AWS open source newsletter, #189
A weekly round up of the latest open source news, projects, and events that every open source developer should know about.
Ricardo Sueiras
Amazon Employee
Published Feb 18, 2024
Celebrating open source contributors
s3-restore-and-copy-progress-monitoring
aws-account-tag-association-imported-portfolios
Demos, Samples, Solutions and Workshops
automated-meeting-scribe-and-summarizer
The best from around the Community
Data Solutions Framework on AWS
Migrate CloudFormation templates to AWS CDK Applications with CDK Migrate
Building your containers on Windows with Finch
FOSSASIA April 8th-10th, Hanoi, Vietnam
Everything Open April 16th-18th, Gladstone Australia
Cortex Every other Thursday, next one 16th February
Welcome to issue #189 of the AWS open source newsletter, the newsletter where we search high and low to provide you with the best open source on AWS content.
As always, this week we start with a round up of some freshly baked new projects for you to practice your four freedoms. This week we have projects that help you find your RDS instances, automate tasks from your online Chime calls, a very nice visual file browser for your Amazon S3 buckets, a tool to help you track and manage copying files from your S3 storage buckets, an active-active multi region cluster solution for Redis, and more! Also featured in this weeks edition is open source goodness on projects such as Redis, Odoo, git-sync, Apache Kafka, AWS CDK, AWS Chalice, Testcontainers, Apache Airflow, Finch, Data Solutions Framework on AWS, AWS Amplify, Jupyter,MySQL, PostgreSQL, OpenSearch, and OpenJD.
Make sure you stick to the very end and check out the Events section at the end - and if you are running an open source event and want me to include it for broader visibility, please drop me a message at ricsue at amazon dot com.
Feedback
Please please please take 1 minute to complete this short survey.
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Takafumi Miyanaga, Olly Pomeroy, Justin Alvarez, Maish Saidel-Keesing, Adam Keller , Alec Hewitt, Will Sorenson, Tamer Solima, Kimate Richards, Adam Chernick, Chi Tran, Michael Jedrzejczyk, Steve Dille, Sudhir Kumar, Mark Greenhalgh, Jonathan Katz, Sunil Kamath, Lotfi Mouhib, Dzenan Softic, and Vincent Gromakowski, Deny Julianto, Warner Bell, Marco Gonzalez, Subbusainath, Kemalcan Bora, and Abhishek Gupta
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution. The projects mentioned here do not represent any formal recommendation or endorsement, I am just sharing for greater awareness as I think they look useful and interesting!
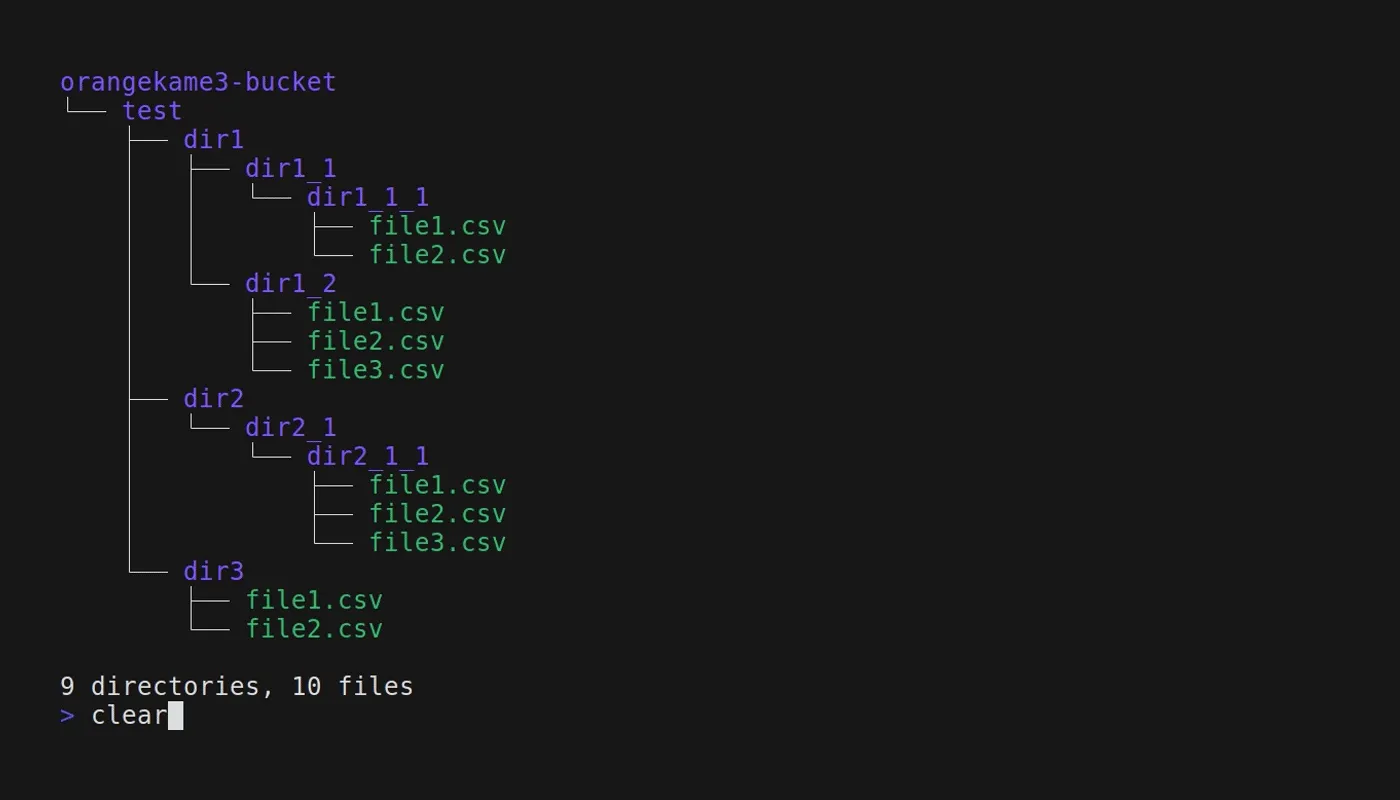
stree this project from Takafumi Miyanaga is a CLI tool designed to visualize the directory tree structure of an S3 bucket. By inputting an S3 bucket/prefix and utilizing various flags to customize your request, you can obtain a colorized or non-colorized directory tree right in your terminal. Whether it's for verifying the file structure, sharing the structure with your team, or any other purpose, stree offers an easy and convenient way to explore your S3 buckets. I love it!
rds-instances-locator There are times when you want to know exactly in which physical AZ your RDS instances are running. For those instances, you can use this script to help you. Details on the various scenarios it has been designed for as well as example commands make this something you can easily get started with. No more hide and seek RDS!
active-active-cache is a repo that helps you build a solution that implements an active-active cache across 2 AWS regions, using ElastiCache for Redis. This solution is automated with CDK and SAM.
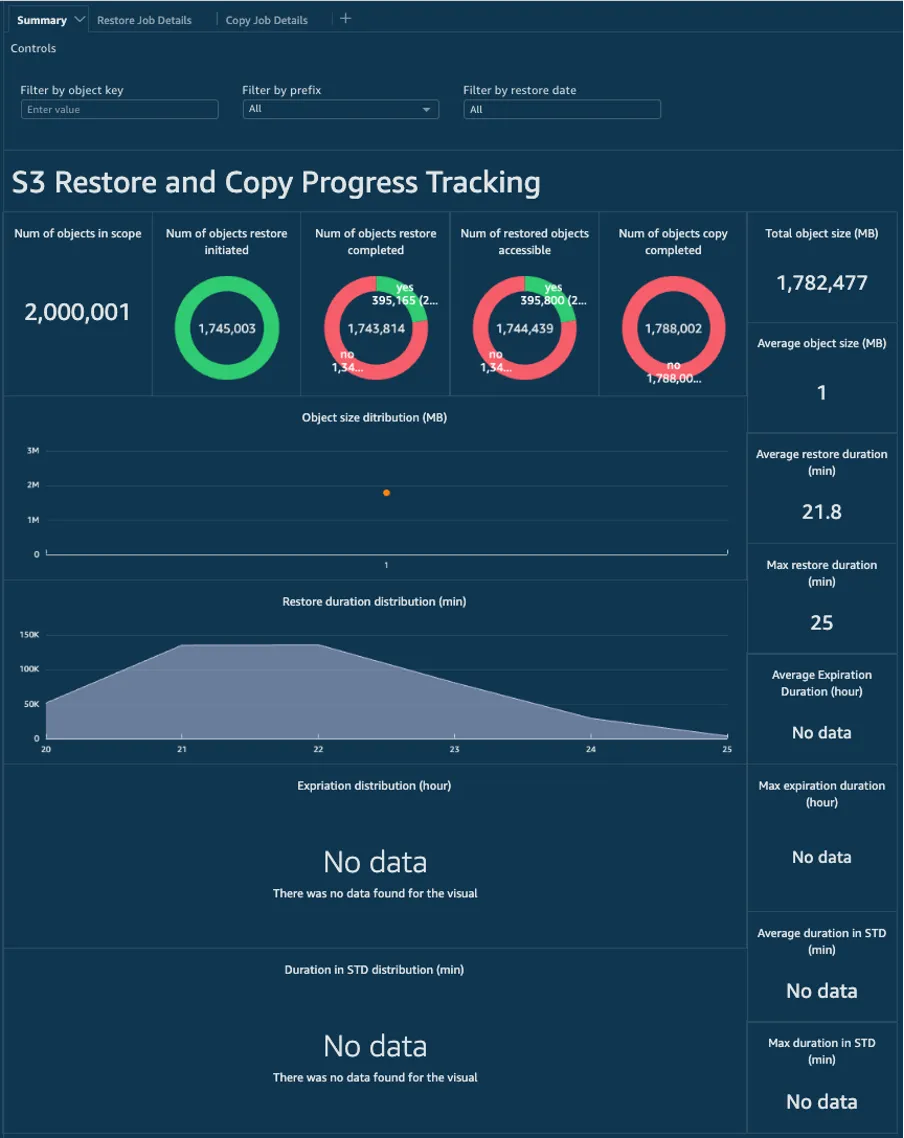
s3-restore-and-copy-progress-monitoring this is a very comprehensive and polished repo that provides an example of how you can restore data that you have stored in S3, providing you a single visualised dashboard to monitor the restore and copy progress within a defined scope.
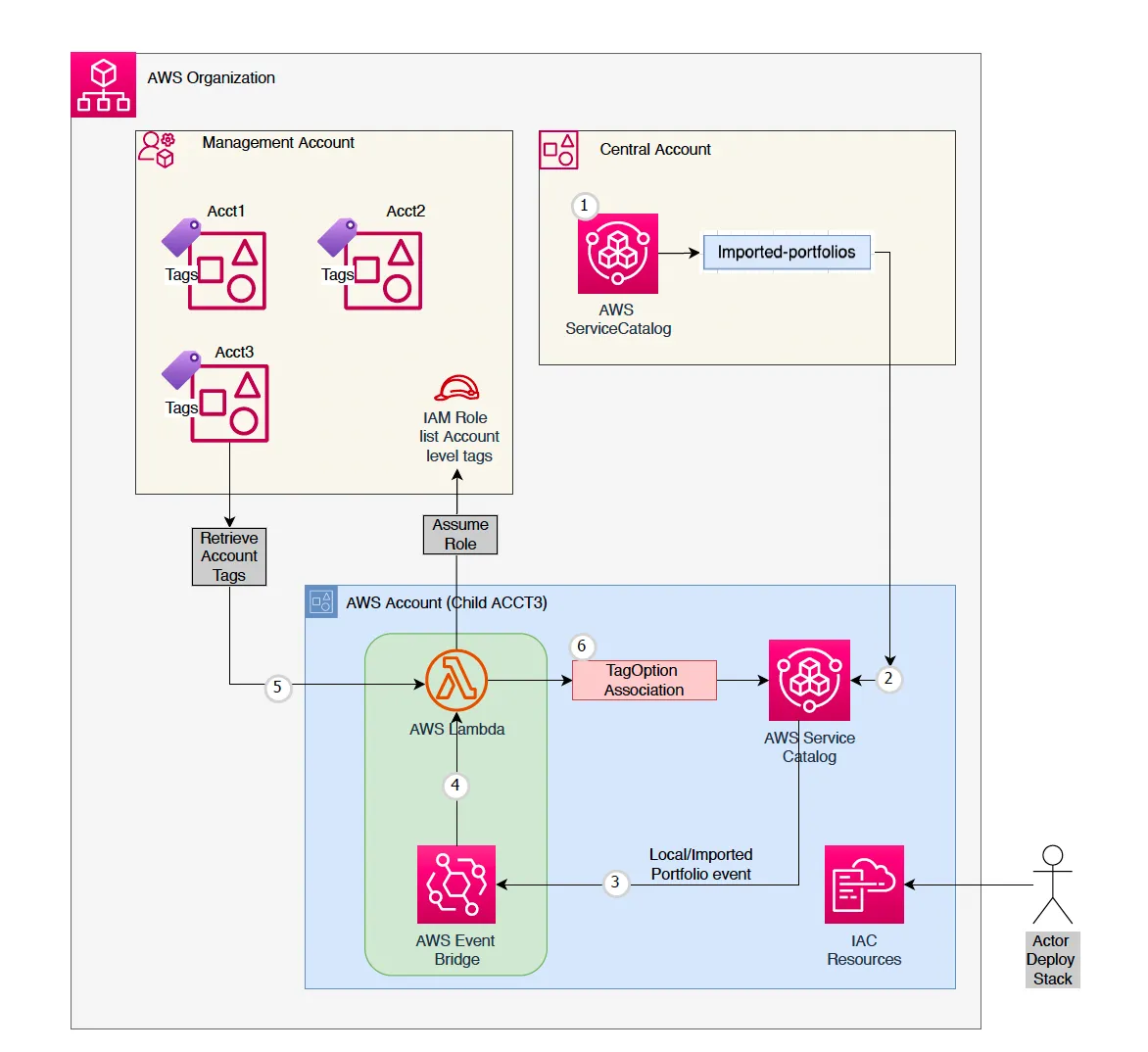
aws-account-tag-association-imported-portfolios This repo provides a solution that is designed to automate associating account level tags to shared and local portfolios in the AWS environment which in turn inherits the tags to launched resources. AWS ServiceCatalog TagOption feature is used for this association.
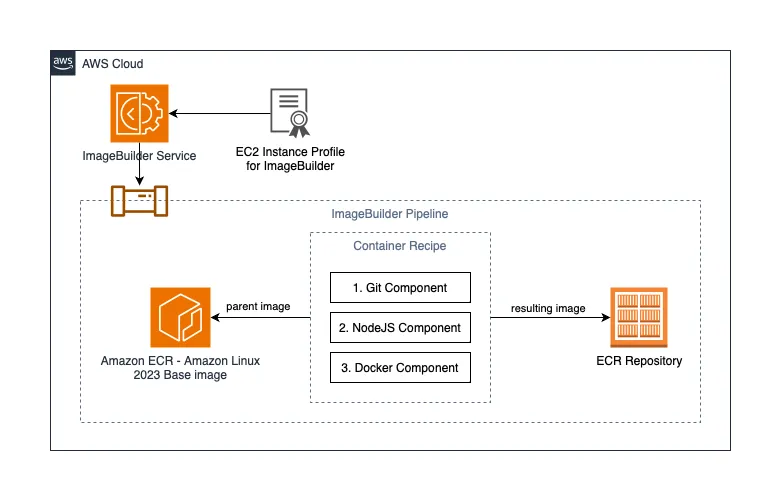
aws-cdk-imagebuilder-sample this repo uses AWS CDK (TypeScript) that demonstrates how to create a fully functional ImageBuilder pipeline that builds an Amazon Linux 2023 container image, installing git, docker and nodejs, all the way to pushing the resulting image to an ECR repository.
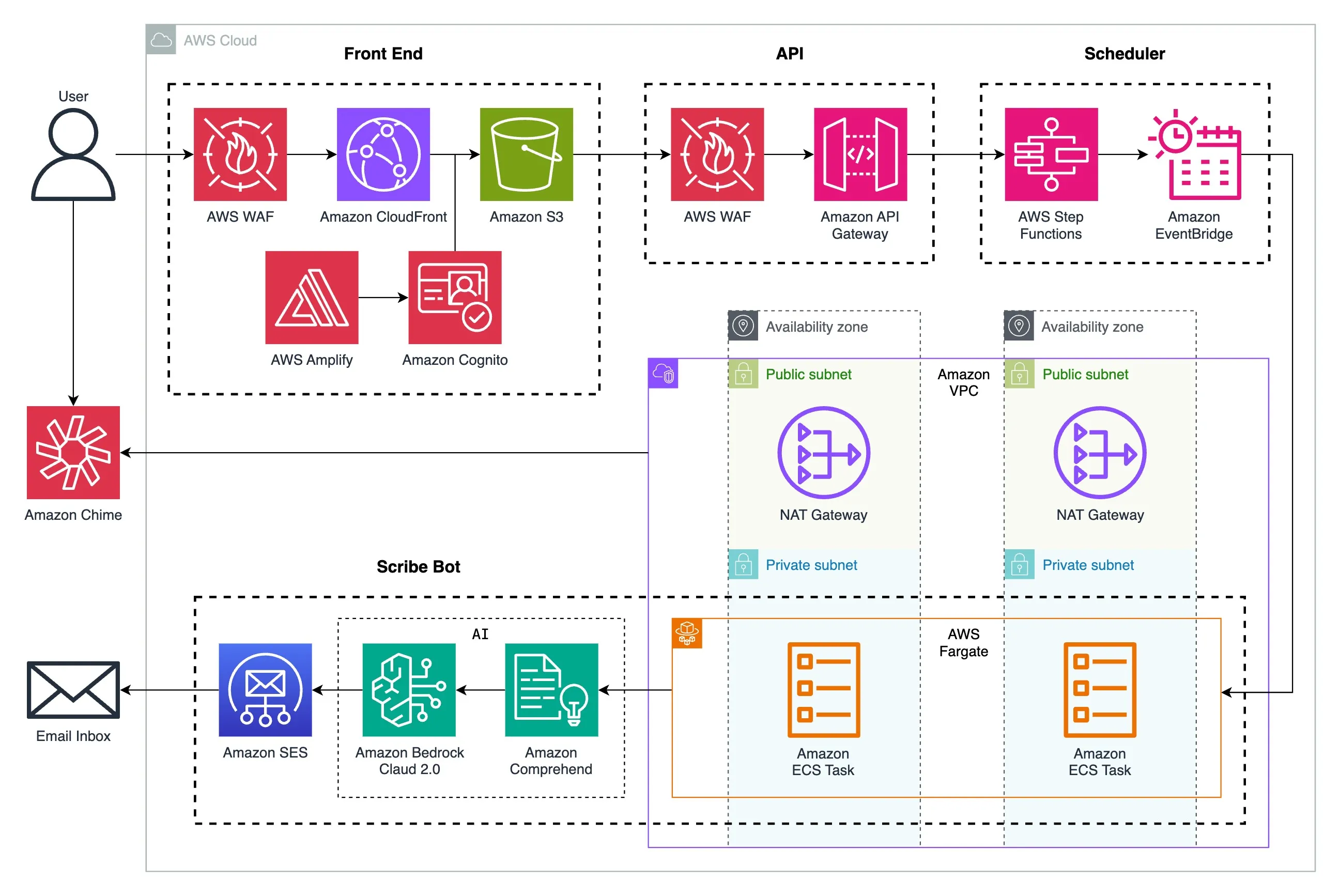
automated-meeting-scribe-and-summarizer Using this application's website, you can invite an AI-assisted scribe bot to your upcoming Amazon Chime meeting(s) to get a follow-up email with the attendee list, chat history, attachments, and transcript, as well as a summary and action items. You don't even need to be present in a meeting for your invited scribe bot to join. Each scribe bot is linked to your email for identification. The scribe bot also redacts sensitive personally identifiable information (PII) by default, with the option to redact additional PII. Very neat indeed.
Each week I spent a lot of time reading posts from across the AWS community on open source topics. In this section I share what personally caught my eye and interest, and I hope that many of you will also find them interesting.
To get things going this week we have AWS Community Builder Deny Julianto who shares how you can install the open source project Odoo, which provides a comprehensive suite of business applications such as ERP, CRM, e-Commerce, and more in the post, How to Install Odoo 17 on Amazon EC2. git-sync is a super handy tool that provides you with the ability to sync a GitHub repo to a local filesystem, and I have used it extensively with distributed systems that need to pull from a single source of truth. AWS Community Builder Warner Bell has put together Automating CloudFormation Deployments with Git sync & GitHub Actions providing you with a quick recipe on using git-sync to synchronise your stacks from a CloudFormation template stored in a remote Git repository. AWS Community Builder Marco Gonzalez help Python developers get started with Apache Kafka in the post, Amazon MSK 101 with Python.
AWS Community Builder Subbusainath provides a guide on the different kinds of constructs you can use and create in AWS CDK in the post, How to create L1,L2 and L3 CDK Constructs ? and When to use it ? At the end of the post you are provided with a list of comparisons between the three, which should help you in your decision making. It has been a while since I have seen content on AWS Chalice, a framework for developing serverless applications in Python, but AWS Community Builder Kemalcan Bora has fixed that with the post, AWS Chalice Introduction. A good read, so well worth checking that out. The final post in this weeks round up is from my colleague Abhishek Gupta, gopher extraordinaire, who this week looks at how you can use Testcontainers with your Go applications in his post, Run and test DynamoDB applications locally using Docker and Testcontainers.
I shared this open source project back in #178 of this newsletter, and so it was great to see Lotfi Mouhib, Dzenan Softic, and Vincent Gromakowski put together the official announcement blog post, Announcing the Data Solutions Framework on AWS. Data Solutions Frameworks (DSF) is an opinionated open source framework that accelerates building data solutions on AWS, which makes it easier to develop solutions and save effort and time that you can spend on your specific use case.
I have been using Finch extensively since the beginning of this year, after having received a new M1 macbook, and agonising over what tools to install on my fresh install. I decided it was time to ditch Docker (nothing wrong with it) and give Finch a try. One of the first things I did was to rework how mwaa-local-runner, a project that makes it simple for developers to run Apache Airflow, and refactor it to use Finch. It was pretty straightforward, with a few gotchas. You can hear all about it in my post, Using Finch to run Apache Airflow using mwaa-local-runner.
- Apple Vision Pro and AWS Amplify Part 1 – Authentication is the first of a three part blog post that shows you how you can use AWS Amplify to quickly get started building with the Apple Vision Pro using Xcode and Amazon Web Services (AWS) [hands on]
- Secure connectivity patterns for Amazon MSK Serverless cross-account access walks you through multiple solution approaches that address the MSK Serverless cross-VPC and cross-account access connectivity options, and looks at the advantages and limitations of each approach
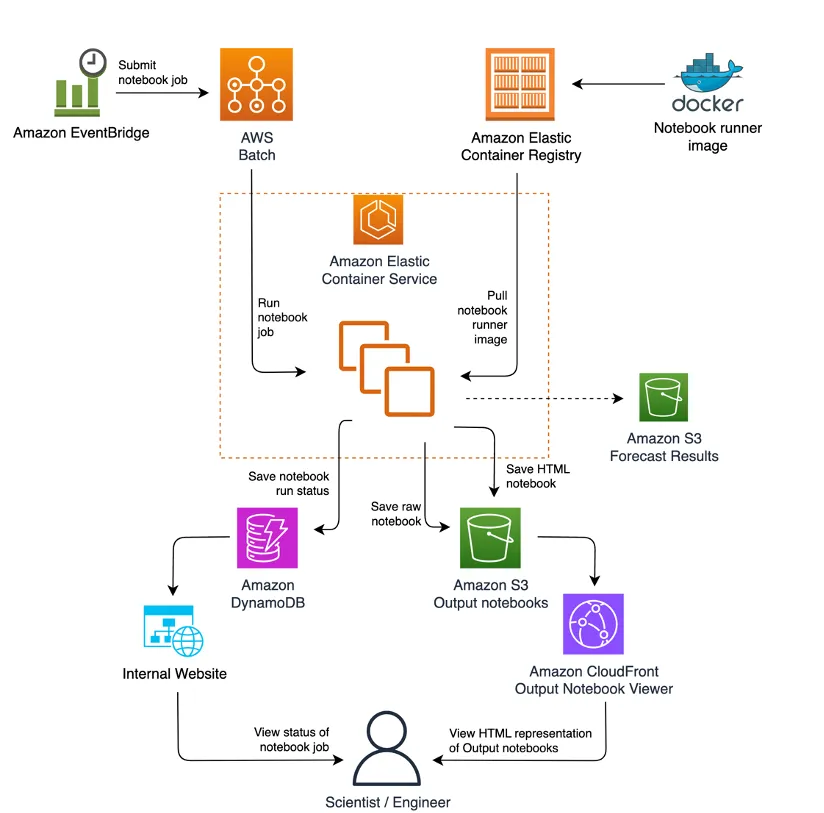
- Amazon’s renewable energy forecasting: continuous delivery with Jupyter Notebooks is a nice study in how to seemlessly move your data scientist work from Jupyter note books to production
- Marqeta supercharges MySQL workloads using Amazon EBS io2 Block Express discusses the storage-centric challenges of running high-performance database workloads in the cloud and how Nitro-based Amazon Elastic Cloud Compute (Amazon EC2) and Amazon Elastic Block Store (Amazon EBS) io2 Block Express can help
- Identify Java nested dependencies with Amazon Inspector SBOM Generator looks at how to navigate the challenges of uncovering nested Java dependencies, guiding you through the process of analysing JAR files and uncovering these dependencies
- Accelerate generative AI workloads on Amazon Aurora with Optimized Reads and pgvector dives into how using Optimized Reads improves performance for vector workloads running on Amazon Aurora PostgreSQL with pgvector, specifically using HNSW indexing
Starting August 15th 2024, the AWS SDK for .NET will end support for .NET Framework 3.5 and will change the minimum .NET Framework version to 4.6.2. Check out the blog post from Norm Johanson, Important changes coming for .NET Framework 3.5 and 4.5 targets of the AWS SDK for .NET, that covers everything you need to know.
Amazon Relational Database Service (Amazon RDS) for MySQL now supports MySQL minor version 8.0.36. We recommend that you upgrade to the latest minor versions to fix known security vulnerabilities in prior versions of MySQL, and to benefit from the bug fixes, performance improvements, and new functionality added by the MySQL community. You can leverage automatic minor version upgrades to automatically upgrade your databases to more recent minor versions during scheduled maintenance windows. You can also leverage Amazon RDS Managed Blue/Green deployments for safer, simpler, and faster updates to your MySQL instances.
A couple of updates from folks using the managed service of OpenSearch.
First up is news that Amazon OpenSearch Service now lets you update cluster volume size, volume type, IOPS and throughput without requiring a blue/green deployment. This makes it easier for you to make changes to your EBS settings without having to plan upfront for a blue/green deployment. Previously, when you updated volume size, volume type, IOPS and throughput on your domain, OpenSearch Service used a blue/green deployment mechanism to make the change. While blue/green deployments are meant to avoid any disruption to your clusters, as the deployment utilises additional resources on the domain, it is recommended that you perform them during low traffic periods. Now, you can update volume related cluster configuration without requiring a blue/green deployment, ensuring minimal performance impact to your online traffic and avoiding any potential disruption to your cluster operations. This feature is available for OpenSearch Service domains with current generation instances, and when the volume size per data node is within 3 TiB. You can use the dry-run option to check whether your change requires a blue/green deployment.
Following that is news that Amazon OpenSearch Serverless now offers improved security options for workloads with the support of Transport Layer Security (TLS) version 1.3. OpenSearch Serverless is the serverless option for Amazon OpenSearch Service that makes it simpler for you to run search and analytics workloads without having to think about infrastructure management. An OpenSearch Serverless collection is a group of OpenSearch indexes that work together to support a specific workload or use case. OpenSearch clients and API can now connect to the collection endpoint using TLS version 1.3. TLS version 1.3 offers enhanced security and performance as compared to older TLS versions. In addition, collection endpoints now supports perfect forward secrecy, which provides additional safeguard against eavesdropping of encrypted data.
AWS has released new tools for the Open Job Description (OpenJD) specification for describing portable render jobs. This update includes a set of three Python libraries and tools packages: openjd-cli, openjd-model, and openjd-sessions. The openjd-cli package provides a command-line tool that you can use to develop and run OpenJD jobs on your own workstation or render farm. The openjd-model and openjd-sessions packages provide functionality that you can use to integrate OpenJD into your own render farm and pipeline software. These libraries and tools packages are provided under the Apache 2.0 license and available on GitHub and the PyPI package manager for Python. The AWS Thinkbox Deadline team designed OpenJD with current and emerging visual technologies in mind. Many graphics workflows, such as 3D scene rendering and photogrammetry, specialize at the application level but share much of their ingest, file types, and automation in software pipelines. OpenJD is extensible and provides a structure for defining parameters for you to integrate custom applications and computing architectures. OpenJD is a way to add an interoperability layer between your render job authoring tools and your render solutions. Use these new tools to build OpenJD support quickly into your tools and solutions.
Adam Keller is back on your YouTube screen, this time he walks you through one of the latest features in AWS CDK, CDK Migrate. CDK Migrate helps customers that want to migrate from CloudFormation to the AWS CDK.
As someone who has recently moved from Docker to using Finch (read more about that here), Olly Pomeroy, Justin Alvarez, and Maish Saidel-Keesing take you through a deep dive into the new release for Finch, one that any of you Windows users should get excited about.
If you are planning any events in 2024, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
I recently found this GitHub repo, open-source-events that is a curated set of open source events for 2024. Go check it out and see what 2024 is looking like.
The FOSSASIA Summit is one of Asia's Premier Open Technology conference with thousands of participants and an Open Tech exhibition taking place every year in March, and this year it will be in the vibrant city of Hanoi, Vietnam. A number of my AWS colleagues will be there as well as myself, so I look forward to meeting with some of you. You can find out more details about this event by checking out the FOSSASIA event page
Everything Open is an open source event where the open source community come together for three days to share updates on their projects and learn about the latest in open technologies from leading community members. The conference will cover a broad range of topics across three days. You can expect to see talks from areas such as the Linux ecosystem, including the Kernel, distros and drivers. There will also be a number of presentations on open source software and open hardware, alongside talks on Galleries, Libraries, Archives and Museums (GLAM), open data, open government, and much more. Another key feature will be talks on building and managing communities around open technologies. I will be attending and doing some open source talks, as well as finding out more about the local open source community.
Check out the event websitefor more details, and hope to see some of you there.
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Remember to check out the Open Source homepage for more open source goodness.
One of the pieces of feedback I received in 2023 was to create a repo where all the projects featured in this newsletter are listed. Where I can hear you all ask? Well as you ask so nicely, you can meander over to newsletter-oss-projects.
Made with ♥ from DevRel
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.
Comments
Log in to comment