✅️I am translating and posting the original text written in Japanese. Screen capture and language settings are set for Japan.
Generative AI is a very prominent technology, but it may be a bit difficult to get started with. New models and utilization methods are emerging almost daily, making it quite challenging to stay up-to-date.
To help those who have missed the opportunity to get started, I've created a hands-on article with the concept of just trying it out and experiencing it. 🎉🎉🎉
The content of the hands-on session is RAG. RAG is a commonly used keyword when it comes to the application of generative AI. In this hands-on, you'll be able to experience the latest "Advanced RAG", not just regular RAG.
✅️We'll assume you have some knowledge of AWS and Python.
⚠️Since this is a super-fast RAG experience, we won't cover what generative AI is or how to write prompts at all (prompts won't even be mentioned).
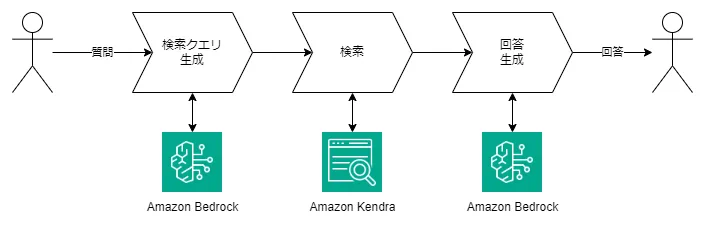
Referenced AWS Architecture
This is from the AWS official blog published on 2024/5/1.
RAG is a technology that solves the challenges of using generative AI
However, a simple RAG architecture may not always provide the desired results
As a performance improvement technique, Advanced RAG has been proposed in a research paper
The blog builds and evaluates Advanced RAG using Kendra and Bedrock (Claude 3)
The Architecture to be Constructed
To make it easy for those new to generative AI, I've designed an architecture focused on clarity, based on the AWS official blog.
The "evaluation of search result relevance" mentioned in the blog has been excluded, as it was deemed to have a small contribution to accuracy improvement.
✅️We'll quickly build the latest RAG architecture on AWS as of May 2024.
Service Explanation
The AWS services used are two:
Amazon Kendra
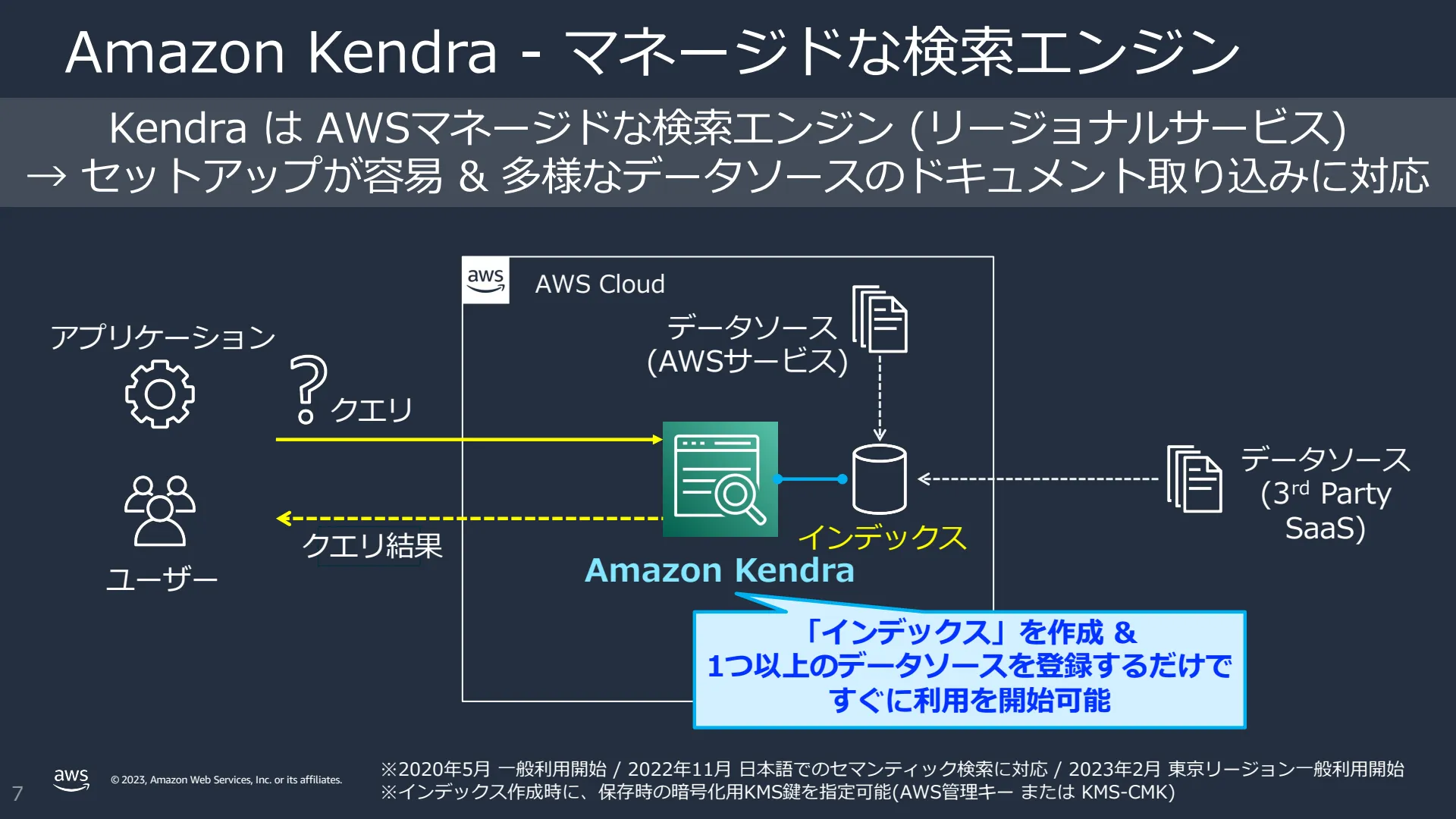
Amazon Kendra is an intelligent search service that uses machine learning (ML). Amazon Kendra rebuilds enterprise search for your websites and applications. Even if your company's content is scattered across various locations and content repositories, your employees and customers can find the content they need.
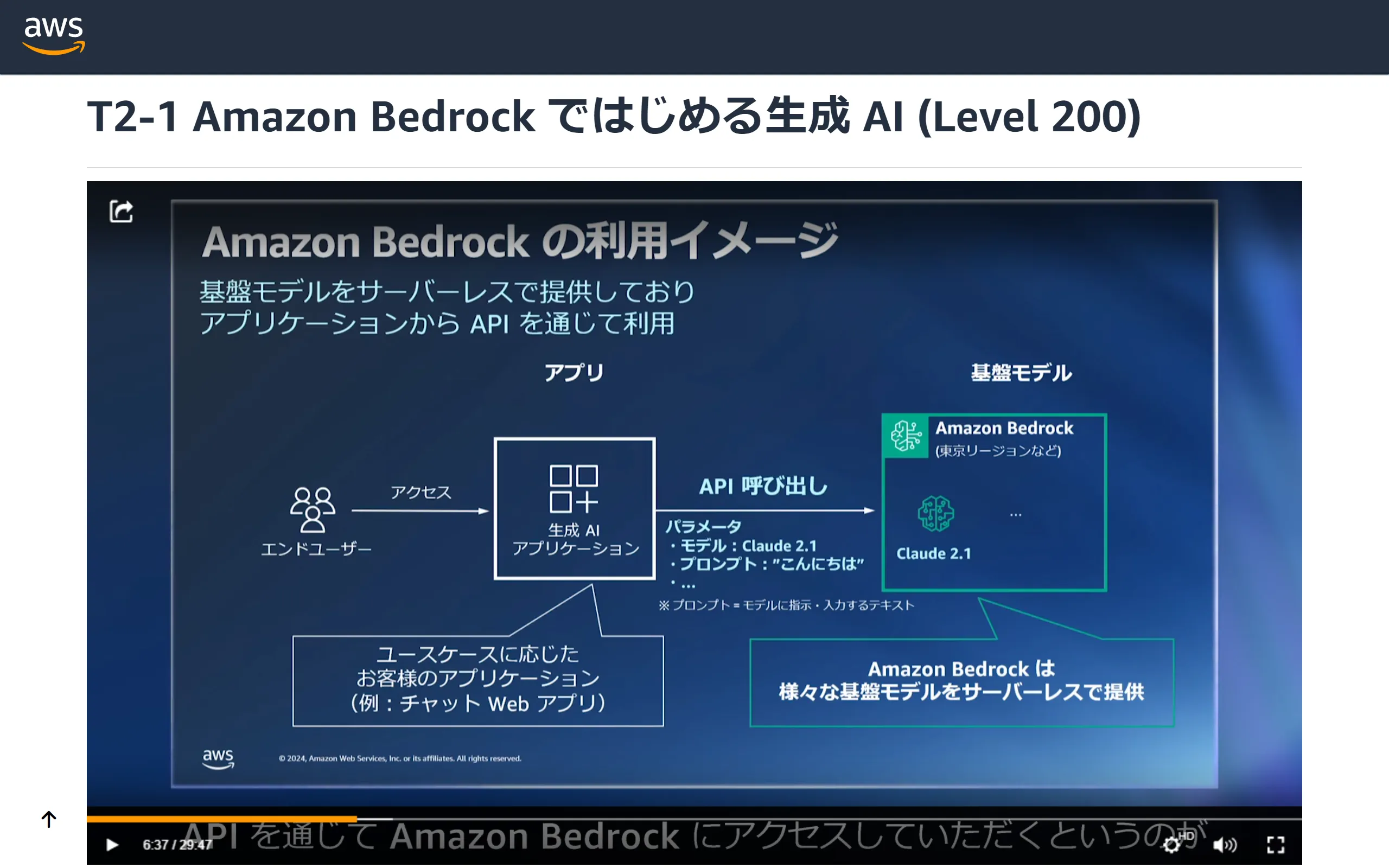
Amazon Bedrock is a fully managed service that allows you to select high-performance foundation models (FM) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. It provides a wide range of capabilities needed to build secure, private, and responsible generative AI applications.
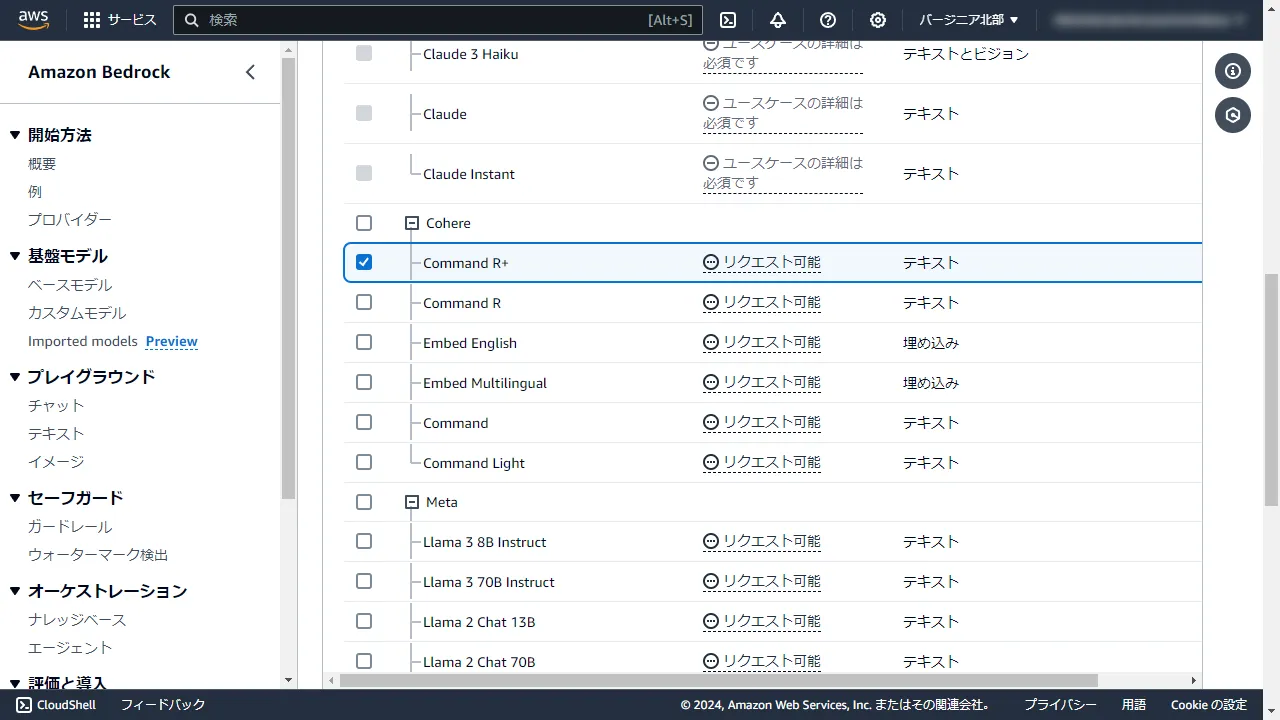
While Bedrock supports various generative AI models, for this hands-on, we'll be using Command R+ from Cohere, a model that became available just recently on 4/29.
We'll enable the use of Cohere's Command R+ model.
Sign in to the AWS Management Console and select the Northern Virginia (us-east-1) region.
Search for "Bedrock" and select Amazon Bedrock.
Open the left menu and click on Model Access.
Click on Manage Model Access.
Check the box for "Command R+" and click Request Model Access at the bottom of the page.
It should take about 5 minutes, and then the status will change to "Access granted". (You should also receive an email with the subject "You accepted an AWS Marketplace offer".)
The Bedrock configuration is done.
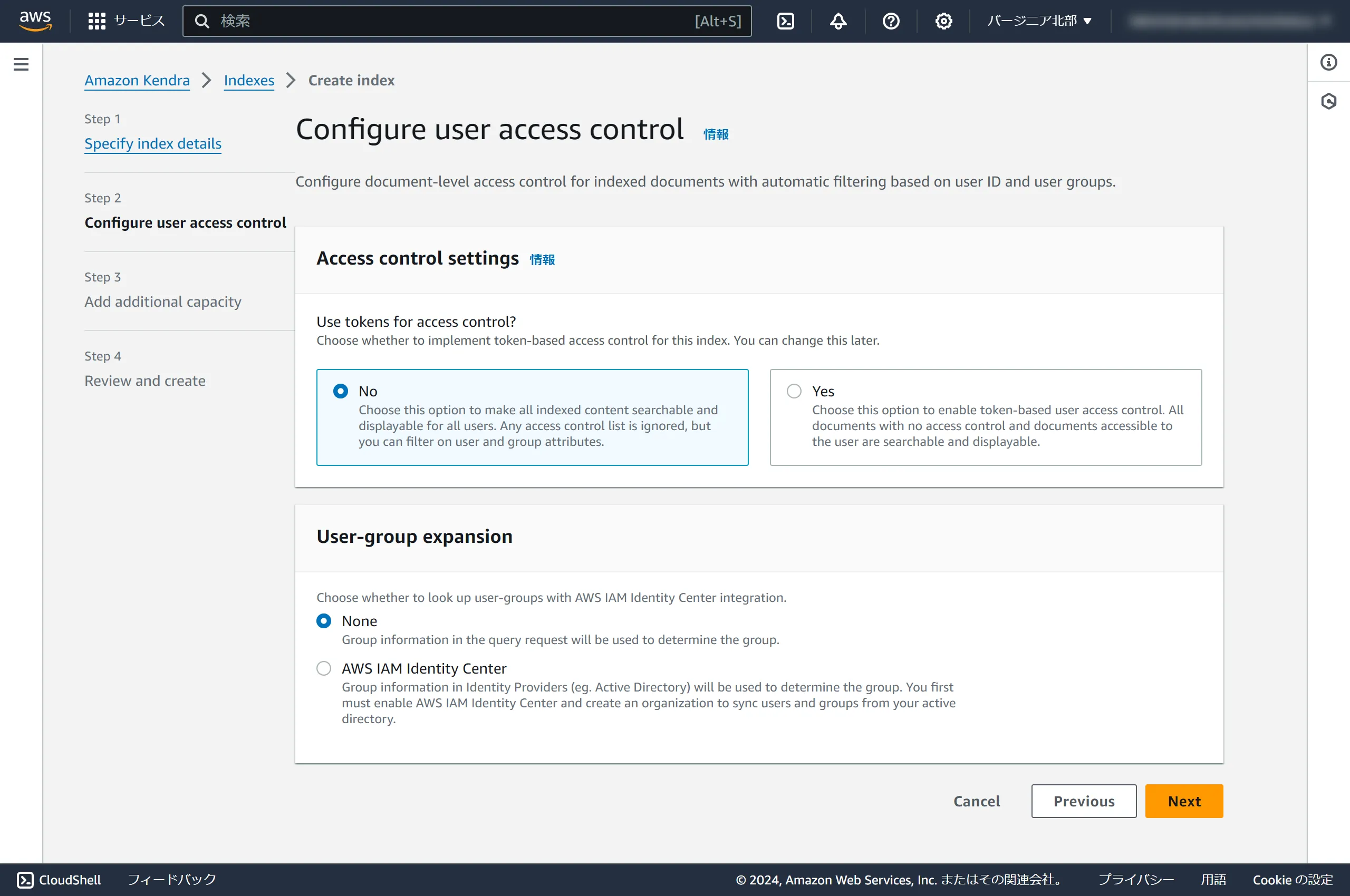
Amazon Kendra
✅️Kendra has a free usage tier."You can get started with the Amazon Kendra Developer Edition for free for the first 30 days, with up to 750 hours of free usage. The use of connectors is not included in the free usage and is subject to the regular usage time and scanning fees. If you exceed the free usage limit, you will be charged the Amazon Kendra Developer Edition rates for the additional resources used."[https://aws.amazon.com/kendra/pricing/?nc1=h_ls](https://aws.amazon.com/kendra/pricing/?nc1=h_ls)If you no longer need it, please delete the index you created, as the charges can be quite substantial once the free tier is exceeded.
Search for "Kendra" and select Amazon Kendra.
Click on Create an Index.
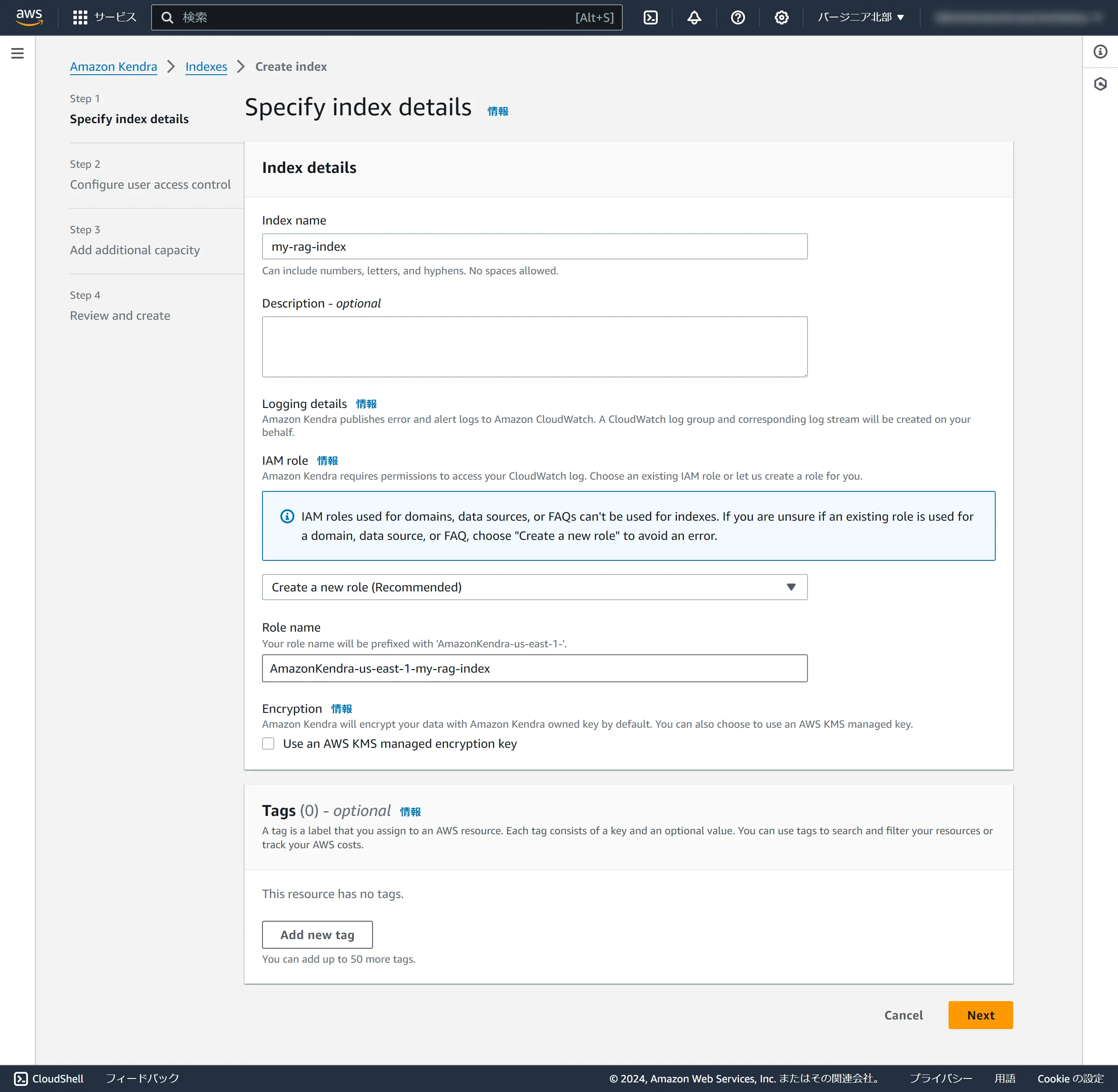
Fill in the required information and click Next.
Item
Value
Index name
my-rag-index
IAM role
Select Create a new role
Role name
AmazonKendra-us-east-1-my-rag-index (the prefix AmazonKendra-us-east-1- will be automatically added)
Don't make any changes and click Next.
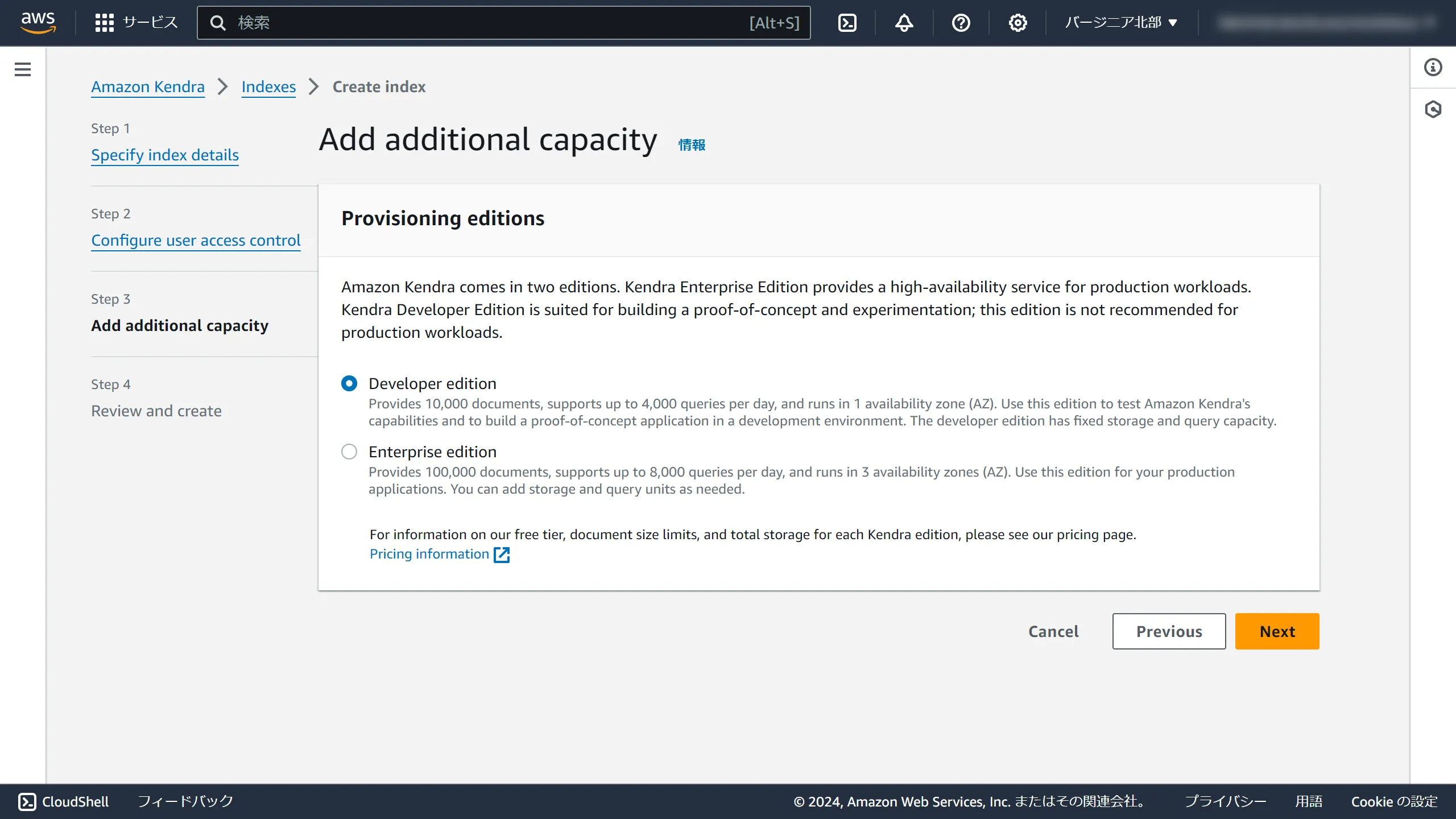
Select Developer edition and click Next.
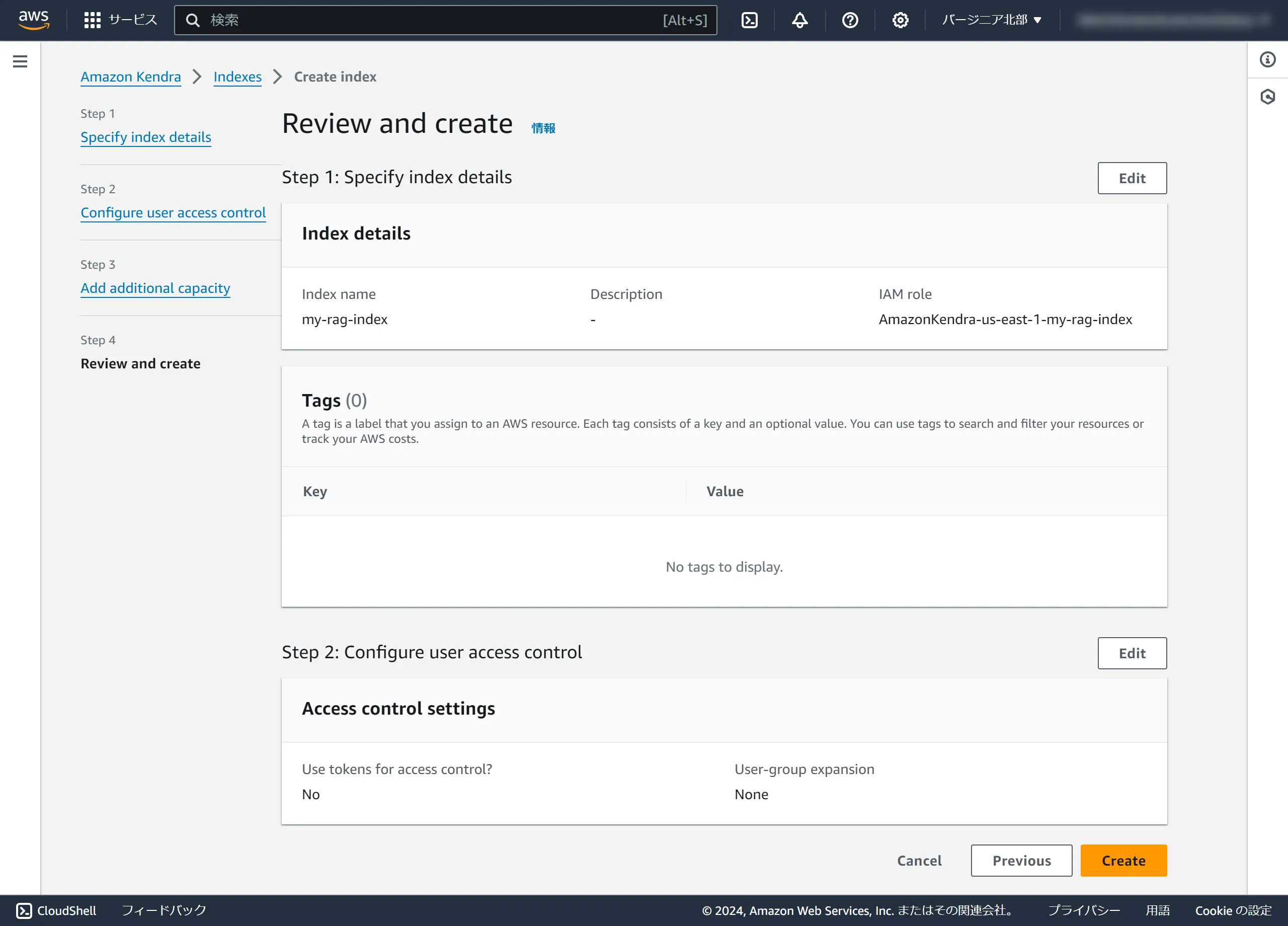
Review the information and click Create.
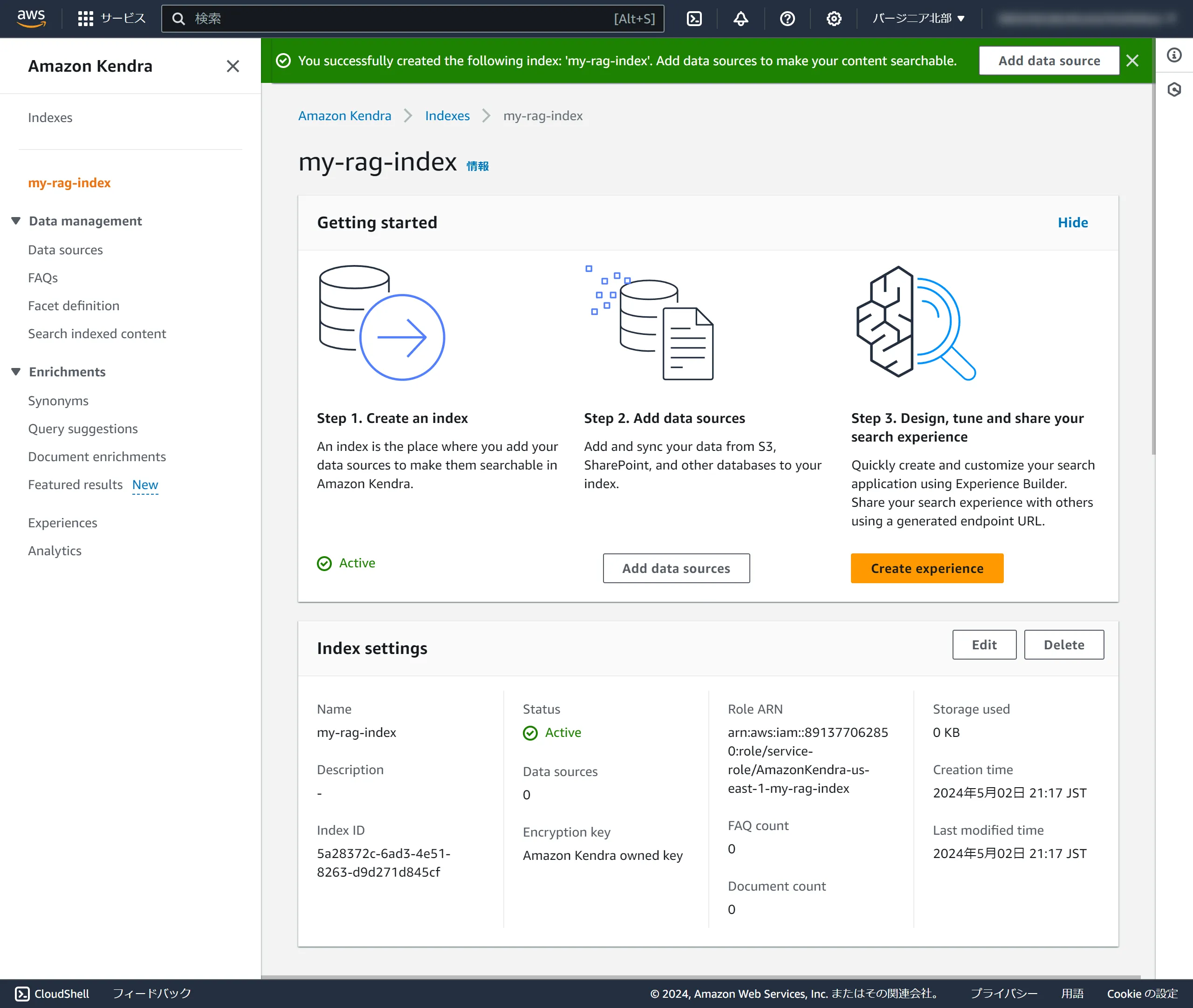
The index has been created.
Next, we'll create a data source. A data source is what you want to search. You can specify S3 buckets, various databases, etc.
✅️Kendra pre-crawls the data source information and registers it to the index. This allows for faster retrieval of search results. (It's not that it accesses the data source itself every time you search.)
Click on Add data sources.
Many connectors are displayed. This time, we'll crawl and register the AWS documentation site. Enter "Web" in the search bar and click on Web Crawler (V2.0).
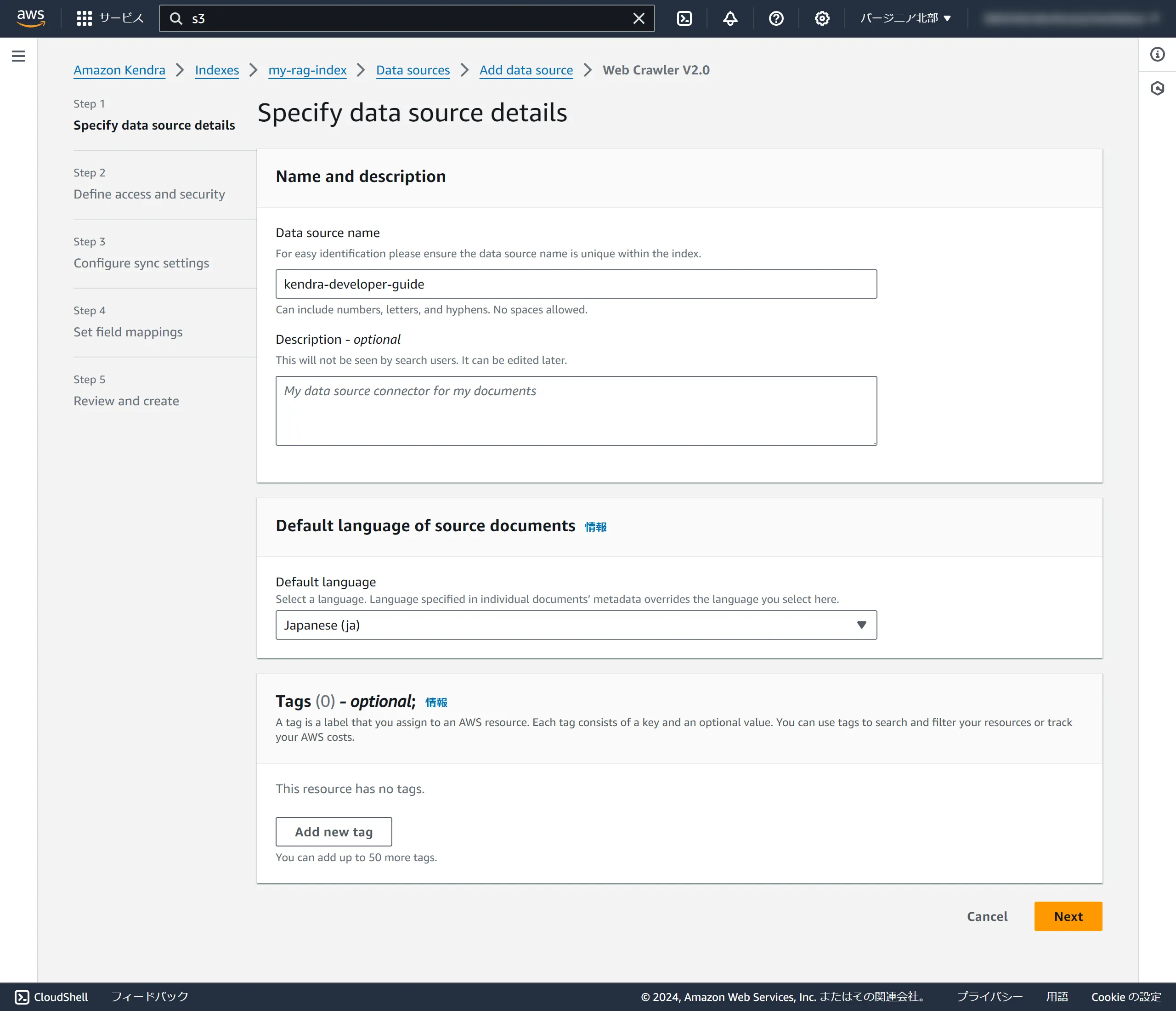
Configure the data source settings.
The Default language setting is quite important. If you have Japanese documents, be sure to select Japanese (ja). (If you leave it as English, your searches won't return anything, so be careful.)
Item
Value
Data source name
kendra-developer-guide
Default language
Japanese (ja)
Continue with the rest of the settings. After inputting, click Next.
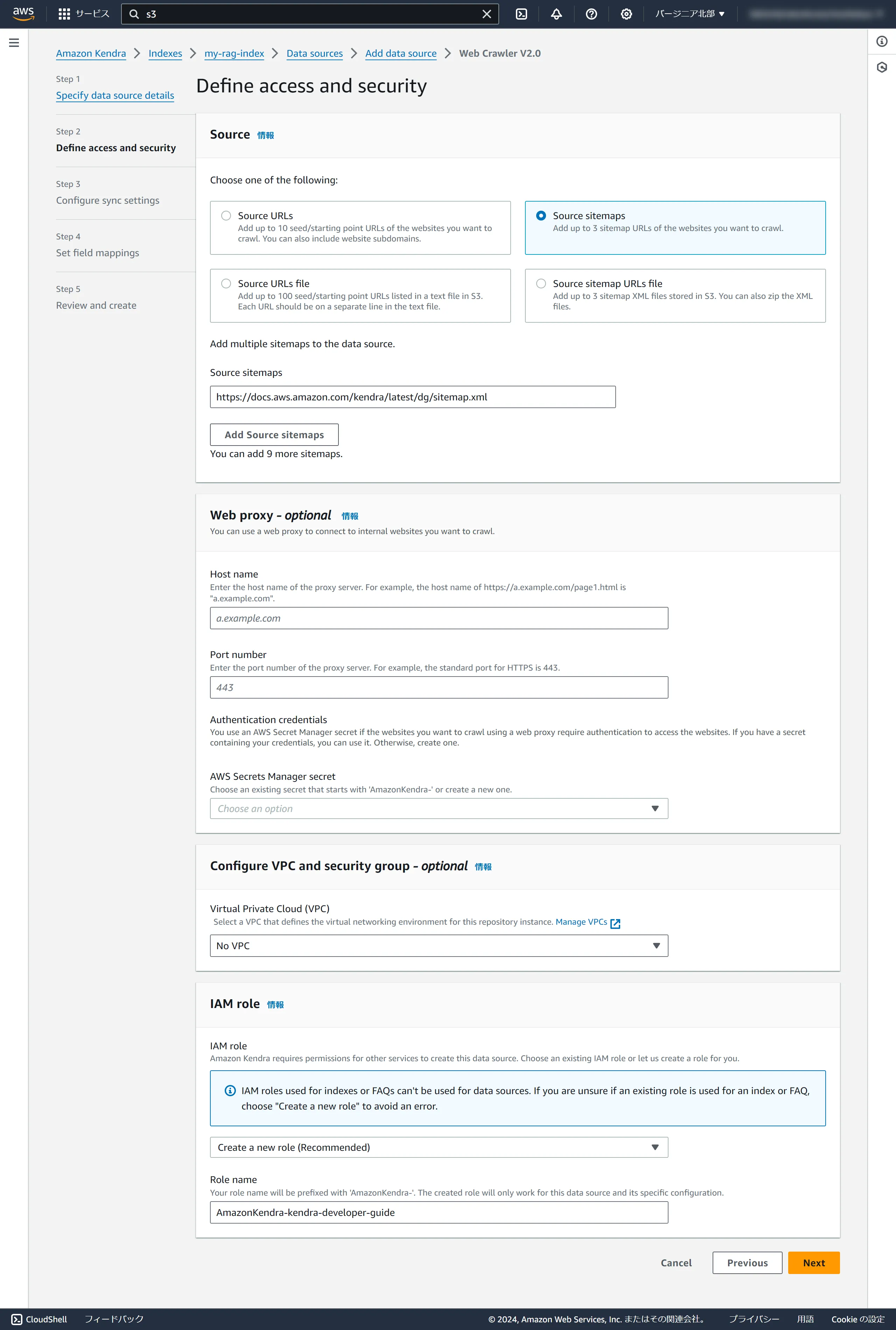
AmazonKendra-kendra-developer-guide (the prefix AmazonKendra- will be automatically added)
A bit more configuration. After inputting, click Next.
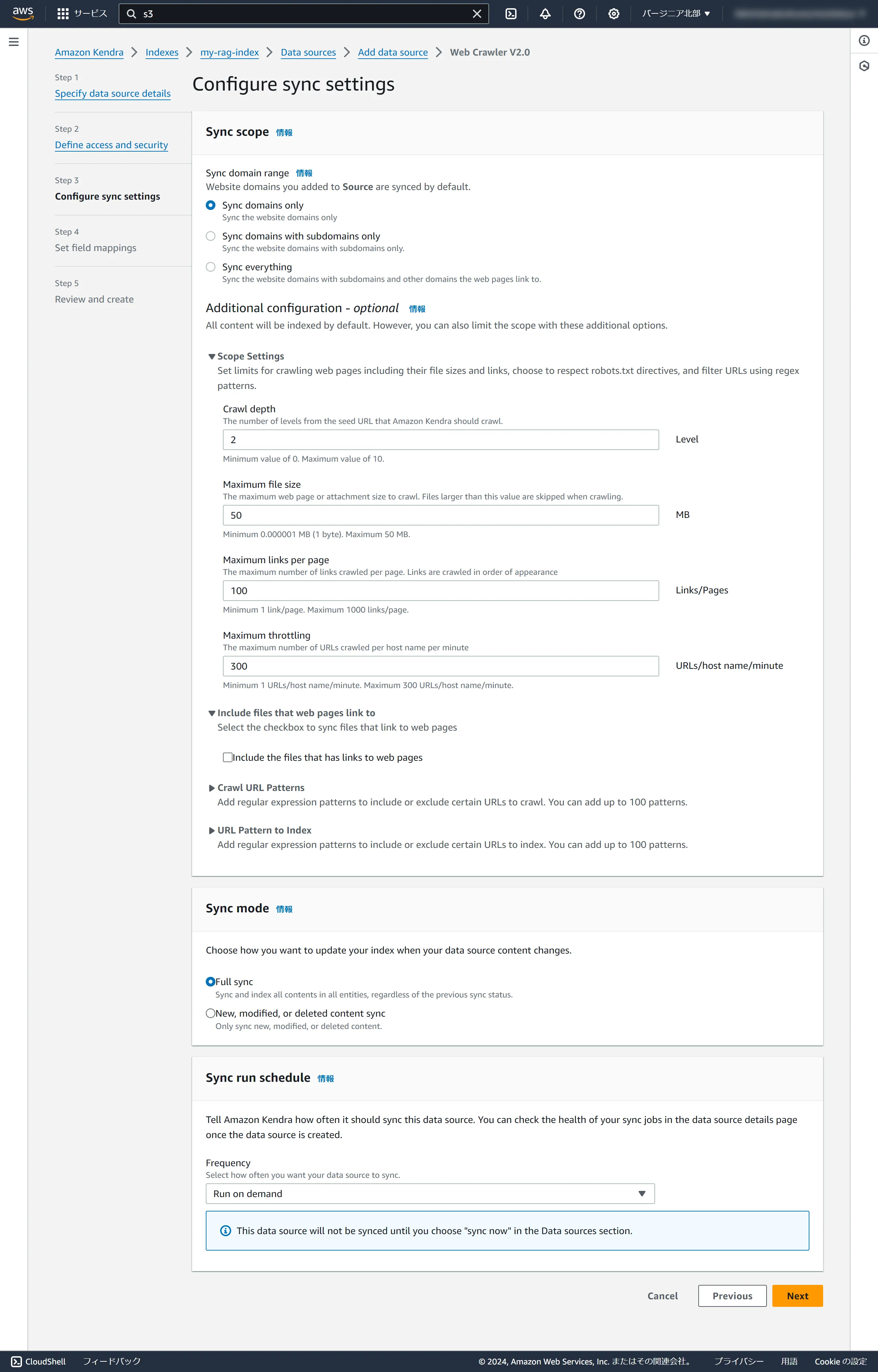
Item
Value
Sync domain range
Select Sync domains only
Sync mode
Select Full sync
Sync run schedule
Select Run on demand
Don't make any changes on this screen, just click Next.
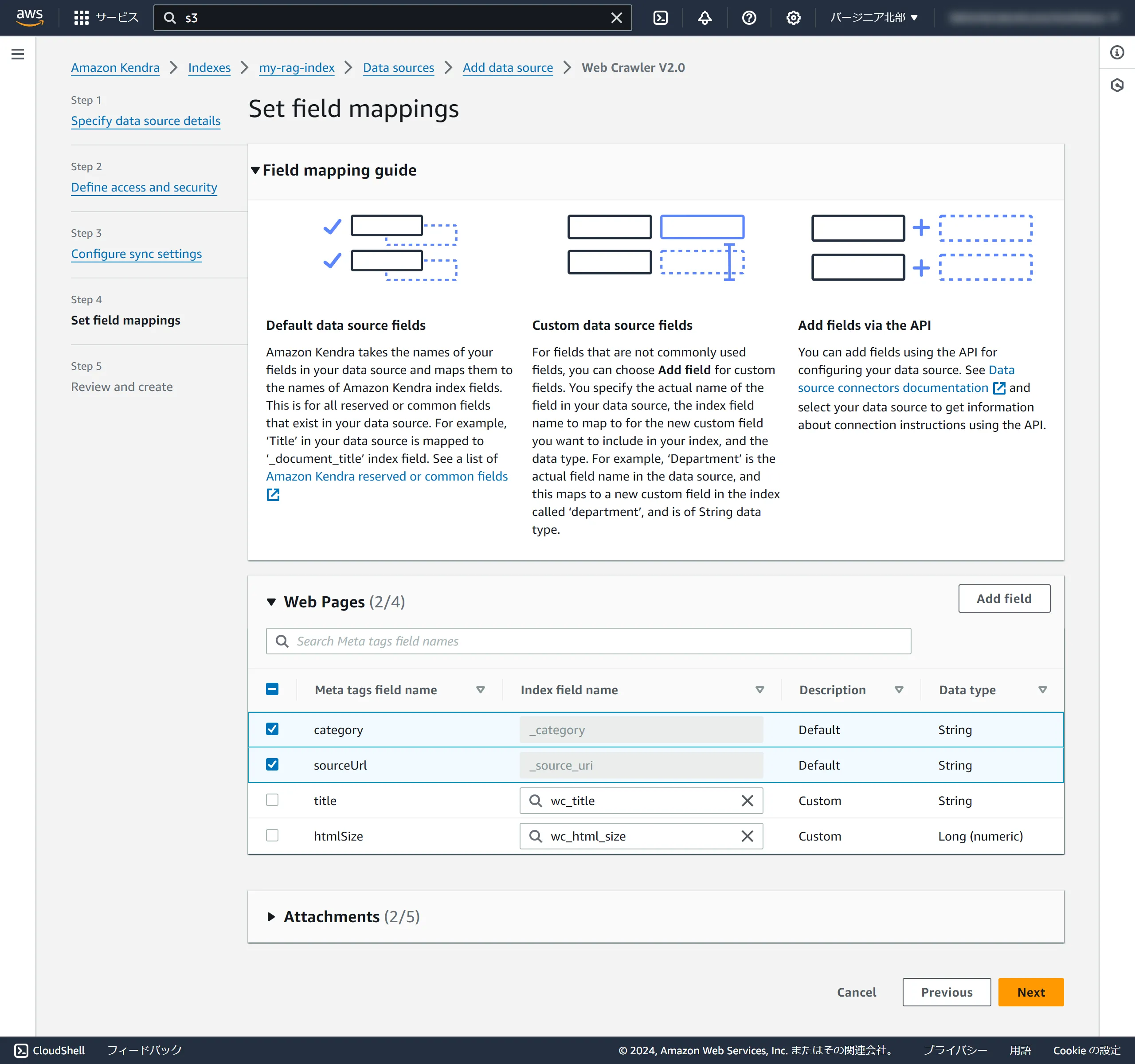
The confirmation screen will appear, so click Add data source. (Screenshot omitted)
The data source has been created. However, it won't be searchable until you perform the synchronization. Click Sync now.
✅️The synchronization will take more than an hour, so let's move on to the next step.
Similarly, add the Bedrock Developer Guide and the Comprehend Developer Guide as data sources.
In the middle of the steps, when specifying an IAM role, it's better to select "Create a new role" each time to ensure a new IAM role is created. Don't forget to execute the "Sync now" as well.