GenAI under the hood [Part 3] - The quest for infinite context in LLMs
What does infinite context length mean? How is this related to attention?
Shreyas Subramanian
Amazon Employee
Published Apr 15, 2024
Powerful LLMs have demonstrated what seem like extraordinary capabilities, enabling applications ranging from text generation and question answering to complex problem-solving and conversational AI. However, a fundamental limitation has persisted – the fixed context window during training and inference, restricting LLMs from effectively processing longer documents, books, or multi-turn conversations in a unified manner. Longer context length models are becoming more popular, not just for the practioners that are lazy-to-chunk, but also for the performance hungry.
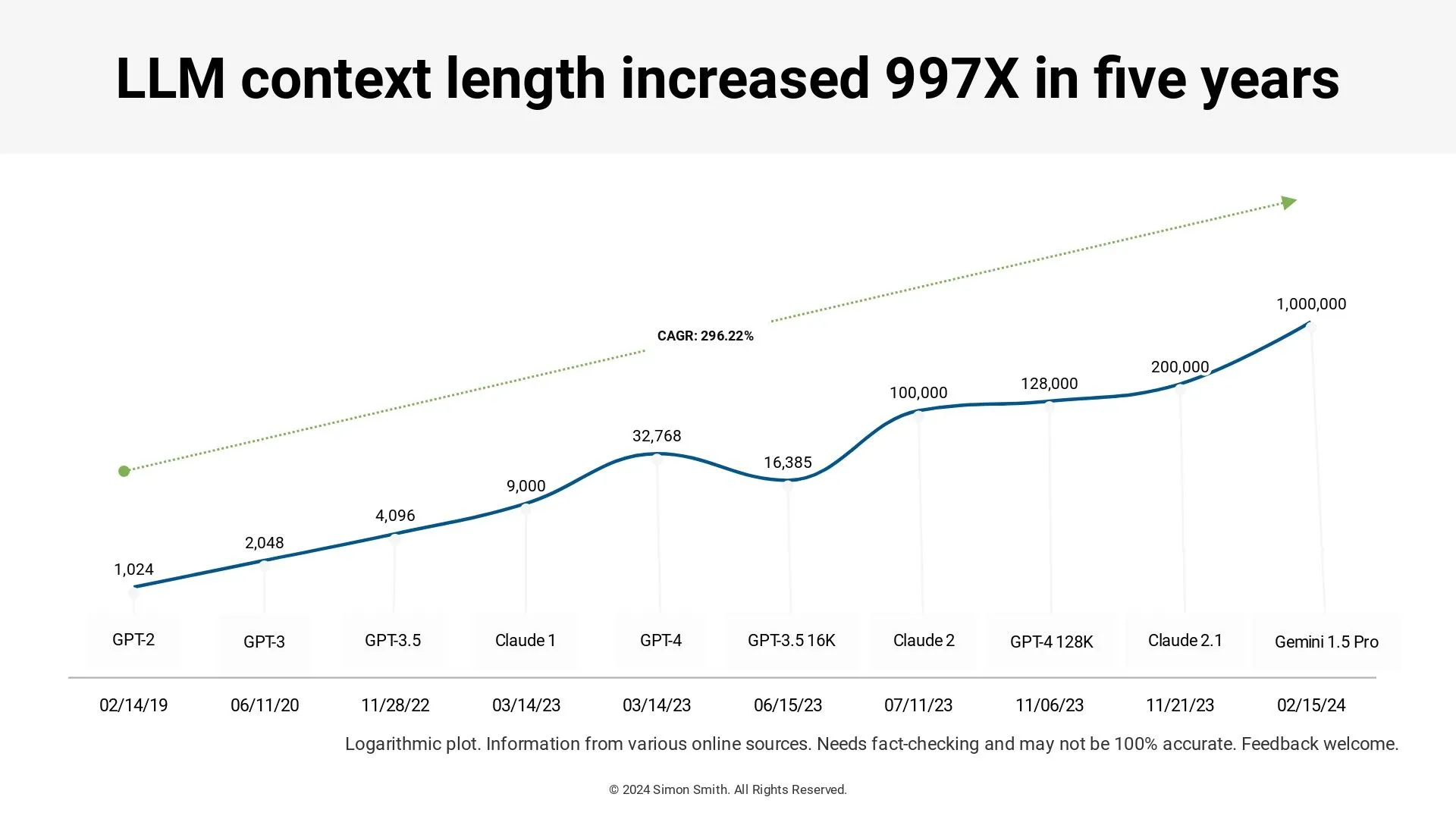
The pursuit of extending context lengths has become a central focus for major AI research labs and companies alike. A key question that has arisen is whether simply increasing the context length provides significant benefits compared to the very popular retrieval-augmented generation (RAG) workflows, where the LLM attends to relevant retrieved documents in addition to the input context. At the time of writing this, RAG remains the the most popular use case for LLMs by far.
In a recent study from NVIDIA (https://arxiv.org/pdf/2310.03025v1.pdf), researchers performed a comprehensive evaluation comparing long context LLMs against retrieval-augmented models on seven diverse datasets spanning question answering and query-based summarization tasks. Surprisingly, they found that a 4K context LLM augmented with simple retrieval can achieve comparable performance to a 16K context LLM fine-tuned with complex positional interpolation methods. Moreover, retrieval significantly boosted the performance of LLMs regardless of their context window size.
Their state-of-the-art model, a retrieval-augmented 70B parameter LLM with a 32K context window, outperformed GPT-3.5 and Claude on these long context benchmarks while being much more efficient at inference time. These findings suggest that while extending context lengths is valuable, augmenting LLMs with targeted retrieval can provide substantial gains that complement long context modeling.
The quest for infinite context lengths, however, could unlock transformative capabilities in language understanding and generation. But what does this mean? Is it even physically possible to have infinite context length? Before getting there, let us understand a key way to test long context models.
Several model providers do what is called a Needle-in-a-haystack test - and it’s exactly what it sounds like:
- Place a random fact or statement (the 'needle') in the middle of a long context window (the 'haystack')
- Ask the model to retrieve this statement
- Iterate over various document depths (where the needle is placed) and context lengths to measure performance
See https://github.com/gkamradt/LLMTest_NeedleInAHaystack for reference.
An instance of using this test is from our friends at Anthropic, where the researchers implemented several refinements to get better at the test. They diversified the needle/question pairs by offering a selection of 30 options for every prompt and extended the evaluation to encompass a varied haystack sourced from a diverse range of materials, including Wikipedia articles, legal documents, financial reports, and medical papers. Furthermore, the researchers experimented with various parameters of the evaluation, such as the size of the document corpus, scaling it up to 200k tokens, and manipulating the placement of the needle within this corpus. For each unique combination, they generated 20 distinct variations by reshuffling articles to create background text. To aid the models in pinpointing relevant sentences amidst the vast sea of information, the researchers appended a crucial cue to their prompts: "Here is the most relevant sentence in the documents." This strategic addition primed the models, resulting in improved recall by minimizing refusals. The results:
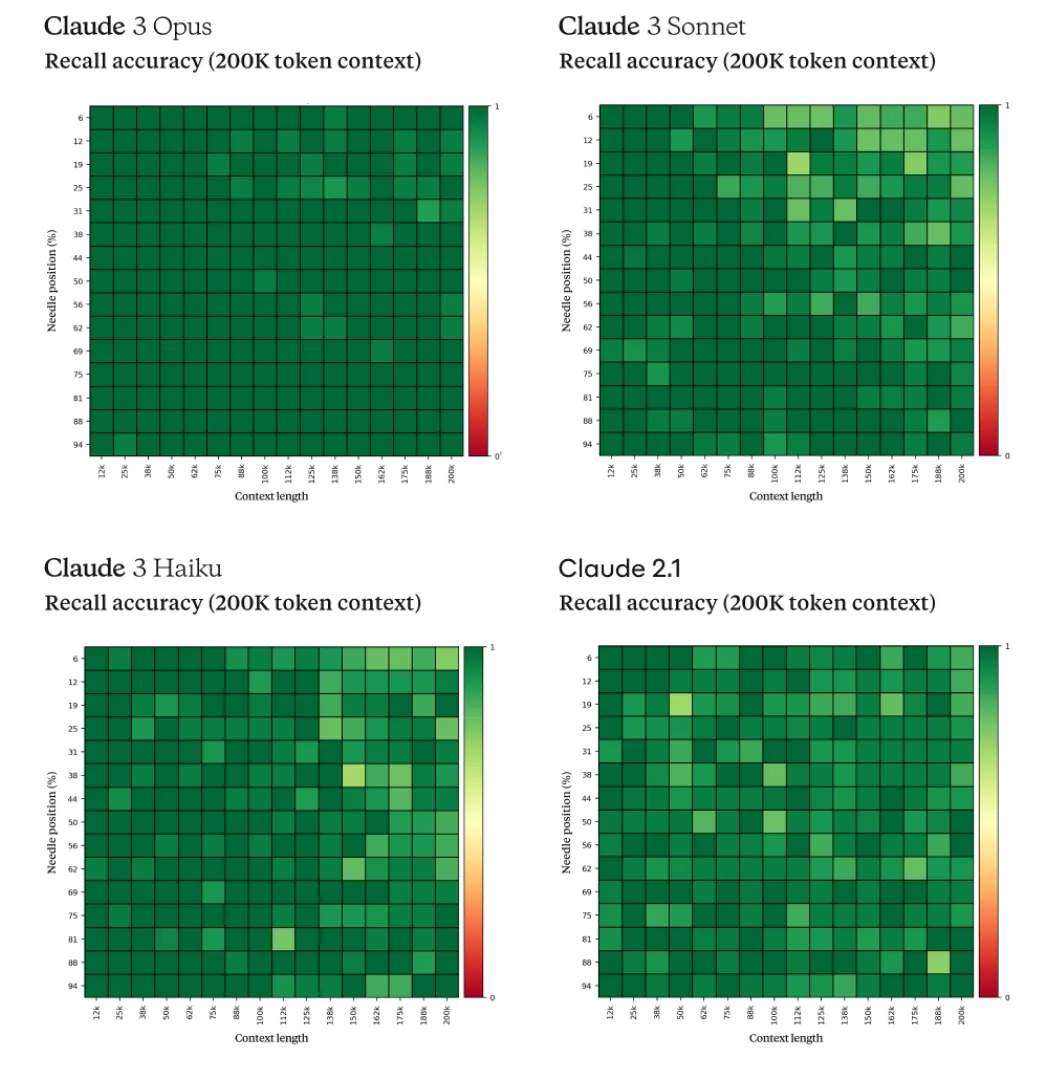
In analyzing the results, all models did better than the older Claude 2.1 models in contexts shorter than 100k tokens and exhibited similar proficiency in longer contexts up to 200k tokens. Claude 3 Opus substantially outperforms all other models with a 99.4% average recall, and maintaining a 98.3% average recall at 200k context length. These models (check https://aws.amazon.com/bedrock/claude/) once again have a long, but fundamentally fixed context window owing to, yes you guessed right, attention.
In the previous post (https://community.aws/content/2eeQ9nlrKkXRNIg18Su4cmJq181/genai-under-the-hood-part-2---some-form-of-attention-is-still-what-you-need-looks-like) we covered the basics of attention and why this is still needed.
Training models with very long context lengths requires immense compute power and memory, leading to higher training costs. Researchers have developed techniques like FlashAttention, Sparse Attention, and Conditional Computation to speed up training and inference of long-context models, but challenges persist. Another obstacle is the lack of long-form training data, as most pre-training datasets consist of short text examples, limiting the ability of models to leverage very long contexts. Evaluating the long-context capabilities of LLMs is also an open challenge, as robust benchmarks are still being developed.
Training models with very long context lengths requires immense compute power and memory, leading to higher training costs. Researchers have developed techniques like FlashAttention, Sparse Attention, and Conditional Computation to speed up training and inference of long-context models, but challenges persist. Another obstacle is the lack of long-form training data, as most pre-training datasets consist of short text examples, limiting the ability of models to leverage very long contexts. Evaluating the long-context capabilities of LLMs is also an open challenge, as robust benchmarks are still being developed.
The attention mechanism in Transformer models has a quadratic time and space complexity with respect to the number of input tokens. Specifically the self-attention mechanism's Key-Value (KV) cache is proportional to the input sequence length. As a result, popular models like GPT have been confined to relatively small context lengths of 2048 tokens or less during pre-training to ensure computational tractability.
Two recent papers, "Leave No Context Behind" (https://arxiv.org/abs/2404.07143) from Google and "Infinite-LLM: Efficient LLM Service for Long Context with DistAttention and Distributed KVCache" (https://arxiv.org/pdf/2401.02669.pdf) from Alibaba, propose innovative solutions to transcend this limitation, enabling transformer models to process infinitely long context sequences using bounded compute resources. While the former introduces a novel attention technique called Infini-attention, the latter presents a distributed system design, DistKV-LLM, for efficient KV cache management across a data center.
The key innovation in "Leave No Context Behind" is the Infini-attention mechanism, which stores KV states from previous segments in a compressed form using an associative memory matrix M. This memory can be incrementally updated and retrieved in a computationally efficient manner:
Memory Update: M_s = M_{s-1} + σ(K)^T V (Equation 1)
Memory Retrieval: A_mem = σ(Q)M_{s-1} / σ(Q)z_{s-1} (Equation 2)
Here, K, V are the keys and values from the current segment, and Q are the queries. σ(.) is a non-linear function that is commonly used in fast weight memories.
The key difference from standard self-attention is that Infini-attention combines both local windowed attention over the current segment and global long-range attention by retrieving from the compressed memory M, using a gating mechanism:
A = sigmoid(β) ⊙ A_mem + (1 - sigmoid(β)) ⊙ A_dot (Equation 3)
This allows modeling long and short-range dependencies in a unified and efficient manner, with only a small constant memory overhead from storing M. For more information, or a deeper insight into this, please take a look at the original paper - (https://arxiv.org/abs/2404.07143)
While Infini-attention addresses the computational challenges of processing long contexts, the DistKV-LLM system from Alibaba tackles the memory management aspect, particularly in the cloud environment. The dynamic and unpredictable nature of auto-regressive text generation in LLM services demands flexible allocation and release of substantial resources, posing significant challenges in designing cloud-based LLM service systems.
DistKV-LLM introduces DistAttention, a novel distributed attention algorithm that segments the KV Cache into smaller, manageable units called “rBlocks”, enabling distributed processing and storage of the attention module. Each LLM service instance is equipped with an rManager that virtualizes the global memory space of GPUs and CPUs, dividing it into fixed-sized physical rBlocks.
The system further incorporates a “gManager”, a global coordinator that maintains a protocol ensuring effective, scalable, and coherent resource management among distributed rManagers. When an instance faces a memory deficit due to KV Cache expansion, DistKV-LLM proactively seeks supplementary memory from less burdened instances, effectively orchestrating all accessible GPU and CPU memories spanning across the data center.
To address the deterioration of data locality resulting from distributed storage, DistKV-LLM proposes the DGFM algorithm, which conceptualizes the problem as a search for circles within a directed graph representing debt relationships among instances. By strategically recalling and swapping memory blocks, DGFM enhances overall system efficiency and memory utilization.
Moreover, DistKV-LLM introduces optimizations to overlap computation and communication, minimizing the overhead associated with distributed storage of the KV cache.
Both papers present elegant and scalable approaches to removing the context length bottleneck hindering current LLMs. While Infini-attention focuses on the attention mechanism itself, enabling efficient compression and retrieval of long-range context, DistKV-LLM tackles the system design challenges of managing and distributing the KV cache across a data center. Infini-attention's compression and retrieval accuracy could potentially be further improved by refining the delta update rule (Equation 1). Additionally, achieving better length generalization when fine-tuning on relatively shorter examples compared to the target context length at inference time remains an open challenge. DistKV-LLM, on the other hand, demonstrates the feasibility and efficiency of distributed KV cache management, supporting context lengths up to 19 times longer than current state-of-the-art systems. However, the communication overhead associated with distributed storage and the potential for performance fluctuations due to data swapping or live migration processes remain areas for further optimization.
From an applications perspective, infinite context capacities pave the way for more intelligent language understanding across multiple documents, seamless long-form question answering without context truncation, and even multi-session dialog modeling. However, simply providing more context may not be enough – the model may also need stronger reasoning capabilities to extract coherent insights from disparate information sources. Integrating Infini-attention or DistKV-LLM with sparse retrieval components could potentially ground the LLM's generation in relevant knowledge sources.
While both Infini-attention and DistKV-LLM present promising solutions to the context length bottleneck, there are potential limitations and pitfalls to consider:
- Compression Accuracy: The associative memory compression in Infini-attention may lead to information loss, potentially impacting the model's performance on long-range dependencies or reasoning tasks.
- Communication Overhead: Despite optimizations, the distributed nature of DistKV-LLM's KV cache storage may introduce non-trivial communication overhead, which could become more significant as context lengths increase further.
- Scalability Challenges: As LLMs continue to grow in size and complexity, the scalability of these solutions across multiple dimensions (model size, context length, and distributed infrastructure) remains an open challenge.
- Reasoning Capabilities: While longer context windows enable processing more information, LLMs may still struggle with coherent reasoning and insight extraction without explicit enhancements to their reasoning capabilities. We see this with much shorter context lengths as well.
- Energy and Resource Considerations: Enabling infinite context processing may come at the cost of increased energy consumption and resource utilization, raising concerns about environmental impact and sustainability.
The quest for infinite context processing in Large Language Models has led to innovative solutions like Infini-attention and DistKV-LLM, which address computational and memory management challenges, respectively. By coupling local and global/long-range signals in a unified mechanism, Infini-attention unlocks the potential for language models to dynamically adapt to and internalize information from infinite context streams. Complementarily, DistKV-LLM establishes an efficient memory pool meticulously crafted for LLM services, supporting the processing of exceptionally long context lengths effectively.
These advancements pave the way for more intelligent language understanding, seamless long-form question answering, and multi-session dialog modeling and perhaps a decent replacement for RAG. However, challenges such as compression accuracy, communication overhead, scalability, and enhancing reasoning capabilities remain areas for further research and development. As LLMs continue to evolve and find applications in diverse domains, the pursuit of infinite context processing will be instrumental in unlocking their true potential, enabling more natural and coherent interactions with these powerful language models.
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.