Stream Amazon Bedrock responses for a more responsive UI
Pair Amazon Bedrock's invoke_model_with_response_stream with a bit of Streamlit's magic to give it the typewriter effect, creating a more responsive UI
Published May 17, 2024
Last Modified May 29, 2024
Earlier this week, my team held a "winging it" session. A "winging it" session is essentially a mob programming session where one person (in this case, me) drives and the rest of the team helps to navigate a problem. I enter this session relatively unprepared, with only a problem I want help solving or something I want to learn more about and a working dev environment. This particular day, I tasked myself with exploring more about integrating my Streamlit webapp with Amazon Bedrock.
Just want to grab the final code? Head to the last section and it's yours!
I had already spent some time with my coworker's article here to make a simple call to a model using the
invoke_model API through a Python script run at the command line. It was pretty straightforward to migrate this send_prompt_to_bedrock function to my Streamlit app:In the code above, the
send_prompt_to_bedrock uses invoke_model to send a user entered prompt to the Claude Sonnet model. When the response is returned, it is simply parsed and written to the page using Streamlit's write function.As I was showing my coworkers my current state, I used my trusty prompt
What is the capital of France? and got a response. A really short one: The capital of France is Paris. But what if I ask a question that warrants a much longer response? Maybe something like Sing me a song about DevOps. The user sits there and waits until the entire response has been returned from the API call and then the UI updates. My coworkers picked up on this and suggested a minor improvement -- stream the response so it prints to the UI earlier. We knew it was possible to do, but none of us knew the exact call to make and how to do it with Streamlit.So, we asked Amazon Q:
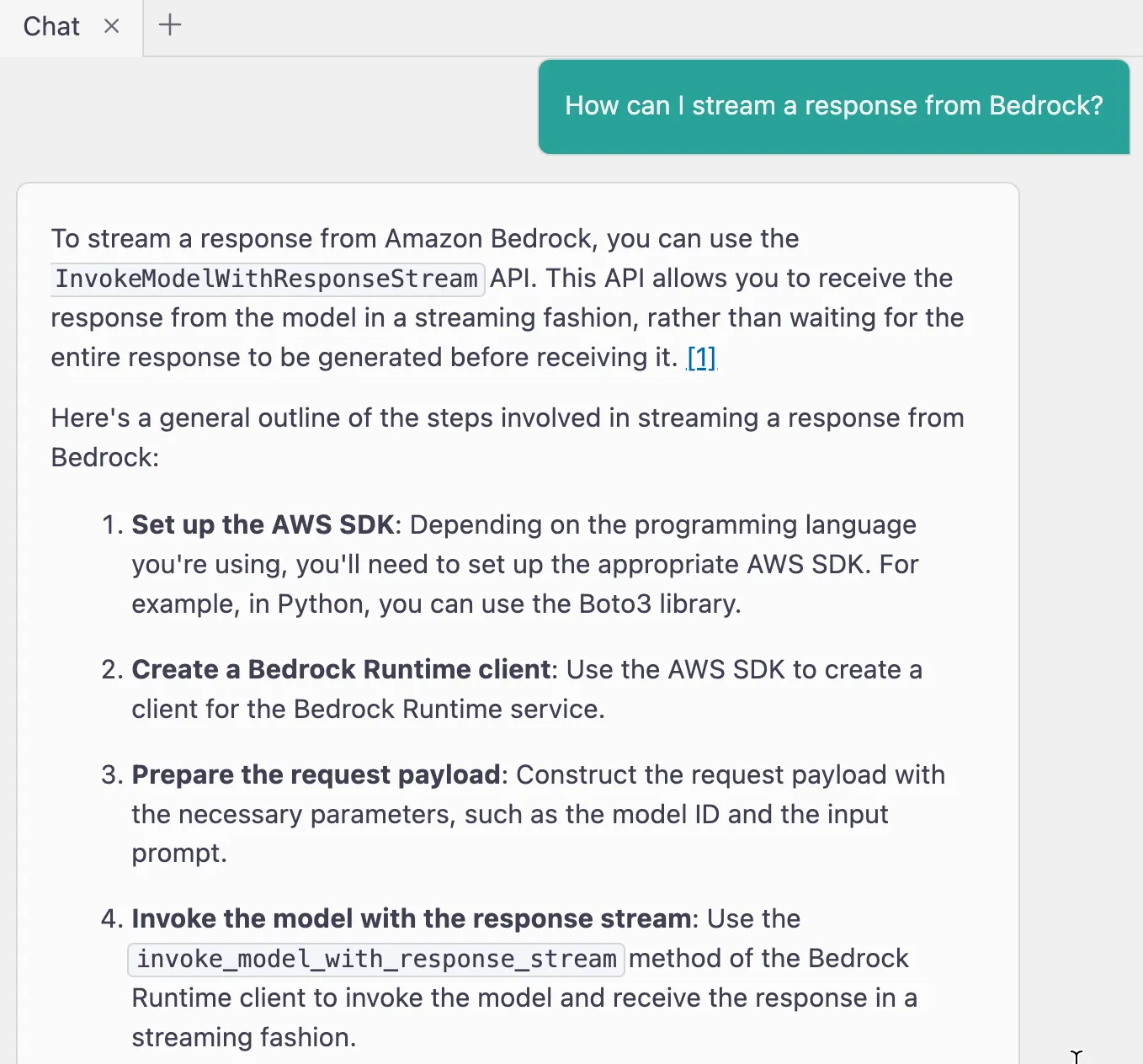
Turns out there is a function on the Amazon Bedrock runtime client that returns the response as a stream --
invoke_model_with_response_stream. Let use that!I swapped out the
invoke_model call for this one:And then had to figure out how to parse and process the streamed response. This took a bit of debugging as the response from Amazon Q wasn't quite what I needed. Below, we get the actual stream object, iterate over it, and return the chunked content if the type is
content_block_delta. And if it's not content_block_delta and instead is message_stop, we know we've hit the end of the response stream and return a new line.Now that we've processed the stream, we can write that back to the page. Instead of using Streamlit's
write function, we swap it out for write_stream which does all the fancy magic to make it look like typewriter output.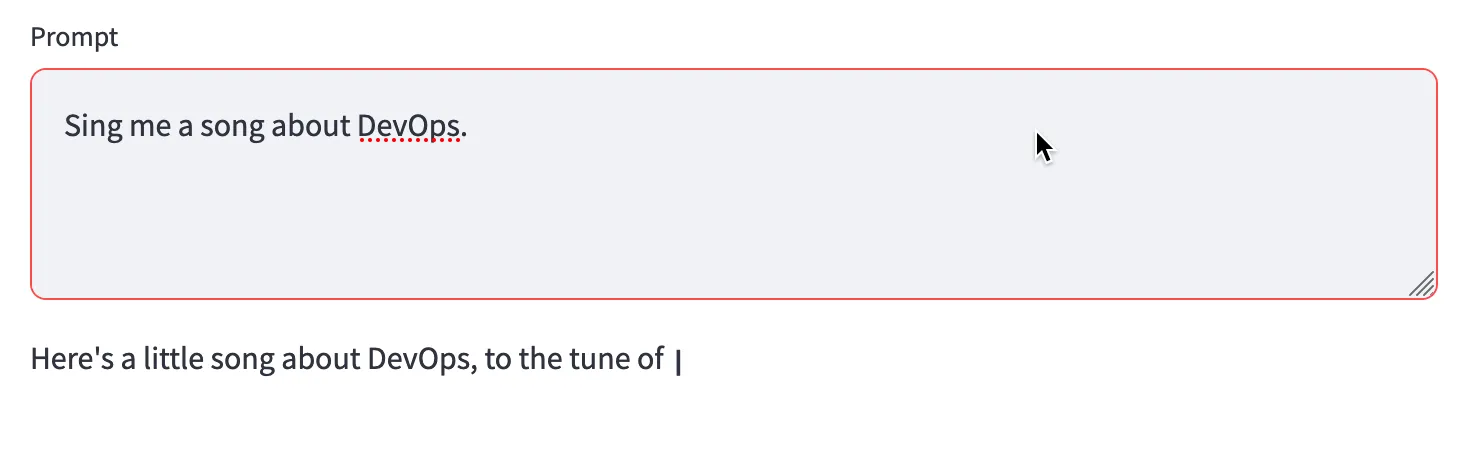
In addition to providing earlier feedback to the user by updating the UI earlier,
invoke_model_with_response_stream also gives us other benefits like better memory management and the potential to interrupt the response.It wasn't too painful to get from
invoke_model to invoke_model_with_response, except that we had to figure out how to process that response stream. In the final code below, you can see how we pull this all together and stream a response from Amazon Bedrock and use a bit of Streamlit's magic to give it the typewriter effect.Want more like this? Give this article a like 👍 or drop a comment 💬 below and help me figure out what to explore next!
Here are a few resources that were helpful to me while figuring this out:
You can grab the full code to stream the response here: