Fighting Hallucinations with LLM Cascades 🍄
Learn how to implement FrugalGPT-style LLM cascades on top of Amazon Bedrock using LangChain and LangGraph without breaking the bank.
João Galego
Amazon Employee
Published May 3, 2024
Last Modified May 4, 2024
"Everything you are comes from choices" ―Jeff Bezos
One of the best things about Amazon Bedrock is model choice. By using Amazon Bedrock, users can experiment and build applications on top of the best-performing foundation models (FMs) from leading AI companies like Anthropic, Mistral, Stability and others.

As a Solutions Architect, one of the top questions I get from customers is: which model should I use?
One way to get out of the choice overload plateau is to use Model Evaluation jobs to test different models and then choose the best one for each specific use case.
💡 If you're looking for guidance, AWS Community has some great posts on how to handle this decision. See, for example, How to choose your LLM by Elizabeth Fuentes and Choose the best foundational model for your AI applications by Suman Debnath.

Sometimes, however, the best model is not the only choice, nor necessarily the right one.
Simple queries can often be addressed by weaker and more affordable models without the need to call the cavalry. Weaker models may not work all the time, but they get the job done.
So how do we know which one is best? And what if we don't want to choose? What if we just want to rely on the wisdom of the crowd and use multiple models... without breaking the bank? 💸
In this post, I'll take the contrarian view to the just-select-the-best-model approach and show you an interesting way to handle choice overload using LLM cascades.
Don't worry, I'll spend some time in the next section explaining what these are and why and when you should use them.
Finally, in the last section, I'll demonstrate all of it by implementing the LLM cascade pattern as a way to tackle one of the biggest issues around LLMs: hallucinations.
Ready, set... go!
In the accelerated timescale of Generative AI innovations, LLM Cascades are old news.
First introduced in the FrugalGPT paper (Chen, Zaharia & Zou, 2023), the general idea is surprisingly easy to state: prompt LLMs in sequence (weaker models first), evaluate their responses and return the first answer that is good enough. Simple, right?
")
Every LLM Cascade is made of two core components:
- a scoring function which evaluates a generated answer to a question by producing a reliability score between
0👎 and1👍 and - an LLM router that dynamically selects the optimal sequence of models to query
Given a new query, the LLM router will
- Invoke a model on the list to generate an answer
- Use the scoring function to evaluate how good it is
- Returns the answer if the score is higher than a given threshold (which can be different for each model)
- Otherwise, it moves to the next model on the list and goes back to step 1
This will continue until the LLM cascade generates an acceptable answer or reaches the final model.
The tricky part is the scoring function. We can create one by training a simple regression model to distinguish yay from nay answers. Ideally, this model should be much smaller, faster and cheaper to run than the weaker LLMs in the sequence to make up for the investment.
The original paper used a simple DistilBERT model as a scoring function, while the selection of the LLM sequence and threshold values is modeled as a constrained optimization problem bounded by the customer's available budget.
👨💻 If you're interested in the original implementation, the code is available on GitHub.
As we can clearly see in the image below, FrugalGPT-style LLM cascades can reach the same level of performance as the best LLM in the chain at a fraction of the cost:
")
The original implementation focused on balancing performance and cost, but there are obviously other factors to consider:
"(...) real-world applications call for the evaluation of other critical factors, including latency, fairness, privacy, and environmental impact. Incorporating these elements into optimization methodologies while maintaining performance and cost-effectiveness is an important avenue for future research."
Latency, in particular, can be a big concern if the "model hit ratio" for weaker models (similar to 'cache hit ratio' but for generated answers) is low and the scoring function execution time is high. Ideally, we want most answer to come from the weaker models in the chain.
Another limitation of FrugalGPT-like LLM cascades is related to their performance on intricate reasoning tasks (Yue et al., 2023). These tasks are hard for LLM cascades since
"Intuitively, it is very challenging to evaluate the difficulty and the answer correctness of a reasoning question solely based on its literal expression, even with a large enough LLM, since the errors could be nuanced despite the reasoning paths appearing promising."
Yue et al. (2023) proposed a new routing mechanism (pictured below) based on the observation that weaker models tend to be consistent when answering easy questions, but inconsistent when the question is hard.
")
These new LLM cascades use a Mixture-of-Thought (MoT) strategy that emulates expert opinion by sampling answers from both Chain-of-Thought (CoT) and Program-of-Thought (PoT) prompts. The generated answers then go through a consistency check phase to find the majority-voted answers (vote-based) and whether they are consistent (verify-based).
Note for the brave ones: 🧐 While MoT-based LLM cascades are well beyond the scope of this post, the curious reader is strongly encouraged to read the paper.
💚 Frugality: Accomplish more with less. Constraints breed resourcefulness, self-sufficiency, and invention. There are no extra points for growing headcount, budget size, or fixed expense.
As far as leadership principles go, frugality is one of the toughest ones to master. Frugality is not about being “cheap", but about spending on things that matter most to customers and the long-term success of the company.
There's also another aspect to frugality involving ingenuity and creativity that is well represented by the LLM cascade pattern and its do-more-with-weaker-models approach.
As we saw in the previous section, FrugalGPT-style LLM cascades use a sequence of dynamically selected models (ordered from weaker to stronger) and trained scoring functions to reach good-enough answers while being cost efficient.
Now it's time to take a step back and explore what makes the LLM cascade pattern so effective and start questioning some of its underlying assumptions.
Take the scoring function. Its purpose is to evaluate whether an answer is "good enough". This notion is usually hard to pin down and we end up training a regression model for every mode+task combination we encounter.
But what if shake things up and start asking simpler, more generic questions like:
- Is the model hallucinating?
- Is the model generating NSFW content?
- How is the overall tone?
In the rest of this section, we'll put our minds to work on the first question and create an LLM cascade for a Q&A application that will accept an answer only if it's factually consistent i.e. only if the model producing it is not hallucinating.
Sounds interesting? Then let's get cracking...
👨💻 All code and documentation for this post is available on GitHub.
Let's start by importing the libraries we'll need for the implementation
🚫 TheBedrockChatclass available onlangchain_communityis on the deprecation path and will be removed with version0.3>>> Please don't use it!
The first thing we need is a scoring function. I'll be using Vectara's Hallucination Evaluation model (HHEM) model, which is available on HuggingFace.
This model produces a Factual Consistency Score (FCS) between
0 😵 and 1 🎩, where 0 means that the model is hallucinating and 1 indicates factual consistency.☝️ For more information about the model and FCS, see the Automating Hallucination Detection: Introducing the Vectara Factual Consistency Score post by Vectara.
Next, we need to build the actual LLM cascade. Let's keep things simple and work only with static LLM cascades, which will be composed from individual model chains.
There are at least two ways to approach the LLM cascade implementation.
We can either use LangChain 🦜🔗 to construct each model chain in the sequence (notice that the scoring is done inside each model chain)
then assemble the LLM cascade by joining all chains with conditional branches based on the answer score
or we can decouple the scoring from the model chain
and use LangGraph 🦜🕸️ to manage the LLM cascade flow
Both implementations should yield the same results, so feel free to pick the one you prefer.
Let's add some helper functions to track down costs
and create a Bedrock pricing file (
pricing.json) for Anthropic and Mistral modelsSince we're building an LLM cascade for Q&A tasks, I'll be using a few samples from the Stanford Question Answering Dataset (SQuAD) to test the application

Finally, let's initialize the LLM cascade and test it against our dataset

Threshold values are a good way to convey how much we trust a specific model and how effective the scoring function is in assessing that model's output. In the snippet above, the last threshold value (set to
0) is not actually used. Just think of it as a gentle reminder that we'll accept everything coming from the best (last) model if the LLM cascade execution ever gets there.Looking at the output below, we see that most queries are reliably answered by weaker models (as we expected) leading to huge drops in cost (🔻75-95%). The only exception is the query that reaches the end of the cascade (🔺20%).
Notice that we achieved these results by picking threshold values ad hoc and selecting the model sequence based on a simple heuristic rules involving model pricing and leaderboard positions. For any given task, simple techniques like grid search can be used to find the optimal model sequence and the best threshold values under budget constraints.
Let me add two final notes on visualization and monitoring before wrapping things up.
If you're using the LangGraph version, you can print the compiled graph in ASCII
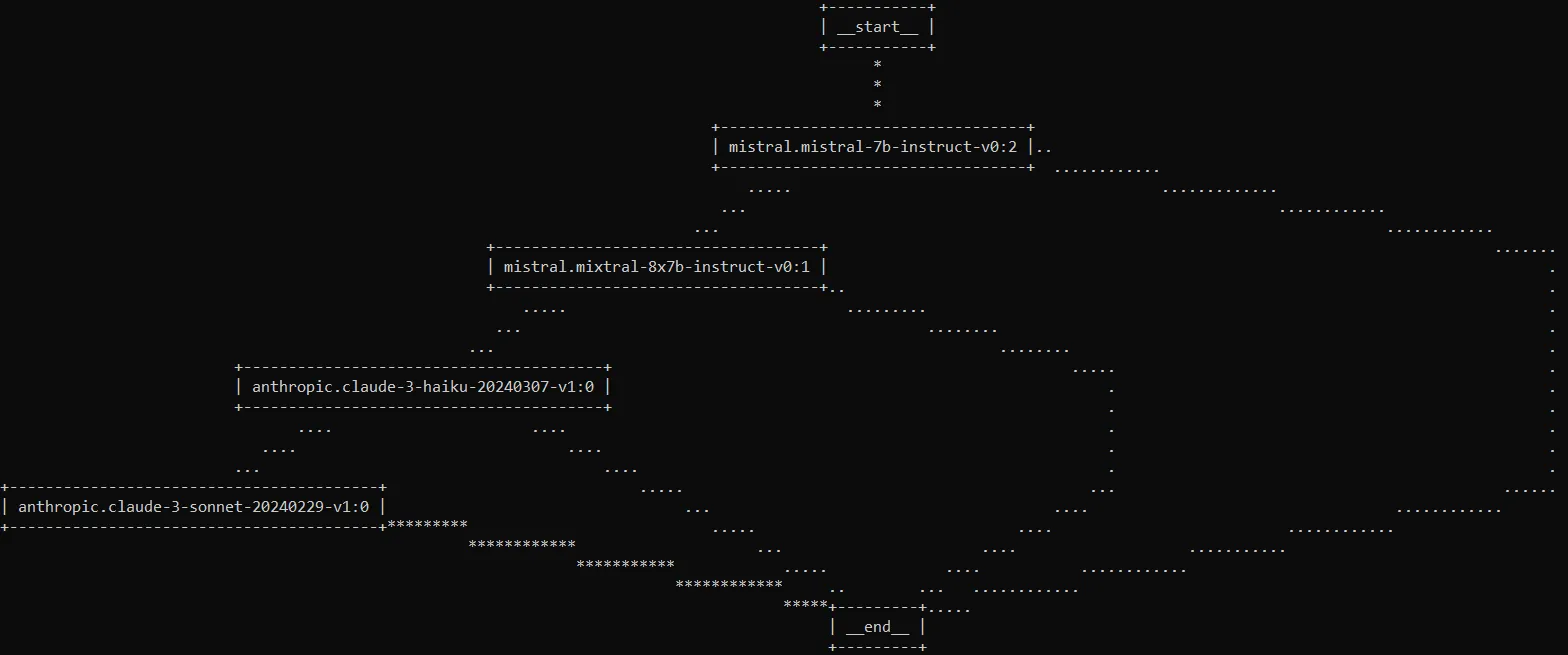
or display it inside a Jupyter notebook using GraphViz
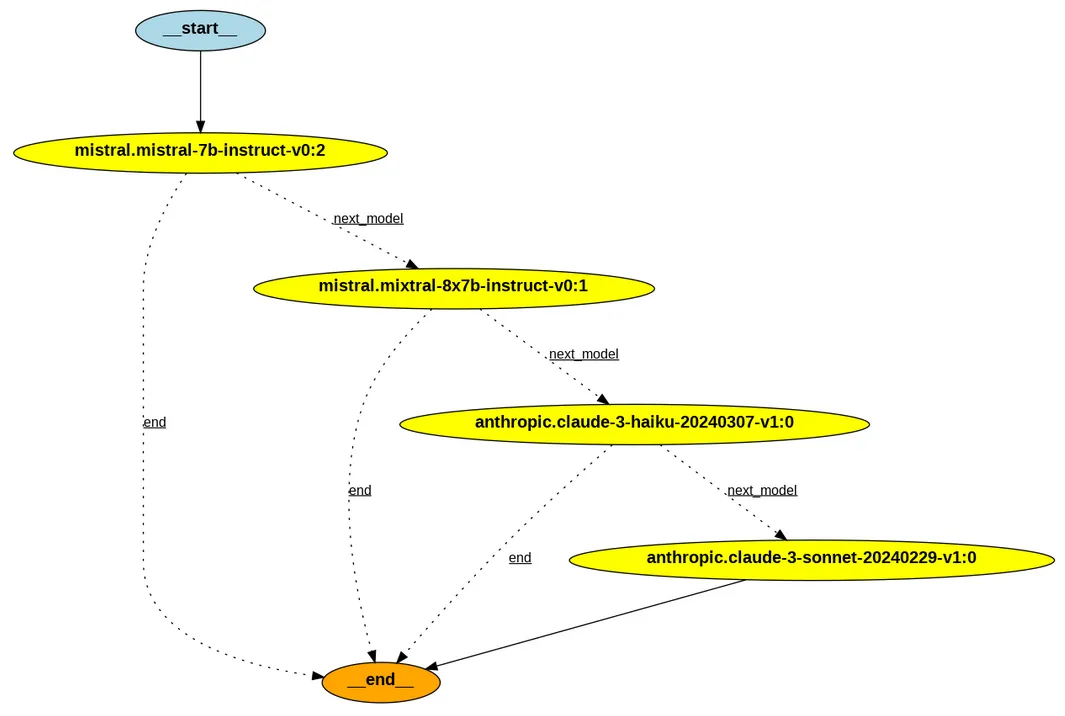
Finally, you can use LangSmith to monitor LLM cascade runs
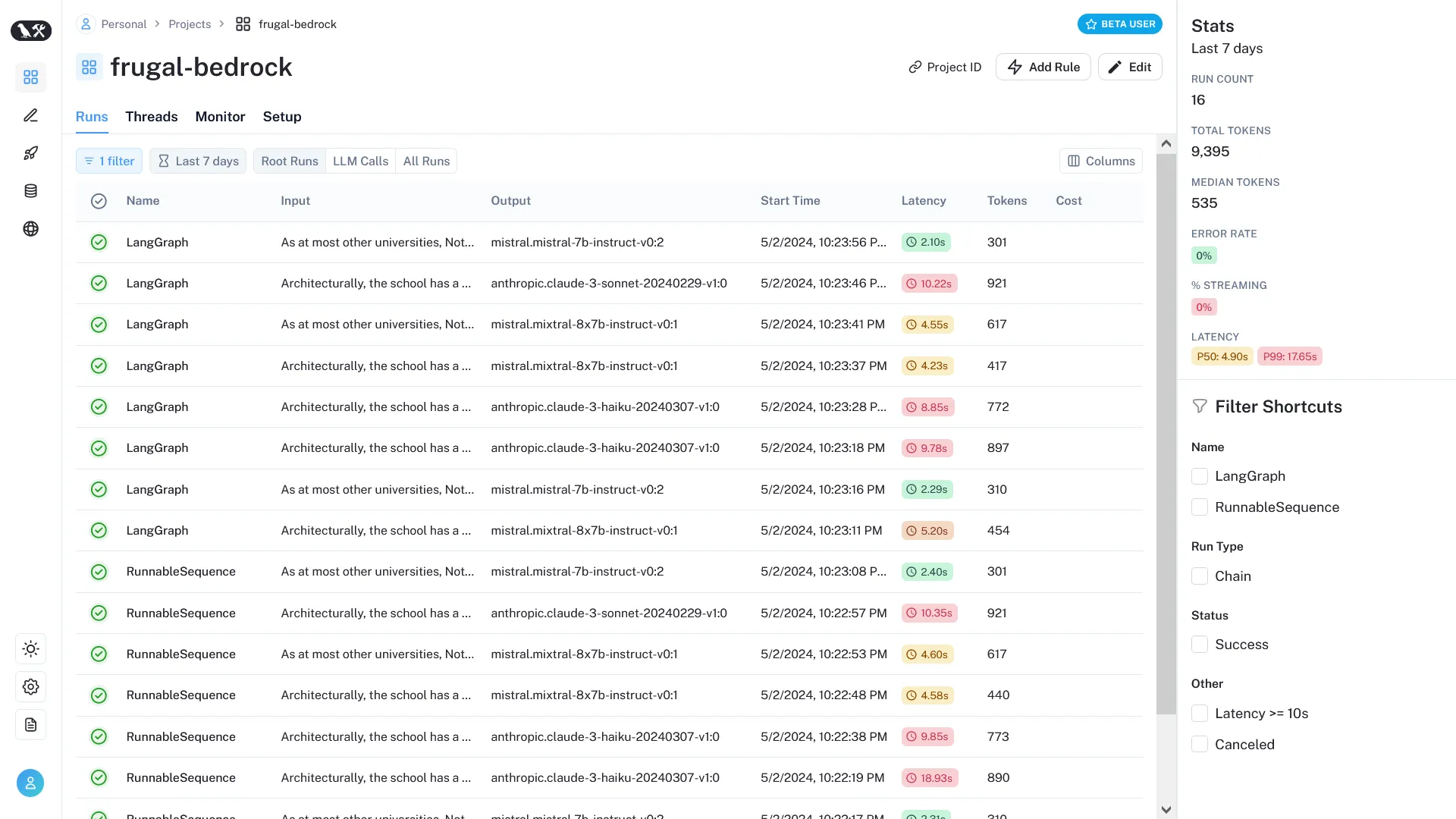
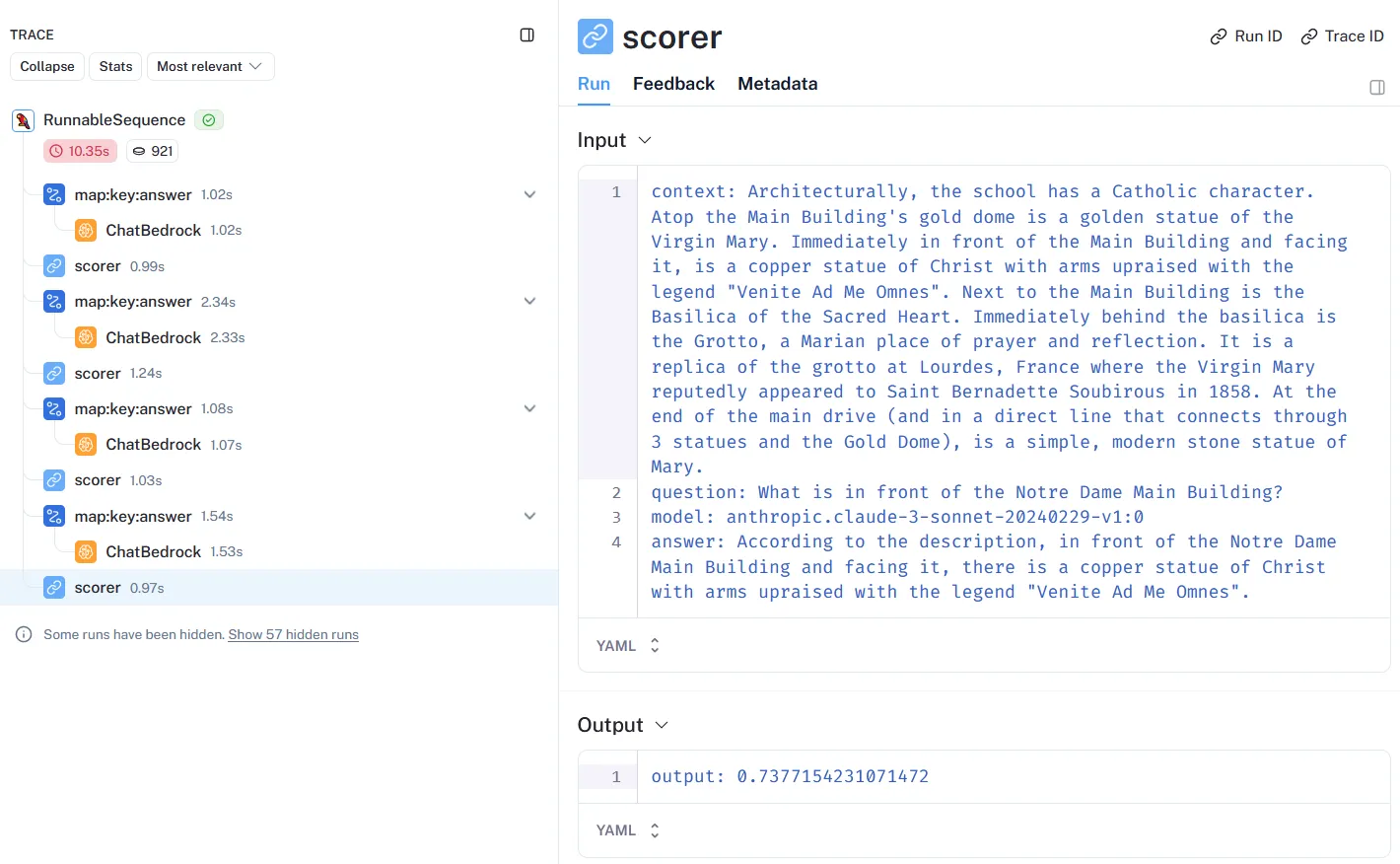
and track query penetration across the model sequence
You've reached the end of this post 🎉
As a token of my appreciation for reading this far, here's a bonus quote about Frugality:
"I think frugality drives innovation, just like other constraints do. One of the only ways to get out of a tight box is to invent your way out." ―Jeff Bezos
See you next time! 👋
- (Chen, Zaharia & Zou, 2023) FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
- (Honovich et al., 2022) TRUE: Re-evaluating Factual Consistency Evaluation
- stanford-futuredata/FrugalGPT - offers a collection of techniques for building LLM applications with budget constraints
- MurongYue/LLM_MoT_cascade - provides prompts, LLM results and code implementation for Yue et al. (2023)
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.