Best Practices When Working With Events, Schema Registry, and Amazon EventBridge
Developers are embracing event-driven architectures to scale their applications. In this post, you will learn about the schema registry, the important role it plays in an event-driven world, and best practices to guide your implementation.
Understand Event Discovery and Design Principles
Develop a Naming Convention for Event Types
Catalog and Document Events for Shared Understanding
Incorporate a Standard Event Metadata for Context Awareness
Implement a Tool for Consistency and Abstraction When Publishing and Consuming Events
Use Code Bindings and Developer Tools for Agility
Implement Validation Across Your Producers and Consumers
Handle Schema Evolution With Versioning and Schema Discovery
Start Small With Sparse Event Payloads
How to Avoid Common Challenges and Pitfalls
Avoid Using Directed Commands as Events
Be Aware of Complexity on Calculating the Current State
Be Aware of Complexity on Inferring State Changes
Be Aware of Complexity on Calculating Relationships and Joins
OrderCreated event may include the status of the order as a string, a list of product-ids as an array.
OrderCreated event can introduce a new field such as the total cost of the order. In a growing business and increasingly complex application, it can be challenging for teams to understand what events are available and what they mean. The schema registry plays an important role in reliability, allowing producers and consumers enforce a contract. And, event discovery, helping teams understand events and the applications they can build on top of them.source and detail-type. This provides important context including where the event came from, and what the event is about. This context will be used by consumers, collaboration across teams, monitoring and observability tools, and tracing across services. As such, developing names that are easy to understand will be beneficial. Names are typically difficult to change, so it’s worthwhile thinking about setting a standard up-front.- Notification and Delta Events: If the event is communicating only the detail relevant to state changes, consider a
<Noun><PastTenseVerb>format. For example,OrderCreated. - Fact Events: If the event is communicating full state changes (also known as event-carried state transfer), consider using an alternative
<Event>Factformat. For example,OrderCreatedFact. - Domain Events: In addition to events used for communicating across services (outside events), there are events that are only used within a service (inside events). Here, consider a namespace prefix. For example,
Order@OrderCreated. Note that events can be produced by different services as the system evolves, and thesourcefield in the event data can be used.
detail, consider augmenting event data with additional metadata to provide additional context for consumers. This is a pattern that is increasingly adopted by the community.1
2
3
4
5
6
7
8
9
10
11
12
13
{
"version": "1.0",
"id": "0d079340-135a-c8c6-95c2-41fb8f496c53",
"detail-type": "OrderCreated",
"source": "com.orders",
"account": "123451235123",
"time": "2023-09-01T18:41:53Z",
"region": "ap-southeast-2",
"detail": {
"metadata": { ... }, /* Metadata for additional context */
"data": { ... } /* Content about the event */
}
}metadata:- event-id: (or
idempotency-key) With a unique identifier (such as a UUID), consumers can identify duplicates. This is important as EventBridge guarantees at-least once delivery and consumers will need to be idempotent. - sequence-id: With a sequence identifier in a new field (or as part of the
event-id), consumers can handle ordering. If an event is out of order, the consumer can make a decision on what to do such as waiting or saving the event for later use. - tenant-id: For a SaaS application, the tenant context will enable consumer services to handle events relevant to the tenant boundary.
- data-classification: For security, a data classification tag can identify whether the event contains sensitive data such as Personally Identifiable Information (PII). This enables security policies to be implemented for certain classifications.
metadata outlined above. To achieve this, develop a custom utility such as PublishEvent() to initialize events. Distribute across teams using a package manager such as AWS CodeArtifact. The utility can additionally provide abstraction for implementation details, enforce security on sensitive data and perform validation. Producers are isolated from details such as the EventBridge PutEvents() API with AWS SDK, and only need to concern themselves with the event they are publishing.1
2
3
4
5
6
7
8
9
10
11
12
13
14
/* Sparse event example */
{
"detail-type": "OrderCreated",
"source": "com.orders",
"detail": {
"metadata": {
"event-id": "1a2b3c4d5e6f7g8h9i",
},
"data": {
"order-id": "123456789",
"fulfillment-type": "fulfilled-by-amazon", /* Data for filtering */
}
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
/* Full state description example */
{
"detail-type": "OrderCreated",
"source": "com.orders",
"detail": {
"metadata": {
"event-id": "1a2b3c4d5e6f7g8h9i",
},
"data": {
"order-id": "123456789",
"fulfillment-type": "fulfilled-by-amazon",
/* Provide data commonly used by consumers */
"total": 100,
"status": "Pending",
"product-ids": ["ABC-123", "DEF-345", "GHI-678"],
}
}
}Send Email may look like an event. However, in an event-driven architecture, it is typically processed by the consumer such as an EmailNotificationService, which subscribes to an observed business domain event such as OrderCreated.To assist, EventBridge provides an archive to replay events. See example Amazon EventBridge implementation.
reason, and even the full before and after states. This can increase the payload size for each event, increasing costs and load on the system, especially for frequent events. In addition, consumers will need to incorporate application logic to infer the state changes. This can be duplicative and add complexity to consumers.Order and Product tables using Change Data Capture (CDC) streams. However, consumers such as EmailNotificationService may require details about both events: the order and relevant products ordered. Unfortunately, unlike a relational database, consumers may not be optimised for relational data and complex joins. Performing these calculations can introduce performance bottlenecks and increase costs.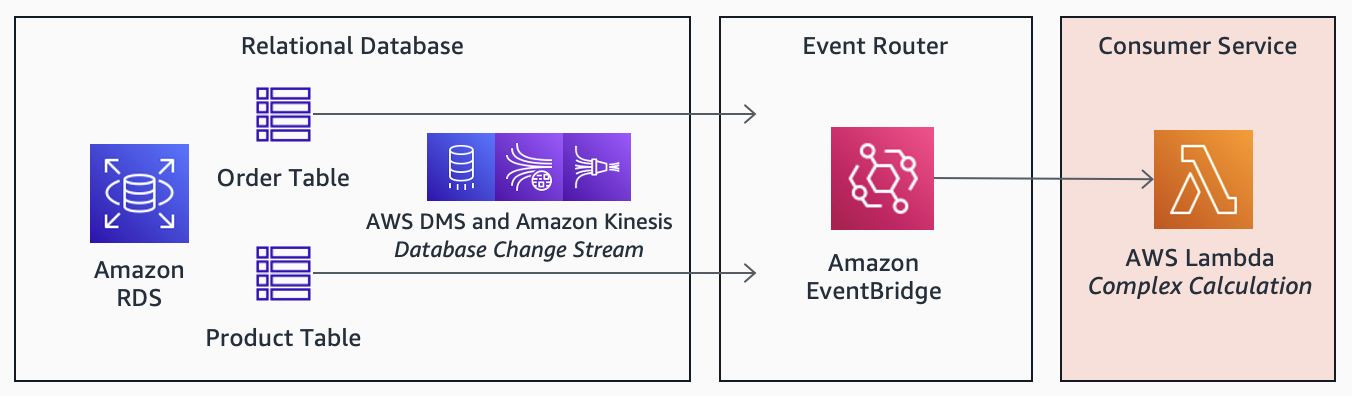
Order and Product tables) and the consumer’s state (as facilitated by the outbox table) are consistent. To avoid performance bottlenecks, avoid data that is too large or frequently updated, and only include data that is commonly used by consumers.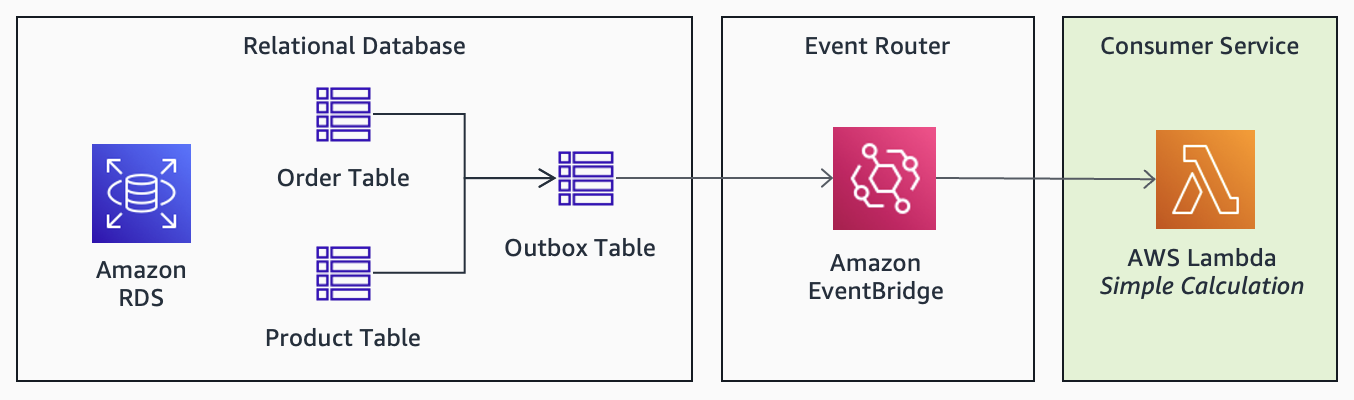
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.