Generative AI Apps With Amazon Bedrock: Getting Started for Go Developers
An introductory guide to using the AWS Go SDK and Amazon Bedrock Foundation Models (FMs) for tasks such as content generation, building chat applications, handling streaming data, and more.
Abhishek Gupta
Amazon Employee
Published Oct 19, 2023
Last Modified May 22, 2024
This article is an introductory guide for Go developers who want to get started building Generative AI applications using Amazon Bedrock, which is a fully managed service that makes base models from Amazon and third-party model providers accessible through an API.
We will be using the AWS Go SDK for Amazon Bedrock, and we'll cover the following topics as we go along:
- Amazon Bedrock Go APIs and how to use them for tasks such as content generation
- How to build a simple chat application and handle streaming output from Amazon Bedrock Foundation Models
- Code walkthrough of the examples
The code examples are available in this GitHub repository
You will need to install a recent version of Go, if you don't have it already.
Make sure you have configured and set up Amazon Bedrock, including requesting access to the Foundation Model(s).
As we run the examples, we will be using the AWS Go SDK to invoke Amazon Bedrock API operations from our local machine. For this, you need to:
- Grant programmatic access using an IAM user/role.
- Grant the below permission(s) to the IAM identity you are using:
1
2
3
4
5
6
7
8
9
10
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "bedrock:*",
"Resource": "*"
}
]
}If you have used the AWS Go SDK before, you will be familiar with this. If not, please note that in the code samples, I have used the following to load the configuration and specify credentials for authentication:
1
cfg, err := config.LoadDefaultConfig(context.Background(), config.WithRegion(region))When you initialize an
aws.Config instance using config.LoadDefaultConfig, the AWS Go SDK uses its default credential chain to find AWS credentials. You can read up on the details here, but in my case, I already have a credentials file in <USER_HOME>/.aws which is detected and picked up by the SDK.The Amazon Bedrock Go SDK supports two client types:
- The first one, bedrock.Client, can be used for control plane-like operations such as getting information about base foundation models, or custom models, creating a fine-tuning job to customize a base model, etc.
- The bedrockruntime.Client in the bedrockruntime package is used to run inference on the Foundation models (this is the interesting part!).
To start off, let's take a look at a simple example of the control plane client to list foundation models in Amazon Bedrock (error handling, logging omitted):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
region := os.Getenv("AWS_REGION")
if region == "" {
region = defaultRegion
}
cfg, err := config.LoadDefaultConfig(context.Background(), config.WithRegion(region))
bc := bedrock.NewFromConfig(cfg)
fms, err := bc.ListFoundationModels(context.Background(), &bedrock.ListFoundationModelsInput{
//ByProvider: aws.String("Amazon"),
//ByOutputModality: types.ModelModalityText,
})
for _, fm := range fms.ModelSummaries {
info := fmt.Sprintf("Name: %s | Provider: %s | Id: %s", *fm.ModelName, *fm.ProviderName, *fm.ModelId)
fmt.Println(info)
}We create a bedrock.Client instance and use it to get the supported Foundation Models in Amazon Bedrock using ListFoundationModels API.
Clone the GitHub repository, change to the correct directory:
1
2
3
4
5
git clone https://github.com/build-on-aws/amazon-bedrock-go-sdk-examples
cd amazon-bedrock-go-sdk-examples
go mod tidyTo run this example:
1
go run bedrock-basic/main.goYou should see the list of supported foundation models.
Note that you can also filter by provider, modality (input/output), and so on by specifying it inListFoundationModelsInput.
Let's start by using Anthropic Claude (v2) model. Here is an example of a simple content generation scenario with the following prompt:
1
2
3
4
5
6
7
<paragraph>
"In 1758, the Swedish botanist and zoologist Carl Linnaeus published in his Systema Naturae, the two-word naming of species (binomial nomenclature). Canis is the Latin word meaning "dog", and under this genus, he listed the domestic dog, the wolf, and the golden jackal."
</paragraph>
Please rewrite the above paragraph to make it understandable to a 5th grader.
Please output your rewrite in <rewrite></rewrite> tags.To run the program:
1
go run claude-content-generation/main.goThe output might differ slightly in your case, but should be somewhat similar to this:
1
2
3
<rewrite>
Carl Linnaeus was a scientist from Sweden who studied plants and animals. In 1758, he published a book called Systema Naturae where he gave all species two word names. For example, he called dogs Canis familiaris. Canis is the Latin word for dog. Under the name Canis, Linnaeus listed the pet dog, the wolf, and the golden jackal. So he used the first word Canis to group together closely related animals like dogs, wolves and jackals. This way of naming species with two words is called binomial nomenclature and is still used by scientists today.
</rewrite>Here is the code snippet (minus error handling etc.).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
//...
brc := bedrockruntime.NewFromConfig(cfg)
payload := {
Prompt: fmt.Sprintf(claudePromptFormat, prompt),
MaxTokensToSample: 2048,
Temperature: 0.5,
TopK: 250,
TopP: 1,
}
payloadBytes, err := json.Marshal(payload)
output, err := brc.InvokeModel(context.Background(), &bedrockruntime.InvokeModelInput{
Body: payloadBytes,
ModelId: aws.String(claudeV2ModelID),
ContentType: aws.String("application/json"),
})
var resp Response
err = json.Unmarshal(output.Body, &resp)
//.....We get the bedrockruntime.Client instance, and create the payload containing the request we need to send Amazon Bedrock (this includes the prompt as well). The payload is
JSON formatted and its details are well documented here - Inference parameters for foundation models.Then we include the payload in the InvokeModel call. Note the
ModelId in the call that you can get from the list of Base model IDs. The JSON response is then converted to a Response struct.Note that this "workflow" (preparing payload with prompt, marshalling payload, model invocation and un-marshalling) will be common across our examples (and most likely in your applications) going forward with slight changes as per the model/use case.
You can also try an information extraction scenario using this prompt:
1
2
3
4
5
6
7
8
9
<directory>
Phone directory:
John Latrabe, 800-232-1995, john909709@geemail.com
Josie Lana, 800-759-2905, josie@josielananier.com
Keven Stevens, 800-980-7000, drkevin22@geemail.com
Phone directory will be kept up to date by the HR manager."
<directory>
Please output the email addresses within the directory, one per line, in the order in which they appear within the text. If there are no email addresses in the text, output "N/A".To run the program:
1
go run claude-information-extraction/main.goWe can't have a GenAI article without a chat application, right? 😉
Continuing with the Claude model, let's look at a coversational example. While you can exchange one-off messages, this example shows how to exchange multiple messages (chat) and also retain the conversation history.
Since it's a simple implementation, the state is maintained in-memory.
To run the application:
1
2
3
4
5
6
go run claude-chat/main.go
If you want to log messages being exchanged with the LLM,
run the program in verbose mode
go run claude-chat/main.go --verboseHere is an output of a conversation I had. Notice how the last response is generated based on previous responses, thanks to the chat history retention:
Image not found
In the previous chat example, you would have waited for a few seconds to get the entire output. This is because the process is completely synchronous - invoke the model and wait for the complete response.
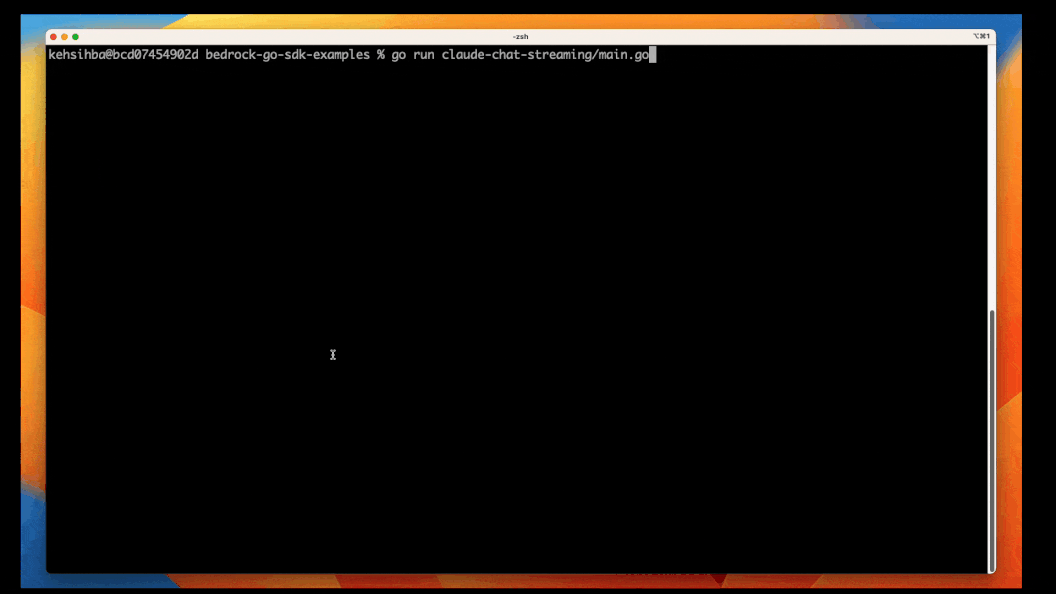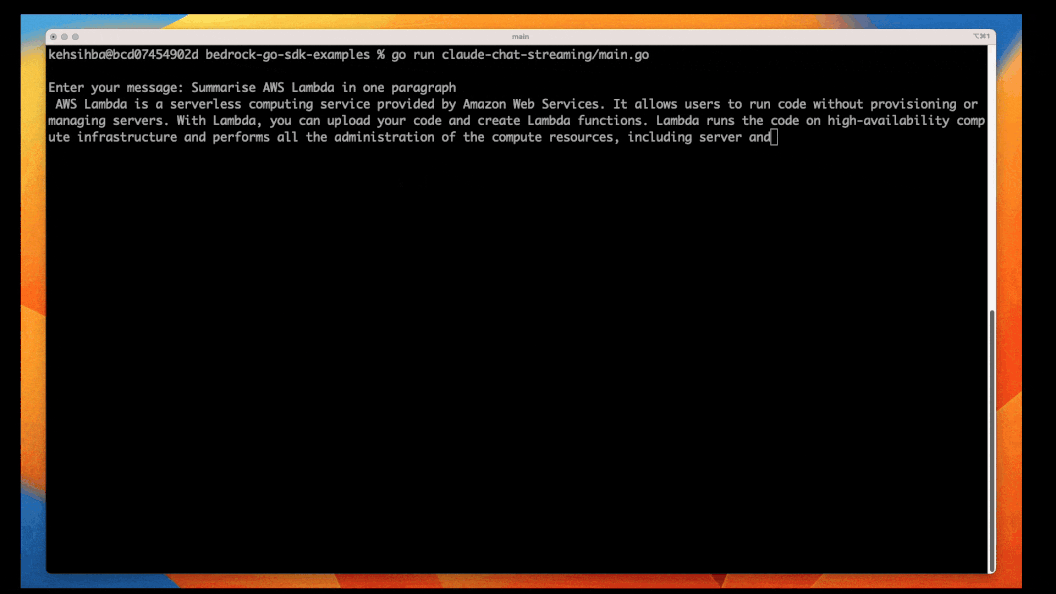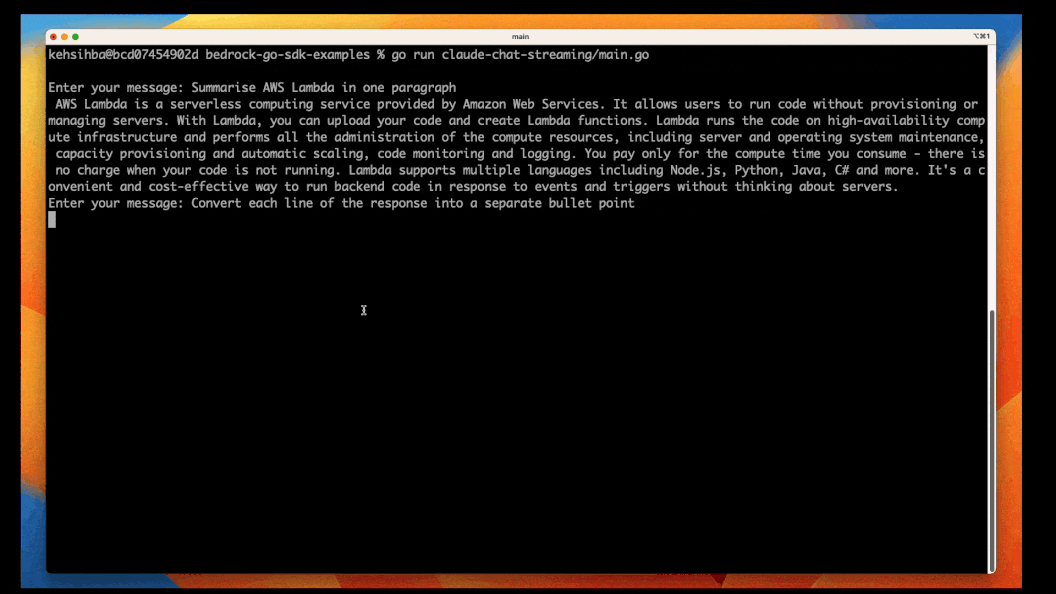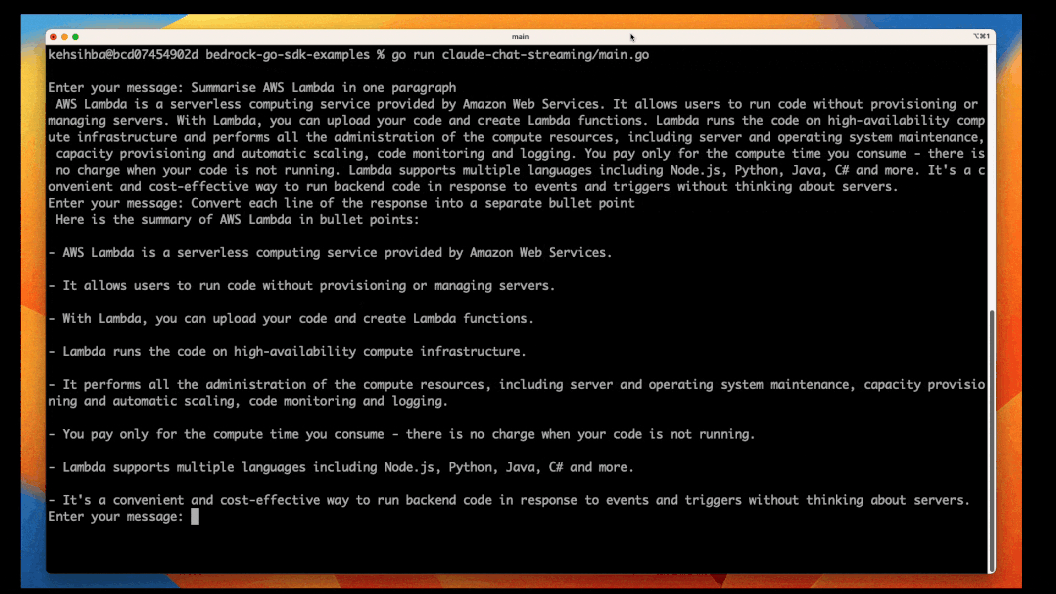
InvokeModelWithResponseStream API allows us to adopt an asynchronous approach - also referred to as Streaming. This is useful if you want to display the response to the user or process the response as it's being generated; this provides a "responsive" experience to the application.
To try it out, we use the same prompt as in the content generation example, since it generates a response long enough for us to see streaming in action.
1
2
3
<rewrite>
Carl Linnaeus was a scientist from Sweden who studied plants and animals. In 1758, he published a book called Systema Naturae where he gave all species two word names. For example, he called dogs Canis familiaris. Canis is the Latin word for dog. Under the name Canis, Linnaeus listed the pet dog, the wolf, and the golden jackal. So he used the first word Canis to group together closely related animals like dogs, wolves and jackals. This way of naming species with two words is called binomial nomenclature and is still used by scientists today.
</rewrite>Run the application:
1
go run streaming-claude-basic/main.goYou should see the output being written to the console as the parts are being generated by Amazon Bedrock.
Let's take a look at the code.
Here is the first part: business as usual. We create a payload with the prompt (and parameters) and call the
InvokeModelWithResponseStream API, which returns a bedrockruntime.InvokeModelWithResponseStreamOutput instance.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
//...
brc := bedrockruntime.NewFromConfig(cfg)
payload := Request{
Prompt: fmt.Sprintf(claudePromptFormat, prompt),
MaxTokensToSample: 2048,
Temperature: 0.5,
TopK: 250,
TopP: 1,
}
payloadBytes, err := json.Marshal(payload)
output, err := brc.InvokeModelWithResponseStream(context.Background(), &bedrockruntime.InvokeModelWithResponseStreamInput{
Body: payloadBytes,
ModelId: aws.String(claudeV2ModelID),
ContentType: aws.String("application/json"),
})
//....The next part is different compared to the synchronous approach with
InvokeModel API. Since the InvokeModelWithResponseStreamOutput instance does not have the complete response (yet), we cannot (or should not) simply return it to the caller. Instead, we opt to process this output bit by bit with the processStreamingOutput function.The function passed into it is of the type
type StreamingOutputHandler func(ctx context.Context, part []byte) error which is a custom type I defined to provide a way for the calling application to specify how to handle the output chunks - in this case, we simply print to the console (standard out).1
2
3
4
5
6
//...
_, err = processStreamingOutput(output, func(ctx context.Context, part []byte) error {
fmt.Print(string(part))
return nil
})
//...Take a look at what the
processStreamingOutput function does (some parts of the code omitted for brevity). InvokeModelWithResponseStreamOutput provides us access to a channel of events (of type types.ResponseStream) which contains the event payload. This is nothing but a JSON formatted string with the partially generated response by the LLM; we convert it into a Response struct.We invoke the
handler function (it prints the partial response to the console) and make sure we keep building the complete response as well by adding the partial bits. The complete response is finally returned from the function.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
func processStreamingOutput(output *bedrockruntime.InvokeModelWithResponseStreamOutput, handler StreamingOutputHandler) (Response, error) {
var combinedResult string
resp := Response{}
for event := range output.GetStream().Events() {
switch v := event.(type) {
case *types.ResponseStreamMemberChunk:
var resp Response
err := json.NewDecoder(bytes.NewReader(v.Value.Bytes)).Decode(&resp)
if err != nil {
return resp, err
}
handler(context.Background(), []byte(resp.Completion))
combinedResult += resp.Completion
//....
}
resp.Completion = combinedResult
return resp, nil
}Now that you have understood the how and why of handling streaming responses, our simple chat app is the perfect candidate for using this!
I will not walk through the code again. I've updated the chat application to use the
InvokeModelWithResponseStream API and handle the responses as per previous example.To run the new version of the app:
1
go run claude-chat-streaming/main.goImage not found
So far we used the Anthropic Claude v2 model. You can also try the Cohere model example for text generation. To run:go run cohere-text-generation/main.go
Image generation is another bread and butter use case of Generative AI! This example uses the Stable Diffusion XL model in Amazon Bedrock to generate an image given a prompt and other parameters.
To try it out:
1
2
3
4
5
6
go run stablediffusion-image-gen/main.go "<your prompt>"
for e.g.
go run stablediffusion-image-gen/main.go "Sri lanka tea plantation"
go run stablediffusion-image-gen/main.go "rocket ship launching from forest with flower garden under a blue sky, masterful, ghibli"You should see an output JPG file generated.
Here is a quick walkthrough of the code (minus error handling, etc.).
The output payload from the
InvokeModel call result is converted to a Response struct which is further deconstructed to extract the base64 image (encoded as []byte) and decoded using encoding/base64 and write the final []byte into an output file (format output-<timestamp>.jpg).1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
//...
brc := bedrockruntime.NewFromConfig(cfg)
prompt := os.Args[1]
payload := Request{
TextPrompts: []TextPrompt{{Text: prompt}},
CfgScale: 10,
Seed: 0,
Steps: 50,
}
payloadBytes, err := json.Marshal(payload)
output, err := brc.InvokeModel(context.Background(), &bedrockruntime.InvokeModelInput{
Body: payloadBytes,
ModelId: aws.String(stableDiffusionXLModelID),
ContentType: aws.String("application/json"),
})
var resp Response
err = json.Unmarshal(output.Body, &resp)
decoded, err := resp.Artifacts[0].DecodeImage()
outputFile := fmt.Sprintf("output-%d.jpg", time.Now().Unix())
err = os.WriteFile(outputFile, decoded, 0644)
//...Notice the model parameters (
CfgScale, Seed and Steps); their values depend on your use case. For instance, CfgScale determines how much the final image portrays the prompt: use a lower number to increase randomness in the generation. Refer to the Amazon Bedrock Inference Parameters documentation for details.Text embeddings represent meaningful vector representations of unstructured text such as documents, paragraphs, and sentences. Amazon Bedrock currently supports the
Titan Embeddings G1 - Text model for text embeddings. It supports text retrieval, semantic similarity, and clustering. The maximum input text is 8K tokens and the maximum output vector length is 1536.To run the example:
1
2
3
4
5
6
go run titan-text-embedding/main.go "<your input>"
for e.g.
go run titan-text-embedding/main.go "cat"
go run titan-text-embedding/main.go "dog"
go run titan-text-embedding/main.go "trex"This is probably the least exciting output you will see! The truth is, it's hard to figure out anything by looking at a slice of
float64s 🤷🏽.It is more relevant when combined with other components such as a Vector Database (for storing these embeddings) and use cases like semantic search (to make use of these embeddings). These topics will be covered in future blog posts. For now, just bear with the fact that "it works".
I hope this proves useful for Go developers as a starting point on how to use Foundation models on Amazon Bedrock to power GenAI applications.
You can also explore how to fine-tune an Amazon Bedrock model by providing your own labeled training data to improve its accuracy and how to monitor it using Amazon CloudWatch and Amazon EventBridge.
Watch out for more articles covering Generative AI topics for Go developers. Until then, Happy Building!
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.
Comments
Log in to comment