#TGIFun🎈 Building GenAI apps with managed AI services
Some random thoughts on managed AI services and their place in the GenAI stack... with examples.
João Galego
Amazon Employee
Published Apr 19, 2024
Last Modified May 22, 2024
In this 2nd episode of #TGIFun🎈, I'd like to share some thoughts on managed AI services and their place in the GenAI application stack.
Now that Foundation Models (FM) can write novels, compose full musical scores, edit movies, generate code and much, much more... is there still a place for traditional AI/ML services? This is one of the most asked questions when I talk with customers and my answer is always an emphatic ✅ 𝒀𝒆𝒔!
I believe there is still a lot of room for AI services like Amazon Polly (text-to-speech, TTS) or Amazon Translate (machine translation) and, yes, even good old Amazon Lex (conversational AI). And just to prove that, I'm going to show you 3 different applications that combine GenAI services like Amazon Bedrock (FMaaS) with traditional AI services from the top of our AI/ML stack.
💡 Did you know? You can try some of these services for *free* on the AWS AI Services Demo website!
The 2022 AWS re:Invent conference in Las Vegas brought us a lot of great things in the ML space, but this one may have flown under your radar. Presented at the AWS Builders' Fair, Describe for Me is an “Image to Speech” app created to help the visually impaired understand images through captions, face recognition, and TTS.
As we can see in the diagram below, it uses an AI service combo that includes Amazon Textract (data extraction), Amazon Rekognition (computer vision) and Amazon SageMaker (E2E ML platform) to do the captioning, while Polly reads the result back to the user in a clear, natural-sounding voice.

The original app is powered by OFA (One For All), a unified seq2seq model available on Hugging Face. We can do one better and replace the whole captioning sequence with a single call to a multimodal model like Claude 3 Sonnet, which is available on Amazon Bedrock, and replicate the whole application in 100 lines of Python code (also available as a gist).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
"""
Describe for Me (Bedrock edition ⛰️)
Image ==> Bedrock -> Translate -> Polly ==> Speech
"""
import argparse
import base64
import json
import boto3
# Parse arguments
parser = argparse.ArgumentParser(
prog='Describe for Me (Bedrock Edition) ⛰️',
description="""
Describe for Me is an 'image-to-speech' app
built on top of AI services that was created
to help the visually impaired understand images
through lively audio captions.
""",
)
parser.add_argument('image')
parser.add_argument('-m', '--model', default="anthropic.claude-3-sonnet-20240229-v1:0")
parser.add_argument('-t', '--translate')
parser.add_argument('-v', '--voice')
args = parser.parse_args()
# Initialize clients
bedrock = boto3.client("bedrock-runtime")
translate = boto3.client("translate")
polly = boto3.client("polly")
# Process image
with open(args.image, "rb") as image_file:
image = base64.b64encode(image_file.read()).decode("utf8")
# Generate a description of the image
response = bedrock.invoke_model(
modelId=args.model,
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1024,
"messages": [{
"role": "user",
"content": [{
"type": "text",
"text": "Describe the image for me.",
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": f"image/{args.image.split('.')[-1]}",
"data": image,
},
}],
}],
}),
)
result = json.loads(response.get("body").read())
description = " ".join([output["text"] for output in result.get("content", [])])
print(f"##### Original #####\n\n{description}\n")
# Translate the description to a target language
if args.translate:
description = translate.translate_text(
Text=description,
SourceLanguageCode='en',
TargetLanguageCode=args.translate
)['TranslatedText']
print(f"##### Translation #####\n\n{description}\n")
# Read the description back to the user
if args.voice:
# Translate -> Polly language map
lang_map = {
'en': 'en-US',
'pt': 'pt-BR'
}
lang_code = lang_map.get(args.translate, args.translate)
# Synthesize audio description
print(f"\nSynthesizing audio description\n> Language: {lang_code}\n> Voice: {args.voice}\n")
audio_data = polly.synthesize_speech(
Engine="neural", # hardcoded, because we want natural-sounding voices only
LanguageCode=lang_code,
OutputFormat="mp3",
Text=description,
TextType='text',
VoiceId=args.voice,
)
# Save audio description
with open(f"{''.join(args.image.split('.')[:-1])}.mp3", 'wb') as audio_file:
audio_file.write(audio_data['AudioStream'].read())
Let's put our script to the test and generate an audio description in European Portuguese (
pt-PT) spoken by Polly's one and only Inês of Seurat's A Sunday Afternoon on the Island of La Grande Jatte:1
python describeforme.py --translate pt-PT --voice Ines seurat.jpeg, A Sunday Afternoon on the Island of La Grande Jatte")
If you're curious, here's the final result:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
##### Original #####
The image depicts a park scene from the late 19th or early 20th century.
It's a lush green landscape with trees and people gathered enjoying the outdoors.
Many are dressed in fashions typical of that era, with men wearing top hats
and women in long dresses with parasols to shade themselves from the sun.
Some people are seated on the grass, while others are strolling along the paths.
There's a body of water in the background, likely a lake or river, with boats
and people gathered near the shoreline.
The style of painting is distinctive, with areas of flat color and simplified forms,
characteristic of the Post-Impressionist or early modern art movements.
The scene captures a leisurely day in an urban park setting, conveying a sense
of relaxation and appreciation for nature amidst the city environment.
##### Translation #####
A imagem retrata uma cena de parque do final do século XIX ou início do século XX.
É uma paisagem verdejante com árvores e pessoas reunidas a desfrutar do ar livre.
Muitos estão vestidos com modas típicas daquela época, com homens a usar chapéus
e mulheres em vestidos longos com guarda-sóis para se proteger do sol.
Algumas pessoas estão sentadas na relva, enquanto outras estão a passear pelos caminhos.
Há um corpo de água ao fundo, provavelmente um lago ou rio, com barcos
e pessoas reunidas perto da costa.
O estilo de pintura é distinto, com áreas de cor plana e formas simplificadas,
características dos movimentos de arte pós-impressionista ou do início da arte moderna.
A cena captura um dia de lazer num cenário de parque urbano, transmitindo uma sensação
de relaxamento e apreciação pela natureza em meio ao ambiente da cidade.
Synthesizing audio description
> Language: pt-PT
> Voice: Ines🎯 Try it out for yourself and share the best descriptions in the comments section below 👇
This one comes from a post published last year in the AWS ML Blog. The solution integrates Amazon Lex (I promised it would make an appearance) with an open-source LLM (FLAN-T5 XL) available through Amazon SageMaker JumpStart.

In a nutshell, Amazon Lex handles the basic stuff, where the user's intent is clear, while the model handles the tough ones, the "don't know" answers, via Lambda functions.
💡 If you want to know more about how Amazon Lex integrates with Lambda functions, read the section on Enabling custom logic with AWS Lambda functions in the Amazon Lex V2 Developer Guide.

All the code and documentation for this solution is available in this GitHub repository, so go check it out.
Finally, let's build an application from scratch. We could aim towards the whimsical goal of using as many AI services as possible, but let's leave that for another post.
For now, I will settle for a simple conversational app powered by LangChain and Streamlit. This kind of application is so mundane nowadays that I gave it an interjection instead of a name (MEH!) then asked Claude to make it an acronym for something (talk about lazy). Oh well...
Fun fact: An earlier version was known as YEAH! (Your Excellent Artificial Helper) but it wasn't so well received during private showings.
So here's what the app is supposed to do:
- Takes in a user prompt
- Translates it to a target language using Amazon Translate
- Sends it to Anthropic's Claude on Amazon Bedrock
- Translates the response back to the source language
- Turns the response into speech via Amazon Polly
If this is not enough, here's a sequence diagram telling you the exact same thing:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
%% Use the mermaid-cli
%% > mmdc -i meh.mmd -o meh.png -t forest -b transparent
%% or the online version
%% https://mermaid.live
%% to create the diagram
sequenceDiagram
You 😒 ->> +MEH! 🐑 : Prompt ✍️
MEH! 🐑 ->> +Amazon Translate : translate_text 🌐
Amazon Translate ->> MEH! 🐑 :
MEH! 🐑 ->> You 😒 : Translated Prompt
MEH! 🐑 ->> Amazon Bedrock: invoke_model 🧠
Amazon Bedrock ->> MEH! 🐑 :
MEH! 🐑 ->> You 😒 : Response
MEH! 🐑 ->> +Amazon Translate : translate_text 🌐
Amazon Translate ->> MEH! 🐑 :
MEH! 🐑 ->> You 😒 : Translated Response
MEH! 🐑 ->> Amazon Polly : synthesize_speech 🦜
Amazon Polly ->> MEH! 🐑 :
MEH! 🐑 ->> You 😒 : Play 🔊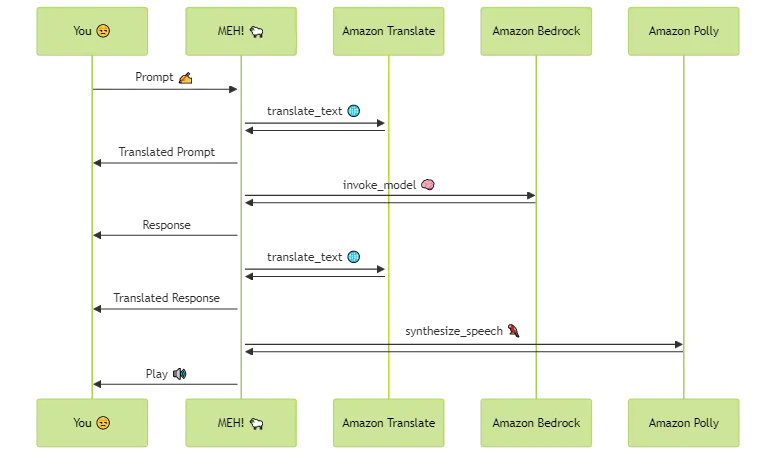
The full code is available in GitHub, so feel free to play around.
💡 This app uses Boto3, the AWS SDK for Python, to call AWS services. You must configure both AWS credentials and an AWS Region in order to make requests. For information on how to do this, see AWS Boto3 documentation (Developer Guide > Credentials).
You can start it directly with Streamlit
1
streamlit run meh.pyor make a container out of it
1
docker build --rm -t meh .and then run it
Linux
1
docker run --rm --device /dev/snd -p 8501:8501 mehWindows (WSL2)
1
wsl docker run --rm -e PULSE_SERVER=/mnt/wslg/PulseServer -v /mnt/wslg/:/mnt/wslg/ -p 8501:8501 meh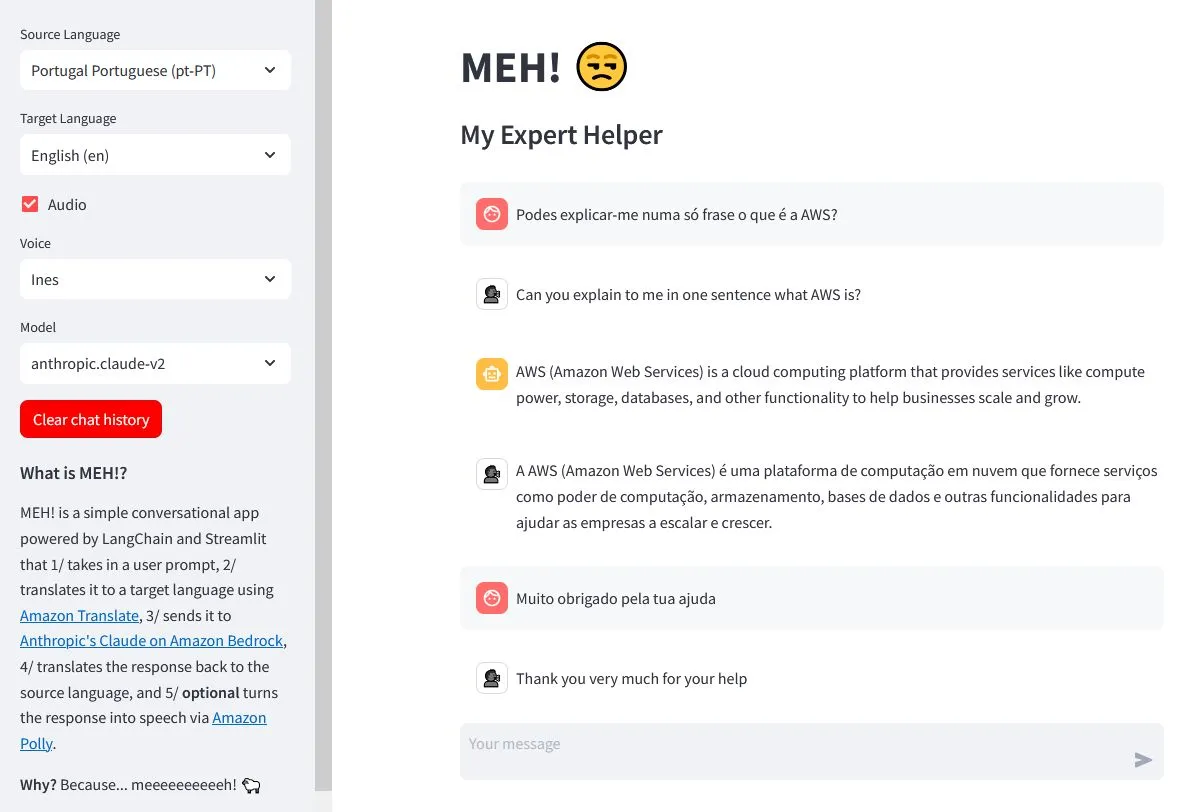
Thank you so much for reading this far and have a nice weekend! 👋
This is the second article in the #TGIFun🎈 series, a personal space where I'll be sharing some small, hobby-oriented projects with a wide variety of applications. As the name suggests, new articles come out on Friday. // PS: If you like this format, don't forget to give it a thumbs up 👍 As always: work hard, have fun, make history!
- JGalego/MEH: A simple conversational app powered by LangChain and Streamlit, feat. Amazon Translate, Amazon Bedrock and Amazon Polly
- aws-samples/conversational-ai-llms-with-amazon-lex-and-sagemaker: Getting Started on Generative AI with Conversational AI and Large Language Models
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.
Comments
Log in to comment