Scrape All Things: AI-powered web scraping with ScrapeGraphAI 🕷️ and Amazon Bedrock ⛰️
Learn how to extract information from documents and websites using natural language prompts.
João Galego
Amazon Employee
Published May 21, 2024
"In the beginning was a graph..." ― Greg Egan, Schild's Ladder
A couple of weeks, I began hearing rumors about a new project that was taking GitHub trends by storm.
I usually don't pay much attention to such gossip, but everyone kept calling it a "revolution" in web scraping and commending it for its "ease of use" that I decided to give it a chance.
The project in question is of course ScrapeGraphAI 🕷️, an open-source Python library that uses large language models (LLMs) 🧠💬 and directed graph logic 🟢→🟡→🟣 to create scraping pipelines for websites and documents, allowing us to extract information from multiple sources using only natural language prompts.
4 pull requests later, I can safely say that I have become a fan 🤩 (Most of my contributions are around improving the integration between ScrapeGraphAI and AWS AI services - big thanks to Marco Vinciguerra and the rest of team for reviewing them all 🙌).
So my plan for today is to show you how to to create next-generation, AI-powered scraping pipelines using ScrapeGraphAI and Amazon Bedrock ⛰️, a fully managed AI service that let's you access state-of-the-art LLMs and embedding models.
But first, let's look at a simple example to illustrate how far we've come along...
Take this XML file which contains a small list of books 📚:
Let's say we want to parse this file, create a list of authors, titles and genres, and discard everything else. How would you do it?
Here's how I would've done it in the old days using lxml, a Python library for processing XML files:
Output:
In order to implement something like this, we would need to know beforehand that all books are represented by a
book element 📗, which contains children elements corresponding to the author, title and genre of the book, and that all books are themselves children nodes of the root node, which is called catalog 🗂️.Not-So-Fun Fact: in a past life, when I worked as a software tester, I used to write scripts like this all the time using frameworks like BeautifulSoup (BS will make an appearance later in this article, just keep reading) and Selenium. Glad those days are over! 🤭
This option is great if you don't mind going through XML hell 🔥

Fortunately, there is now a better way: we can simply ask for what we need.
Although the old 👴🏻 and the new 🕷️⛰️ scraper implementations have exactly the same size (28 LoC) and both will generate the same output, the way they work is completely different.
In the new scraper, we're using two different Bedrock-provided models - Claude 3 Sonnet as the LLM and Cohere Embed Multilingual v3 as the embedder - that receive our file and generate a response.
As a prompt, we're simply sending our original request plus a
Skip the preamble instruction to ensure that Claude goes straight to the point and generates the right output.Tying everything together is the graph.
In ScrapeGraphAI parlance, graphs are just scraping pipelines aimed at solving specific tasks.
Each graph is composed of several nodes 🟢🟡🟣, which can be configured individually to address different aspects of the task like fetching data or extracting information, and the edges that connect them
Input → 🟢 → 🟡 → 🟣 → Output.ScrapeGraphAI offers a wide range of pre-built graphs like the
XMLScraperGraph, which we used in the example above, or the SmartScraperGraph (pictured below), and the possibility to create your own custom graphs.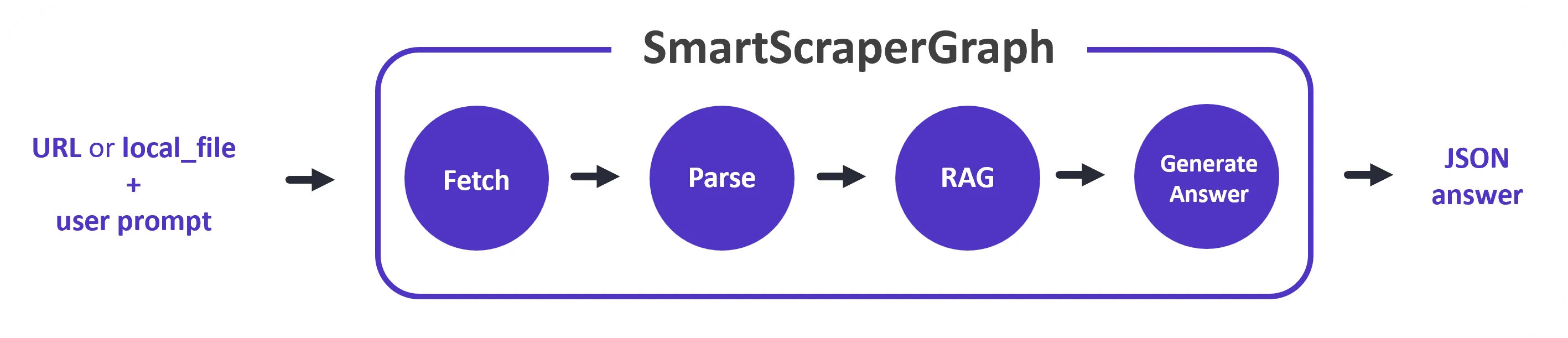
AWS credentials and settings are usually injected via environment variables (
AWS_*) but we can create a custom client and pass it along to the graph:Output:
As a way to explore different use cases with Amazon Bedrock, I've created a multi-page Streamlit application that showcases a small subset of scraper graphs.
👨💻 All code and documentation is available on GitHub.
1/ Clone the ScrapeGraphAI-Bedrock repository
and install the dependencies
2/ Don't forget to set up the AWS credentials
3/ Start the demo application
Remember when I said that BeautifulSoup would make an appearance? You can use the Script Generator demo, which is backed by the
ScriptCreatorGraph, to generate an old-style scraping pipeline powered by the beautifulsoup framework or any other scraping library.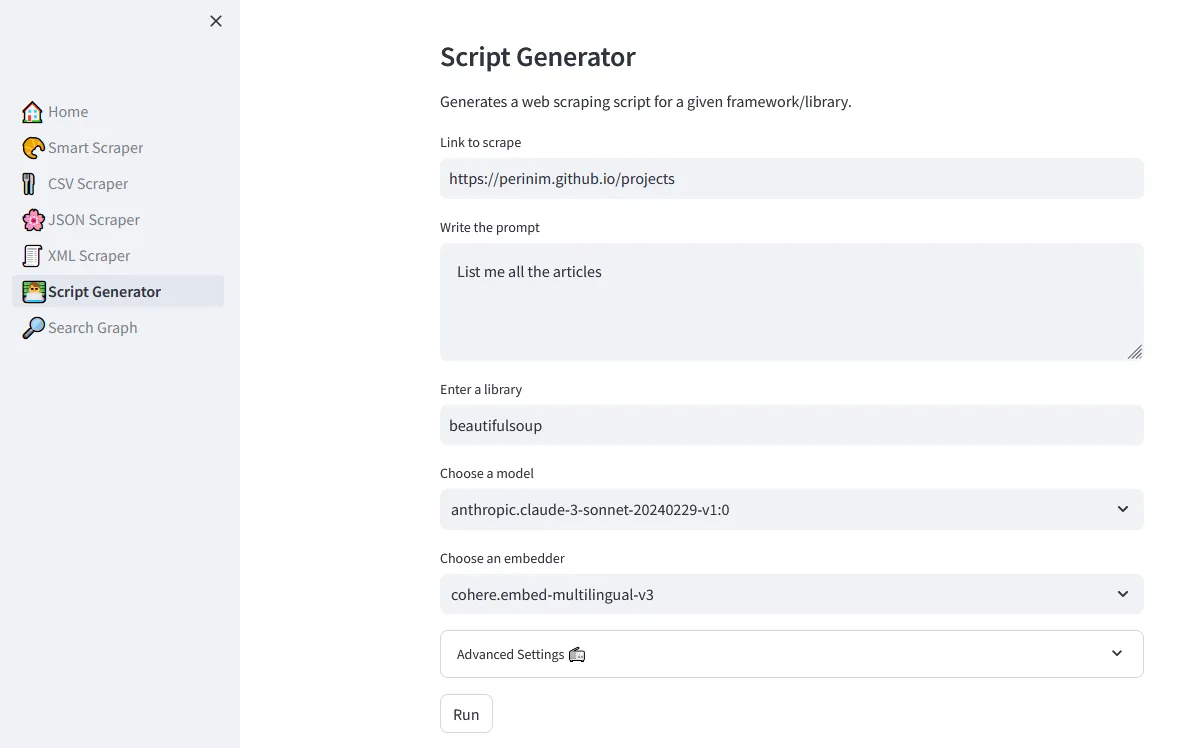
Try it out, share it and let me know what you think in the comments section below ⤵️
👷♂️ Want to contribute? Feel free to open an issue or a pull request!
See you next time! 👋
Any opinions in this post are those of the individual author and may not reflect the opinions of AWS.