14 LLMs fought 314 Street Fighter matches. Here's who won
I benchmarked models in an actual chatbot arena
Banjo Obayomi
Amazon Employee
Published Apr 1, 2024
Last Modified May 3, 2024
Have you ever wondered what would happen if we created a new type of benchmark for large language models (LLMs) that goes beyond the typical question-answering and text generation tasks? What if we had an arena where the models could compete against each other in challenges entirely outside their designed purpose?
That's precisely what I explored by pitting LLMs against one another in the classic arcade game, Street Fighter III. In this post I'll go into the details of how I built this unique arena and the fascinating insights learned from watching LLMs battle it out on the virtual streets of Metro City.

The arena was set up using an emulator running Street Fighter III powered by Diambra and from the work of Stan Girard who open sourced his test bed for this benchmark.
To begin, two random LLMs on Amazon Bedrock are selected to control Ken, and then the test bed executes the following steps:
The current state of the game was continuously read such as the character location, health, and score. This information was then translated into a prompt with all the relevant context for the LLM such as available moves and recommended strategies.
With the relevant context, a system prompt can be crafted and be sent to the corresponding LLM via Bedrock serverless API. Upon receiving the prompt, each LLM analyzes the game state and picks moves.
Finally, the chosen moves were translated back into game commands and executed within the emulator. This closed loop allowed the LLMs to actively participate in the game, effectively "playing" against each other. Now, lets see how the models stacked up against each other.
I tracked each LLM's performance using an Elo rating system, similar to those used in chess rankings. This system provided a dynamic leaderboard, showcasing which models adapted best to the fast-paced environment of Street Fighter III. I ran 314 matches with 14 different models
| Model | Elo |
|---|---|
| 🥇 claude_3_haiku | 1613.45 |
| 🥈 claude_3_sonnet | 1557.25 |
| 🥉 claude_2 | 1554.98 |
| claude_instant | 1548.16 |
| cohere_light | 1527.07 |
| cohere_command | 1511.45 |
| titan_express | 1502.56 |
| mistral_7b | 1490.06 |
| ai21_ultra | 1477.17 |
| mistral_8x7b | 1450.07 |
The smaller models outperformed larger models in the arena likely due to their lower latency which allowed for quicker reaction times and more moves per match. This highlights an interesting trade-off between size and speed when it comes to playing real time games. Also, no surprise that Anthropic's Claude models top the list, they are currently the best ranked models on several benchmarks.

While the leaderboard show which model is on top diving deeper into the matches themselves revealed several insights about how LLMs approached the game.
The experiment was not without its quirks. LLMs, while highly intelligent, are not infallible and sometimes displayed behaviors that were both fascinating and humorous:
Hallucinations: Instances of "invalid moves" were recorded, where models would generate actions not applicable or possible within the game. This included moves like "Special Move," "Jump Cancel," and even "Hardest hitting combo of all," showcasing the models' attempts to apply their knowledge creatively.
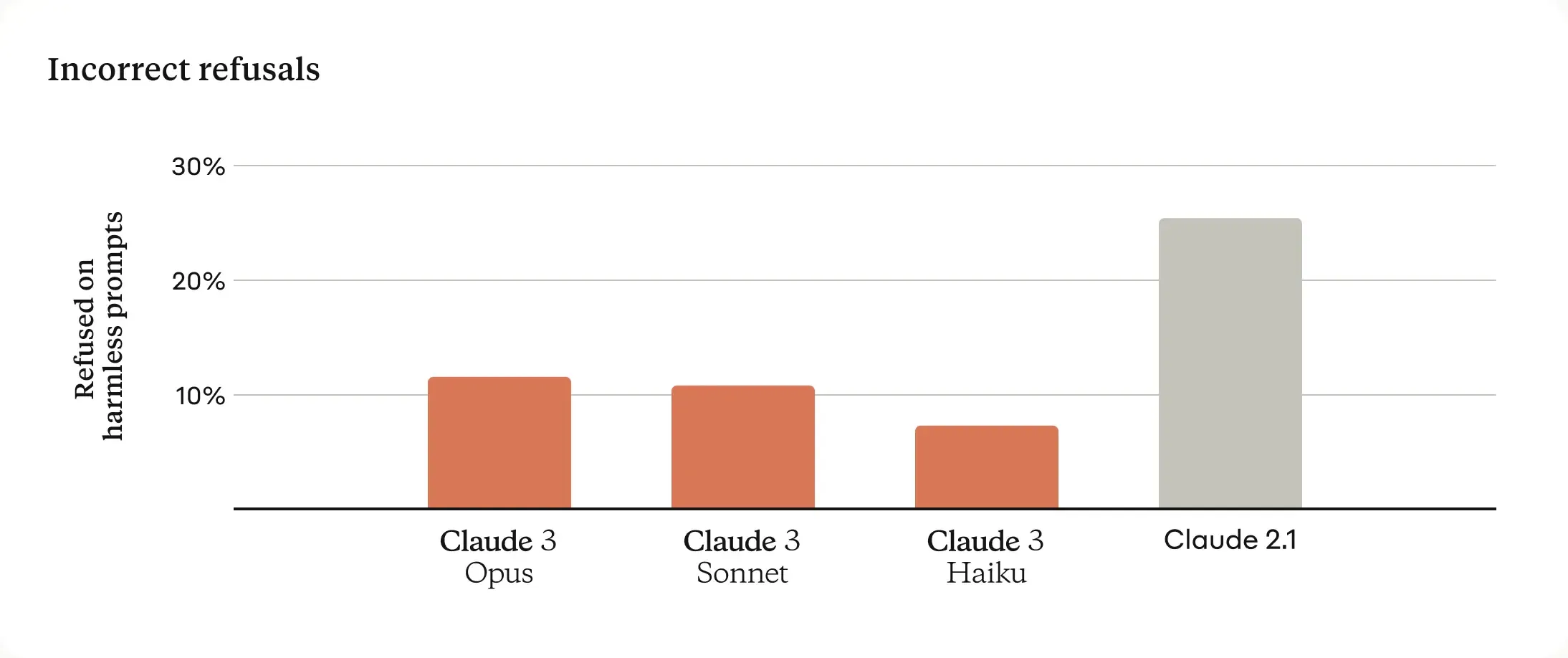
Refusal to play: Claude 2.1 refused to play and would say" I apologize, upon reflection I do not feel comfortable recommending violent actions or strategies, even in a fictional context." Thankfully the Claude 3 models show a more nuanced understanding of requests, recognize real harm, and refuse to answer harmless prompts much less often.
Personalized Playstyles: Each LLM seemed to develop its own distinct playstyle. Some favored aggressive tactics, while others took a more defensive, counter-attacking approach. While other just spammed the same move over and over.

Ready to run the benchmark on your own? All code and documentation are on GitHub. I'm curious how folks can tweak the prompts, add new LLM contenders, or explore model behaviors further. If you're interested in playing with the winning Claude 3 models check out my getting started guide.
Have an idea or question about the arena? Leave a comment below, and lets build!
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.