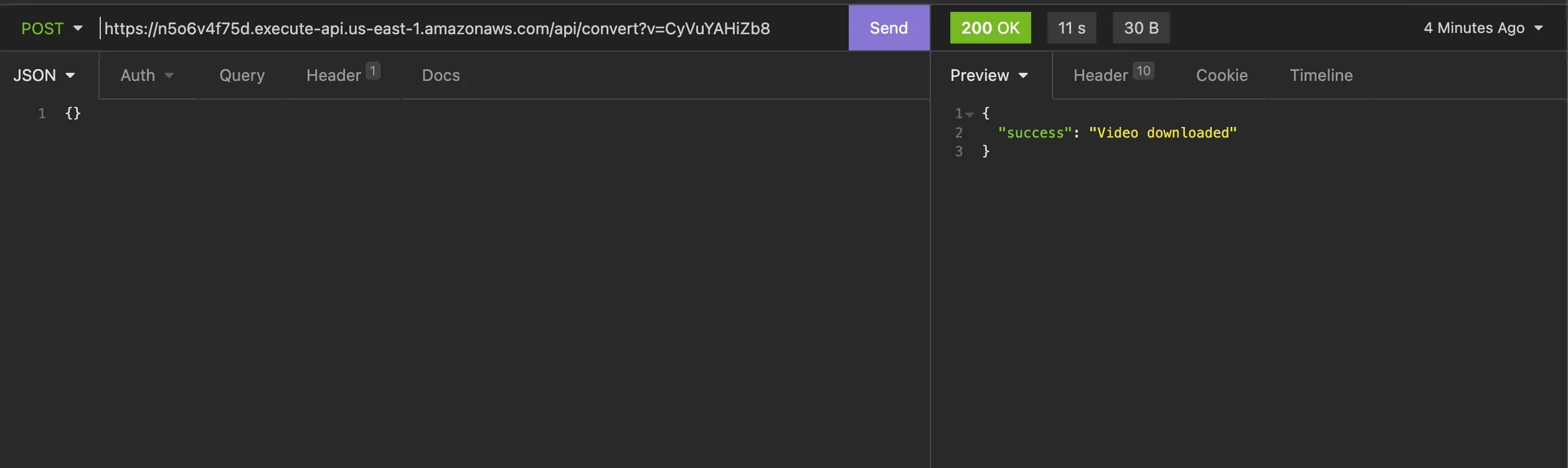
return {'error': 'No video URL provided'}Yes, we made a request and our video was downloaded. What we need to do now is to first transfer the file to our tmp file to S3 and then delete it from tmp.
First, I created a py file called AWS helper and then made a small development for the operations I would perform in S3.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import boto3
import botocore.exceptions
class S3:
def __init__(self, bucket_name):
self.s3 = boto3.client("s3")
self.bucket_name = bucket_name
if not self.check_if_bucket_exists():
print("okay, bucket does not exist")
self.create_bucket()
else:
print("bucket exists")
def check_if_bucket_exists(self):
try:
self.s3.head_bucket(Bucket=self.bucket_name)
return True
except botocore.exceptions.ClientError:
return False
def create_bucket(self):
print("Creating bucket: " + self.bucket_name)
self.s3.create_bucket(Bucket=self.bucket_name)
def upload_file(self, file_path, s3_path):
self.s3.upload_file(file_path, self.bucket_name, s3_path)
def download_file(self,s3_path):
return self.s3.generate_presigned_url(
ClientMethod="get_object",
Params={
"Bucket": self.bucket_name,
"Key": s3_path,
},
ExpiresIn=3600,
)I am using presigned url here. AWS explains it this way: When you create a pre-signed URL, you need to provide your security credentials and then specify a package name, an object key, an HTTP method (PUT to load objects), and an expiration date and time. Pre-signed URLs are valid only for the specified period. That is, you must initiate the action before the expiration date and time. So we can say that it is a good thing for security.
Well, everything is fine, but does lambda have access to S3? Yes, what we need to do here is to write a policy. I have now passed the security issues and allowed all of them. If you are developing something for prod, I recommend you to be more careful in the policy section here.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*"
},
{
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": "*"
}
]
}and then we need to edit config.json and deploy it with chalice deploy
1
2
3
4
5
6
7
8
9
10
11
12
{
"version": "2.0",
"app_name": "podtube",
"automatic_layer": true,
"stages": {
"dev": {
"api_gateway_stage": "api",
"autogen_policy": false,
"api_gateway_policy_file": "policy.json"
}
}
}
Thank you for your passion I hope it will be helpful for your project!
Comments
Log in to comment