Simplify analyzing AWS WAF rules with GenAI using Amazon Bedrock
Use natural language queries to get insights from your WAF logs with the help of generative AI
Karan Desai
Amazon Employee
Published May 20, 2024
Last Modified May 28, 2024
AWS Web Application Firewall (WAF) is widely used to protect websites and internet-facing applications from web exploits and attacks. A common question we get is "how do I know my WAF rules are working?" or "how can I check why certain requests got blocked? Which WAF rule triggered it?" There are solutions built for this such as using Amazon CloudWatch Logs Insights or writing SQL queries in Amazon Athena. However, now you can leverage the power of generative AI by asking for the details you need in regular English and have a generative AI foundation model interpret your WAF logs and provide you the insights from it. In this article, I will show how to build a simple app to achieve this.
- An AWS account where you have resources deployed and protected by an AWS WAF WebACL. If you do not have existing WAF configuration, you can create a new one.
- AWS Command Line Interface (CLI) installed on your local machine, or you can use AWS Cloud9 IDE
- Boto3 which is the AWS SDK for Python. Install on your local machine if you do not have it.
- Streamlit to create a web UI for the app. Install on your local machine or Cloud9 IDE
- Access to Amazon Bedrock foundation models. Request access for AI21 Labs Jurassic models if you have do not have it already
To keep this solution simple, we will query WAF sampled requests, however you can modify this to query complete WAF logs if you have them enabled. We will fetch sampled requests for a specific WebACL of your choice for the last 60 minutes, get an input from the user in natural language what details they want to know from the logs, and create a prompt from it to feed it to AI21 Labs Jurassic 2 Ultra foundation model running on Amazon Bedrock. The generative AI model will interpret the logs and provide the response. We will create a simple web application with Streamlit to provide a browser-based UI to input questions and view the response. You can run the Streamlit app locally on your machine, or deploy it on an Amazon EC2 instance or in a container to access it over the internet.
Copy the following code in your IDE and save it as a .py file, for example
wafanalysis.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
import json
import boto3
import streamlit as st
from datetime import datetime, timedelta
# Initialize AWS clients
session = boto3.Session(profile_name='default')
waf = session.client(service_name='wafv2')
bedrock = session.client(service_name='bedrock-runtime')
bedrock_model_id = 'ai21.j2-ultra-v1' # Using AI21 Labs Jurassic model. For all model IDs, refer https://docs.aws.amazon.com/bedrock/latest/userguide/model-ids.html
# Function to fetch and analyze AWS WAF logs
def fetch_and_analyze_waf_logs(web_acl_arn, rule_metric_name, user_prompt):
# Get the current time and the time 60 minutes ago
current_time = datetime.utcnow()
start_time = current_time - timedelta(minutes=60)
# Fetch the AWS WAF logs for last 60 minutes from a specific WebACL
response = waf.get_sampled_requests(
WebAclArn=web_acl_arn,
RuleMetricName=rule_metric_name,
Scope='CLOUDFRONT', # Change this to REGIONAL if WebACL is associated with regional resources such as ALB or API Gateway
TimeWindow={
'StartTime': start_time,
'EndTime': current_time
},
MaxItems=100
)
# Create a prompt with WAF logs appended to it
input_data = "Analyze the following AWS WAF logs and provide insights for the following: " + str(user_prompt) + " " + str(response)
# FOR DEBUGGING: print the input prompt created in command line. Comment out if not required.
print("Input Prompt = ")
print(input_data)
# Provide inference parameters to the Amazon Bedrock model. This format is specific to AI21 model. For parameters for other models, refer https://docs.aws.amazon.com/bedrock/latest/userguide/model-parameters.html
body = json.dumps({
"prompt": input_data,
"maxTokens": 1024,
"temperature": 0,
"topP": 0.5,
"stopSequences": [],
"countPenalty": {"scale": 0 },
"presencePenalty": {"scale": 0 },
"frequencyPenalty": {"scale": 0 }
})
# Invoke Amazon Bedrock with the input data in JSON format
bedrock_response = bedrock.invoke_model(
modelId=bedrock_model_id,
body=body,
contentType='application/json',
accept='application/json'
)
# Decode the response body
response_body = json.loads(bedrock_response['body'].read().decode('utf-8'))
# Extract the text from the JSON response
response_text = response_body.get("completions", [])
if response_text:
response_text = response_text[0].get("data", {}).get("text", "")
return response_text
# Streamlit app to capture user input and display results
def main():
st.title("Analyze AWS WAF Logs with GenAI using Amazon Bedrock")
# Get user input for WebAclArn and RuleMetricName
web_acl_arn = st.text_input("Enter WebAclArn", value="")
rule_metric_name = st.text_input("Enter RuleMetricName", value="")
user_prompt = st.text_input("Enter your question", value="What rule is causing the 403 block?")
# Run the analysis when the user clicks the button
if st.button("Analyze WAF Logs"):
analysis = fetch_and_analyze_waf_logs(web_acl_arn, rule_metric_name, user_prompt)
st.write(analysis)
if __name__ == "__main__":
main()The comments in the code explain each section. You can use this as-is, or modify as per your preference.
One section particularly that you may wish to modify is the inference parameters given to the foundation model. The temperature is set to 0 because we want the model to give a more deterministic response based on the WAF logs we are providing rather than it getting creative. The topP is set to 0.5 to be neutral but if you find the responses to be misleading, you can experiment changing it a lower value to decrease the size of the pool and limit the options to more likely outputs. There is no count penalty, presence penalty or frequency penalty set but you can change the penalties if you want to limit the responses based on the presence of specific terms (tokens).
To run the Streamlit app, navigate to the folder where you saved the Python file, and run the following command from the terminal/command line prompt on your local machine or Cloud9:
streamlit run wafanalysis.py --server.port 8080This will open a web UI in your default browser. If it does not open automatically, you can type
localhost:8080 in the address bar of your browser and it should open the UI.In the UI, enter the following details:
- ARN of your WAF WebACL. You can find the ARN by navigating to AWS WAF on the AWS console. Go to the list of your WebACLs, click the radio button next to the name of the WebACL and click the CopyARN button. The ARN should look something like this:
arn:aws:wafv2:us-east-1:1234567890:global/webacl/name-of-webacl/46abc41c-04ca-4d90-a317-66f6e5e123bd- The name of the WAF rule whose details you want to analyze. Copy this from the Rules tab of your WebACL on the AWS console
- Your question in natural language. For example, how many requests were blocked by this rule and what IPs did they come from?
- Click the Analyze WAF logs button and wait for a few seconds. The generative AI model will evaluate your question and provide a response on the screen.
For example, you can ask why are certain requests getting blocked by your WAF rules.
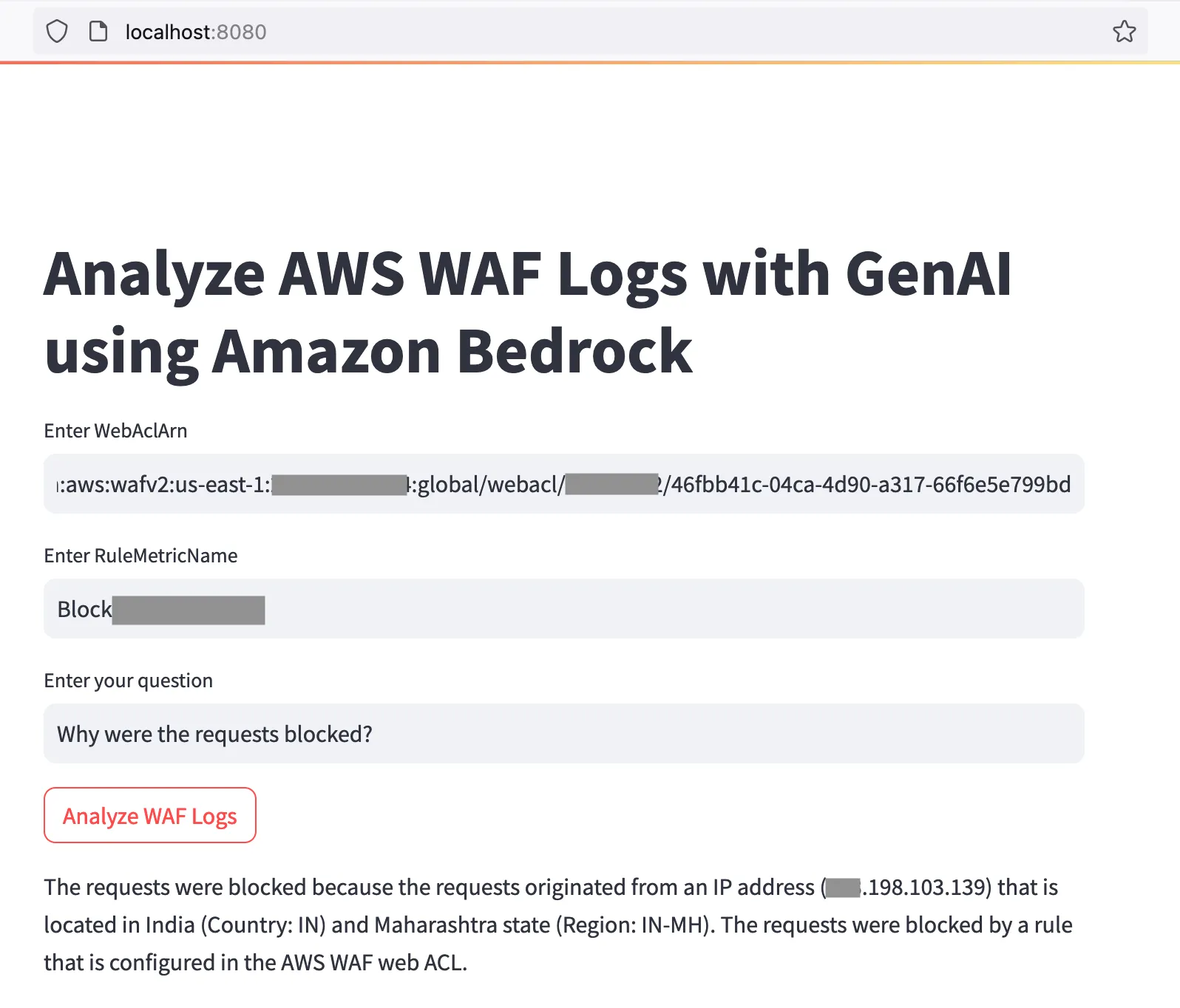
Or, you can ask to find commonalities between the various requests getting blocked which can help you better understand if there is any pattern in the origin of the malicious traffic attacking your resources.
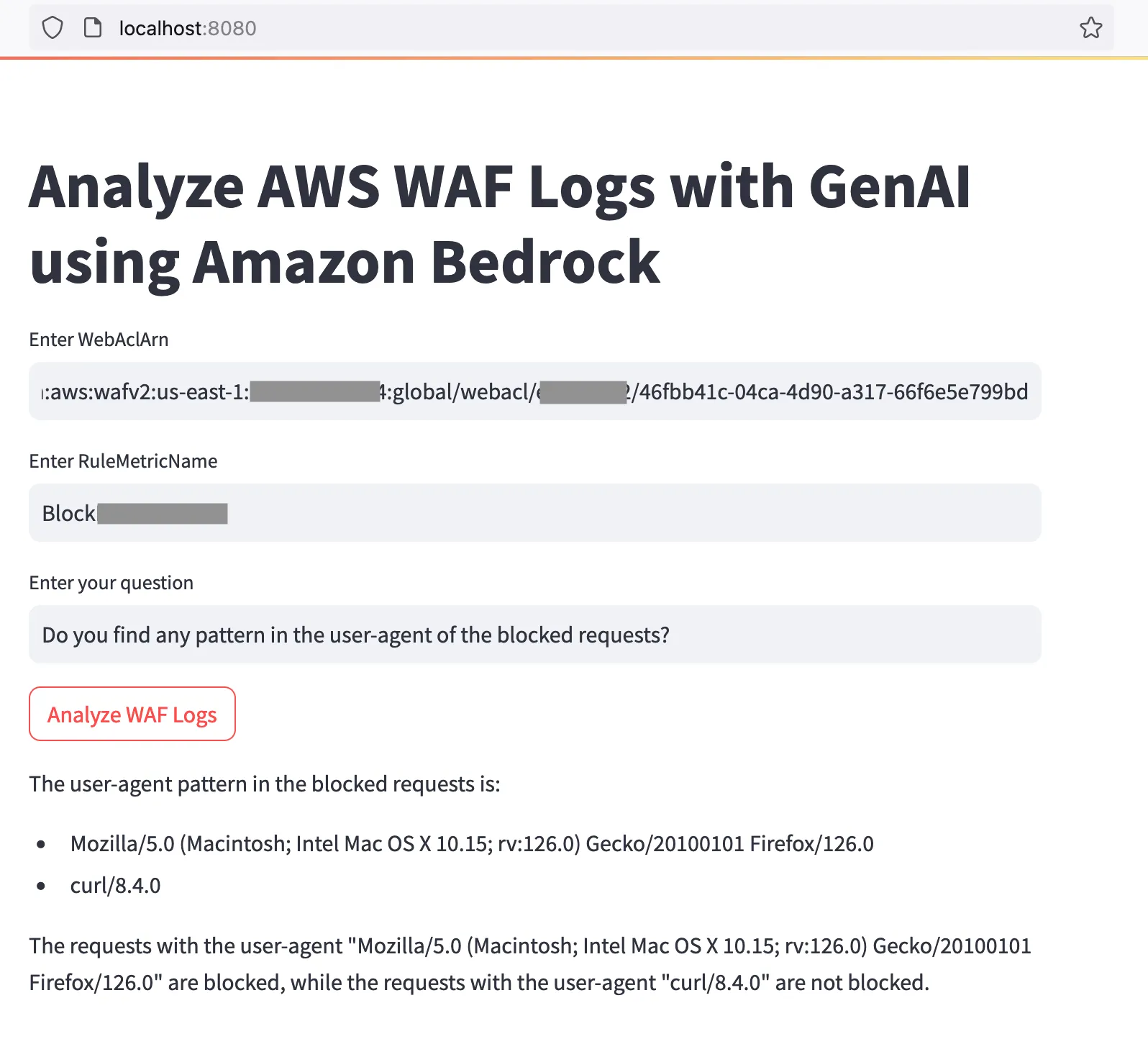
These are just some examples. You can experiment with a variety of prompts to get the insights you are looking to get from your WAF logs.
This is an example of a simple implementation of using the power of GenAI to provide an easy interface to interpret your AWS WAF traffic. You can enhance this further by experimenting with different foundation models available on Amazon Bedrock, modify the inference parameters, use knowledge bases to take advantage of retrieval augmented generation (RAG) by providing your own data sources with details about your application to augment the interpretation of results, and so on. If you build something cool based on this, consider writing an article about it here on AWS Community to share your solution!
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.
Comments
Log in to comment