[Beginner] Experience RAG through a Hands-on : Part 2
I've created a hands-on article with the concept of just trying it out and experiencing it. 🎉🎉🎉
Published May 6, 2024
Last Modified May 7, 2024
✅️I am translating and posting the original text written in Japanese. Screen capture and language settings are set for Japan.
Generative AI is a very prominent technology, but it may be a bit difficult to get started with. New models and utilization methods are emerging almost daily, making it quite challenging to stay up-to-date.To help those who have missed the opportunity to get started, I've created a hands-on article with the concept of just trying it out and experiencing it. 🎉🎉🎉The content of the hands-on session is RAG. RAG is a commonly used keyword when it comes to the application of generative AI. In this hands-on, you'll be able to experience the latest "Advanced RAG", not just regular RAG.
✅️We'll assume you have some knowledge of AWS and Python.
⚠️Since this is a super-fast RAG experience, we won't cover what generative AI is or how to write prompts at all (prompts won't even be mentioned).
Let's create the application.
Prepare a Python 3.11 environment and install
boto3.First, let's import the necessary libraries.
Create a client using boto3. The service name to use for invoking Bedrock models is bedrock-runtime.
✅️While there are also bedrock clients, let's ignore those for now.
This is the ID of the Bedrock model to be used. The model ID for the Cohere Command R+ model is:
The Bedrock invocation is done using the
Set the
invoke_model method.Set the
question as the message in the JSON body, and the rest can be written as is.The response is not a simple JSON string, but the
body part is returned as a StreamingBody type. We need to convert the body to JSON.✅️This is similar to usingget_objectto retrieve objects from an S3 bucket. Bedrock seems to be designed to return not only text but also images, as it has image generation models.
Extract the
text values from the search_queries array.It's done.
Let's try running it.
The user's question is: "I'm considering using Amazon Kendra to make the content of my website searchable. Is there a way to restrict the URLs that Kendra crawls?"
['Amazon Kendra Crawl URL Restrictions']
---
✅️In the example above, the array contains only one item. However, if the question was "Tell me about the regions supported by Kendra and Bedrock", the following two items would be returned:* Kendra available regions
* Bedrock coverage
We will perform a search using the generated search query in Kendra.
We will generate a Kendra client.
We will call the
Set the
The
retrieve API.Set the
IndexId to the Kendra Index ID, and the QueryText to the search keyword generated in the previous step.The
AttributeFilter is a setting to search for data indexed in Japanese.✅️If you don't specify the search language in the AttributeFilter, the search will be in English (en).
The
ResultItems in the JSON response are the search results. They are returned in the following structure.Since there may be multiple search queries, we will store the
ResultItems values in search_results.After executing all the search queries, we will convert the data to include only the "Id", "DocumentTitle", "Content", and "DocumentURI" fields.
The search process is now complete.
Execute.
Result.
[
{
"Id": "b0701a9f-3928-49e5-a98d-a48f6e7e3a58-9d3749bf-3d22-4361-add3-e90945426f1b",
"DocumentTitle": "Confluence Connector V2.0 - Amazon Kendra",
"Content": "[Additional Configuration] using the [Spaces] key...",
"DocumentURI": "https://docs.aws.amazon.com/ja_jp/kendra/latest/dg/data-source-v2-confluence.html"
},
...
{
"Id": "b0701a9f-3928-49e5-a98d-a48f6e7e3a58-89d91765-63e3-44c0-acd6-0c5d61b9353b",
"DocumentTitle": "Data Source Template Schemas - Amazon Kendra",
"Content": "The repositoryConfigurations for the data source...",
"DocumentURI": "https://docs.aws.amazon.com/ja_jp/kendra/latest/dg/ds-schemas.html"
}
]
Generate the answer from the question and search results.
Call Bedrock again to generate the answer.
When generating the search queries, we specified
message and search_queries_only in the body. For answer generation, we specify message and documents instead.The way to receive the response is the same as before, but the structure of the
The
response_body is different.The
text contains the answer generated by the AI based on the referenced documents.It's complete.
😀Question:
I'm considering making the content of my website searchable using Amazon Kendra. Is there a way to restrict the URLs that are crawled?
🤖Answer:
Yes, Amazon Kendra allows you to restrict the URLs that are crawled. When configuring the synchronization settings, you can set limits on the crawling of web pages, such as by domain, file size, links, and use regular expression patterns to filter URLs.
---
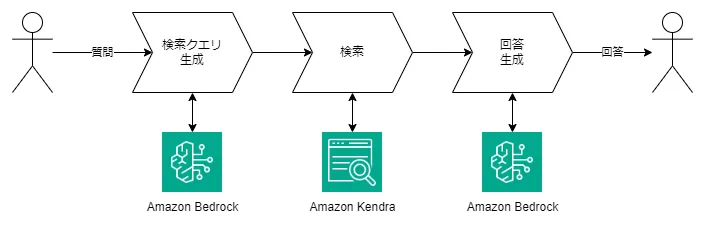
✅️It's complete. This is RAG (Retrieval-Augmented Generation).
[R] Retrieval: Search
[A] Augmented: Augment
[G] Generation: Generate the answer
The complete source code is here.
We've created an RAG (Advanced RAG) application with about 100 lines of code. As you can see, each step is very simple.
Didn't you feel like you were using a generative AI at all? What do you think?
Didn't you feel like you were using a generative AI at all? What do you think?
There was no mention of "prompts" or "prompt engineering" at all. We just simply:
- Call an API to generate search queries from the user's question
- Call a search API
- Call an API to generate the answer from the search results
This ease of use is a characteristic of Cohere Command R+. In the case of GPT-4 or Claude 3, you would need techniques like "how to write the question in the prompt" and "how to reference the documents", which can lead to difficulty in getting started.
Command R+ has a very well-designed API, and I was impressed.
Command R+ has a very well-designed API, and I was impressed.
If you feel like "Ah, RAG is simple after all, I completely understand it!!", then please come to the world of Bedrock and let's have fun together!!