Instrumenting Java Applications with OpenTelemetry
Hands-on tutorial showing how to implement OpenTelemetry in a Java application.
Published Oct 24, 2022
Last Modified Mar 19, 2024
In this tutorial, you will learn how to instrument an existing microservice written in Java and SpringBoot to produce telemetry data using OpenTelemetry. You will learn the differences between instrumenting the microservice using an automatic approach, where everything is automatically discovered for you, and the manual approach, where you make the code observable with instrumentation that you provide using the OpenTelemetry SDK. You will also learn how to send this telemetry data to a compatible backend using the OpenTelemetry collector, and eventually switch to another compatible backend without any modifications in the microservice code. In this tutorial, you will learn:
- How to use the OpenTelemetry Java agent with a microservice
- How to configure and implement the OpenTelemetry collector
- Differences between black-box and white-box instrumentation
- How to write your own telemetry data with the OpenTelemetry SDK
- How to send generated traces to Grafana Tempo and AWS X-Ray
- How to send generated metrics to Prometheus and Amazon CloudWatch
- How to switch between observability backends without code changes
| About | |
|---|---|
| ✅ AWS experience | 200 - Intermediate |
| ⏱ Time to complete | 45 minutes |
| 💰 Cost to complete | Free tier eligible |
| 🧩 Prerequisites | - Docker 4.11+ (Required) - Java 17+ (Required) - Maven 3.8.6+ (Required) - AWS Account (Optional) |
| 🧑🏻💻 Code | Code used in this tutorial |
OpenTelemetry is one of those technologies that you know you must learn and start using as soon as possible, but every time you get to work with it, you find it more complicated than it should be. If this is you, don't worry. You're not alone. Many other people also complain about OpenTelemetry being complicated. However, it is important for you to understand that some of this complexity is incidental because OpenTelemetry is not a ready-to-use library. It is a framework.
If you've implemented observability before, you probably did so by leveraging technologies like agents and libraries that did the job of offloading from your hands much of the work related to collect, process, and transmit telemetry data to observability backends. But this simplicity had a price: you end up locked to that observability backend. OpenTelemetry was created with the main purpose of providing a neutral and extensible way for developers to instrument their applications so telemetry data could be collected, processed, and transmitted to compatible observability backends. With OpenTelemetry, you trade the benefit of vendor portability for a little less encapsulation in how observability must be implemented. Therefore, you are exposed to the moving parts that comprise the implementation.
The good news is that once you understand these moving parts, OpenTelemetry becomes less complicated. It is just a matter of knowing what these moving parts are, how to implement them, and how to integrate them with your observability backend. And you know what? This is exactly what this tutorial is about. I will work with you, step by step, to create an end to end scenario using OpenTelemetry that will even allow for a migration of your observability backend. Let's get to it.
To keep things focused, you are going to implement this observability scenario by using code that contains an existing microservice written in Java and Spring Boot, and a pre-configured observability backend. This observability backend is based on Grafana Tempo for handling tracing data, Prometheus for metrics, and Grafana for visualizing both types of telemetry data. The repository containing this existing code can be found here.
However, instead of using the complete code already implemented, you are going to use a specific branch of this code called
build-on-aws-tutorial that is incomplete. In this tutorial, you will implement the missing part to do things like transmit traces to Grafana Tempo and metrics to Prometheus using OpenTelemetry.- Clone the repository using the tutorial branch:
You can use any tool to work with the files from this repository, including Vim. But I would highly recommend using a full-fledged IDE, such as Visual Studio Code, for this, as you may need to work with different files simultaneously. It will make your life less dreadful.
Now let's make sure everything works as expected. Finishing this section successfully is paramount for you to start and complete the next ones. First, check if the microservice can be compiled, built, and executed. This will require you to have Java and Maven properly installed on your machine. The script
run-microservice.sh builds the code and also executes the microservice at the same time.- Change the directory to the folder containing the code.
- Execute the script
run-microservice.sh.
This is the log output from the microservice:
The microservice exposes a REST API over the port 8888. Next, you'll test if the API is accepting requests.
- Send an HTTP request to the API.
You should receive a reply like this:
Once you are done with the tests, stop
run-microservice.sh to shut down the microservice. You can do this by pressing Ctrl+C. From this point on, every time you need to execute the microservice again with a new version of the code that you changed, just execute the same script.You can now check the observability backend. As mentioned before, this is based on Grafana Tempo, Prometheus, and Grafana. The code contains a
docker-compose.yaml file with the three services pre-configured.- Start the observability backend using:
It may take several minutes until this command completes, as the respective container images need to be downloaded. But once it finishes, you should have Grafana Tempo running on port 3200, Prometheus running on port 9090, and Grafana running on port 3000. Let's check if they are actually running.
- Open a browser and point the location to http://localhost:3200/status.
You should see the following page:
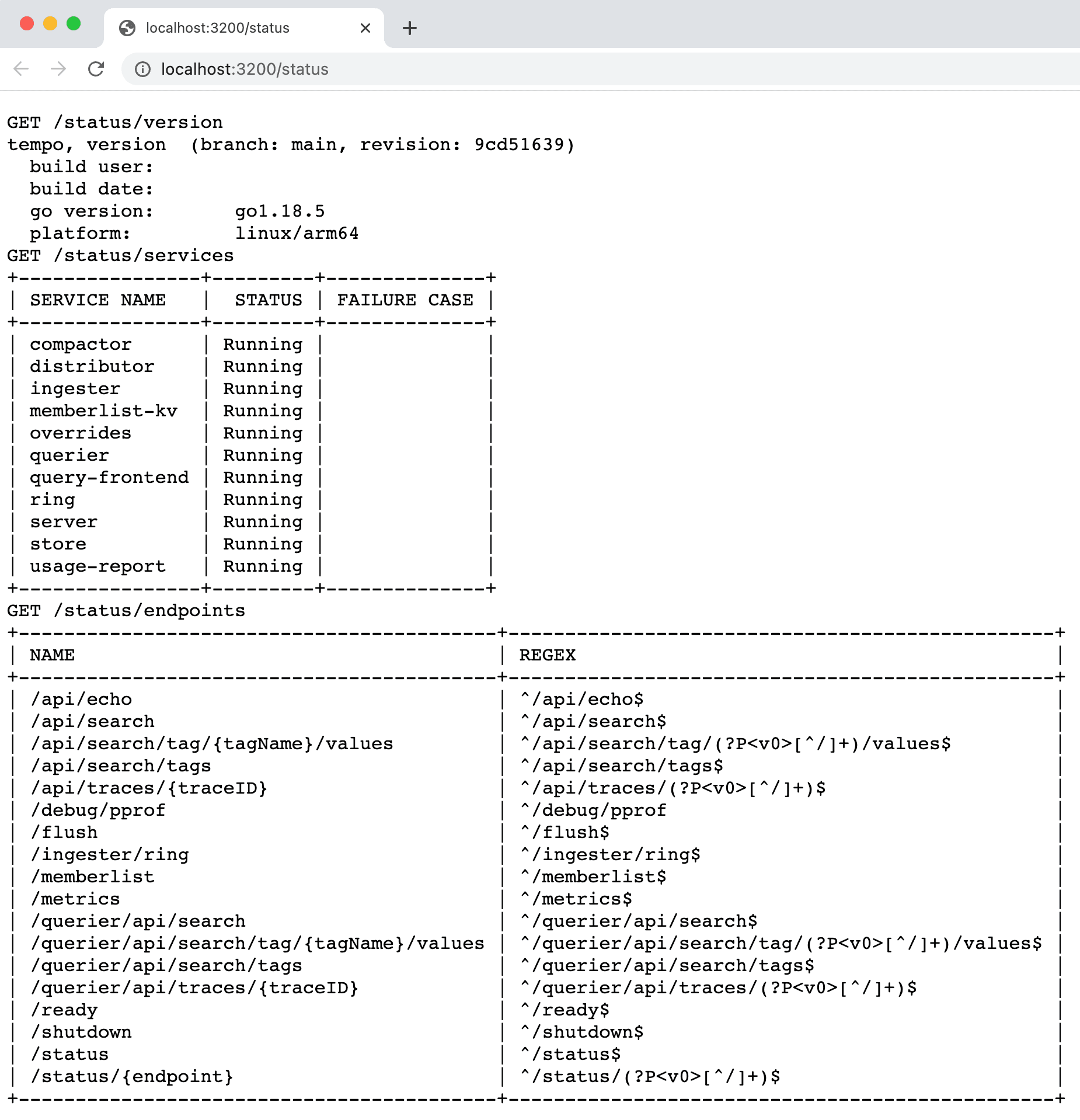
You will learn later in this tutorial that Grafana Tempo is also leveraging the port 4317 to receive spans generated by the microservice. Now let's check Prometheus.
- Point your browser to http://localhost:9090/status.
You should see the following page:
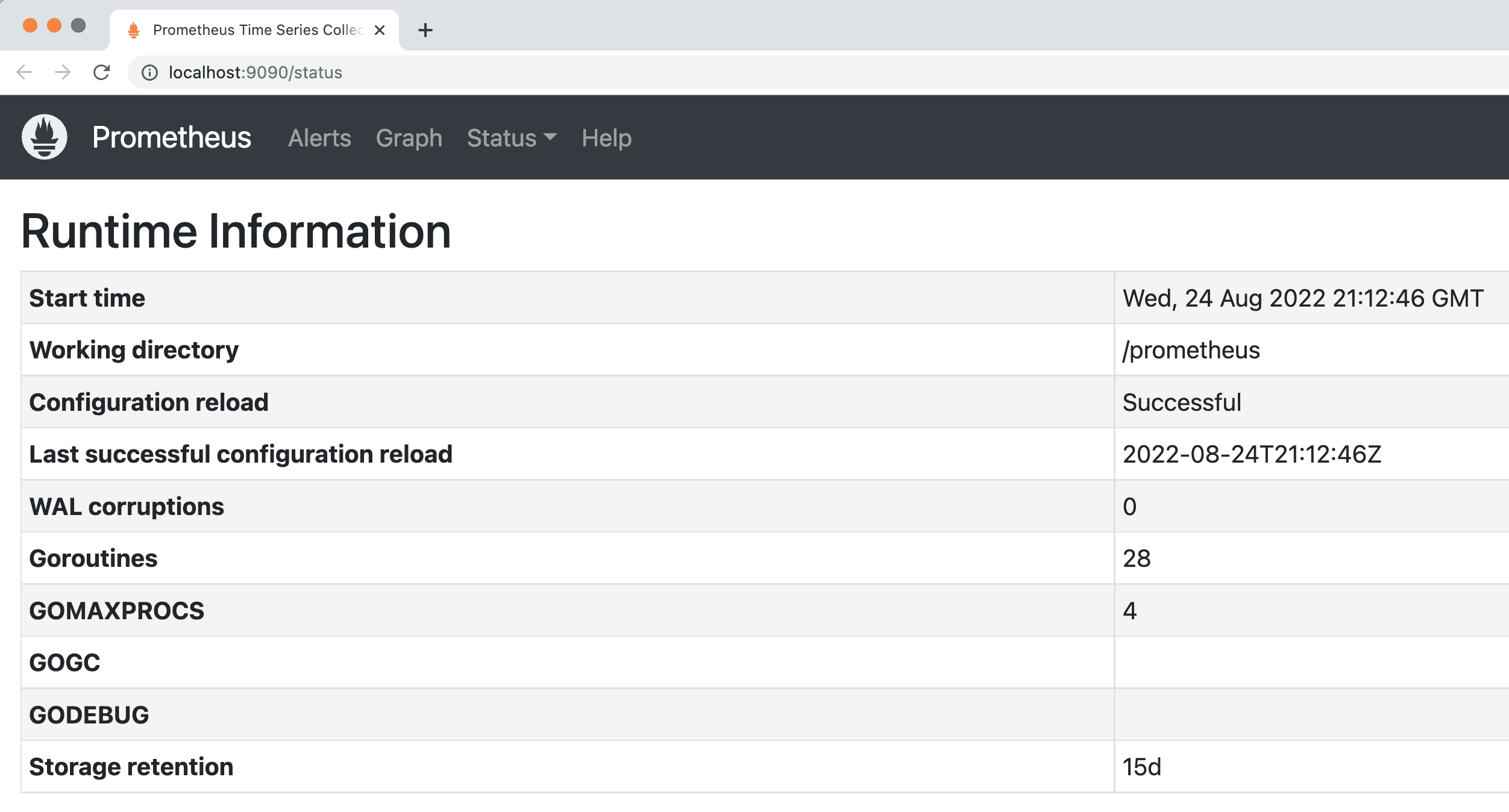
This means it is running OK. Finally, let's check Grafana.
- Point your browser to http://localhost:3000.
You should see the following page:
Just like the others, this means it is running OK. Before we wrap up and get you into the next section, there is one more thing you can check. Click on the option to
Explore on Grafana. Then, a drop-down in the top will list all the datasources configured, one for Prometheus and another for Grafana Tempo.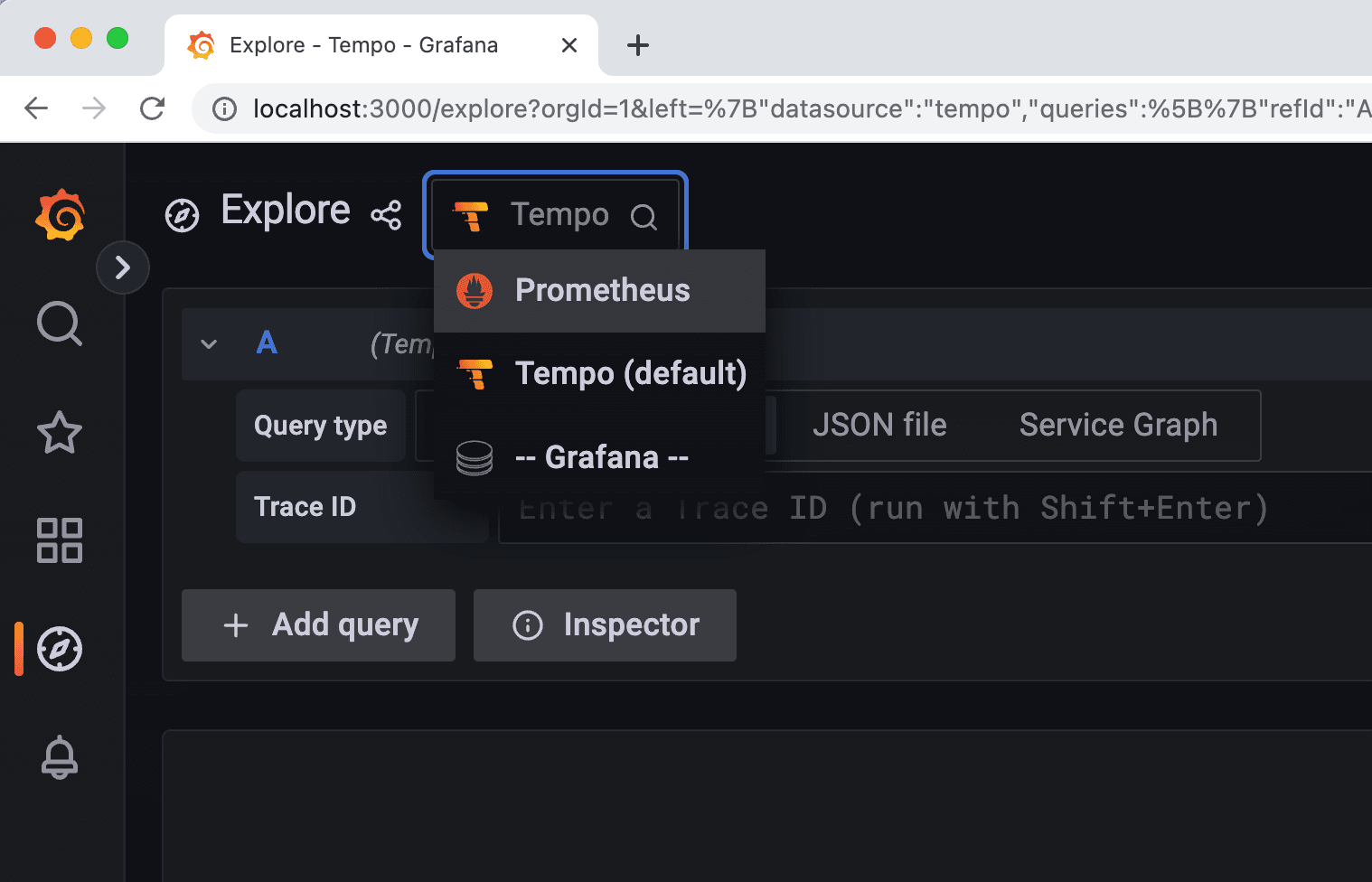
This means once telemetry data for traces and metrics are transmitted to the respective backends — notably Grafana Tempo and Prometheus — you will be able to visualize them here.
- Stop the observability backend using:
🎥 Here is a video containing a hands-on implementation about this section.
You have your microservice ready to go, the observability backend is eager to receive telemetry data, so now it is time for you to start the instrumentation process. This is the process where you teach the code how to emit telemetry data. How intrusive in your code this process is depends on a lot of factors, like which programming language you are using, the level of detail you want to provide for the observability backend, and whether you can effectively change your code for this. These factors often dictate if you are going to use black-box instrumentation or white-box instrumentation.
When you don't want to change nothing in your code and still emit telemetry data, we call this black-box instrumentation. It is known this way because you treat your code as a black-box. While powerful and convenient, black-box instrumentation sometimes is not always a good idea. First, the level of instrumentation is limited, as there is only so much that can be automatically discovered. Second, not all technologies and programming languages have support for it. In most cases, you need to write the instrumentation code yourself. Examples of black-box instrumentation include observability achieved by cluster orchestrators such as Kubernetes, messaging backbones such as service meshes, kernel-level instrumentation with eBPF, and with programming languages that support the concept of agents like Java.
When black-box instrumentation is not available, you can use white-box instrumentation. This is when you open your code for changes, roll up your sleeves, and implement your way out to achieve the observability you need. It is the best way to achieve maximum visibility about what the code is doing, as you can narrate each step of its execution as if you were telling a story. You can implement your own metrics and update them the way you want. But, it is also a lot of work as coding is involved.
For the microservice of this tutorial, we will use both approaches so you can learn the differences. We will start with black-box instrumentation and later on you will practice white-box instrumentation. Since this microservice has been written in Java, we can leverage Java's agent architecture to attach an agent that can automatically add instrumentation code during the JVM bootstrap.
- Edit the file
run-microservice.sh.
You will change the code in
run-microservice.sh to instruct the script to download the agent for OpenTelemetry that will instrument the microservice during bootstrap. If the agent was downloaded before, meaning that its file is available locally, then the script will simply reuse it. Here is how the updated script should look like.- Execute the script
run-microservice.sh.
After the changes, you will notice that nothing much will happen. It will continue to serve HTTP requests sent to the API as it would normally do. However, be sure that traces and metrics are being generated already. They are just not being properly processed. The OpenTelemetry agent is configured by default to export telemetry data to a local OTLP endpoint running on port 4317. This is the reason why you will see messages like this in the logs:
We will fix this later. But for now, you can visualize the traces and metrics created using plain old logging. Yes, the oldest debugging technique is available for the OpenTelemetry agent as well. To enable logging for your telemetry data:
- Edit the file
run-microservice.sh.
Here is how the updated
run-microservice.sh file should look:- Execute the script
run-microservice.sh. - Send an HTTP request to the API.
You will notice that in the logs there will be an entry like this:
This is a root span, a type of trace data, generated automatically by the OpenTelemetry agent. A root span will be created for every single execution of the microservice, meaning that if you send 5 HTTP requests to its API, then 5 root spans will be created. If you keep the microservice running for over one minute, you will also see entries like this in the logs:
These are metrics generated automatically by the OpenTelemetry agent, that are updated every minute. In your case, there will be more metrics than what was shown above for brevity. What matters is the microservice already generating useful telemetry data for traces and metrics without you changing a single line of its code. And it was achieved by one of the moving parts of OpenTelemetry called the agent. An agent, whether one that is pre-packaged like this, or one that you implemented yourself, is the component responsible for collecting the generated telemetry data and sending to a destination.
Now that you know your microservice is properly instrumented, we can work towards sending all this telemetry data to a useful place. We will achieve this by using the OpenTelemetry collector.
🎥 Here is a video containing a hands-on implementation about this section.
Any type of data is not very useful if it cannot be consumed and used to drive insight and support decisions. The same can be said for telemetry data. If you don't export telemetry data to an observability backend that allows you to put it to good use, there is no point in generating it in the first place. OpenTelemetry allows you to collect, process, and transmit the telemetry data to observability backends using a collector.
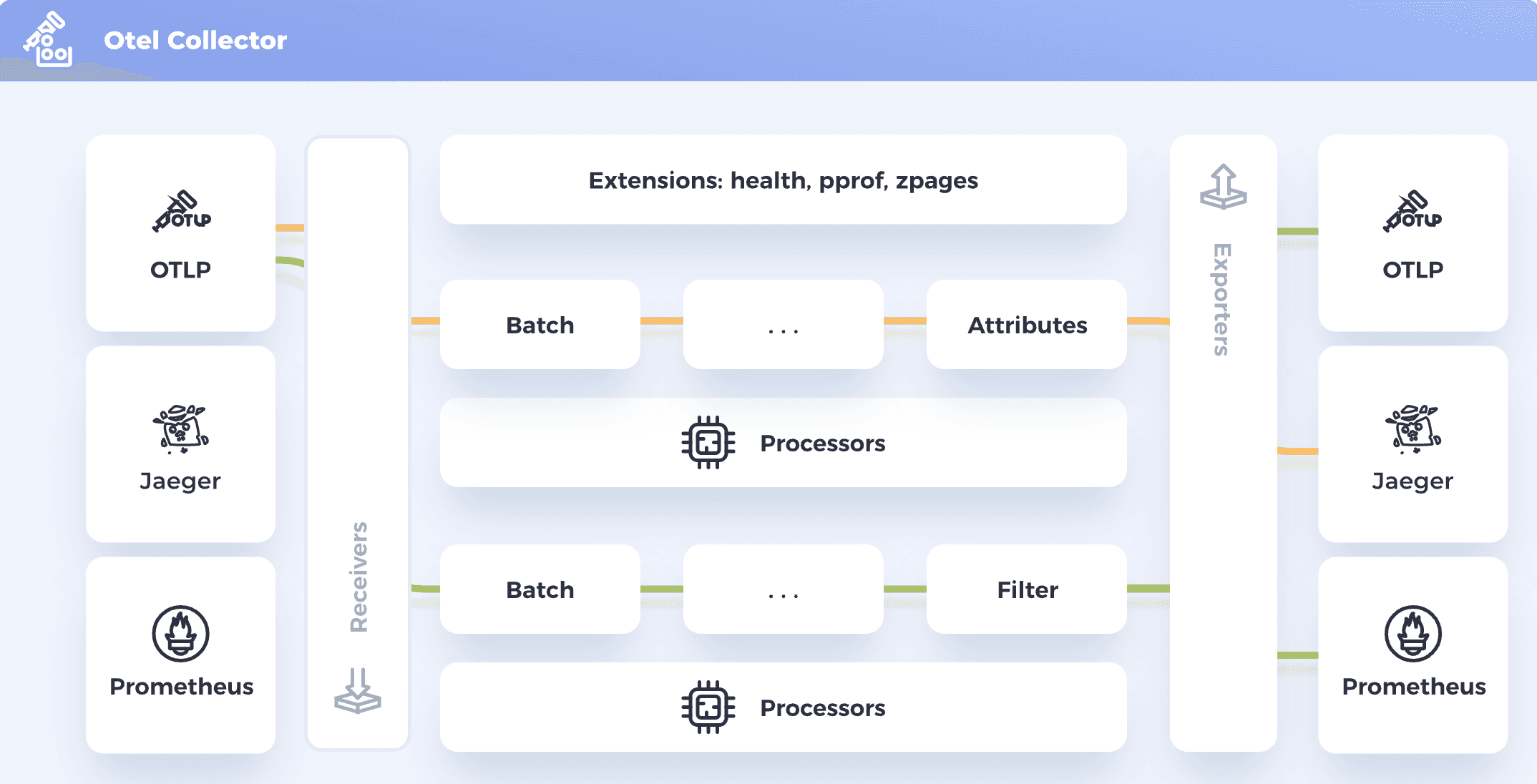
(Image from the OpenTelemetry Documentation, © 2022 The OpenTelemetry Authors, used under CC-BY-4.0 license)
The function of the collector is to work as the glue between your instrumented code that generates telemetry data and the observability backend. Think of it as an integration middleware. It exposes APIs compatible with different protocols so your code can connect to and send the data in, provides mechanisms for you to process the data, and provides connectivity with observability backends also over different protocols.
You may ask: "Why don't we send the telemetry data directly to the observability backend?" Although sometimes you actually can if the observability backend supports the native protocol from OpenTelemetry called OTLP, it is often a best practice to use a collector instead. For example, you can co-locate the collector with your application to minimize the chances of data being lost while transmitted over the network. This is useful for edge-based scenarios such as IoT or if the observability backend sits far away from the application. You can also use the collector to buffer data before sending to the observability backend. If you have a high-volume telemetry data generation, this can protect your observability backend from bursts and being overloaded. You can also use the collector as a gateway for multiple applications to send telemetry data to the same collector, which can process and send the collected data to the observability backend. Finally, the collector acts as a layer of indirection between your application and the observability backend. This is useful to allow you to change, upgrade, and replace the observability backend without downtime to your applications.
Using the collector is straightforward. All you need to do is to create a configuration file that describes how the processing pipeline should work. A processing pipeline comprises three components: one or more receivers, optional processors, and one or more exporters.
- Create a file named
collector-config-local.yamlwith the following content:
In this example, we want the collector to expose an endpoint over the port 5555 that will accept connections over gRPC using the OTLP protocol. Then, we will export any data received to the logging, whether these data are traces or metrics.
- Execute the collector with a container:
You should see the following output:
Leave this collector running for now.
- Edit the file
run-microservice.sh.
Here is how the updated
run-microservice.sh file should look:Save the changes and execute the microservice. Then, send a HTTP request to its API.
- Send an HTTP request to the API.
You will notice that in the logs from the collector, there will be the following output:
This means that the generated root span from the microservice was successfully transmitted to the collector, which then exported the data to the logging. You may notice that it will take a couple seconds for the data to actually be printed into the collector logging. This is because by default the collector tries to buffer data as much as it can and flush periodically to the configured exporters. You can tweak this behavior by adding a batch processor to the processing pipeline that flushes the data every second. Stop both the microservice and the collector.
- Edit the file
collector-config-local.yaml
Here is how the updated
collector-config-local.yaml file should look:As you can see, we have added a processor into the processing pipeline to change the batching behavior, and applied that processor for both the metrics and traces pipelines. This means that if the microservice now sends either traces or metrics to the collector, it will flush whatever has been buffered every second or until the buffer reaches 1K of size. You can check this behavior by executing the collector again, then executing the microservice one more time, and sending another HTTP request to its API. Once you are done with the tests, make sure to stop the collector's execution to free up the port 5555.
Now that the microservice is properly sending telemetry data to the collector, and the collector works as expected, you can start preparing the collector to transmit telemetry data to the observability backend. Therefore, it is a good idea to have the collector being executed along with the observability backend. You can do this by adding a new service in the file
docker-compose.yaml that represents the collector.- Edit the file
docker-compose.yaml
You need to include the following service before Grafana Tempo:
Save the contents of the
docker-compose.yaml file. The code is now in good shape so we can switch our focus to the observability backend, and how to configure the collector to send data to it.🎥 Here is a video containing a hands-on implementation about this section.
So far, you have been using the logging from the console to visualize telemetry data. While logging is great for debugging and troubleshooting purposes, it is not very useful to analyze large amounts of telemetry data. This is particularly true for traces, where you would like to see the complete flow of the code using visualizations such as the timelines or waterfalls.
This is why you are going to configure the collector to send the traces to Grafana Tempo. Grafana Tempo is a tracing backend compatible with OpenTelemetry and other technologies that can process the received spans and make them available for visualization using Grafana. As you may expect, all the changes will occur in the collector configuration file.
- Edit the file
collector-config-local.yaml.
Here is how the updated
collector-config-local.yaml file should look:Before testing this new configuration, let's understand what was done. We have added a new exporter called
otlp that sends telemetry data to the endpoint tempo:4317. The port 4317 is being used by Grafana Tempo to receive any type of telemetry data; and since TLS is disabled in that port, the option insecure was used. Then, we have updated the traces pipeline to include another exporter along with the logging. Think about how powerful this is. Instead of just replacing the existing exporter, we added another one. This is useful for scenarios where you want to broadcast the same telemetry data to multiple observability backends — whether you are executing them side-by-side or you are working on a migration project.- Start the observability backend using:
- Execute the script
run-microservice.sh.
- Send a couple HTTP requests to the microservice API like you did in past steps.
- Open your browser and point to the following location: http://localhost:3000.
- Click on the option to
Exploreon Grafana. - In the drop-down at the top, select the option
Tempo.
You should see the following screen:
- Click on the
Searchtab. - In the
Service Namedrop-down, select the optionhello-app. - In the
Span Namedrop-down, select the option/hello. - Click on the blue button named
Run queryin the upper right corner of the UI.
You should see the following result:
These are the two traces generated when you sent two HTTP requests to the microservice API. To visualize the trace:
- Click on the
Trace IDlink for one of the traces.
You will see that Grafana splits the screen in two, and on the right side of the screen, it will show the details of the selected trace.
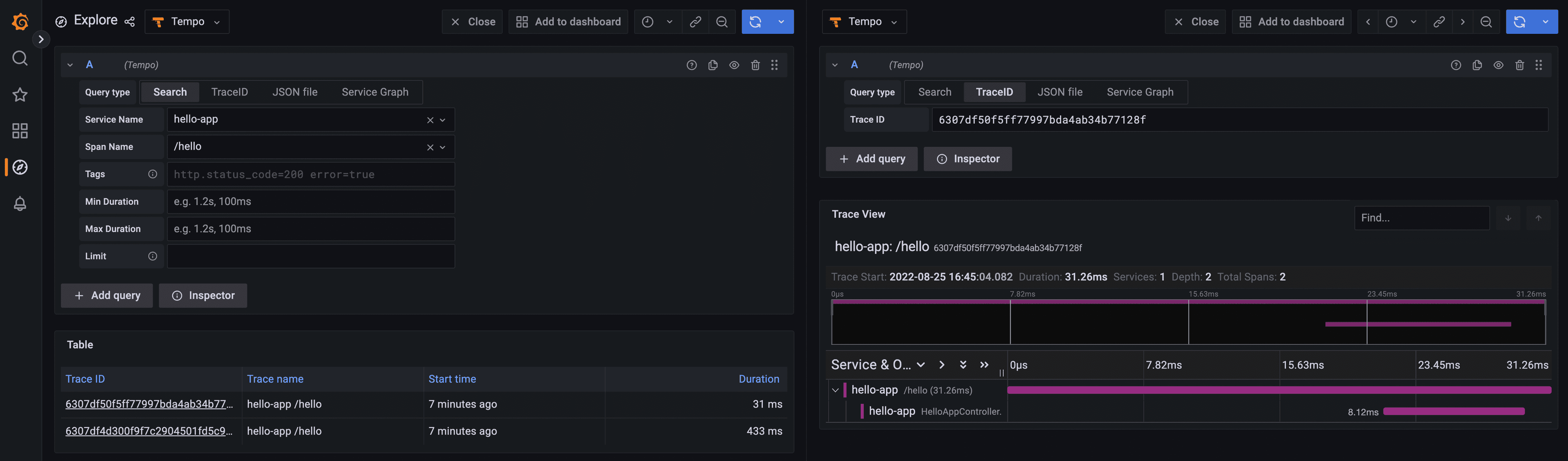
This is a much better way to visualize traces, right? Take a moment to understand the amount of information that Grafana UI is sharing with you. For each trace, it details the relationship between the root span and the child spans created within that execution. It is also telling you how much time each span took to execute, which is valuable information to measure performance. Also, if you click on each span, you will see the inner details of that span.
All this information was generated without you changing a single line of the microservice code. Thanks to the support for black-box instrumentation offered by the OpenTelemetry agent for Java. However, there are situations that even when you have access to black-box instrumentation, you may need to provide additional context to the spans, and sometimes even new spans from scratch. You can achieve this by using the OpenTelemetry SDK for a particular programming language.
🎥 Here is a video containing a hands-on implementation about this section.
In the previous section, you learned how to configure the collector to send traces to Grafana Tempo. You also learned how to visualize those traces using Grafana, where you could see all the details related to how the code was executed. Using tools like this is useful for situations where you need to troubleshoot performance-related problems in applications. Even more so when these applications are distributed, with code executed in different layers, platforms, and machines. But let's dig into what Grafana is showing a bit more.
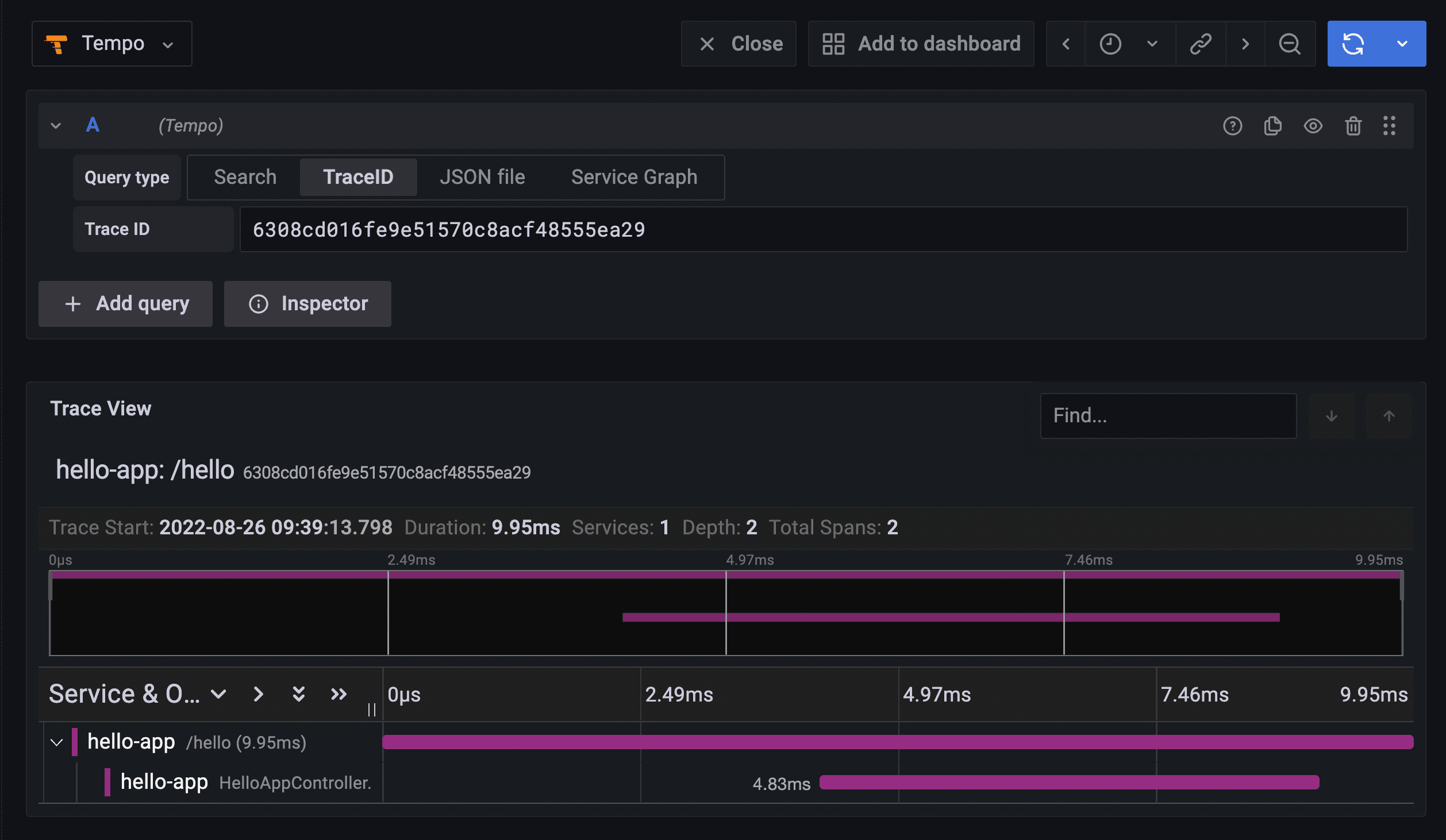
For tools like this to make sense, whoever sees the execution timeline needs to truly believe that what is shown is the actual code execution. In the case above, we are seeing that it took 9.95ms to complete the request sent to the microservice API represented by the
/hello root span. 4.83ms was spent with code for the HelloAppController, executed within the context of the microservice API call. In this example, HelloAppController is a child-span created automatically by the OpenTelemetry agent for Java.Now let's look into the actual microservice code.
- Go to src/main/java folder. You will see the code for the microservice.
- Look into the code of the Java class
HelloAppController.java.
The entry point of the code execution starts at the method
hello() which is mapped to the URI /hello. Anything after this is what actually happens every time you send an HTTP request to the microservice API. Here, you can start having a sense that what Grafana was showing before wasn't complete. For instance, think about where the invocation call to the method buildResponse() is? What if that method alone took a greater part of the code execution? Working only with the visibility you have right now, you wouldn't know for sure where the time was actually spent. In this example, we know just by looking into the code that the method buildResponse() won't take much time to execute. But what if that method was executing code against a remote database that may take a while to reply? You would want people looking at Grafana to see that.This is why I mentioned before that black-box instrumentation sometimes is not a good idea. It can only discover things to a certain level. There is a set of libraries, frameworks, and application servers that are supported by the OpenTelemetry agent for Java, but it is a limited set. Everything else that is not listed there, or what your code does besides using them, won't be captured by the instrumentation.
But you don't have to settle for this. You can use the OpenTelemetry SDK to provide white-box instrumentation to your code to fit your needs. By the way, the OpenTelemetry SDK is another moving part that you have to be aware of. In this section, you are going to change the code of the microservice to highlight other important parts of the code, and make sure that the traces sent to Grafana Tempo are going to show all of that.
- Open the file
pom.xml. - Update the properties section to the following:
These properties will be used throughout many parts of the code.
- Still in the
pom.xmlfile, add the following dependencies:
- Save the changes made in the
pom.xmlfile.
You now have everything you need to write code using the OpenTelemetry SDK for Java. Go back to the Java class
HelloAppControlller.java that contains the code of the microservice.- Change its code to the following version:
Before testing this new version of the code, let's understand what was done. We have added a field-scoped variable called
tracer into the class. This is how we are going to programmatically create custom spans for the parts of the code that we want to highlight. Note that, while creating the tracer, we provided the value of the traces API version that we have set in the pom.xml file. This is useful for debugging purposes, if you feel that certain tracing behaviors are not working as expected, so you can check if that has to do with versioning.Within the
hello() method, we have added a section that creates a span called mySpan, that will represent the portion of the code that verifies if the response is valid. While creating spans, it is important to always call the method end() to share how long that span duration was. Here, you control the time it takes. Also, we have added the annotation @WithSpan to the method buildResponse(). This means that whenever that method is executed, a span will be created for it, including the correct start and end time of its duration.- Save the changes made to the
HelloAppController.javafile.
If the microservice is running, stop it and execute it again so the next test can reflect the changes you made.
- Once the microservice is up and running, send a couple of HTTP request to the microservice API.
- Go to Grafana and search for the newly generated traces.
- Select one of them to visualize its details.
This is how the timeline should look like right now.
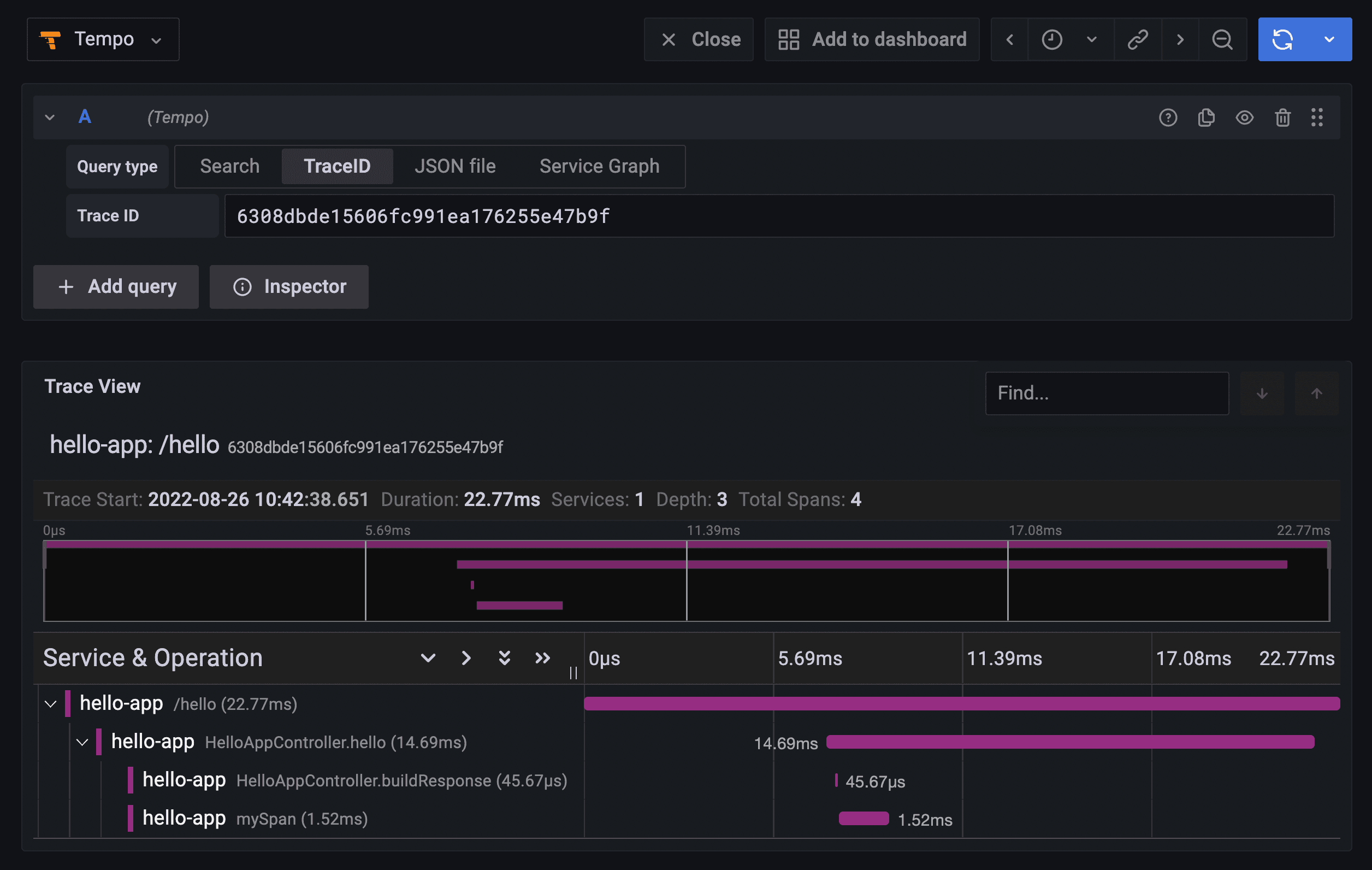
Cool right? You now have a more realistic view of what the code does. You can see that right after the
/hello execution, two child spans were executed. First, the buildResponse() method, which took 45.67μs to execute. Then, the mySpan section of the code, which took 1.52ms to execute. More importantly, in this precise order.If there is such thing of observability well implemented, I would say that it should include practices like this where you take any measures necessary to make your code rightfully observable. And this sometimes means going beyond what black-box instrumentation offers.
🎥 Here is a video containing a hands-on implementation about this section.
Now that you have learned how to use the OpenTelemetry SDK to create custom spans, let's see how to do the same for metrics. The ability to create your own metrics is important because sometimes you need to provide insight about certain aspects of the code that are tricky to monitor. In this section, you will change the code of the microservice to create and update two metrics: one that will count every time the microservice is executed and another one to monitor the amount of memory the JVM is consuming.
- Edit the Java class
HelloAppController.java.
Change its code to the following version:
Let's understand the changes. We have created field-scoped variable called
meter into the class. This is how we are going to programmatically create custom metrics for the parts of the code that we want to highlight. Similarly to what we have done with the tracer, we provided the value of the metrics API version that we have set in the pom.xml file. We created another field-scoped variable called numberOfExecutions. This is going to be a monotonic metric that will count every time the microservice is executed, hence the usage of a counter type.We also added to the class a new method called
createMetrics(). This method does the job of creating the metrics during bootstrap, hence the usage of the @PostContruct annotation. Be mindful though, that we create the metrics using distinct approaches. For the metric that counts the number of executions for the microservice, we used the SDK to build a new metric and then assign this metric to the numberOfExecutions variable. But we create the other metric to monitor the amount of memory the JVM is consuming and don't assign it to any variable. This is because this second metric is an asynchronous metric. We provide a callback method that will be periodically invoked by the OpenTelemetry agent, which will update the value of the metric. This is a non-monotonic metric implemented using a gauge type.The metric assigned to the
numberOfExecutions variable is synchronous. This means that it is up to you to provide the code that will update the metric. It won't happen automatically. Specifically, we have updated the code from the hello() method to include the following line:As you can see, the fundamental difference between synchronous and asynchronous metrics is that for the synchronous ones, you need to control when and where in the code its value will be updated. For the sake of knowing how to look for these metrics in the observability backend, know that we have used specific names for each metric. The metric that counts when the microservice is executed is called
custom.metric.number.of.exec and the metric that monitors the amount of memory consumed by the JVM is called custom.metric.heap.memory.- Save the changes made to the
HelloAppController.javafile.
Now that we have the metrics properly implemented, it is time to configure the collector to send them to Prometheus.
🎥 Here is a video containing a hands-on implementation about this section.
Now that the microservice has been instrumented to produce metrics, we need to configure the collector to send them to Prometheus. Right now, the collector is sending all metrics to logging. To change this, update the processing pipeline from the
collector-config-local.yaml file.- Edit the file
collector-config-local.yaml
Here is how the updated file should look like.
In this new version of the processing pipeline, we have added a new exporter called
prometheus that will be used to send the metrics to Prometheus. We have also updated the metrics pipeline to include this exporter. This new exporter behaves differently though. Instead of pushing the metrics to Prometheus, it will expose all the metrics in an endpoint using the port 6666. This endpoint will be used by Prometheus to pull the metrics. This process in Prometheus is called scrapping. For this reason, you need to update the Prometheus configuration to gather metrics from this endpoint.- Go to the o11y-backend folder.
- Open the file
prometheus.yaml.
Here is how the updated
prometheus.yaml file should look like.After making these changes, you will need to restart the containers for Prometheus and the collector.
- Restart the containers
With all the containers up and running, it is now time to test all of this. If the microservice is running, stop it and execute it again so the next test can reflect the changes you made in the previous section. Once the microservice is up and running:
- Send about a dozen HTTP requests to the microservice API.
- Go to Grafana, click on the
Exploreoption. - Make sure to select
Prometheusin the drop-down box. - Click on the button
Metrics browser.
You should see all metrics collected from the microservice.
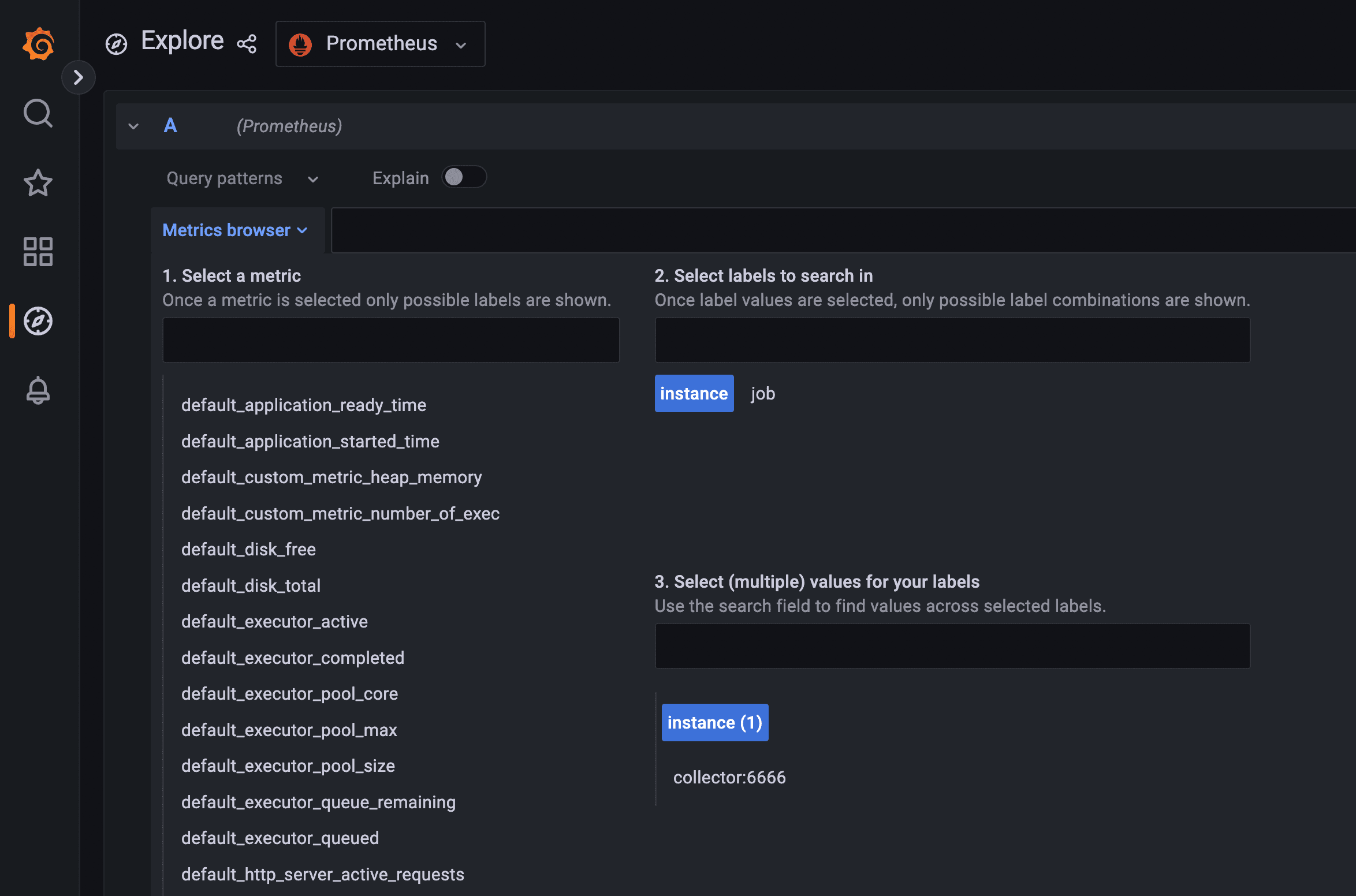
As you can see, all the metrics coming from the microservice are now being stored in Prometheus, with each metric using the prefix
default for the namespace. Along with the metrics created automatically by the OpenTelemetry agent for Java, there is the metrics default_custom_metric_heap_memory and default_custom_metric_number_of_exec, which were created programmatically in the previous section.Let's now visualize the metrics.
- Select the metric
default_custom_metric_number_of_exec. - Click on the
Use querybutton.
You should see the following.
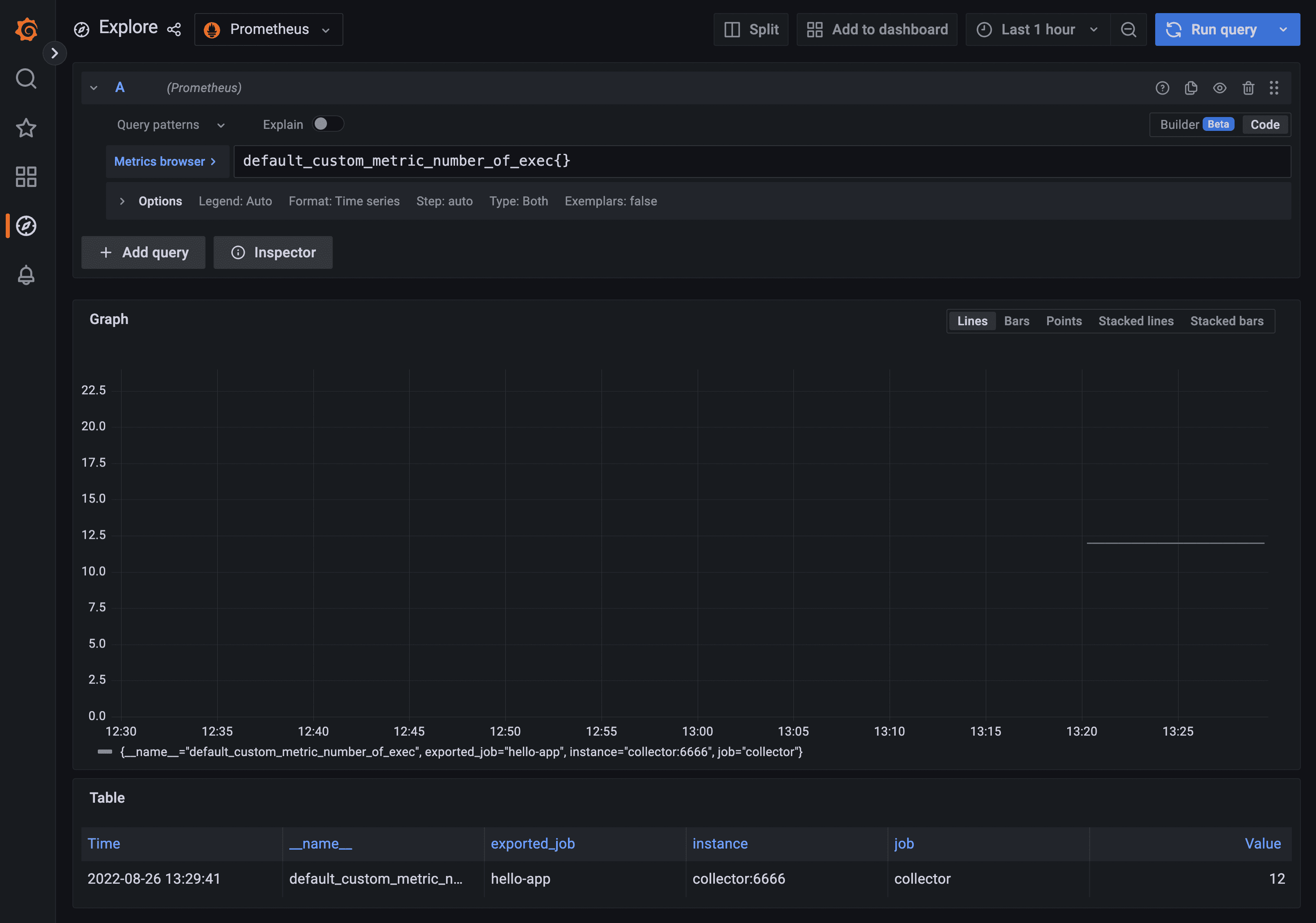
Since this metric is monotonic, the graph itself is not very exciting, given that its value only increments. But the table sitting below the graph is useful for you to check the current value for this metric. It should be the number of HTTP requests you sent to the microservice API.
The metric
default_custom_metric_heap_memory should provide a better visualization.- Repeat steps
8through10but for the metricdefault_custom_metric_heap_memory.
Here is what you should see.
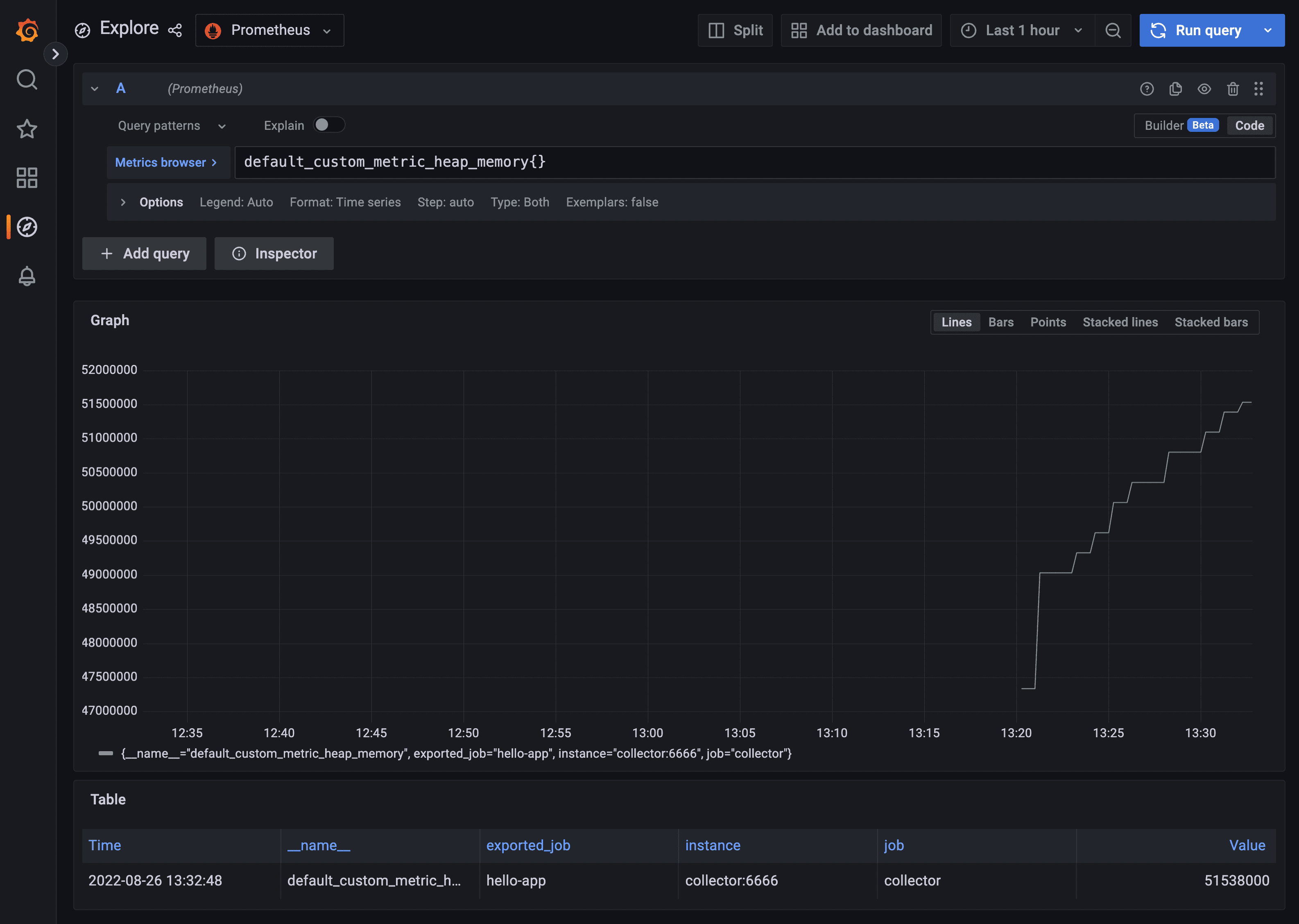
Go ahead and play with the different graph types for this visualization until you find one that looks better. As you can see, creating and maintaining your own traces and metrics using OpenTelemetry is not rocket science. This should be enough for you to leverage this technology for your observability needs. As I mentioned before, OpenTelemetry is not complicated once you understand which moving parts to work with and how to configure them.
🎥 Here is a video containing a hands-on implementation about this section.
At this point, you have now completed all the objectives of this tutorial. You instrumented the microservice code using both the black-box and white-box approaches where you created custom spans and metrics using the OpenTelemetry SDK. You have used a collector to send telemetry data to the observability backend, and you have verified that all the data ended up there using Grafana to visualize them. If you stop this tutorial right now, you would be totally fine.
However, there is one important aspect that you didn't have the chance to test: how much vendor neutral OpenTelemetry really is. This is why we provided you with this bonus section. You will switch the observability backend completely to AWS and everything that you have implemented so far must work. This means that you are going to get rid of Grafana Tempo, Prometheus, and Grafana, and replace them with AWS services that can handle traces and metrics. Specifically, you will send the traces to AWS X-Ray and the metrics to Amazon CloudWatch.
- Stop all the containers.
- If it is currently running, stop the microservice as well.
No changes have to be made in the microservice code. Since the microservice essentially sends all telemetry data to an OTLP endpoint running on port 5555, you are going to create an alternative processing pipeline for the collector.
- Create a file called
collector-config-aws.yaml.
Add the following content:
This processing pipeline is very similar to the one you have used before, except for the exporters section. Here, we have used the
awsemf exporter to send the metrics to CloudWatch, and the awsxray to send the traces to X-Ray.These are exporters that are not available in the default distribution of the OpenTelemetry collector, but it is available in the contributors’ version of the collector, and the distribution AWS OpenDistro for OpenTelemetry. It may be a little confusing using distributions of the collector instead of the official one, but this is a standard practice. As long as the distributions are created from the official code of the collector, you're going to be fine. Many observability vendors use this practice, as they derive from the official code to be inline with the spec and latest developments, but add their specific support to help their community of users.
For this reason, you will use the collector from the AWS OpenDistro for OpenTelemetry in this tutorial. To configure the service for the collector:
- Create a new Docker Compose file called
docker-compose-aws.yaml.
Add the following content:
Here, we are defining a container called
collector that will use the AWS OpenDistro for OpenTelemetry distribution of the collector. We will provide the file collector-config-aws.yaml as parameter to define the processing pipeline for this collector. This container image was created to obtain the AWS credentials in different ways, but in this case, you will provide the credentials via the configured credentials stored in the ˜/.aws/credentials file. Assuming you can have different profiles configured in that file, you are informing which one to use via the environment variable AWS_PROFILE. You can learn different ways to provide the AWS credentials here.This is it. You are ready to send the telemetry data from the microservice to AWS.
- Start the container for this collector:
- Now execute the microservice by running the script
run-microservice.sh.
Then, send a couple of HTTP requests to its API. This should be enough for you to verify if everything is working.
- Open the AWS Management Console.
- Configure the console to point to the region you have implemented in the
collector-config-aws.yamlfile which isus-east-1.
- Go the X-Ray service by clicking here.
You should be able to see the generated traces if you click in the menu option
Traces, right under X-Ray Traces.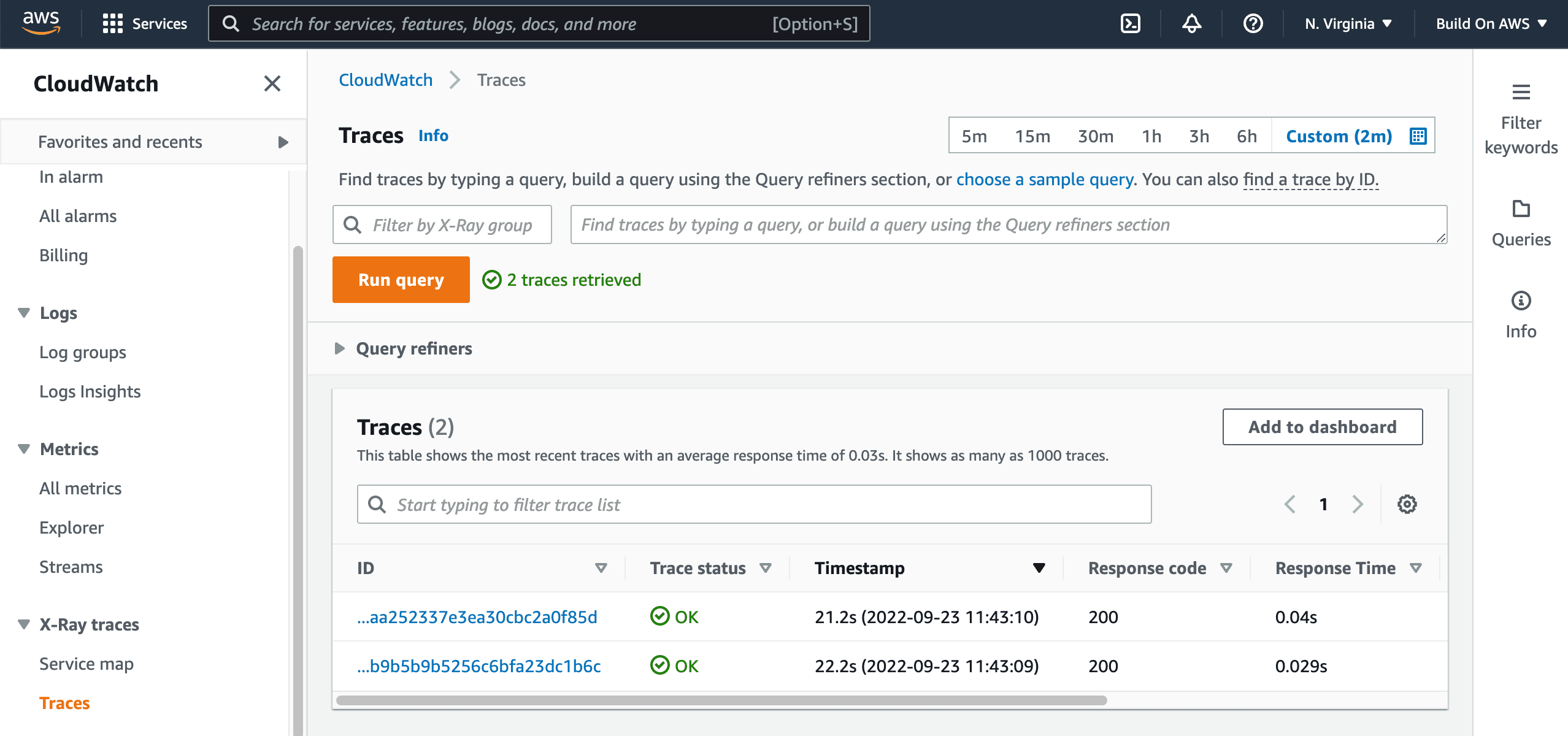
- Click the link in the
IDcolumn to select a specific trace.
This is what you should see:
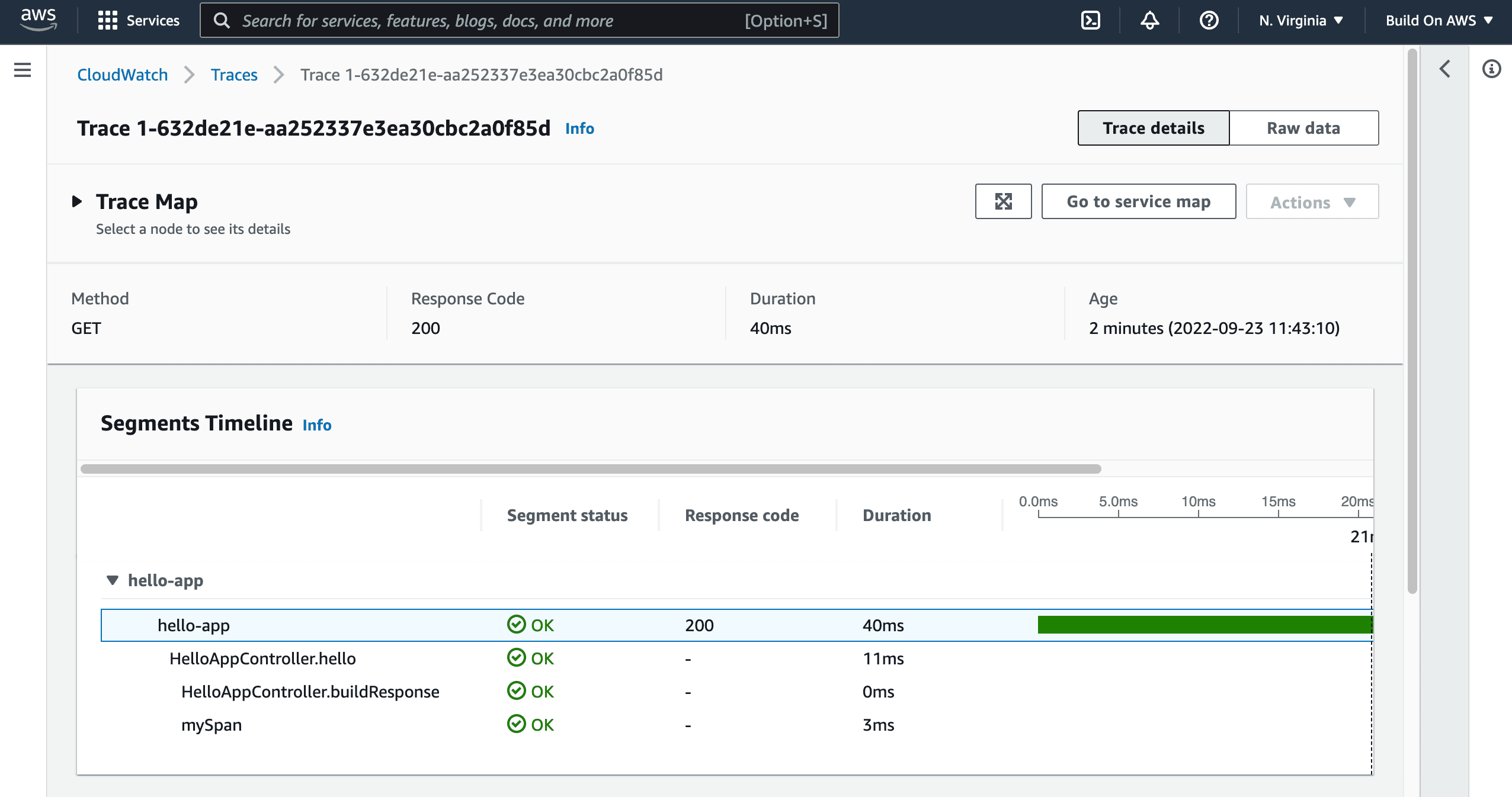
As you can see, everything that you could see with Grafana before it is being shown here. Meaning that you were able to successfully switch the observability backend for traces without changing a single line of code for the microservice.
Let's now verify the metrics.
- Go to the Amazon CloudWatch service by clicking here.
- Then, click on
All metrics.
This is what you should see:
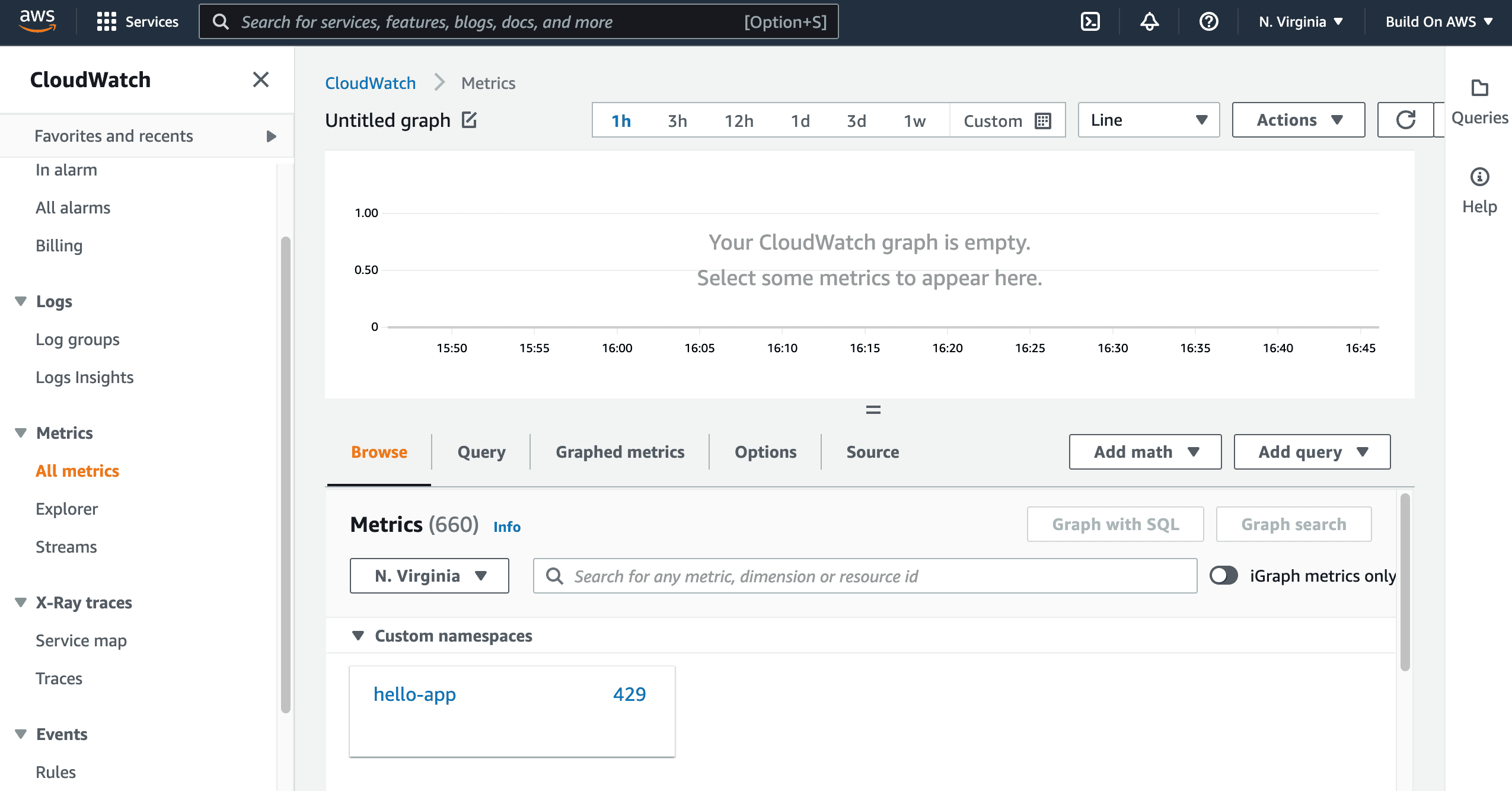
As you can see from the image above, there are
429 metrics collected from your microservice. These are the 427 metrics collected automatically by the OpenTelemetry agent for Java, plus the two custom metrics you implemented.- Look at the metric
custom.metric.number.of.exec.
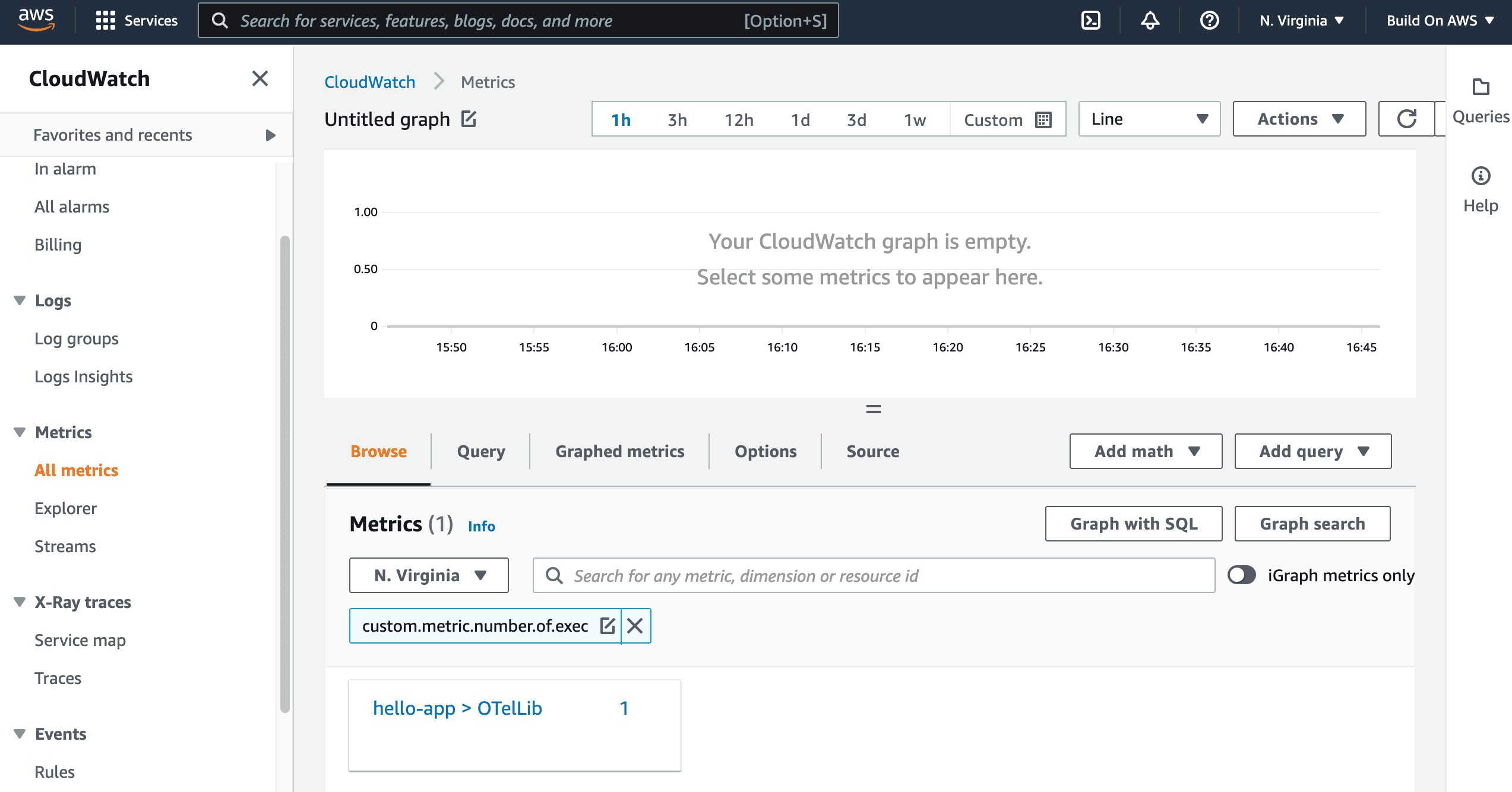
Once you find the metric, you can select it and add to the visualization. To speed things up for you, you can use the source below to implement a gauge that ranges from
0 to 10 that sums the metric for the period of one hour.- Click in the tab named
Sourceand paste the following JSON code.
You should get the following visualization:
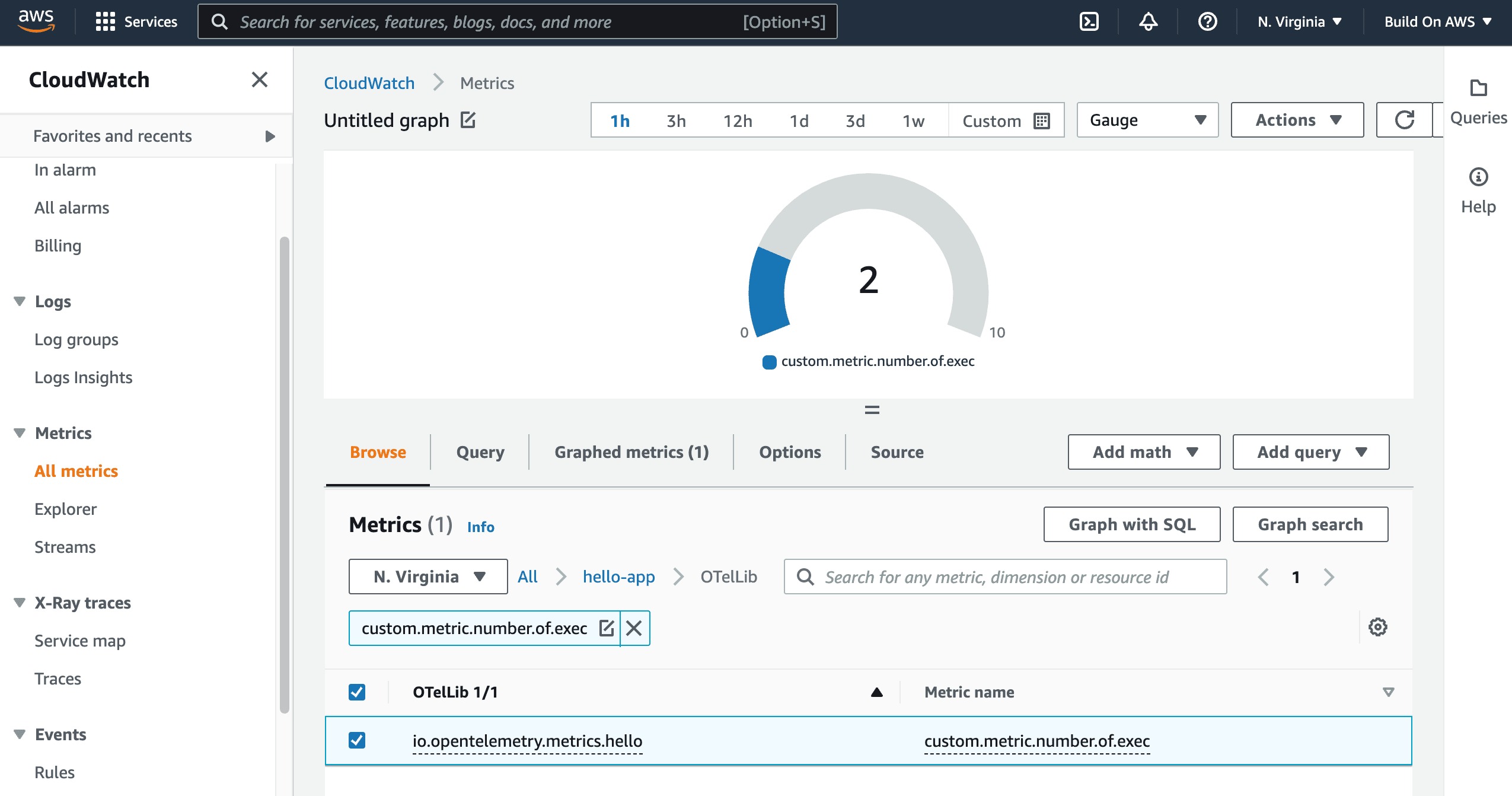
This is the proof that you were able to successfully switch the observability backend for metrics without changing a single line of code for the microservice. Instrument once, reuse everywhere. This is how OpenTelemetry was designed to work.
🎥 Here is a video containing a hands-on implementation about this section.
Congratulations. You have now officially completed all the steps from this tutorial.